 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Optimizing Vision Transformers for Medical Image Segmentation and Few-Shot Domain Adaptation
Oct 14, 2022
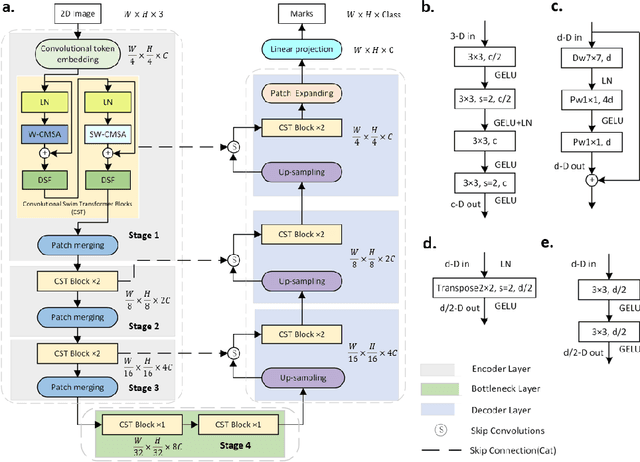
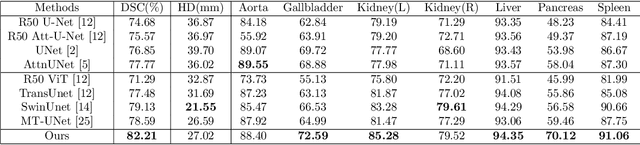
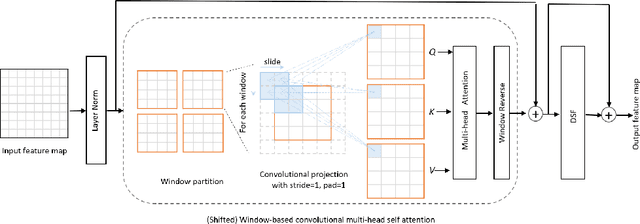
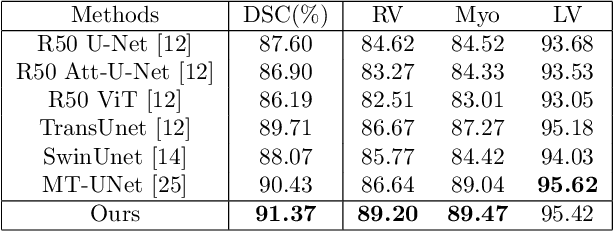
The adaptation of transformers to computer vision is not straightforward because the modelling of image contextual information results in quadratic computational complexity with relation to the input features. Most of existing methods require extensive pre-training on massive datasets such as ImageNet and therefore their application to fields such as healthcare is less effective. CNNs are the dominant architecture in computer vision tasks because convolutional filters can effectively model local dependencies and reduce drastically the parameters required. However, convolutional filters cannot handle more complex interactions, which are beyond a small neighbour of pixels. Furthermore, their weights are fixed after training and thus they do not take into consideration changes in the visual input. Inspired by recent work on hybrid visual transformers with convolutions and hierarchical transformers, we propose Convolutional Swin-Unet (CS-Unet) transformer blocks and optimise their settings with relation to patch embedding, projection, the feed-forward network, up sampling and skip connections. CS-Unet can be trained from scratch and inherits the superiority of convolutions in each feature process phase. It helps to encode precise spatial information and produce hierarchical representations that contribute to object concepts at various scales. Experiments show that CS-Unet without pre-training surpasses other state-of-the-art counterparts by large margins on two medical CT and MRI datasets with fewer parameters. In addition, two domain-adaptation experiments on optic disc and polyp image segmentation further prove that our method is highly generalizable and effectively bridges the domain gap between images from different sources.
'The Taurus': Cattle Breeds & Diseases Identification Mobile Application using Machine Learning
Feb 21, 2023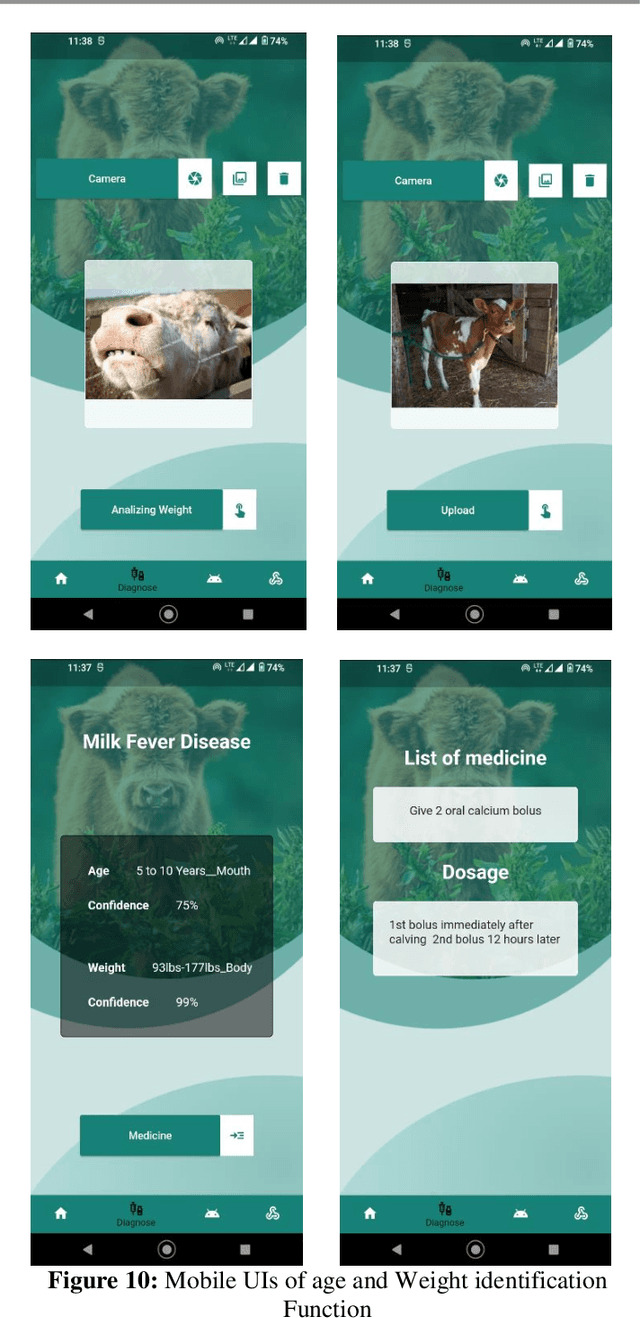
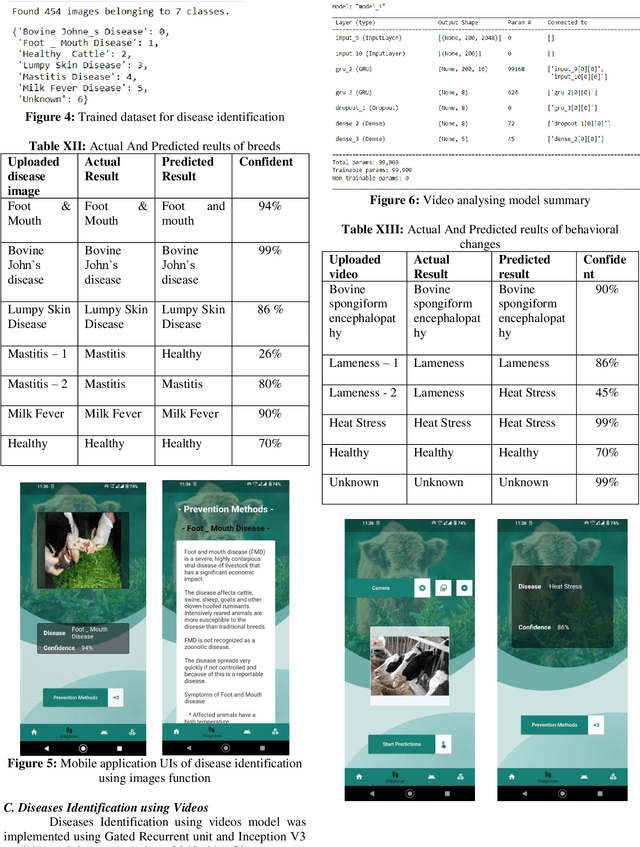

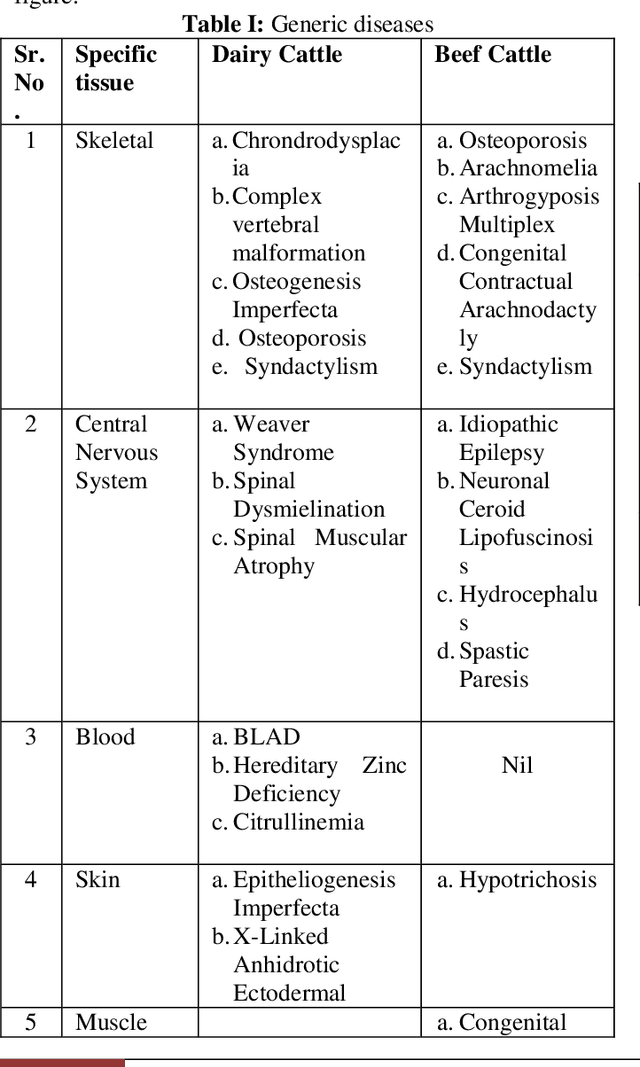
Dairy farming plays an important role in agriculture for thousands of years not only in Sri Lanka but also in so many other countries. When it comes to dairy farming cattle is an indispensable animal. According to the literature surveys almost 3.9 million cattle and calves die in a year due to different types of diseases. The causes of diseases are mainly bacteria, parasites, fungi, chemical poisons and etc. Infectious diseases can be a greatest threat to livestock health. The mortality rate of cattle causes a huge impact on social, economic and environmental damage. In order to decrease this negative impact, the proposal implements a cross-platform mobile application to easily analyze and identify the diseases which cattle suffer from and give them a solution and also to identify the cattle breeds. The mobile application is designed to identify the breeds by analyzing the images of the cattle and identify diseases after analyzing the videos and the images of affected areas. Then make a model to identify the weight and the age of a particular cow and suggest the best dose of the medicine to the identified disease. This will be a huge advantage to farmers as well as to dairy industry. The name of the proposed mobile application is 'The Taurus' and this paper address the selected machine learning and image processing models and the approaches taken to identify the diseases, breeds and suggest the prevention methods and medicine to the identified disease.
DaliID: Distortion-Adaptive Learned Invariance for Identification Models
Feb 11, 2023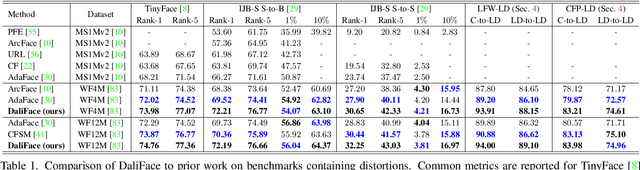


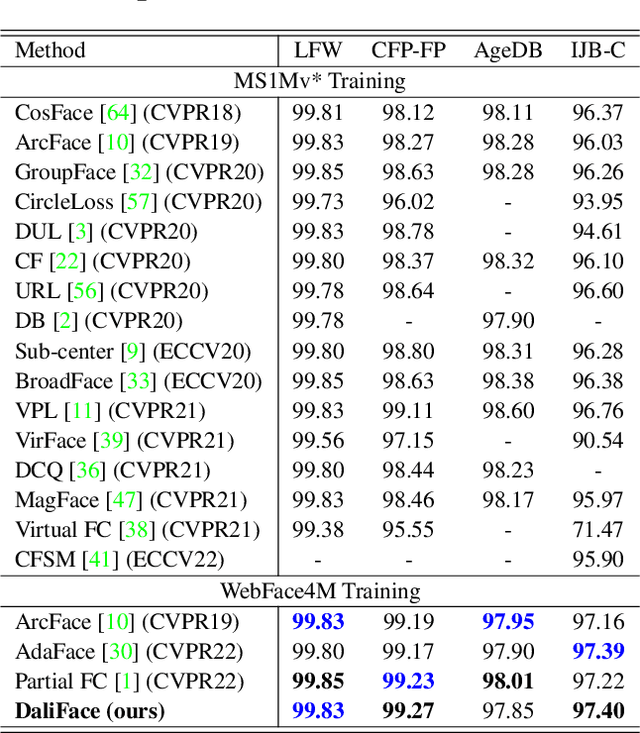
In unconstrained scenarios, face recognition and person re-identification are subject to distortions such as motion blur, atmospheric turbulence, or upsampling artifacts. To improve robustness in these scenarios, we propose a methodology called Distortion-Adaptive Learned Invariance for Identification (DaliID) models. We contend that distortion augmentations, which degrade image quality, can be successfully leveraged to a greater degree than has been shown in the literature. Aided by an adaptive weighting schedule, a novel distortion augmentation is applied at severe levels during training. This training strategy increases feature-level invariance to distortions and decreases domain shift to unconstrained scenarios. At inference, we use a magnitude-weighted fusion of features from parallel models to retain robustness across the range of images. DaliID models achieve state-of-the-art (SOTA) for both face recognition and person re-identification on seven benchmark datasets, including IJB-S, TinyFace, DeepChange, and MSMT17. Additionally, we provide recaptured evaluation data at a distance of 750+ meters and further validate on real long-distance face imagery.
The XPRESS Challenge: Xray Projectomic Reconstruction -- Extracting Segmentation with Skeletons
Feb 24, 2023
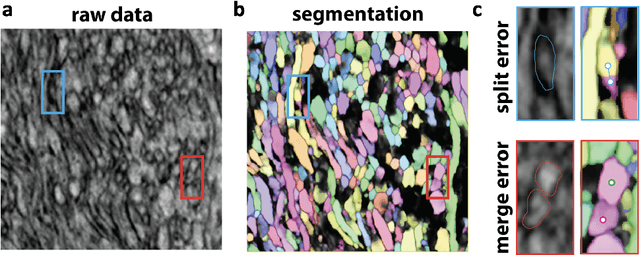
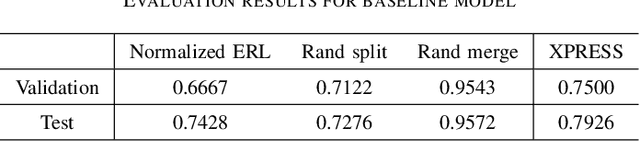

The wiring and connectivity of neurons form a structural basis for the function of the nervous system. Advances in volume electron microscopy (EM) and image segmentation have enabled mapping of circuit diagrams (connectomics) within local regions of the mouse brain. However, applying volume EM over the whole brain is not currently feasible due to technological challenges. As a result, comprehensive maps of long-range connections between brain regions are lacking. Recently, we demonstrated that X-ray holographic nanotomography (XNH) can provide high-resolution images of brain tissue at a much larger scale than EM. In particular, XNH is wellsuited to resolve large, myelinated axon tracts (white matter) that make up the bulk of long-range connections (projections) and are critical for inter-region communication. Thus, XNH provides an imaging solution for brain-wide projectomics. However, because XNH data is typically collected at lower resolutions and larger fields-of-view than EM, accurate segmentation of XNH images remains an important challenge that we present here. In this task, we provide volumetric XNH images of cortical white matter axons from the mouse brain along with ground truth annotations for axon trajectories. Manual voxel-wise annotation of ground truth is a time-consuming bottleneck for training segmentation networks. On the other hand, skeleton-based ground truth is much faster to annotate, and sufficient to determine connectivity. Therefore, we encourage participants to develop methods to leverage skeleton-based training. To this end, we provide two types of ground-truth annotations: a small volume of voxel-wise annotations and a larger volume with skeleton-based annotations. Entries will be evaluated on how accurately the submitted segmentations agree with the ground-truth skeleton annotations.
FLSea: Underwater Visual-Inertial and Stereo-Vision Forward-Looking Datasets
Feb 24, 2023
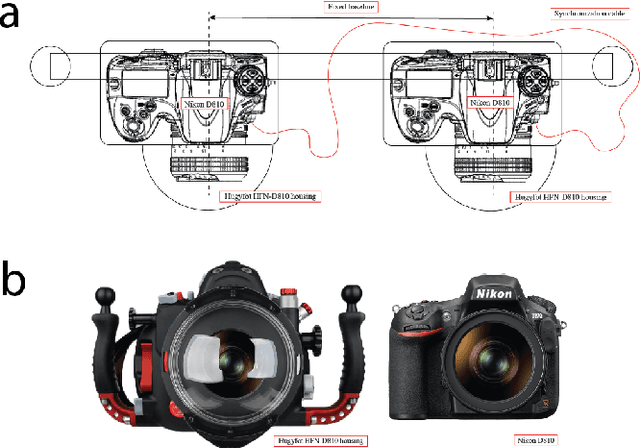
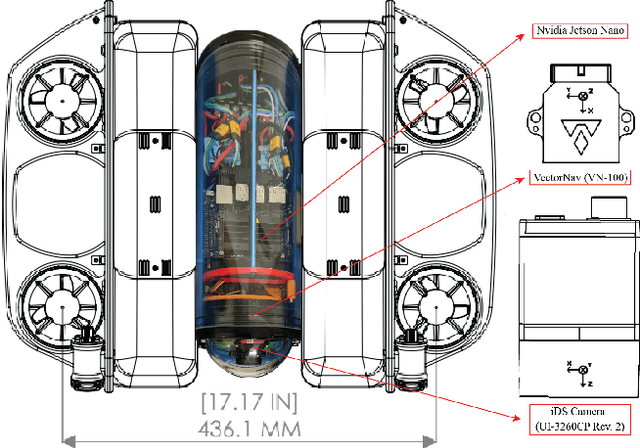

Visibility underwater is challenging, and degrades as the distance between the subject and camera increases, making vision tasks in the forward-looking direction more difficult. We have collected underwater forward-looking stereo-vision and visual-inertial image sets in the Mediterranean and Red Sea. To our knowledge there are no other public datasets in the underwater environment acquired with this camera-sensor orientation published with ground-truth. These datasets are critical for the development of several underwater applications, including obstacle avoidance, visual odometry, 3D tracking, Simultaneous Localization and Mapping (SLAM) and depth estimation. The stereo datasets include synchronized stereo images in dynamic underwater environments with objects of known-size. The visual-inertial datasets contain monocular images and IMU measurements, aligned with millisecond resolution timestamps and objects of known size which were placed in the scene. Both sensor configurations allow for scale estimation, with the calibrated baseline in the stereo setup and the IMU in the visual-inertial setup. Ground truth depth maps were created offline for both dataset types using photogrammetry. The ground truth is validated with multiple known measurements placed throughout the imaged environment. There are 5 stereo and 8 visual-inertial datasets in total, each containing thousands of images, with a range of different underwater visibility and ambient light conditions, natural and man-made structures and dynamic camera motions. The forward-looking orientation of the camera makes these datasets unique and ideal for testing underwater obstacle-avoidance algorithms and for navigation close to the seafloor in dynamic environments. With our datasets, we hope to encourage the advancement of autonomous functionality for underwater vehicles in dynamic and/or shallow water environments.
MSCDA: Multi-level Semantic-guided Contrast Improves Unsupervised Domain Adaptation for Breast MRI Segmentation in Small Datasets
Jan 04, 2023
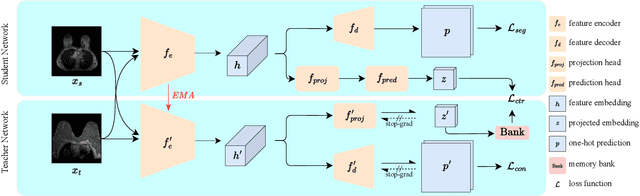
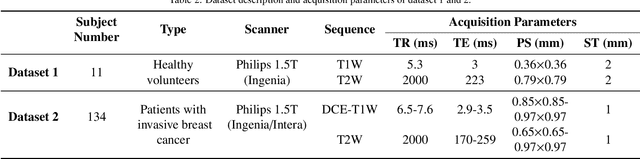
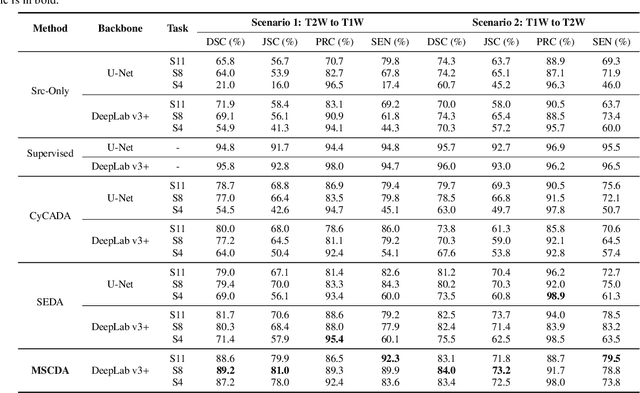
Deep learning (DL) applied to breast tissue segmentation in magnetic resonance imaging (MRI) has received increased attention in the last decade, however, the domain shift which arises from different vendors, acquisition protocols, and biological heterogeneity, remains an important but challenging obstacle on the path towards clinical implementation. Recently, unsupervised domain adaptation (UDA) methods have attempted to mitigate this problem by incorporating self-training with contrastive learning. To better exploit the underlying semantic information of the image at different levels, we propose a Multi-level Semantic-guided Contrastive Domain Adaptation (MSCDA) framework to align the feature representation between domains. In particular, we extend the contrastive loss by incorporating pixel-to-pixel, pixel-to-centroid, and centroid-to-centroid contrasts to integrate semantic information of images. We utilize a category-wise cross-domain sampling strategy to sample anchors from target images and build a hybrid memory bank to store samples from source images. Two breast MRI datasets were retrospectively collected: The source dataset contains non-contrast MRI examinations from 11 healthy volunteers and the target dataset contains contrast-enhanced MRI examinations of 134 invasive breast cancer patients. We set up experiments from source T2W image to target dynamic contrast-enhanced (DCE)-T1W image (T2W-to-T1W) and from source T1W image to target T2W image (T1W-to-T2W). The proposed method achieved Dice similarity coefficient (DSC) of 89.2\% and 84.0\% in T2W-to-T1W and T1W-to-T2W, respectively, outperforming state-of-the-art methods. Notably, good performance is still achieved with a smaller source dataset, proving that our framework is label-efficient.
IDEAL: Improved DEnse locAL Contrastive Learning for Semi-Supervised Medical Image Segmentation
Oct 26, 2022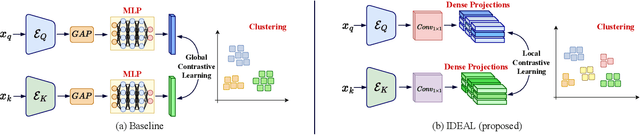
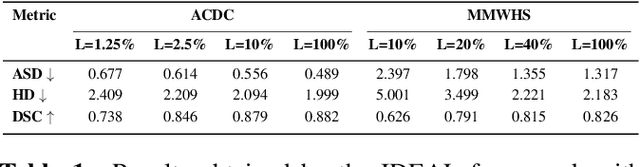
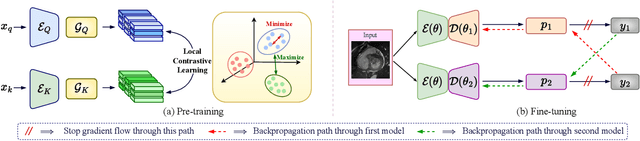
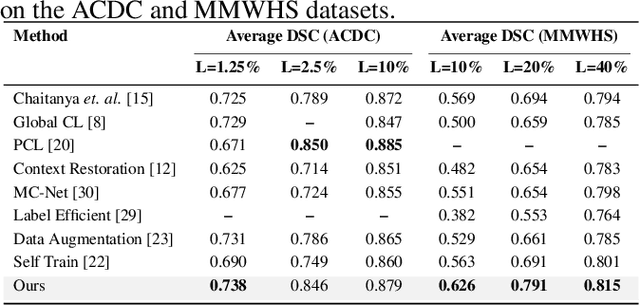
Due to the scarcity of labeled data, Contrastive Self-Supervised Learning (SSL) frameworks have lately shown great potential in several medical image analysis tasks. However, the existing contrastive mechanisms are sub-optimal for dense pixel-level segmentation tasks due to their inability to mine local features. To this end, we extend the concept of metric learning to the segmentation task, using a dense (dis)similarity learning for pre-training a deep encoder network, and employing a semi-supervised paradigm to fine-tune for the downstream task. Specifically, we propose a simple convolutional projection head for obtaining dense pixel-level features, and a new contrastive loss to utilize these dense projections thereby improving the local representations. A bidirectional consistency regularization mechanism involving two-stream model training is devised for the downstream task. Upon comparison, our IDEAL method outperforms the SoTA methods by fair margins on cardiac MRI segmentation.
Learning sparse auto-encoders for green AI image coding
Sep 09, 2022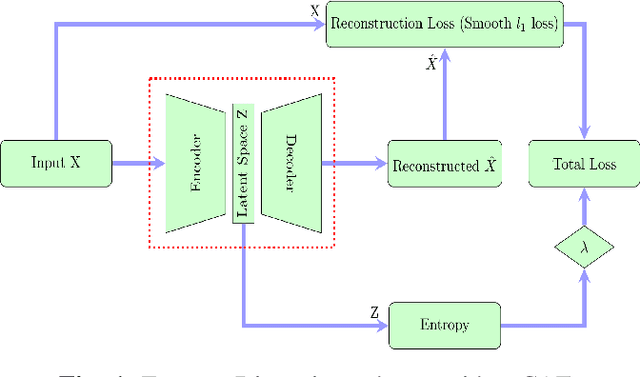
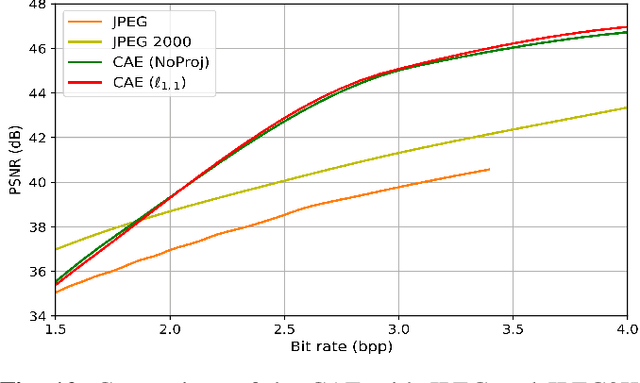
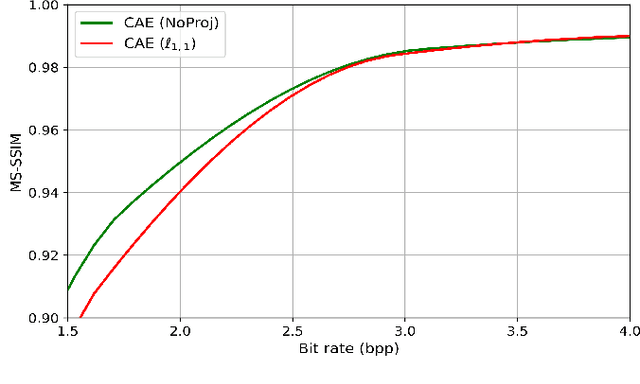

Recently, convolutional auto-encoders (CAE) were introduced for image coding. They achieved performance improvements over the state-of-the-art JPEG2000 method. However, these performances were obtained using massive CAEs featuring a large number of parameters and whose training required heavy computational power.\\ In this paper, we address the problem of lossy image compression using a CAE with a small memory footprint and low computational power usage. In order to overcome the computational cost issue, the majority of the literature uses Lagrangian proximal regularization methods, which are time consuming themselves.\\ In this work, we propose a constrained approach and a new structured sparse learning method. We design an algorithm and test it on three constraints: the classical $\ell_1$ constraint, the $\ell_{1,\infty}$ and the new $\ell_{1,1}$ constraint. Experimental results show that the $\ell_{1,1}$ constraint provides the best structured sparsity, resulting in a high reduction of memory and computational cost, with similar rate-distortion performance as with dense networks.
Retrieval-Augmented Transformer for Image Captioning
Jul 26, 2022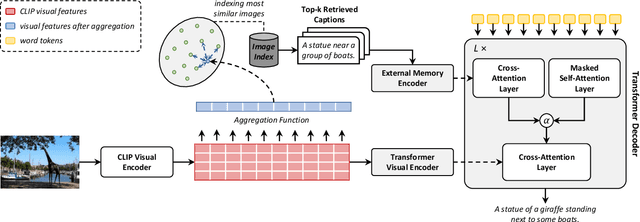

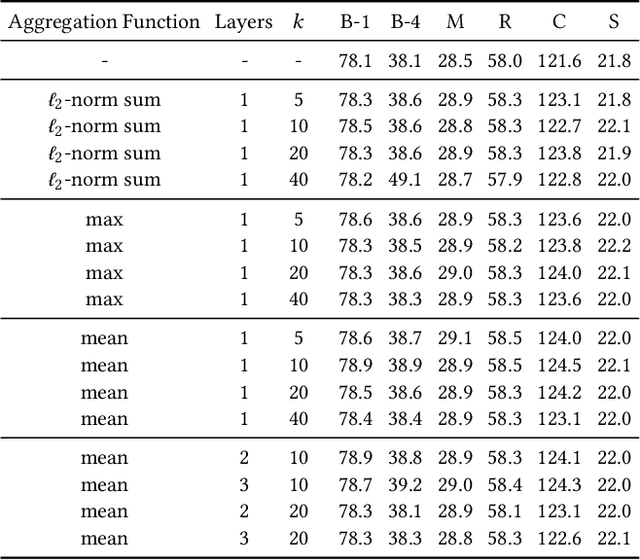
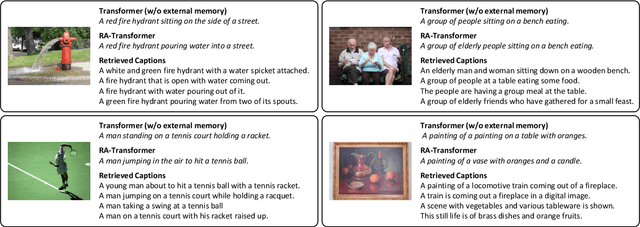
Image captioning models aim at connecting Vision and Language by providing natural language descriptions of input images. In the past few years, the task has been tackled by learning parametric models and proposing visual feature extraction advancements or by modeling better multi-modal connections. In this paper, we investigate the development of an image captioning approach with a kNN memory, with which knowledge can be retrieved from an external corpus to aid the generation process. Our architecture combines a knowledge retriever based on visual similarities, a differentiable encoder, and a kNN-augmented attention layer to predict tokens based on the past context and on text retrieved from the external memory. Experimental results, conducted on the COCO dataset, demonstrate that employing an explicit external memory can aid the generation process and increase caption quality. Our work opens up new avenues for improving image captioning models at larger scale.
CLiNet: Joint Detection of Road Network Centerlines in 2D and 3D
Feb 04, 2023
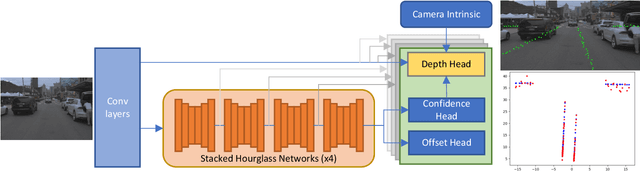

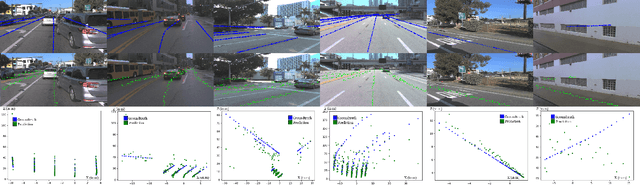
This work introduces a new approach for joint detection of centerlines based on image data by localizing the features jointly in 2D and 3D. In contrast to existing work that focuses on detection of visual cues, we explore feature extraction methods that are directly amenable to the urban driving task. To develop and evaluate our approach, a large urban driving dataset dubbed AV Breadcrumbs is automatically labeled by leveraging vector map representations and projective geometry to annotate over 900,000 images. Our results demonstrate potential for dynamic scene modeling across various urban driving scenarios. Our model achieves an F1 score of 0.684 and an average normalized depth error of 2.083. The code and data annotations are publicly available.