 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Retina Vision Transformer (RetinaViT): Introducing Scaled Patches into Vision Transformers
Mar 20, 2024

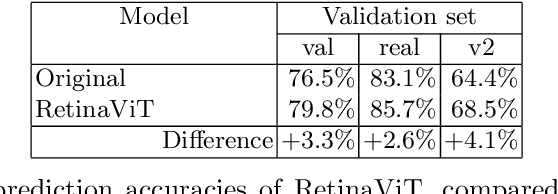
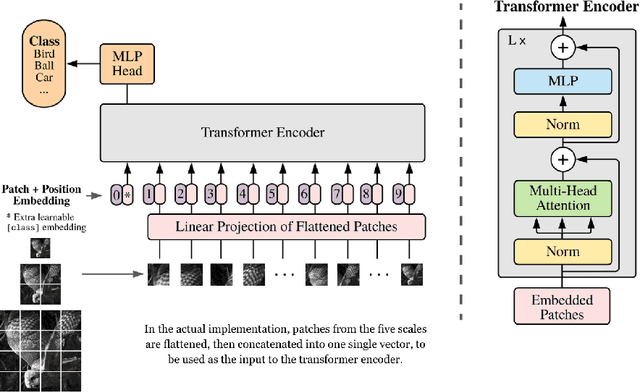
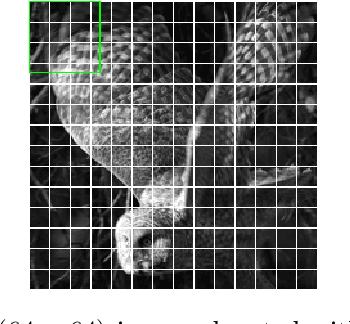
Humans see low and high spatial frequency components at the same time, and combine the information from both to form a visual scene. Drawing on this neuroscientific inspiration, we propose an altered Vision Transformer architecture where patches from scaled down versions of the input image are added to the input of the first Transformer Encoder layer. We name this model Retina Vision Transformer (RetinaViT) due to its inspiration from the human visual system. Our experiments show that when trained on the ImageNet-1K dataset with a moderate configuration, RetinaViT achieves a 3.3% performance improvement over the original ViT. We hypothesize that this improvement can be attributed to the inclusion of low spatial frequency components in the input, which improves the ability to capture structural features, and to select and forward important features to deeper layers. RetinaViT thereby opens doors to further investigations into vertical pathways and attention patterns.
Boosting Flow-based Generative Super-Resolution Models via Learned Prior
Mar 16, 2024
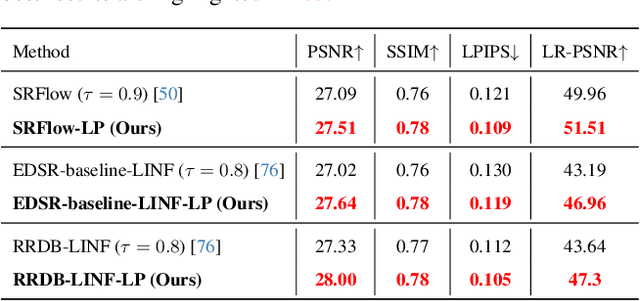

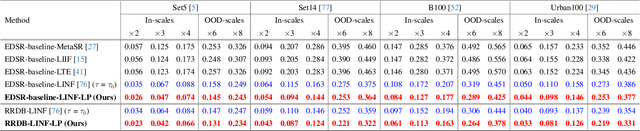
Flow-based super-resolution (SR) models have demonstrated astonishing capabilities in generating high-quality images. However, these methods encounter several challenges during image generation, such as grid artifacts, exploding inverses, and suboptimal results due to a fixed sampling temperature. To overcome these issues, this work introduces a conditional learned prior to the inference phase of a flow-based SR model. This prior is a latent code predicted by our proposed latent module conditioned on the low-resolution image, which is then transformed by the flow model into an SR image. Our framework is designed to seamlessly integrate with any contemporary flow-based SR model without modifying its architecture or pre-trained weights. We evaluate the effectiveness of our proposed framework through extensive experiments and ablation analyses. The proposed framework successfully addresses all the inherent issues in flow-based SR models and enhances their performance in various SR scenarios. Our code is available at: https://github.com/liyuantsao/FlowSR-LP
Adversarial Testing for Visual Grounding via Image-Aware Property Reduction
Mar 02, 2024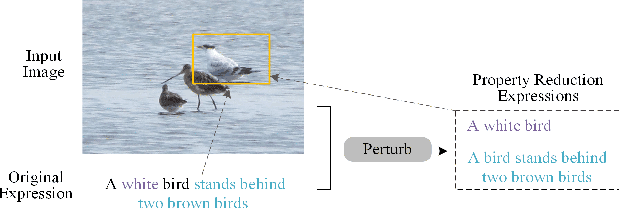

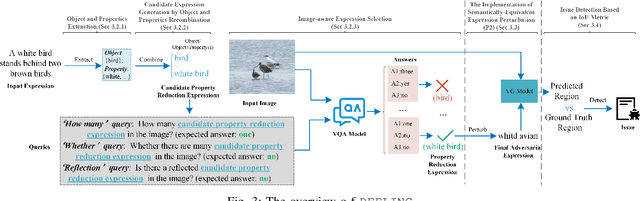

Due to the advantages of fusing information from various modalities, multimodal learning is gaining increasing attention. Being a fundamental task of multimodal learning, Visual Grounding (VG), aims to locate objects in images through natural language expressions. Ensuring the quality of VG models presents significant challenges due to the complex nature of the task. In the black box scenario, existing adversarial testing techniques often fail to fully exploit the potential of both modalities of information. They typically apply perturbations based solely on either the image or text information, disregarding the crucial correlation between the two modalities, which would lead to failures in test oracles or an inability to effectively challenge VG models. To this end, we propose PEELING, a text perturbation approach via image-aware property reduction for adversarial testing of the VG model. The core idea is to reduce the property-related information in the original expression meanwhile ensuring the reduced expression can still uniquely describe the original object in the image. To achieve this, PEELING first conducts the object and properties extraction and recombination to generate candidate property reduction expressions. It then selects the satisfied expressions that accurately describe the original object while ensuring no other objects in the image fulfill the expression, through querying the image with a visual understanding technique. We evaluate PEELING on the state-of-the-art VG model, i.e. OFA-VG, involving three commonly used datasets. Results show that the adversarial tests generated by PEELING achieves 21.4% in MultiModal Impact score (MMI), and outperforms state-of-the-art baselines for images and texts by 8.2%--15.1%.
LightIt: Illumination Modeling and Control for Diffusion Models
Mar 15, 2024
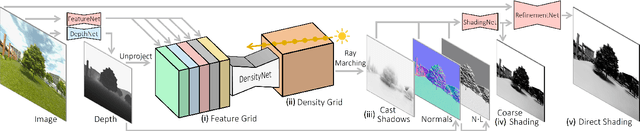

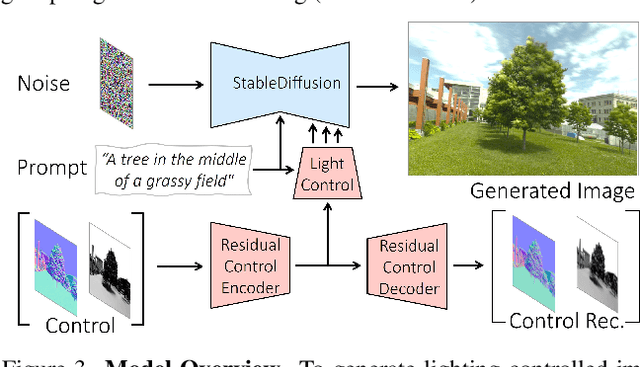
We introduce LightIt, a method for explicit illumination control for image generation. Recent generative methods lack lighting control, which is crucial to numerous artistic aspects of image generation such as setting the overall mood or cinematic appearance. To overcome these limitations, we propose to condition the generation on shading and normal maps. We model the lighting with single bounce shading, which includes cast shadows. We first train a shading estimation module to generate a dataset of real-world images and shading pairs. Then, we train a control network using the estimated shading and normals as input. Our method demonstrates high-quality image generation and lighting control in numerous scenes. Additionally, we use our generated dataset to train an identity-preserving relighting model, conditioned on an image and a target shading. Our method is the first that enables the generation of images with controllable, consistent lighting and performs on par with specialized relighting state-of-the-art methods.
BlendScape: Enabling Unified and Personalized Video-Conferencing Environments through Generative AI
Mar 20, 2024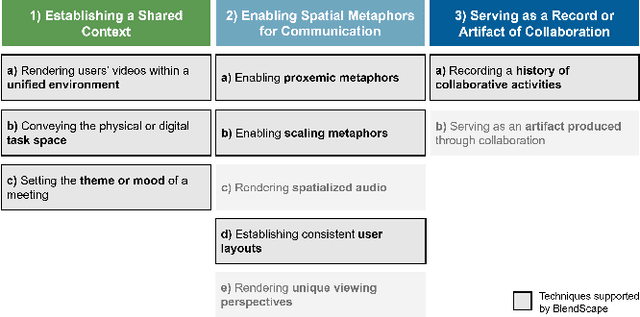

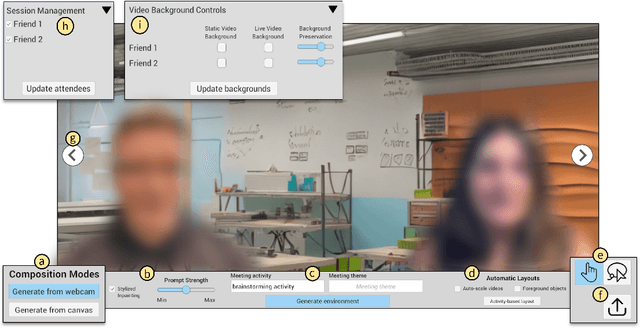

Today's video-conferencing tools support a rich range of professional and social activities, but their generic, grid-based environments cannot be easily adapted to meet the varying needs of distributed collaborators. To enable end-user customization, we developed BlendScape, a system for meeting participants to compose video-conferencing environments tailored to their collaboration context by leveraging AI image generation techniques. BlendScape supports flexible representations of task spaces by blending users' physical or virtual backgrounds into unified environments and implements multimodal interaction techniques to steer the generation. Through an evaluation with 15 end-users, we investigated their customization preferences for work and social scenarios. Participants could rapidly express their design intentions with BlendScape and envisioned using the system to structure collaboration in future meetings, but experienced challenges with preventing distracting elements. We implement scenarios to demonstrate BlendScape's expressiveness in supporting distributed collaboration techniques from prior work and propose composition techniques to improve the quality of environments.
Embedding Pose Graph, Enabling 3D Foundation Model Capabilities with a Compact Representation
Mar 20, 2024

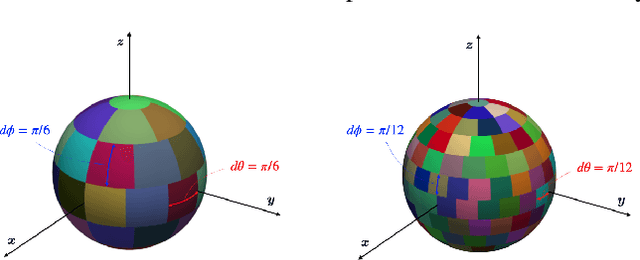
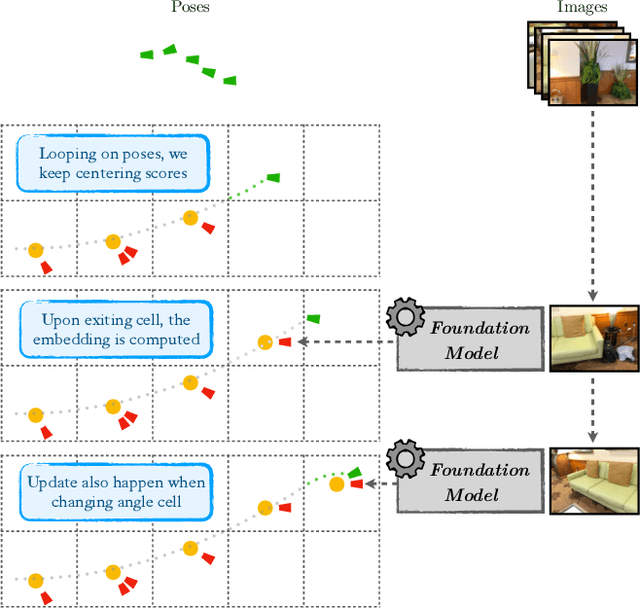
This paper presents the Embedding Pose Graph (EPG), an innovative method that combines the strengths of foundation models with a simple 3D representation suitable for robotics applications. Addressing the need for efficient spatial understanding in robotics, EPG provides a compact yet powerful approach by attaching foundation model features to the nodes of a pose graph. Unlike traditional methods that rely on bulky data formats like voxel grids or point clouds, EPG is lightweight and scalable. It facilitates a range of robotic tasks, including open-vocabulary querying, disambiguation, image-based querying, language-directed navigation, and re-localization in 3D environments. We showcase the effectiveness of EPG in handling these tasks, demonstrating its capacity to improve how robots interact with and navigate through complex spaces. Through both qualitative and quantitative assessments, we illustrate EPG's strong performance and its ability to outperform existing methods in re-localization. Our work introduces a crucial step forward in enabling robots to efficiently understand and operate within large-scale 3D spaces.
MEDBind: Unifying Language and Multimodal Medical Data Embeddings
Mar 20, 2024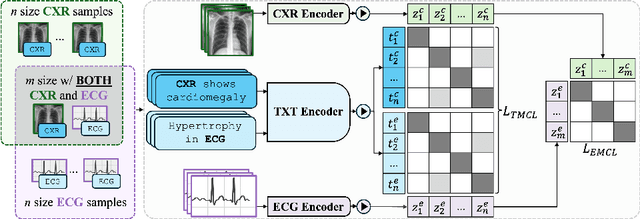

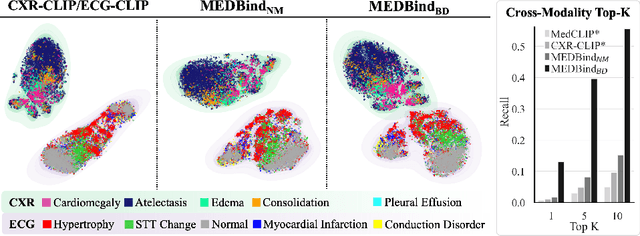
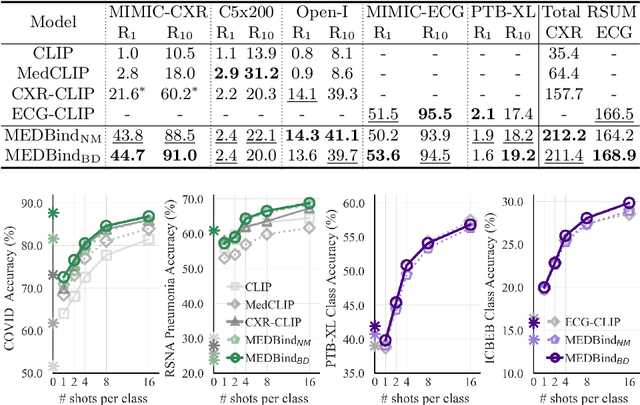
Medical vision-language pretraining models (VLPM) have achieved remarkable progress in fusing chest X-rays (CXR) with clinical texts, introducing image-text data binding approaches that enable zero-shot learning and downstream clinical tasks. However, the current landscape lacks the holistic integration of additional medical modalities, such as electrocardiograms (ECG). We present MEDBind (Medical Electronic patient recorD), which learns joint embeddings across CXR, ECG, and medical text. Using text data as the central anchor, MEDBind features tri-modality binding, delivering competitive performance in top-K retrieval, zero-shot, and few-shot benchmarks against established VLPM, and the ability for CXR-to-ECG zero-shot classification and retrieval. This seamless integration is achieved through combination of contrastive loss on modality-text pairs with our proposed contrastive loss function, Edge-Modality Contrastive Loss, fostering a cohesive embedding space for CXR, ECG, and text. Finally, we demonstrate that MEDBind can improve downstream tasks by directly integrating CXR and ECG embeddings into a large-language model for multimodal prompt tuning.
Cell Tracking in C. elegans with Cell Position Heatmap-Based Alignment and Pairwise Detection
Mar 20, 2024
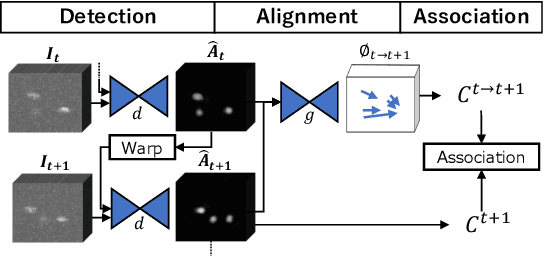
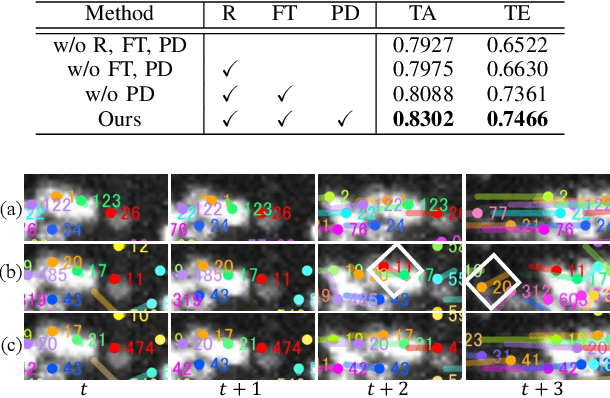

3D cell tracking in a living organism has a crucial role in live cell image analysis. Cell tracking in C. elegans has two difficulties. First, cell migration in a consecutive frame is large since they move their head during scanning. Second, cell detection is often inconsistent in consecutive frames due to touching cells and low-contrast images, and these inconsistent detections affect the tracking performance worse. In this paper, we propose a cell tracking method to address these issues, which has two main contributions. First, we introduce cell position heatmap-based non-rigid alignment with test-time fine-tuning, which can warp the detected points to near the positions at the next frame. Second, we propose a pairwise detection method, which uses the information of detection results at the previous frame for detecting cells at the current frame. The experimental results demonstrate the effectiveness of each module, and the proposed method achieved the best performance in comparison.
Nellie: Automated organelle segmentation, tracking, and hierarchical feature extraction in 2D/3D live-cell microscopy
Mar 20, 2024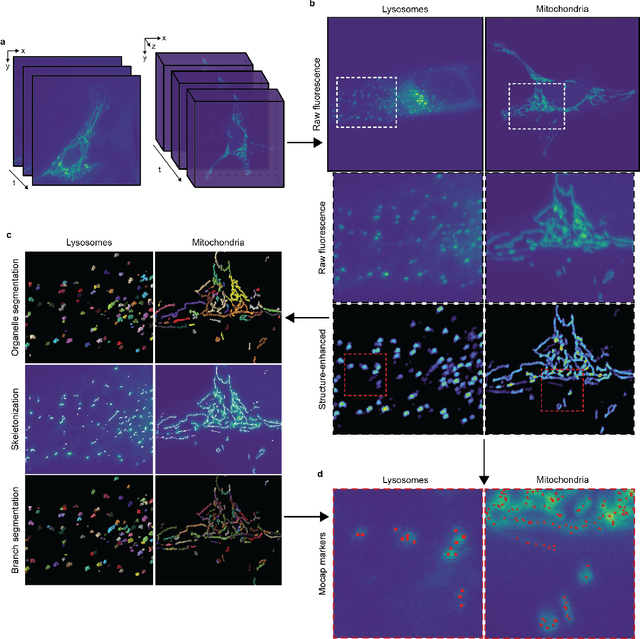
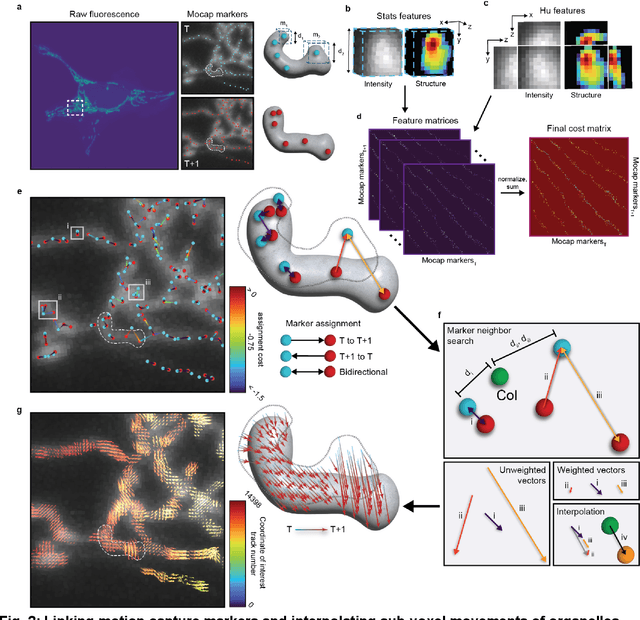
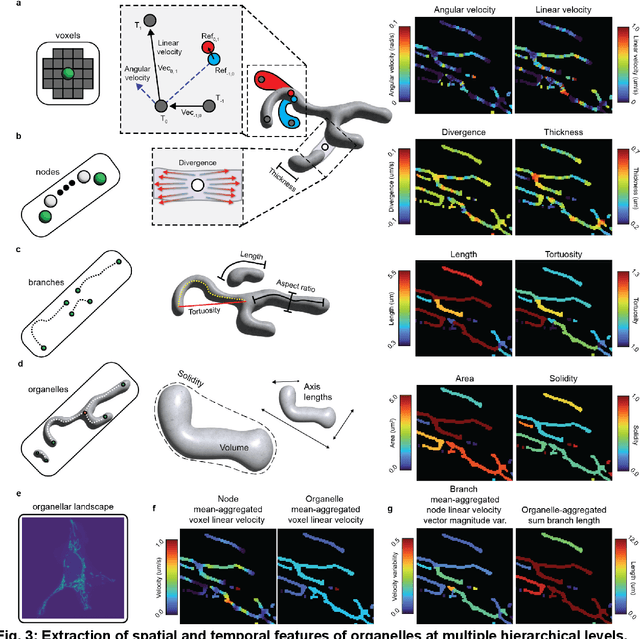
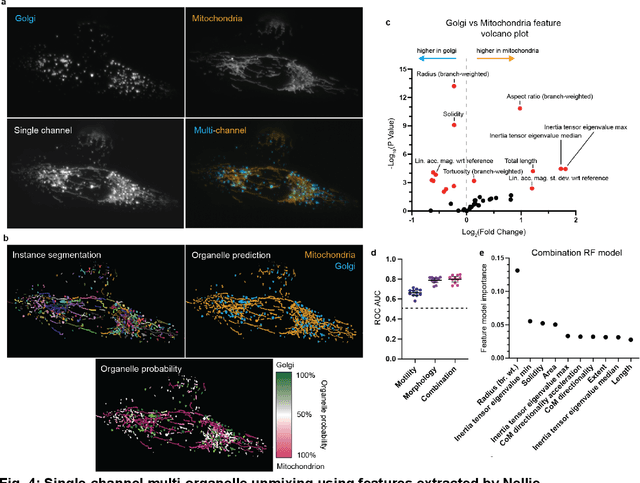
The analysis of dynamic organelles remains a formidable challenge, though key to understanding biological processes. We introduce Nellie, an automated and unbiased pipeline for segmentation, tracking, and feature extraction of diverse intracellular structures. Nellie adapts to image metadata, eliminating user input. Nellie's preprocessing pipeline enhances structural contrast on multiple intracellular scales allowing for robust hierarchical segmentation of sub-organellar regions. Internal motion capture markers are generated and tracked via a radius-adaptive pattern matching scheme, and used as guides for sub-voxel flow interpolation. Nellie extracts a plethora of features at multiple hierarchical levels for deep and customizable analysis. Nellie features a Napari-based GUI that allows for code-free operation and visualization, while its modular open-source codebase invites customization by experienced users. We demonstrate Nellie's wide variety of use cases with two examples: unmixing multiple organelles from a single channel using feature-based classification and training an unsupervised graph autoencoder on mitochondrial multi-mesh graphs to quantify latent space embedding changes following ionomycin treatment.
Text-to-3D Shape Generation
Mar 20, 2024

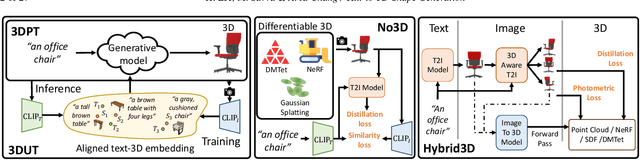
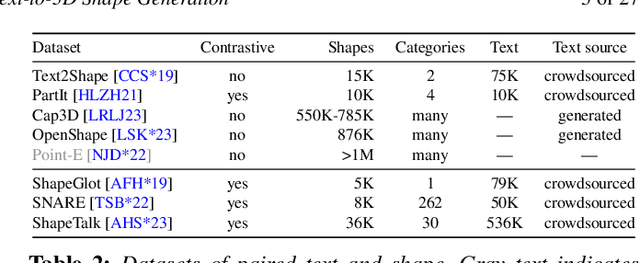
Recent years have seen an explosion of work and interest in text-to-3D shape generation. Much of the progress is driven by advances in 3D representations, large-scale pretraining and representation learning for text and image data enabling generative AI models, and differentiable rendering. Computational systems that can perform text-to-3D shape generation have captivated the popular imagination as they enable non-expert users to easily create 3D content directly from text. However, there are still many limitations and challenges remaining in this problem space. In this state-of-the-art report, we provide a survey of the underlying technology and methods enabling text-to-3D shape generation to summarize the background literature. We then derive a systematic categorization of recent work on text-to-3D shape generation based on the type of supervision data required. Finally, we discuss limitations of the existing categories of methods, and delineate promising directions for future work.