 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Object Advertisement Creative Generation
Mar 14, 2026Lifestyle images are photographs that capture environments and objects in everyday settings. In furniture product marketing, advertisers often create lifestyle images containing products to resonate with potential buyers, allowing buyers to visualize how the products fit into their daily lives. While recent advances in Generative Artificial Intelligence (GenAI) have given rise to realistic image content creation, their application in e-commerce advertising is challenging because high-quality ads must authentically representing the products in realistic scearios. Therefore, manual intervention is usually required for individual generations, making it difficult to scale to larger product catalogs. To understand the challenges faced by advertisers using GenAI to create lifestyle images at scale, we conducted evaluations on ad images generated using state-of-the-art image generation models and identified the major challenges. Based on our findings, we present CreativeAds, a multi-product ad creation system that supports scalable automated generation with customized parameter adjustment for individual generation. To ensure automated high-quality ad generation, CreativeAds innovates a pipeline that consists of three modules to address challenges in product pairing, layout generation, and background generation separately. Furthermore, CreativeAds contains an intuitive user interface to allow users to oversee generation at scale, and it also supports detailed controls on individual generation for user customized adjustments. We performed a user study on CreativeAds and extensive evaluations of the generated images, demonstrating CreativeAds's ability to create large number of high-quality images at scale for advertisers without requiring expertise in GenAI tools.
MineNPC-Task: Task Suite for Memory-Aware Minecraft Agents
Jan 08, 2026We present \textsc{MineNPC-Task}, a user-authored benchmark and evaluation harness for testing memory-aware, mixed-initiative LLM agents in open-world \emph{Minecraft}. Rather than relying on synthetic prompts, tasks are elicited from formative and summative co-play with expert players, normalized into parametric templates with explicit preconditions and dependency structure, and paired with machine-checkable validators under a bounded-knowledge policy that forbids out-of-world shortcuts. The harness captures plan/act/memory events-including plan previews, targeted clarifications, memory reads and writes, precondition checks, and repair attempts and reports outcomes relative to the total number of attempted subtasks, derived from in-world evidence. As an initial snapshot, we instantiate the framework with GPT-4o and evaluate \textbf{216} subtasks across \textbf{8} experienced players. We observe recurring breakdown patterns in code execution, inventory/tool handling, referencing, and navigation, alongside recoveries supported by mixed-initiative clarifications and lightweight memory. Participants rated interaction quality and interface usability positively, while highlighting the need for stronger memory persistence across tasks. We release the complete task suite, validators, logs, and harness to support transparent, reproducible evaluation of future memory-aware embodied agents.
Out of Sight, Not Out of Context? Egocentric Spatial Reasoning in VLMs Across Disjoint Frames
May 30, 2025



An embodied AI assistant operating on egocentric video must integrate spatial cues across time - for instance, determining where an object A, glimpsed a few moments ago lies relative to an object B encountered later. We introduce Disjoint-3DQA , a generative QA benchmark that evaluates this ability of VLMs by posing questions about object pairs that are not co-visible in the same frame. We evaluated seven state-of-the-art VLMs and found that models lag behind human performance by 28%, with steeper declines in accuracy (60% to 30 %) as the temporal gap widens. Our analysis further reveals that providing trajectories or bird's-eye-view projections to VLMs results in only marginal improvements, whereas providing oracle 3D coordinates leads to a substantial 20% performance increase. This highlights a core bottleneck of multi-frame VLMs in constructing and maintaining 3D scene representations over time from visual signals. Disjoint-3DQA therefore sets a clear, measurable challenge for long-horizon spatial reasoning and aims to catalyze future research at the intersection of vision, language, and embodied AI.
Grounding Task Assistance with Multimodal Cues from a Single Demonstration
May 02, 2025



A person's demonstration often serves as a key reference for others learning the same task. However, RGB video, the dominant medium for representing these demonstrations, often fails to capture fine-grained contextual cues such as intent, safety-critical environmental factors, and subtle preferences embedded in human behavior. This sensory gap fundamentally limits the ability of Vision Language Models (VLMs) to reason about why actions occur and how they should adapt to individual users. To address this, we introduce MICA (Multimodal Interactive Contextualized Assistance), a framework that improves conversational agents for task assistance by integrating eye gaze and speech cues. MICA segments demonstrations into meaningful sub-tasks and extracts keyframes and captions that capture fine-grained intent and user-specific cues, enabling richer contextual grounding for visual question answering. Evaluations on questions derived from real-time chat-assisted task replication show that multimodal cues significantly improve response quality over frame-based retrieval. Notably, gaze cues alone achieves 93% of speech performance, and their combination yields the highest accuracy. Task type determines the effectiveness of implicit (gaze) vs. explicit (speech) cues, underscoring the need for adaptable multimodal models. These results highlight the limitations of frame-based context and demonstrate the value of multimodal signals for real-world AI task assistance.
SpaceBlender: Creating Context-Rich Collaborative Spaces Through Generative 3D Scene Blending
Sep 20, 2024There is increased interest in using generative AI to create 3D spaces for Virtual Reality (VR) applications. However, today's models produce artificial environments, falling short of supporting collaborative tasks that benefit from incorporating the user's physical context. To generate environments that support VR telepresence, we introduce SpaceBlender, a novel pipeline that utilizes generative AI techniques to blend users' physical surroundings into unified virtual spaces. This pipeline transforms user-provided 2D images into context-rich 3D environments through an iterative process consisting of depth estimation, mesh alignment, and diffusion-based space completion guided by geometric priors and adaptive text prompts. In a preliminary within-subjects study, where 20 participants performed a collaborative VR affinity diagramming task in pairs, we compared SpaceBlender with a generic virtual environment and a state-of-the-art scene generation framework, evaluating its ability to create virtual spaces suitable for collaboration. Participants appreciated the enhanced familiarity and context provided by SpaceBlender but also noted complexities in the generative environments that could detract from task focus. Drawing on participant feedback, we propose directions for improving the pipeline and discuss the value and design of blended spaces for different scenarios.
BlendScape: Enabling Unified and Personalized Video-Conferencing Environments through Generative AI
Mar 20, 2024Today's video-conferencing tools support a rich range of professional and social activities, but their generic, grid-based environments cannot be easily adapted to meet the varying needs of distributed collaborators. To enable end-user customization, we developed BlendScape, a system for meeting participants to compose video-conferencing environments tailored to their collaboration context by leveraging AI image generation techniques. BlendScape supports flexible representations of task spaces by blending users' physical or virtual backgrounds into unified environments and implements multimodal interaction techniques to steer the generation. Through an evaluation with 15 end-users, we investigated their customization preferences for work and social scenarios. Participants could rapidly express their design intentions with BlendScape and envisioned using the system to structure collaboration in future meetings, but experienced challenges with preventing distracting elements. We implement scenarios to demonstrate BlendScape's expressiveness in supporting distributed collaboration techniques from prior work and propose composition techniques to improve the quality of environments.
Dynamic Task Execution using Active Parameter Identification with the Baxter Research Robot
Sep 11, 2017



This paper presents experimental results from real-time parameter estimation of a system model and subsequent trajectory optimization for a dynamic task using the Baxter Research Robot from Rethink Robotics. An active estimator maximizing Fisher information is used in real-time with a closed-loop, non-linear control technique known as Sequential Action Control. Baxter is tasked with estimating the length of a string connected to a load suspended from the gripper with a load cell providing the single source of feedback to the estimator. Following the active estimation, a trajectory is generated using the trep software package that controls Baxter to dynamically swing a suspended load into a box. Several trials are presented with varying initial estimates showing that estimation is required to obtain adequate open-loop trajectories to complete the prescribed task. The result of one trial with and without the active estimation is also shown in the accompanying video.
* 7 pages
Trajectory Synthesis for Fisher Information Maximization
Sep 11, 2017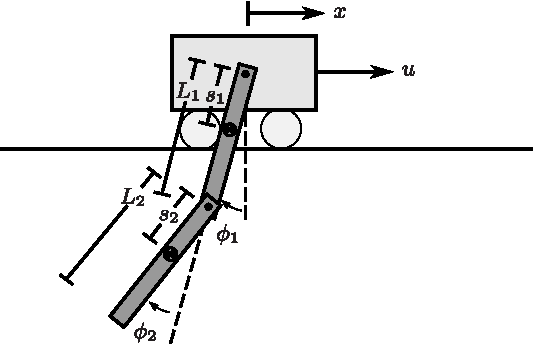

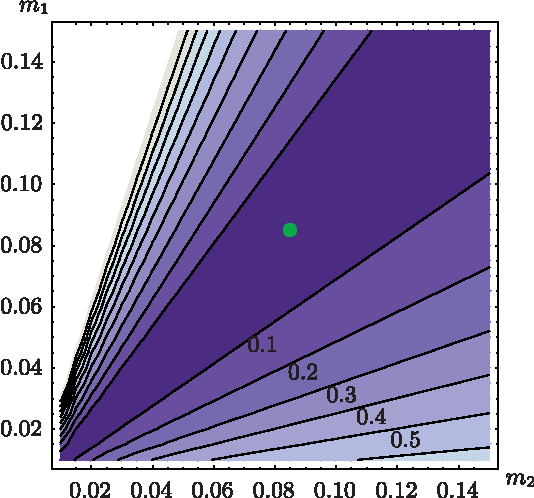
Estimation of model parameters in a dynamic system can be significantly improved with the choice of experimental trajectory. For general, nonlinear dynamic systems, finding globally "best" trajectories is typically not feasible; however, given an initial estimate of the model parameters and an initial trajectory, we present a continuous-time optimization method that produces a locally optimal trajectory for parameter estimation in the presence of measurement noise. The optimization algorithm is formulated to find system trajectories that improve a norm on the Fisher information matrix. A double-pendulum cart apparatus is used to numerically and experimentally validate this technique. In simulation, the optimized trajectory increases the minimum eigenvalue of the Fisher information matrix by three orders of magnitude compared to the initial trajectory. Experimental results show that this optimized trajectory translates to an order of magnitude improvement in the parameter estimate error in practice.
* 12 pages