 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SwinVFTR: A Novel Volumetric Feature-learning Transformer for 3D OCT Fluid Segmentation
Mar 17, 2023
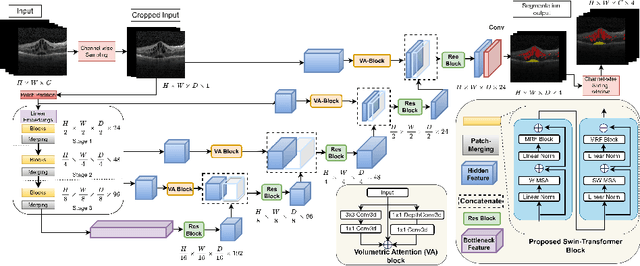
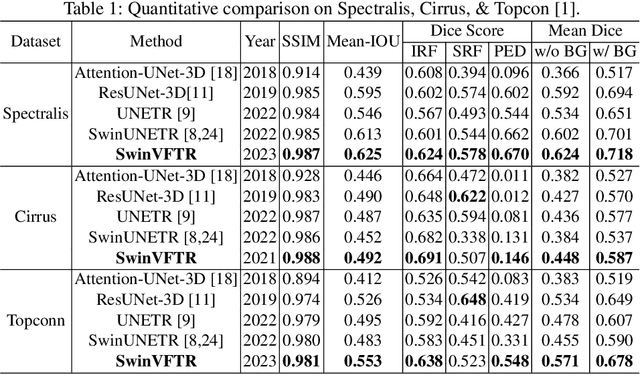
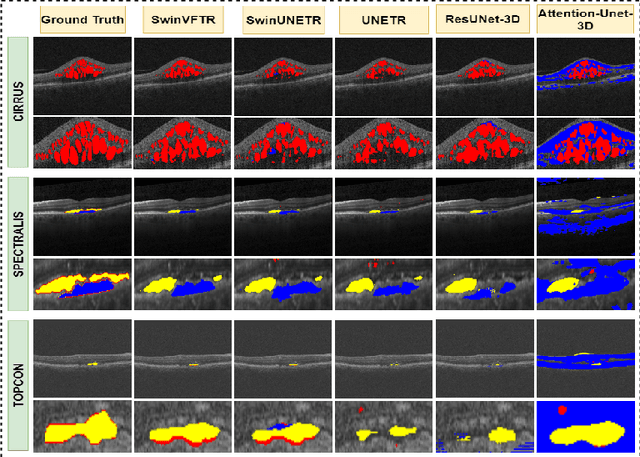
Accurately segmenting fluid in 3D volumetric optical coherence tomography (OCT) images is a crucial yet challenging task for detecting eye diseases. Traditional autoencoding-based segmentation approaches have limitations in extracting fluid regions due to successive resolution loss in the encoding phase and the inability to recover lost information in the decoding phase. Although current transformer-based models for medical image segmentation addresses this limitation, they are not designed to be applied out-of-the-box for 3D OCT volumes, which have a wide-ranging channel-axis size based on different vendor device and extraction technique. To address these issues, we propose SwinVFTR, a new transformer-based architecture designed for precise fluid segmentation in 3D volumetric OCT images. We first utilize a channel-wise volumetric sampling for training on OCT volumes with varying depths (B-scans). Next, the model uses a novel shifted window transformer block in the encoder to achieve better localization and segmentation of fluid regions. Additionally, we propose a new volumetric attention block for spatial and depth-wise attention, which improves upon traditional residual skip connections. Consequently, utilizing multi-class dice loss, the proposed architecture outperforms other existing architectures on the three publicly available vendor-specific OCT datasets, namely Spectralis, Cirrus, and Topcon, with mean dice scores of 0.72, 0.59, and 0.68, respectively. Additionally, SwinVFTR outperforms other architectures in two additional relevant metrics, mean intersection-over-union (Mean-IOU) and structural similarity measure (SSIM).
Multi-stage image denoising with the wavelet transform
Sep 27, 2022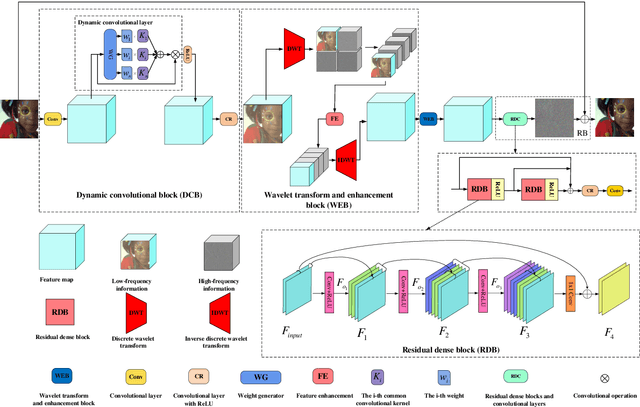
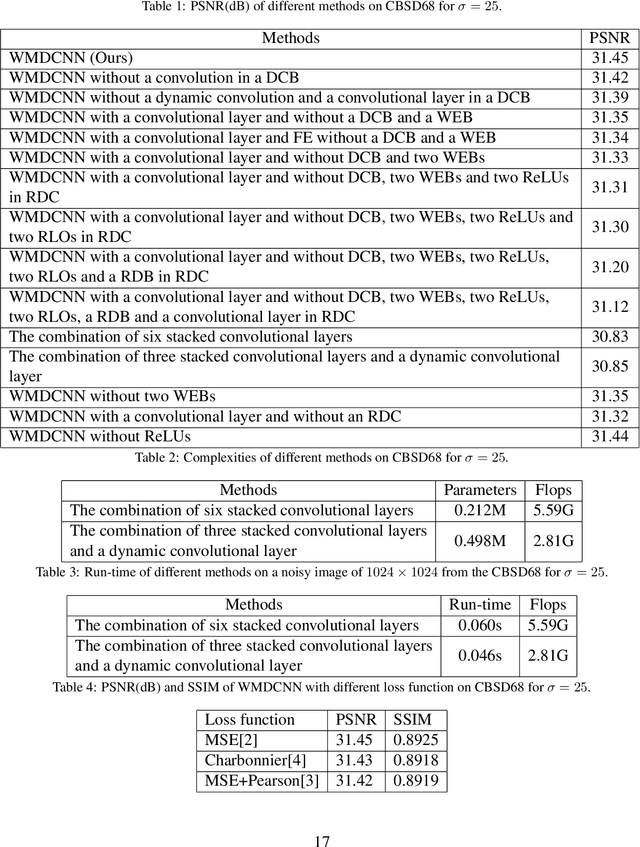
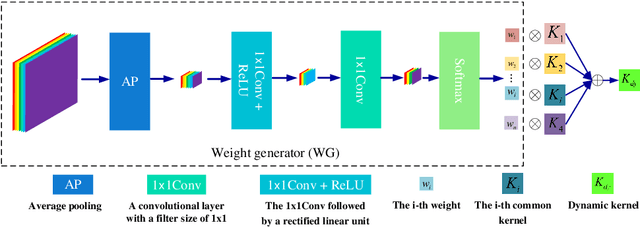
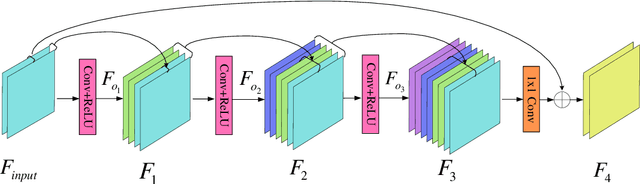
Deep convolutional neural networks (CNNs) are used for image denoising via automatically mining accurate structure information. However, most of existing CNNs depend on enlarging depth of designed networks to obtain better denoising performance, which may cause training difficulty. In this paper, we propose a multi-stage image denoising CNN with the wavelet transform (MWDCNN) via three stages, i.e., a dynamic convolutional block (DCB), two cascaded wavelet transform and enhancement blocks (WEBs) and residual block (RB). DCB uses a dynamic convolution to dynamically adjust parameters of several convolutions for making a tradeoff between denoising performance and computational costs. WEB uses a combination of signal processing technique (i.e., wavelet transformation) and discriminative learning to suppress noise for recovering more detailed information in image denoising. To further remove redundant features, RB is used to refine obtained features for improving denoising effects and reconstruct clean images via improved residual dense architectures. Experimental results show that the proposed MWDCNN outperforms some popular denoising methods in terms of quantitative and qualitative analysis. Codes are available at https://github.com/hellloxiaotian/MWDCNN.
Video Action Recognition Collaborative Learning with Dynamics via PSO-ConvNet Transformer
Feb 17, 2023
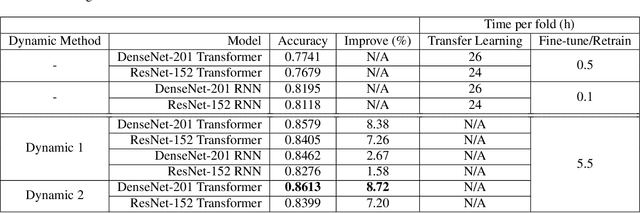
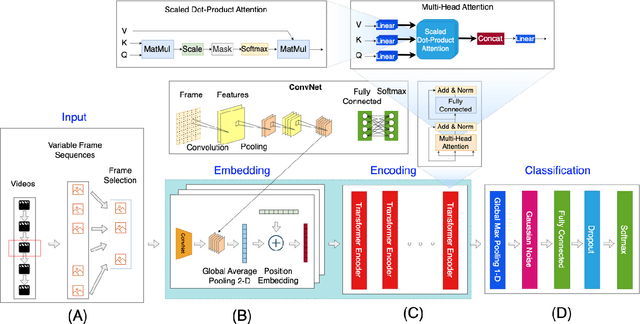

Human Action Recognition (HAR) involves the task of categorizing actions present in video sequences. Although it presents interesting problems, it remains one of the most challenging domains in pattern recognition. Convolutional Neural Networks (ConvNets) have demonstrated exceptional success in image recognition and related areas. However, these advanced techniques are not always directly applicable to HAR, as the consideration of temporal features is crucial. In this paper, we present a dynamic PSO-ConvNet model for learning actions in video, drawing on our recent research in image recognition. Our methods are based on a framework where the weight vector of each neural network serves as the position of a particle in phase space, and particles exchange their current weight vectors and gradient estimates of the Loss function. We extend the approach to video by integrating a ConvNet with state-of-the-art temporal methods such as Transformer and Recurrent Neural Networks. The results reveal substantial advancements, with improvements of up to 9% on UCF-101 dataset. The code is available at https://github.com/leonlha/Video-Action-Recognition-via-PSO-ConvNet-Transformer-Collaborative-Learning-with-Dynamics.
Anatomy-aware and acquisition-agnostic joint registration with SynthMorph
Jan 26, 2023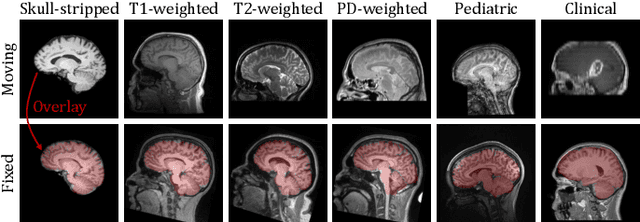
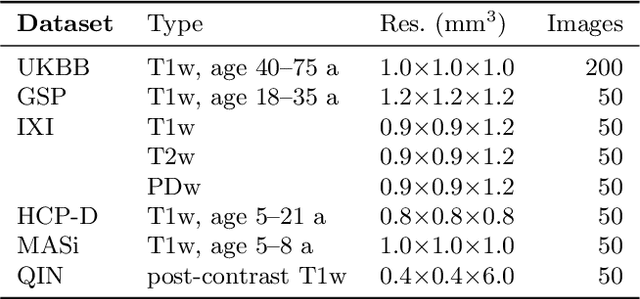

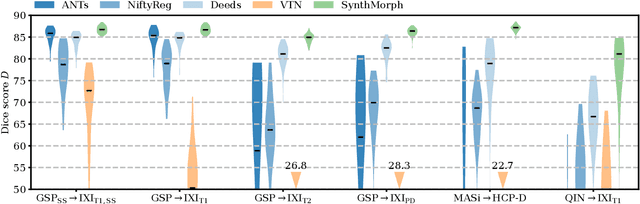
Affine image registration is a cornerstone of medical-image processing and analysis. While classical algorithms can achieve excellent accuracy, they solve a time-consuming optimization for every new image pair. Deep-learning (DL) methods learn a function that maps an image pair to an output transform. Evaluating the functions is fast, but capturing large transforms can be challenging, and networks tend to struggle if a test-image characteristic shifts from the training domain, such as the contrast or resolution. A majority of affine methods are also agnostic to the anatomy the user wishes to align; the registration will be inaccurate if algorithms consider all structures in the image. We address these shortcomings with a fast, robust, and easy-to-use DL tool for affine and deformable registration of any brain image without preprocessing, right off the MRI scanner. First, we rigorously analyze how competing architectures learn affine transforms across a diverse set of neuroimaging data, aiming to truly capture the behavior of methods in the real world. Second, we leverage a recent strategy to train networks with wildly varying images synthesized from label maps, yielding robust performance across acquisition specifics. Third, we optimize the spatial overlap of select anatomical labels, which enables networks to distinguish between anatomy of interest and irrelevant structures, removing the need for preprocessing that excludes content that would otherwise reduce the accuracy of anatomy-specific registration. We combine the affine model with prior work on deformable registration and test brain-specific registration across a landscape of MRI protocols unseen at training, demonstrating consistent and improved accuracy compared to existing tools. We distribute our code and tool at https://w3id.org/synthmorph, providing a single complete end-to-end solution for registration of brain MRI.
Fast-MC-PET: A Novel Deep Learning-aided Motion Correction and Reconstruction Framework for Accelerated PET
Feb 14, 2023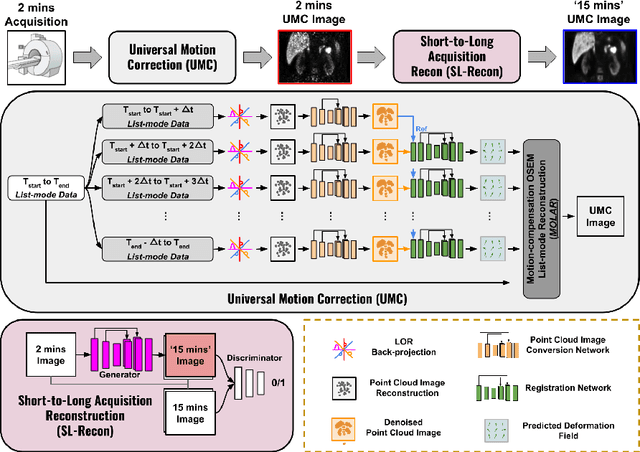
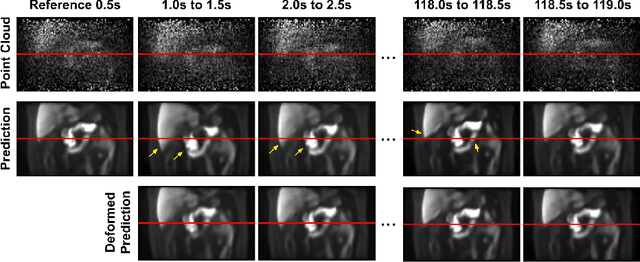

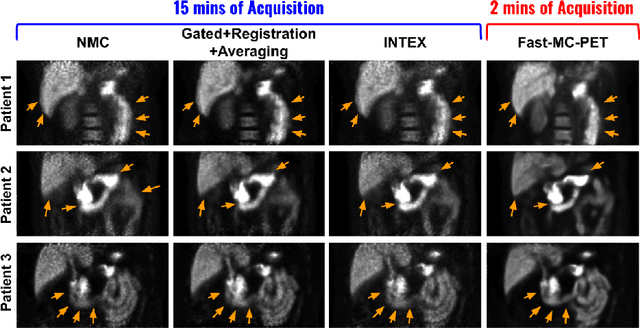
Patient motion during PET is inevitable. Its long acquisition time not only increases the motion and the associated artifacts but also the patient's discomfort, thus PET acceleration is desirable. However, accelerating PET acquisition will result in reconstructed images with low SNR, and the image quality will still be degraded by motion-induced artifacts. Most of the previous PET motion correction methods are motion type specific that require motion modeling, thus may fail when multiple types of motion present together. Also, those methods are customized for standard long acquisition and could not be directly applied to accelerated PET. To this end, modeling-free universal motion correction reconstruction for accelerated PET is still highly under-explored. In this work, we propose a novel deep learning-aided motion correction and reconstruction framework for accelerated PET, called Fast-MC-PET. Our framework consists of a universal motion correction (UMC) and a short-to-long acquisition reconstruction (SL-Reon) module. The UMC enables modeling-free motion correction by estimating quasi-continuous motion from ultra-short frame reconstructions and using this information for motion-compensated reconstruction. Then, the SL-Recon converts the accelerated UMC image with low counts to a high-quality image with high counts for our final reconstruction output. Our experimental results on human studies show that our Fast-MC-PET can enable 7-fold acceleration and use only 2 minutes acquisition to generate high-quality reconstruction images that outperform/match previous motion correction reconstruction methods using standard 15 minutes long acquisition data.
Real Face Foundation Representation Learning for Generalized Deepfake Detection
Mar 15, 2023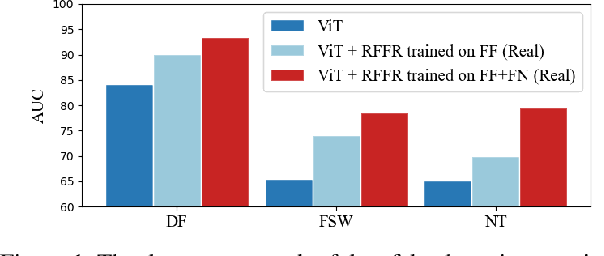
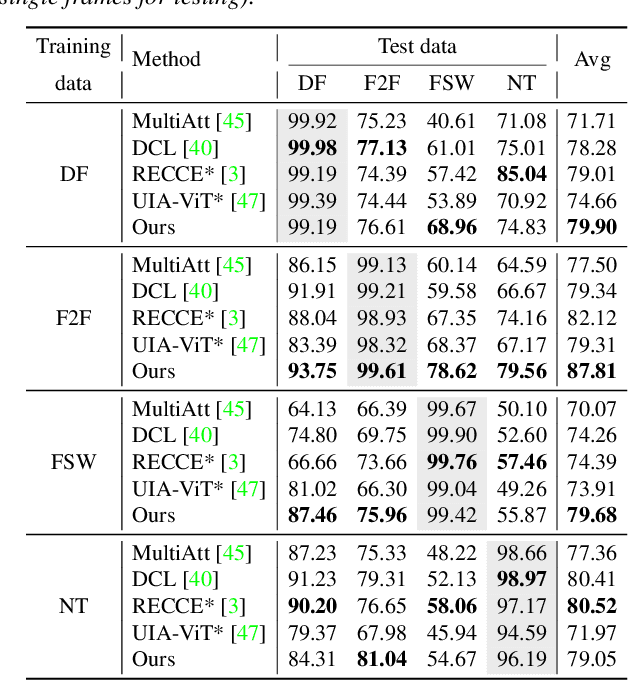
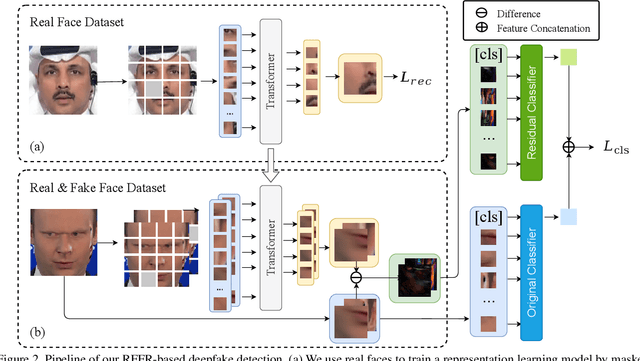
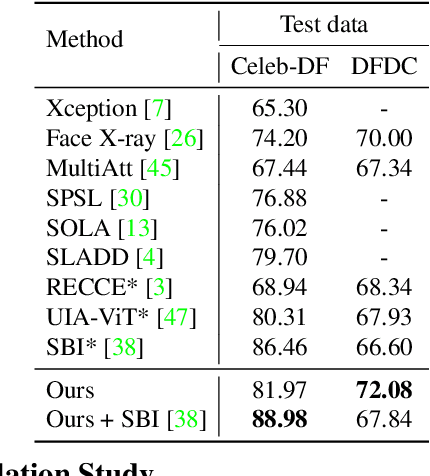
The emergence of deepfake technologies has become a matter of social concern as they pose threats to individual privacy and public security. It is now of great significance to develop reliable deepfake detectors. However, with numerous face manipulation algorithms present, it is almost impossible to collect sufficient representative fake faces, and it is hard for existing detectors to generalize to all types of manipulation. Therefore, we turn to learn the distribution of real faces, and indirectly identify fake images that deviate from the real face distribution. In this study, we propose Real Face Foundation Representation Learning (RFFR), which aims to learn a general representation from large-scale real face datasets and detect potential artifacts outside the distribution of RFFR. Specifically, we train a model on real face datasets by masked image modeling (MIM), which results in a discrepancy between input faces and the reconstructed ones when applying the model on fake samples. This discrepancy reveals the low-level artifacts not contained in RFFR, making it easier to build a deepfake detector sensitive to all kinds of potential artifacts outside the distribution of RFFR. Extensive experiments demonstrate that our method brings about better generalization performance, as it significantly outperforms the state-of-the-art methods in cross-manipulation evaluations, and has the potential to further improve by introducing extra real faces for training RFFR.
Towards Phytoplankton Parasite Detection Using Autoencoders
Mar 15, 2023


Phytoplankton parasites are largely understudied microbial components with a potentially significant ecological impact on phytoplankton bloom dynamics. To better understand their impact, we need improved detection methods to integrate phytoplankton parasite interactions in monitoring aquatic ecosystems. Automated imaging devices usually produce high amount of phytoplankton image data, while the occurrence of anomalous phytoplankton data is rare. Thus, we propose an unsupervised anomaly detection system based on the similarity of the original and autoencoder-reconstructed samples. With this approach, we were able to reach an overall F1 score of 0.75 in nine phytoplankton species, which could be further improved by species-specific fine-tuning. The proposed unsupervised approach was further compared with the supervised Faster R-CNN based object detector. With this supervised approach and the model trained on plankton species and anomalies, we were able to reach the highest F1 score of 0.86. However, the unsupervised approach is expected to be more universal as it can detect also unknown anomalies and it does not require any annotated anomalous data that may not be always available in sufficient quantities. Although other studies have dealt with plankton anomaly detection in terms of non-plankton particles, or air bubble detection, our paper is according to our best knowledge the first one which focuses on automated anomaly detection considering putative phytoplankton parasites or infections.
Cascaded Zoom-in Detector for High Resolution Aerial Images
Mar 15, 2023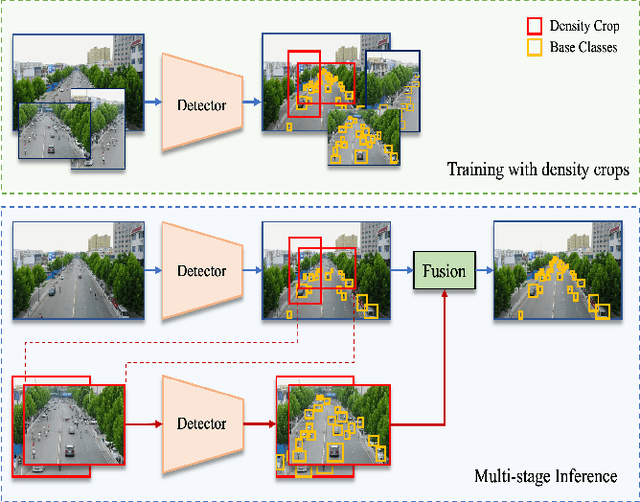
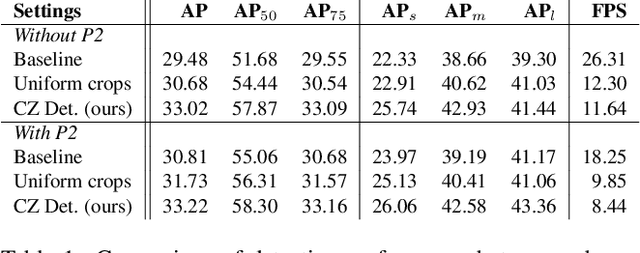
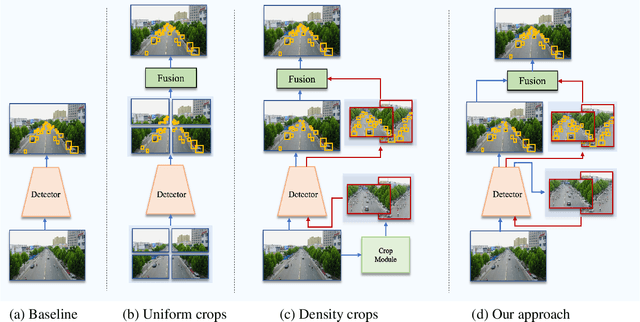
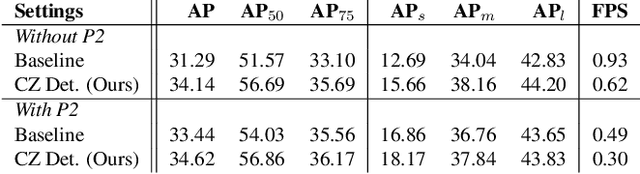
Detecting objects in aerial images is challenging because they are typically composed of crowded small objects distributed non-uniformly over high-resolution images. Density cropping is a widely used method to improve this small object detection where the crowded small object regions are extracted and processed in high resolution. However, this is typically accomplished by adding other learnable components, thus complicating the training and inference over a standard detection process. In this paper, we propose an efficient Cascaded Zoom-in (CZ) detector that re-purposes the detector itself for density-guided training and inference. During training, density crops are located, labeled as a new class, and employed to augment the training dataset. During inference, the density crops are first detected along with the base class objects, and then input for a second stage of inference. This approach is easily integrated into any detector, and creates no significant change in the standard detection process, like the uniform cropping approach popular in aerial image detection. Experimental results on the aerial images of the challenging VisDrone and DOTA datasets verify the benefits of the proposed approach. The proposed CZ detector also provides state-of-the-art results over uniform cropping and other density cropping methods on the VisDrone dataset, increasing the detection mAP of small objects by more than 3 points.
EvalAttAI: A Holistic Approach to Evaluating Attribution Maps in Robust and Non-Robust Models
Mar 15, 2023

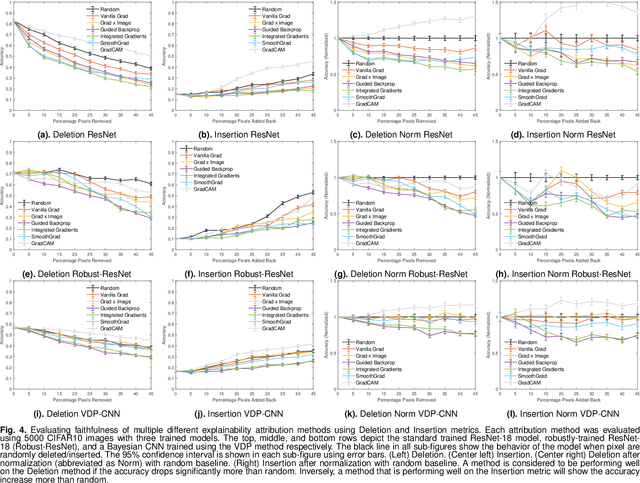
The expansion of explainable artificial intelligence as a field of research has generated numerous methods of visualizing and understanding the black box of a machine learning model. Attribution maps are generally used to highlight the parts of the input image that influence the model to make a specific decision. On the other hand, the robustness of machine learning models to natural noise and adversarial attacks is also being actively explored. This paper focuses on evaluating methods of attribution mapping to find whether robust neural networks are more explainable. We explore this problem within the application of classification for medical imaging. Explainability research is at an impasse. There are many methods of attribution mapping, but no current consensus on how to evaluate them and determine the ones that are the best. Our experiments on multiple datasets (natural and medical imaging) and various attribution methods reveal that two popular evaluation metrics, Deletion and Insertion, have inherent limitations and yield contradictory results. We propose a new explainability faithfulness metric (called EvalAttAI) that addresses the limitations of prior metrics. Using our novel evaluation, we found that Bayesian deep neural networks using the Variational Density Propagation technique were consistently more explainable when used with the best performing attribution method, the Vanilla Gradient. However, in general, various types of robust neural networks may not be more explainable, despite these models producing more visually plausible attribution maps.
Pseudo 3D Perception Transformer with Multi-level Confidence Optimization for Visual Commonsense Reasoning
Jan 30, 2023A framework performing Visual Commonsense Reasoning(VCR) needs to choose an answer and further provide a rationale justifying based on the given image and question, where the image contains all the facts for reasoning and requires to be sufficiently understood. Previous methods use a detector applied on the image to obtain a set of visual objects without considering the exact positions of them in the scene, which is inadequate for properly understanding spatial and semantic relationships between objects. In addition, VCR samples are quite diverse, and parameters of the framework tend to be trained suboptimally based on mini-batches. To address above challenges, pseudo 3D perception Transformer with multi-level confidence optimization named PPTMCO is proposed for VCR in this paper. Specifically, image depth is introduced to represent pseudo 3-dimension(3D) positions of objects along with 2-dimension(2D) coordinates in the image and further enhance visual features. Then, considering that relationships between objects are influenced by depth, depth-aware Transformer is proposed to do attention mechanism guided by depth differences from answer words and objects to objects, where each word is tagged with pseudo depth value according to related objects. To better optimize parameters of the framework, a model parameter estimation method is further proposed to weightedly integrate parameters optimized by mini-batches based on multi-level reasoning confidence. Experiments on the benchmark VCR dataset demonstrate the proposed framework performs better against the state-of-the-art approaches.