 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
REVEL Framework to measure Local Linear Explanations for black-box models: Deep Learning Image Classification case of study
Nov 11, 2022

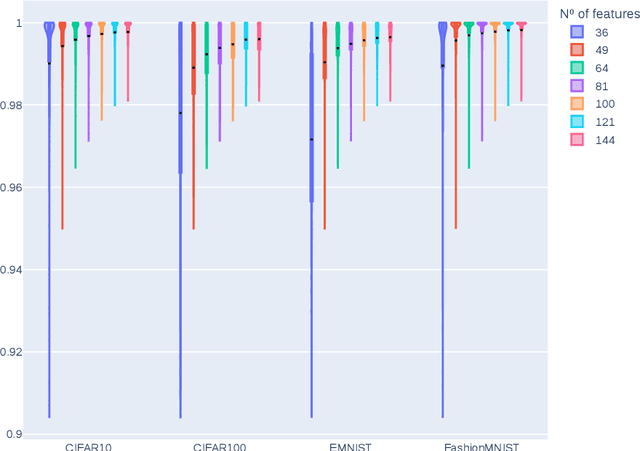

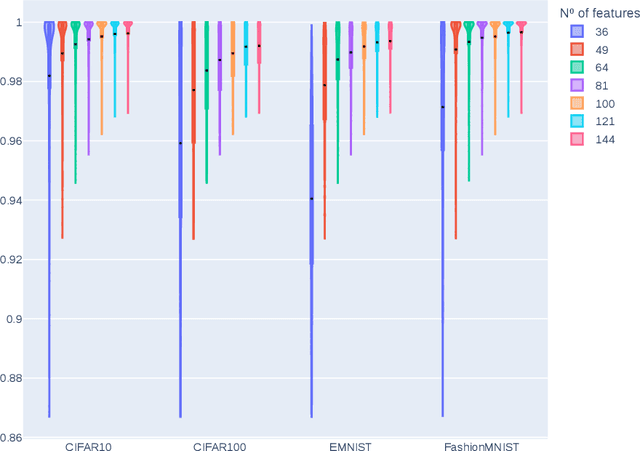
Explainable artificial intelligence is proposed to provide explanations for reasoning performed by an Artificial Intelligence. There is no consensus on how to evaluate the quality of these explanations, since even the definition of explanation itself is not clear in the literature. In particular, for the widely known Local Linear Explanations, there are qualitative proposals for the evaluation of explanations, although they suffer from theoretical inconsistencies. The case of image is even more problematic, where a visual explanation seems to explain a decision while detecting edges is what it really does. There are a large number of metrics in the literature specialized in quantitatively measuring different qualitative aspects so we should be able to develop metrics capable of measuring in a robust and correct way the desirable aspects of the explanations. In this paper, we propose a procedure called REVEL to evaluate different aspects concerning the quality of explanations with a theoretically coherent development. This procedure has several advances in the state of the art: it standardizes the concepts of explanation and develops a series of metrics not only to be able to compare between them but also to obtain absolute information regarding the explanation itself. The experiments have been carried out on image four datasets as benchmark where we show REVEL's descriptive and analytical power.
CMVAE: Causal Meta VAE for Unsupervised Meta-Learning
Feb 20, 2023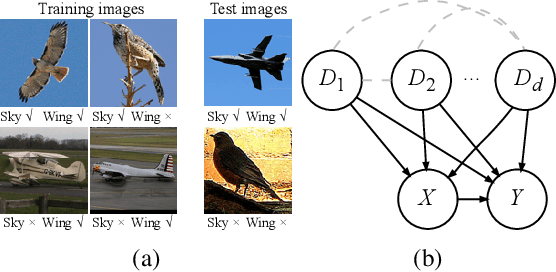
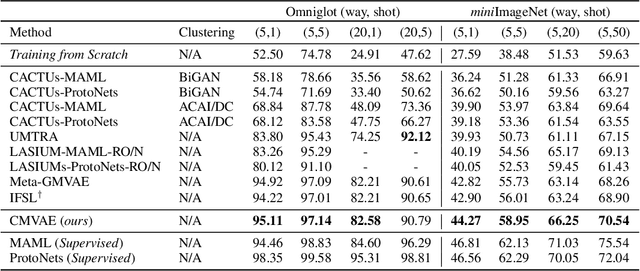
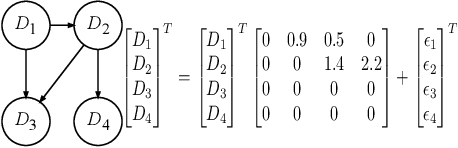
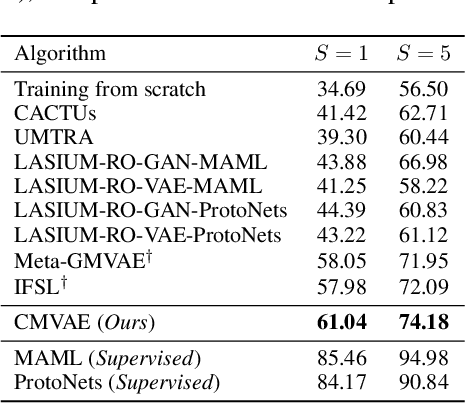
Unsupervised meta-learning aims to learn the meta knowledge from unlabeled data and rapidly adapt to novel tasks. However, existing approaches may be misled by the context-bias (e.g. background) from the training data. In this paper, we abstract the unsupervised meta-learning problem into a Structural Causal Model (SCM) and point out that such bias arises due to hidden confounders. To eliminate the confounders, we define the priors are \textit{conditionally} independent, learn the relationships between priors and intervene on them with casual factorization. Furthermore, we propose Causal Meta VAE (CMVAE) that encodes the priors into latent codes in the causal space and learns their relationships simultaneously to achieve the downstream few-shot image classification task. Results on toy datasets and three benchmark datasets demonstrate that our method can remove the context-bias and it outperforms other state-of-the-art unsupervised meta-learning algorithms because of bias-removal. Code is available at \url{https://github.com/GuodongQi/CMVAE}
A Large Scale Homography Benchmark
Feb 20, 2023


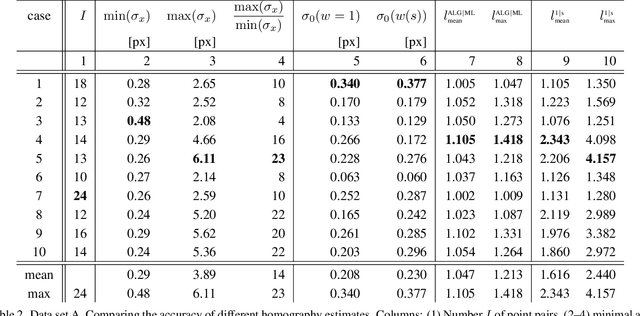
We present a large-scale dataset of Planes in 3D, Pi3D, of roughly 1000 planes observed in 10 000 images from the 1DSfM dataset, and HEB, a large-scale homography estimation benchmark leveraging Pi3D. The applications of the Pi3D dataset are diverse, e.g. training or evaluating monocular depth, surface normal estimation and image matching algorithms. The HEB dataset consists of 226 260 homographies and includes roughly 4M correspondences. The homographies link images that often undergo significant viewpoint and illumination changes. As applications of HEB, we perform a rigorous evaluation of a wide range of robust estimators and deep learning-based correspondence filtering methods, establishing the current state-of-the-art in robust homography estimation. We also evaluate the uncertainty of the SIFT orientations and scales w.r.t. the ground truth coming from the underlying homographies and provide codes for comparing uncertainty of custom detectors. The dataset is available at \url{https://github.com/danini/homography-benchmark}.
CISum: Learning Cross-modality Interaction to Enhance Multimodal Semantic Coverage for Multimodal Summarization
Feb 20, 2023
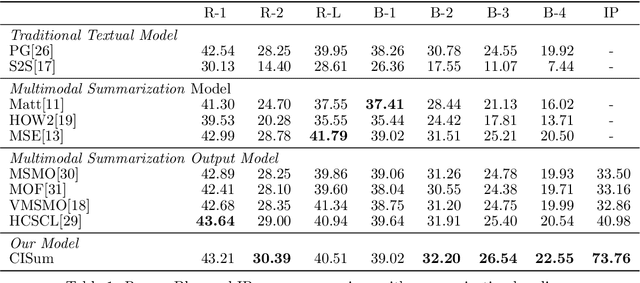
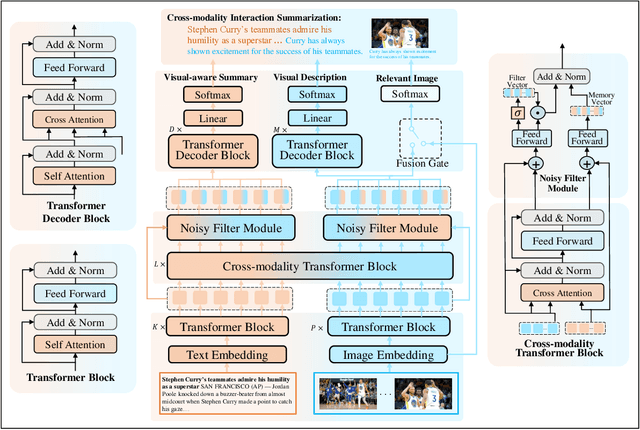
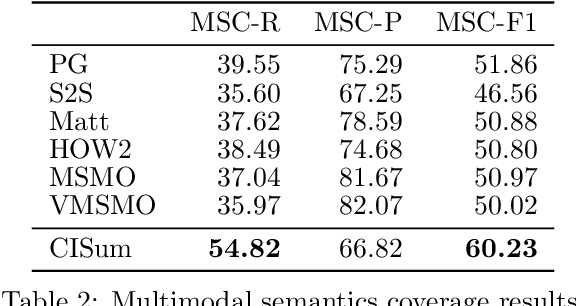
Multimodal summarization (MS) aims to generate a summary from multimodal input. Previous works mainly focus on textual semantic coverage metrics such as ROUGE, which considers the visual content as supplemental data. Therefore, the summary is ineffective to cover the semantics of different modalities. This paper proposes a multi-task cross-modality learning framework (CISum) to improve multimodal semantic coverage by learning the cross-modality interaction in the multimodal article. To obtain the visual semantics, we translate images into visual descriptions based on the correlation with text content. Then, the visual description and text content are fused to generate the textual summary to capture the semantics of the multimodal content, and the most relevant image is selected as the visual summary. Furthermore, we design an automatic multimodal semantics coverage metric to evaluate the performance. Experimental results show that CISum outperforms baselines in multimodal semantics coverage metrics while maintaining the excellent performance of ROUGE and BLEU.
Restoration based Generative Models
Feb 20, 2023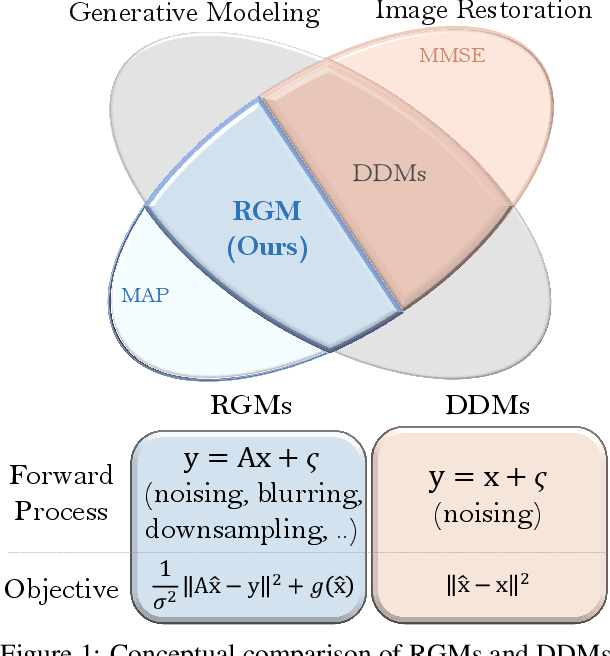
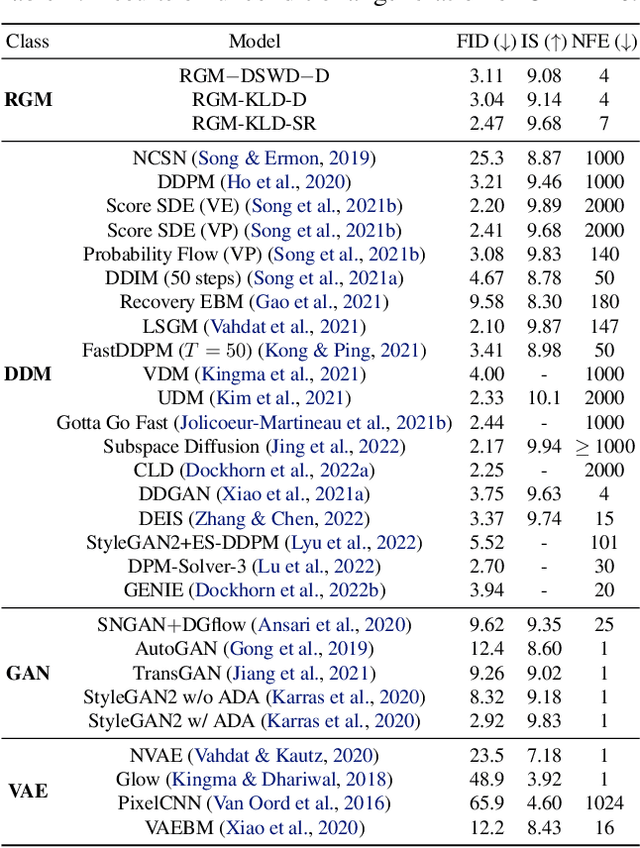

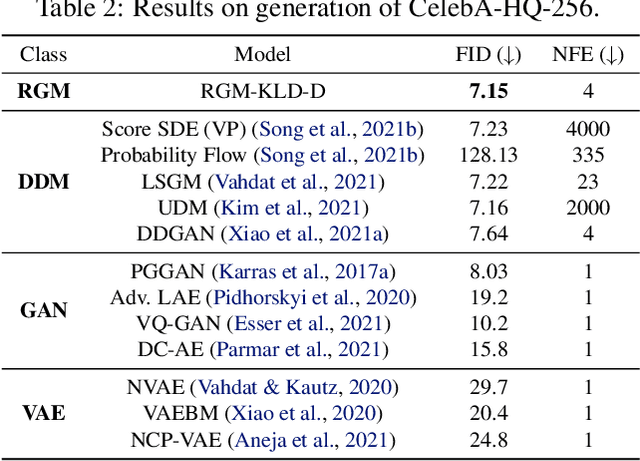
Denoising diffusion models (DDMs) have recently attracted increasing attention by showing impressive synthesis quality. DDMs are built on a diffusion process that pushes data to the noise distribution and the models learn to denoise. In this paper, we establish the interpretation of DDMs in terms of image restoration (IR). Integrating IR literature allows us to use an alternative objective and diverse forward processes, not confining to the diffusion process. By imposing prior knowledge on the loss function grounded on MAP-based estimation, we eliminate the need for the expensive sampling of DDMs. Also, we propose a multi-scale training, which improves the performance compared to the diffusion process, by taking advantage of the flexibility of the forward process. Experimental results demonstrate that our model improves the quality and efficiency of both training and inference. Furthermore, we show the applicability of our model to inverse problems. We believe that our framework paves the way for designing a new type of flexible general generative model.
Novel Machine Learning Approach for Predicting Poverty using Temperature and Remote Sensing Data in Ethiopia
Feb 28, 2023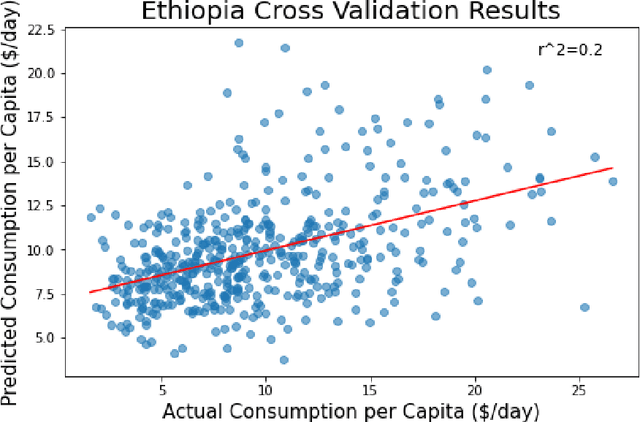
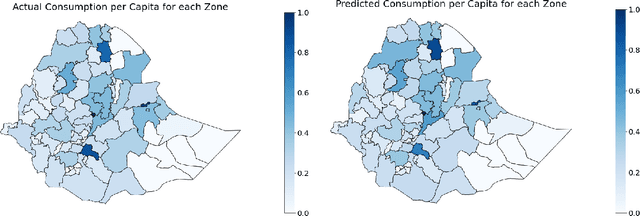
In many developing nations, a lack of poverty data prevents critical humanitarian organizations from responding to large-scale crises. Currently, socioeconomic surveys are the only method implemented on a large scale for organizations and researchers to measure and track poverty. However, the inability to collect survey data efficiently and inexpensively leads to significant temporal gaps in poverty data; these gaps severely limit the ability of organizational entities to address poverty at its root cause. We propose a transfer learning model based on surface temperature change and remote sensing data to extract features useful for predicting poverty rates. Machine learning, supported by data sources of poverty indicators, has the potential to estimate poverty rates accurately and within strict time constraints. Higher temperatures, as a result of climate change, have caused numerous agricultural obstacles, socioeconomic issues, and environmental disruptions, trapping families in developing countries in cycles of poverty. To find patterns of poverty relating to temperature that have the highest influence on spatial poverty rates, we use remote sensing data. The two-step transfer model predicts the temperature delta from high resolution satellite imagery and then extracts image features useful for predicting poverty. The resulting model achieved 80% accuracy on temperature prediction. This method takes advantage of abundant satellite and temperature data to measure poverty in a manner comparable to the existing survey methods and exceeds similar models of poverty prediction.
LogicRank: Logic Induced Reranking for Generative Text-to-Image Systems
Aug 29, 2022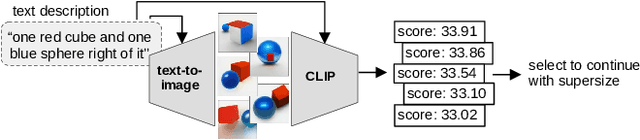
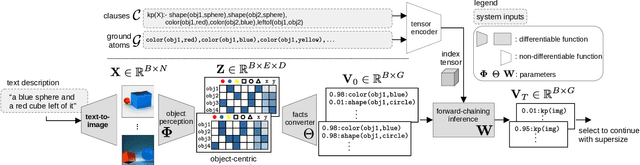
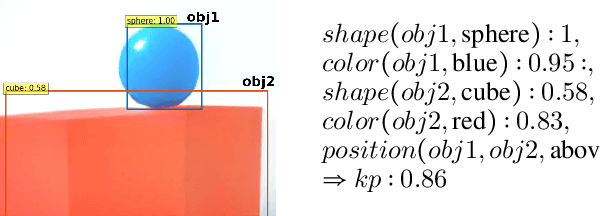
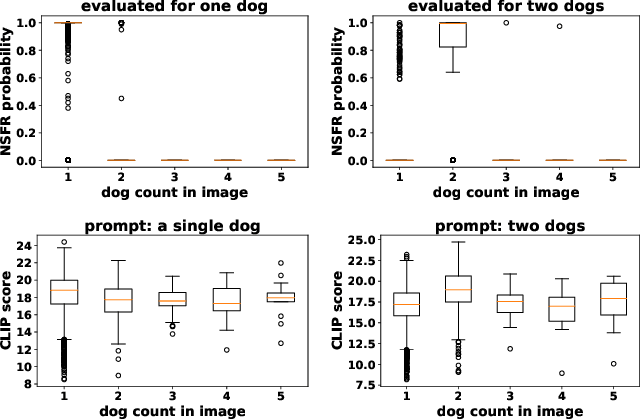
Text-to-image models have recently achieved remarkable success with seemingly accurate samples in photo-realistic quality. However as state-of-the-art language models still struggle evaluating precise statements consistently, so do language model based image generation processes. In this work we showcase problems of state-of-the-art text-to-image models like DALL-E with generating accurate samples from statements related to the draw bench benchmark. Furthermore we show that CLIP is not able to rerank those generated samples consistently. To this end we propose LogicRank, a neuro-symbolic reasoning framework that can result in a more accurate ranking-system for such precision-demanding settings. LogicRank integrates smoothly into the generation process of text-to-image models and moreover can be used to further fine-tune towards a more logical precise model.
Shifted Windows Transformers for Medical Image Quality Assessment
Aug 11, 2022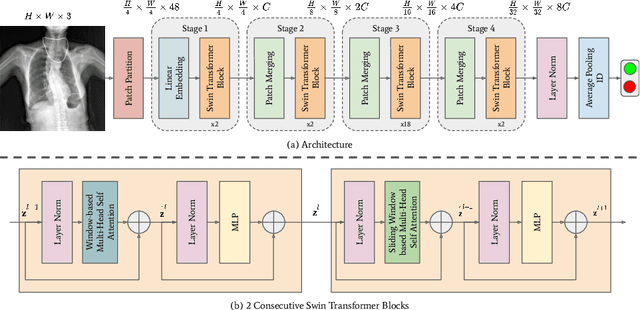

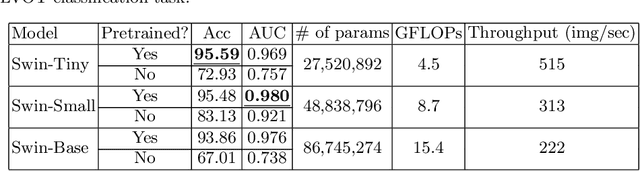
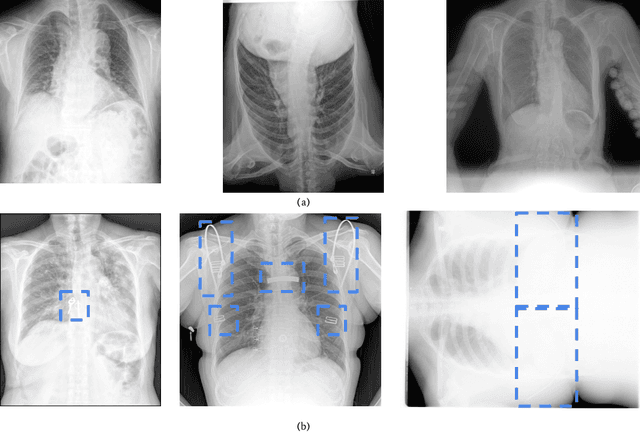
To maintain a standard in a medical imaging study, images should have necessary image quality for potential diagnostic use. Although CNN-based approaches are used to assess the image quality, their performance can still be improved in terms of accuracy. In this work, we approach this problem by using Swin Transformer, which improves the poor-quality image classification performance that causes the degradation in medical image quality. We test our approach on Foreign Object Classification problem on Chest X-Rays (Object-CXR) and Left Ventricular Outflow Tract Classification problem on Cardiac MRI with a four-chamber view (LVOT). While we obtain a classification accuracy of 87.1% and 95.48% on the Object-CXR and LVOT datasets, our experimental results suggest that the use of Swin Transformer improves the Object-CXR classification performance while obtaining a comparable performance for the LVOT dataset. To the best of our knowledge, our study is the first vision transformer application for medical image quality assessment.
Rate-Distortion Optimized Post-Training Quantization for Learned Image Compression
Nov 05, 2022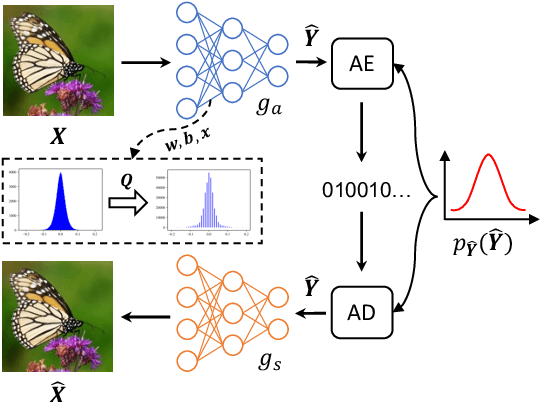
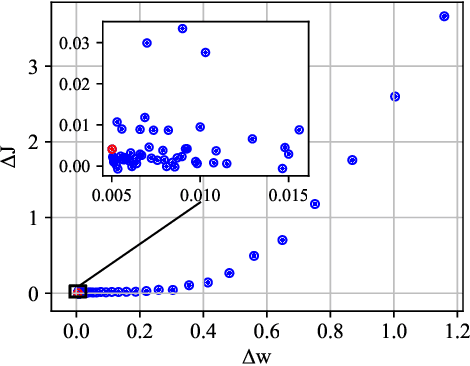
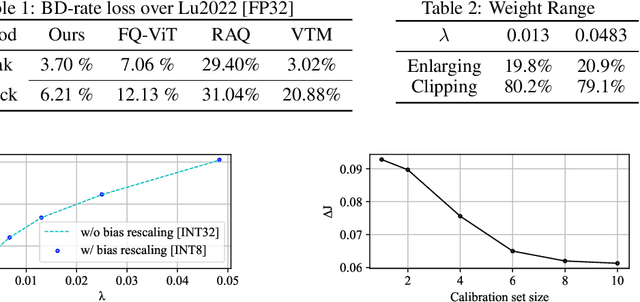
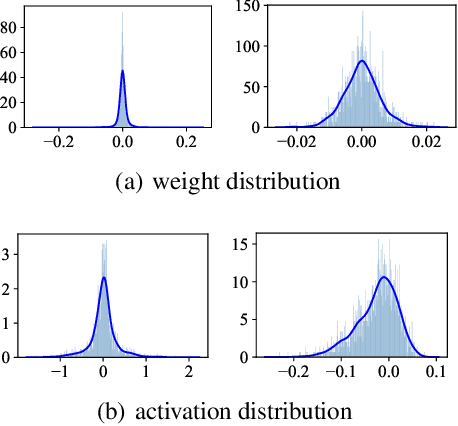
Quantizing floating-point neural network to its fixed-point representation is crucial for Learned Image Compression (LIC) because it ensures the decoding consistency for interoperability and reduces space-time complexity for implementation. Existing solutions often have to retrain the network for model quantization which is time consuming and impractical. This work suggests the use of Post-Training Quantization (PTQ) to directly process pretrained, off-the-shelf LIC models. We theoretically prove that minimizing the mean squared error (MSE) in PTQ is sub-optimal for compression task and thus develop a novel Rate-Distortion (R-D) Optimized PTQ (RDO-PTQ) to best retain the compression performance. Such RDO-PTQ just needs to compress few images (e.g., 10) to optimize the transformation of weight, bias, and activation of underlying LIC model from its native 32-bit floating-point (FP32) format to 8-bit fixed-point (INT8) precision for fixed-point inference onwards. Experiments reveal outstanding efficiency of the proposed method on different LICs, showing the closest coding performance to their floating-point counterparts. And, our method is a lightweight and plug-and-play approach without any need of model retraining which is attractive to practitioners.
Learning Support and Trivial Prototypes for Interpretable Image Classification
Jan 08, 2023

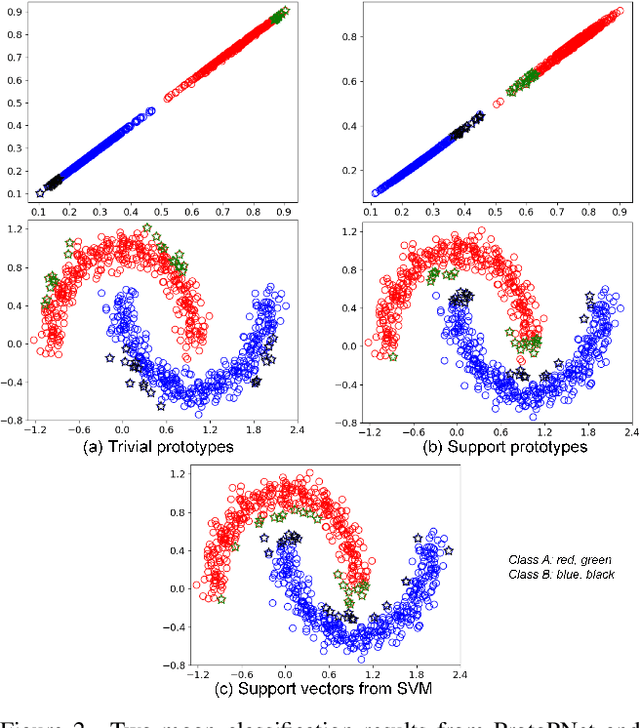

Prototypical part network (ProtoPNet) methods have been designed to achieve interpretable classification by associating predictions with a set of training prototypes, which we refer to as trivial (i.e., easy-to-learn) prototypes because they are trained to lie far from the classification boundary in the feature space. Note that it is possible to make an analogy between ProtoPNet and support vector machine (SVM) given that the classification from both methods relies on computing similarity with a set of training points (i.e., trivial prototypes in ProtoPNet, and support vectors in SVM). However, while trivial prototypes are located far from the classification boundary, support vectors are located close to this boundary, and we argue that this discrepancy with the well-established SVM theory can result in ProtoPNet models with suboptimal classification accuracy. In this paper, we aim to improve the classification accuracy of ProtoPNet with a new method to learn support prototypes that lie near the classification boundary in the feature space, as suggested by the SVM theory. In addition, we target the improvement of classification interpretability with a new model, named ST-ProtoPNet, which exploits our support prototypes and the trivial prototypes to provide complementary interpretability information. Experimental results on CUB-200-2011, Stanford Cars, and Stanford Dogs datasets demonstrate that the proposed method achieves state-of-the-art classification accuracy and produces more visually meaningful and diverse prototypes.