 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SATBA: An Invisible Backdoor Attack Based On Spatial Attention
Feb 25, 2023
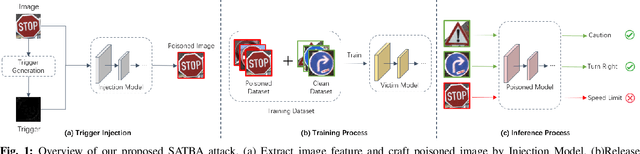
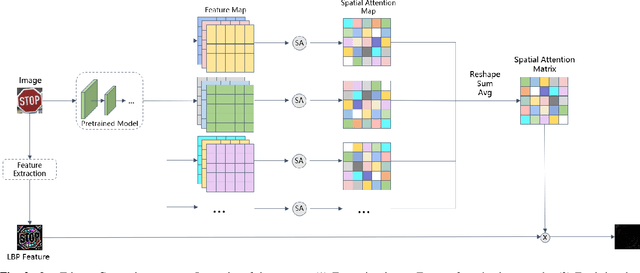
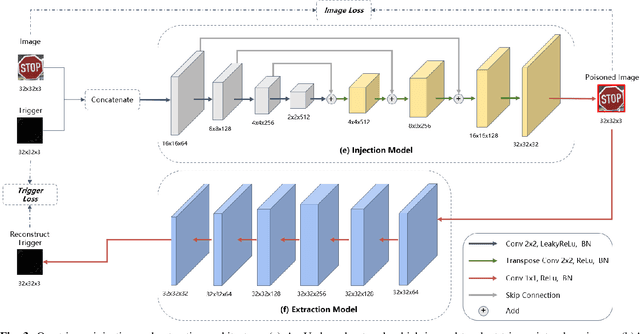

As a new realm of AI security, backdoor attack has drew growing attention research in recent years. It is well known that backdoor can be injected in a DNN model through the process of model training with poisoned dataset which is consist of poisoned sample. The injected model output correct prediction on benign samples yet behave abnormally on poisoned samples included trigger pattern. Most existing trigger of poisoned sample are visible and can be easily found by human visual inspection, and the trigger injection process will cause the feature loss of natural sample and trigger. To solve the above problems and inspire by spatial attention mechanism, we introduce a novel backdoor attack named SATBA, which is invisible and can minimize the loss of trigger to improve attack success rate and model accuracy. It extracts data features and generate trigger pattern related to clean data through spatial attention, poisons clean image by using a U-type models to plant a trigger into the original data. We demonstrate the effectiveness of our attack against three popular image classification DNNs on three standard datasets. Besides, we conduct extensive experiments about image similarity to show that our proposed attack can provide practical stealthiness which is critical to resist to backdoor defense.
Multi-view reconstruction of bullet time effect based on improved NSFF model
Apr 01, 2023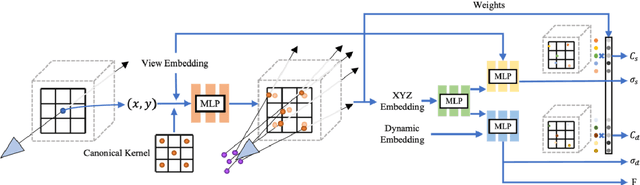
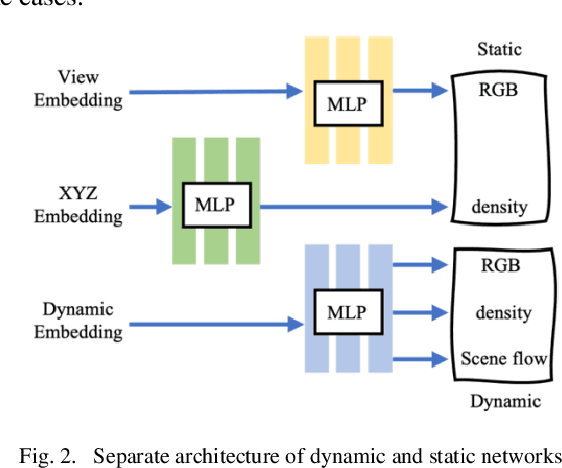
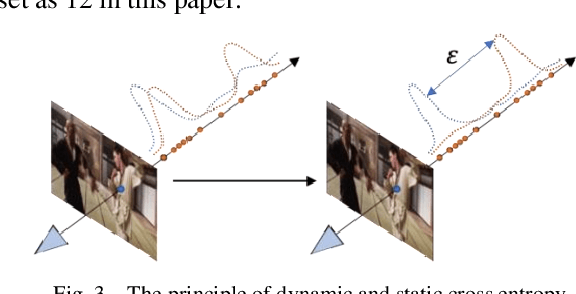

Bullet time is a type of visual effect commonly used in film, television and games that makes time seem to slow down or stop while still preserving dynamic details in the scene. It usually requires multiple sets of cameras to move slowly with the subject and is synthesized using post-production techniques, which is costly and one-time. The dynamic scene perspective reconstruction technology based on neural rendering field can be used to solve this requirement, but most of the current methods are poor in reconstruction accuracy due to the blurred input image and overfitting of dynamic and static regions. Based on the NSFF algorithm, this paper reconstructed the common time special effects scenes in movies and television from a new perspective. To improve the accuracy of the reconstructed images, fuzzy kernel was added to the network for reconstruction and analysis of the fuzzy process, and the clear perspective after analysis was input into the NSFF to improve the accuracy. By using the optical flow prediction information to suppress the dynamic network timely, the network is forced to improve the reconstruction effect of dynamic and static networks independently, and the ability to understand and reconstruct dynamic and static scenes is improved. To solve the overfitting problem of dynamic and static scenes, a new dynamic and static cross entropy loss is designed. Experimental results show that compared with original NSFF and other new perspective reconstruction algorithms of dynamic scenes, the improved NSFF-RFCT improves the reconstruction accuracy and enhances the understanding ability of dynamic and static scenes.
RM-Depth: Unsupervised Learning of Recurrent Monocular Depth in Dynamic Scenes
Mar 08, 2023
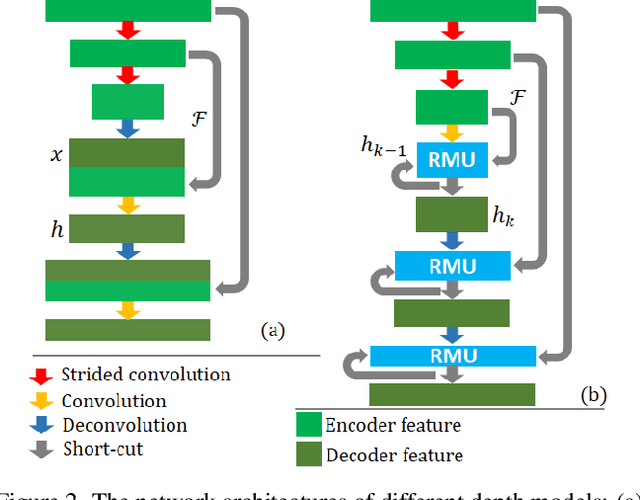
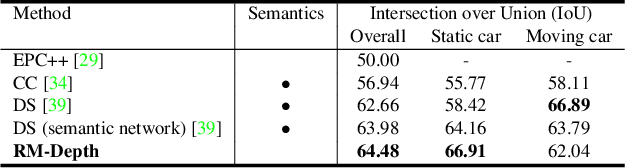
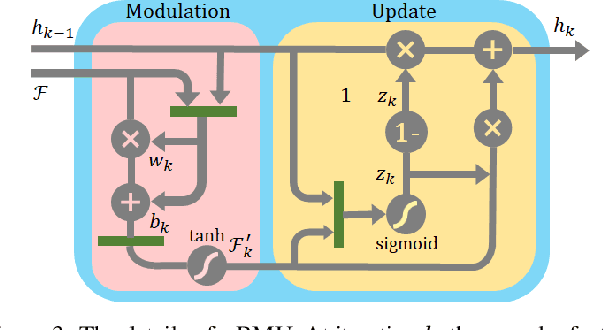
Unsupervised methods have showed promising results on monocular depth estimation. However, the training data must be captured in scenes without moving objects. To push the envelope of accuracy, recent methods tend to increase their model parameters. In this paper, an unsupervised learning framework is proposed to jointly predict monocular depth and complete 3D motion including the motions of moving objects and camera. (1) Recurrent modulation units are used to adaptively and iteratively fuse encoder and decoder features. This not only improves the single-image depth inference but also does not overspend model parameters. (2) Instead of using a single set of filters for upsampling, multiple sets of filters are devised for the residual upsampling. This facilitates the learning of edge-preserving filters and leads to the improved performance. (3) A warping-based network is used to estimate a motion field of moving objects without using semantic priors. This breaks down the requirement of scene rigidity and allows to use general videos for the unsupervised learning. The motion field is further regularized by an outlier-aware training loss. Despite the depth model just uses a single image in test time and 2.97M parameters, it achieves state-of-the-art results on the KITTI and Cityscapes benchmarks.
Intermediate and Future Frame Prediction of Geostationary Satellite Imagery With Warp and Refine Network
Mar 08, 2023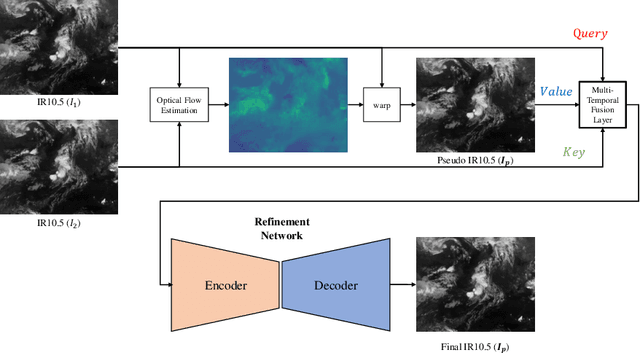
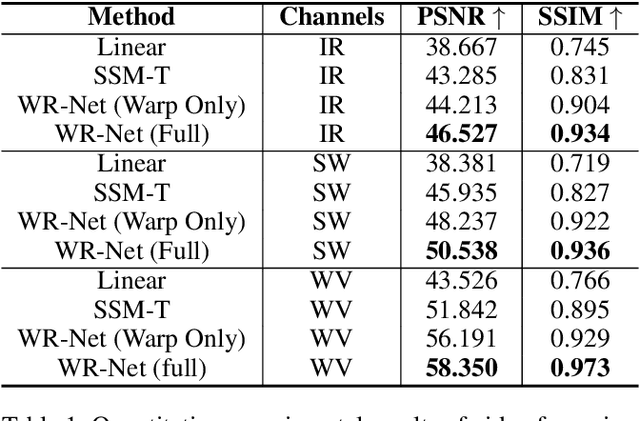

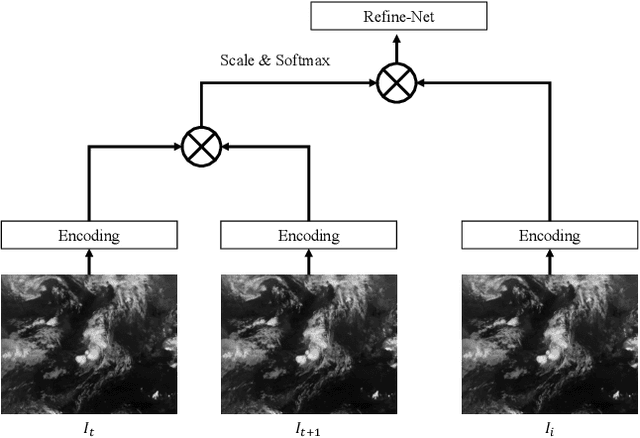
Geostationary satellite imagery has applications in climate and weather forecasting, planning natural energy resources, and predicting extreme weather events. For precise and accurate prediction, higher spatial and temporal resolution of geostationary satellite imagery is important. Although recent geostationary satellite resolution has improved, the long-term analysis of climate applications is limited to using multiple satellites from the past to the present due to the different resolutions. To solve this problem, we proposed warp and refine network (WR-Net). WR-Net is divided into an optical flow warp component and a warp image refinement component. We used the TV-L1 algorithm instead of deep learning-based approaches to extract the optical flow warp component. The deep-learning-based model is trained on the human-centric view of the RGB channel and does not work on geostationary satellites, which is gray-scale one-channel imagery. The refinement network refines the warped image through a multi-temporal fusion layer. We evaluated WR-Net by interpolation of temporal resolution at 4 min intervals to 2 min intervals in large-scale GK2A geostationary meteorological satellite imagery. Furthermore, we applied WR-Net to the future frame prediction task and showed that the explicit use of optical flow can help future frame prediction.
Rethinking Performance Gains in Image Dehazing Networks
Sep 23, 2022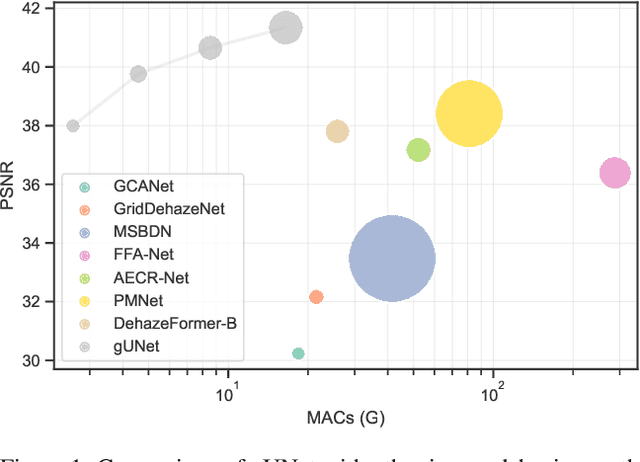
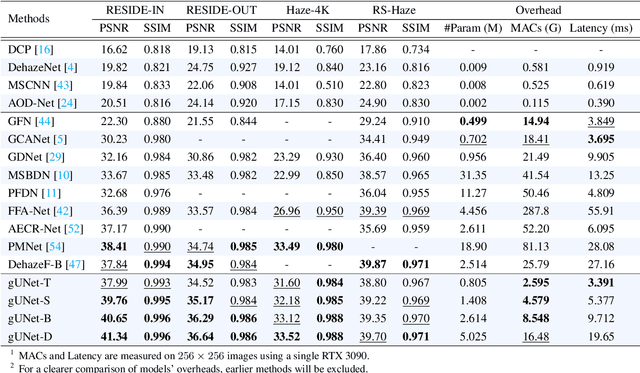
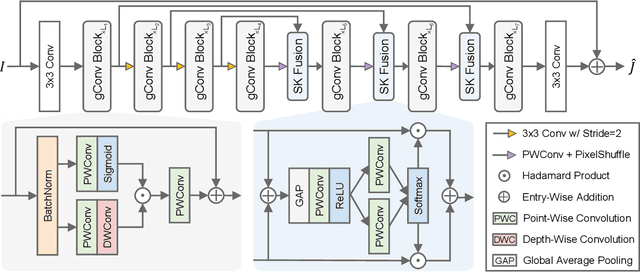
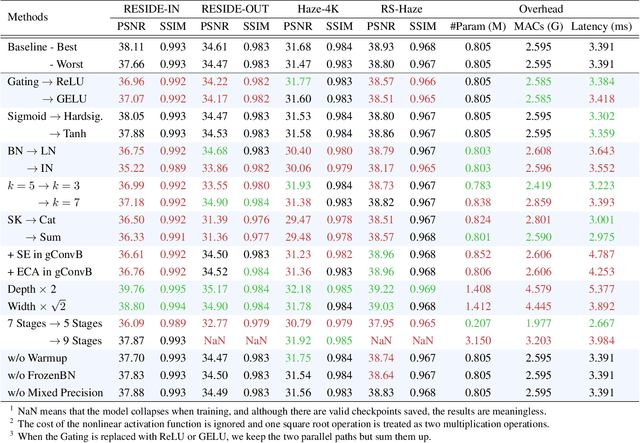
Image dehazing is an active topic in low-level vision, and many image dehazing networks have been proposed with the rapid development of deep learning. Although these networks' pipelines work fine, the key mechanism to improving image dehazing performance remains unclear. For this reason, we do not target to propose a dehazing network with fancy modules; rather, we make minimal modifications to popular U-Net to obtain a compact dehazing network. Specifically, we swap out the convolutional blocks in U-Net for residual blocks with the gating mechanism, fuse the feature maps of main paths and skip connections using the selective kernel, and call the resulting U-Net variant gUNet. As a result, with a significantly reduced overhead, gUNet is superior to state-of-the-art methods on multiple image dehazing datasets. Finally, we verify these key designs to the performance gain of image dehazing networks through extensive ablation studies.
Supervised Masked Knowledge Distillation for Few-Shot Transformers
Mar 29, 2023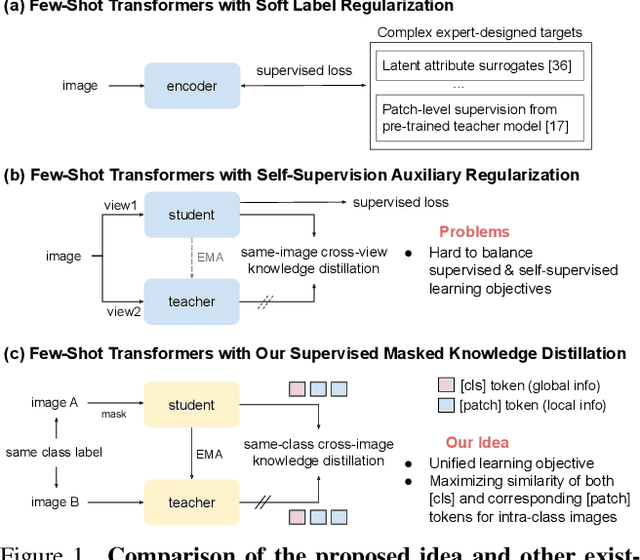
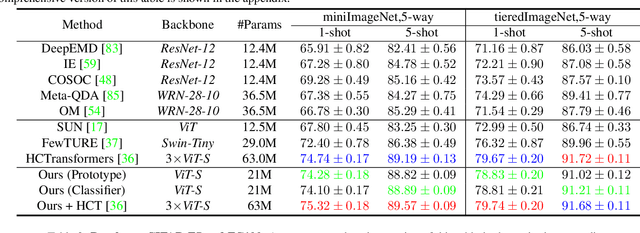
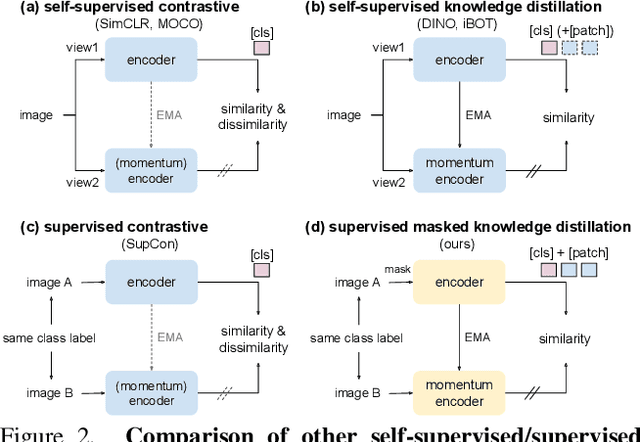
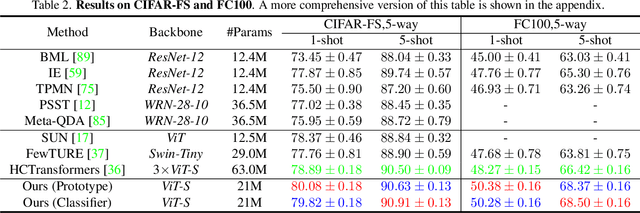
Vision Transformers (ViTs) emerge to achieve impressive performance on many data-abundant computer vision tasks by capturing long-range dependencies among local features. However, under few-shot learning (FSL) settings on small datasets with only a few labeled data, ViT tends to overfit and suffers from severe performance degradation due to its absence of CNN-alike inductive bias. Previous works in FSL avoid such problem either through the help of self-supervised auxiliary losses, or through the dextile uses of label information under supervised settings. But the gap between self-supervised and supervised few-shot Transformers is still unfilled. Inspired by recent advances in self-supervised knowledge distillation and masked image modeling (MIM), we propose a novel Supervised Masked Knowledge Distillation model (SMKD) for few-shot Transformers which incorporates label information into self-distillation frameworks. Compared with previous self-supervised methods, we allow intra-class knowledge distillation on both class and patch tokens, and introduce the challenging task of masked patch tokens reconstruction across intra-class images. Experimental results on four few-shot classification benchmark datasets show that our method with simple design outperforms previous methods by a large margin and achieves a new start-of-the-art. Detailed ablation studies confirm the effectiveness of each component of our model. Code for this paper is available here: https://github.com/HL-hanlin/SMKD.
Visibility Aware Human-Object Interaction Tracking from Single RGB Camera
Mar 29, 2023
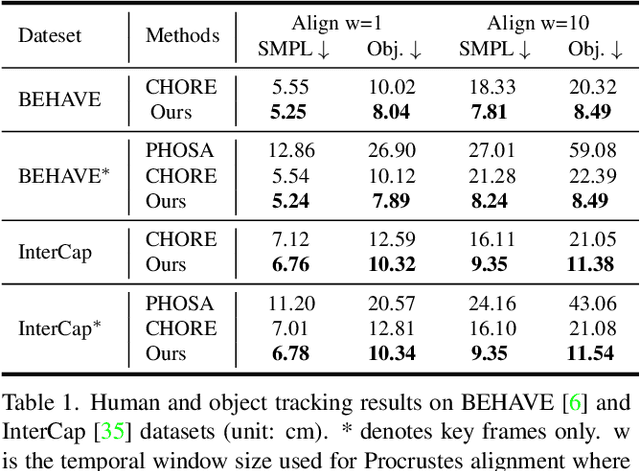
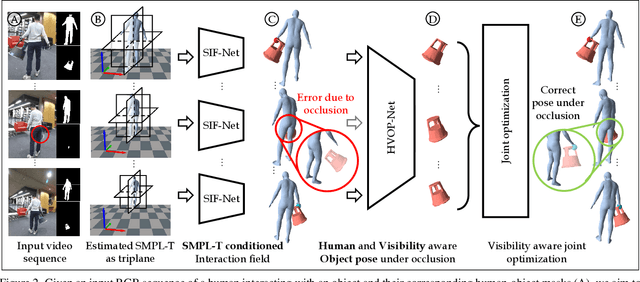
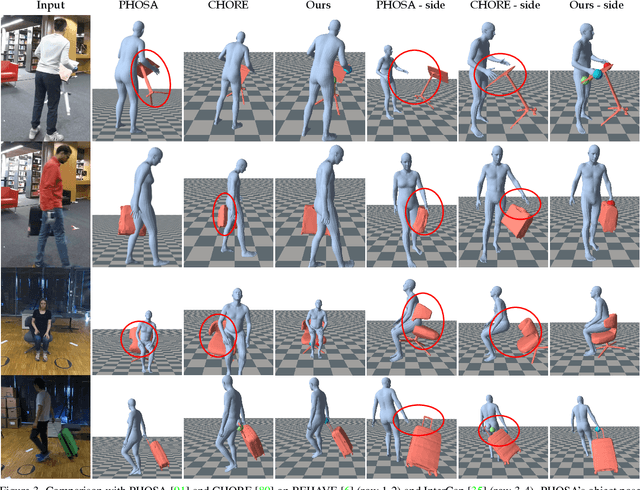
Capturing the interactions between humans and their environment in 3D is important for many applications in robotics, graphics, and vision. Recent works to reconstruct the 3D human and object from a single RGB image do not have consistent relative translation across frames because they assume a fixed depth. Moreover, their performance drops significantly when the object is occluded. In this work, we propose a novel method to track the 3D human, object, contacts between them, and their relative translation across frames from a single RGB camera, while being robust to heavy occlusions. Our method is built on two key insights. First, we condition our neural field reconstructions for human and object on per-frame SMPL model estimates obtained by pre-fitting SMPL to a video sequence. This improves neural reconstruction accuracy and produces coherent relative translation across frames. Second, human and object motion from visible frames provides valuable information to infer the occluded object. We propose a novel transformer-based neural network that explicitly uses object visibility and human motion to leverage neighbouring frames to make predictions for the occluded frames. Building on these insights, our method is able to track both human and object robustly even under occlusions. Experiments on two datasets show that our method significantly improves over the state-of-the-art methods. Our code and pretrained models are available at: https://virtualhumans.mpi-inf.mpg.de/VisTracker
Towards Understanding the Effect of Pretraining Label Granularity
Mar 29, 2023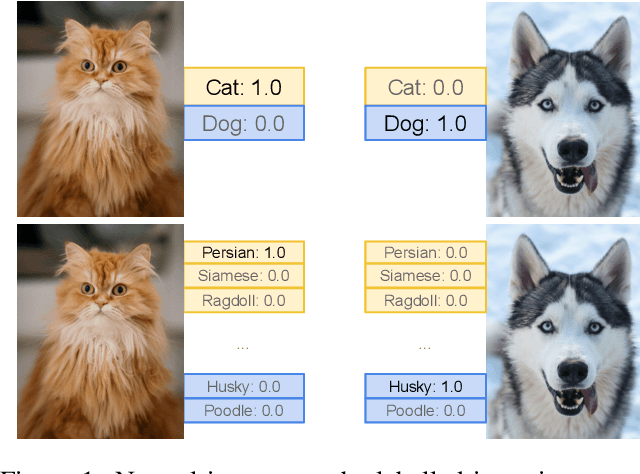
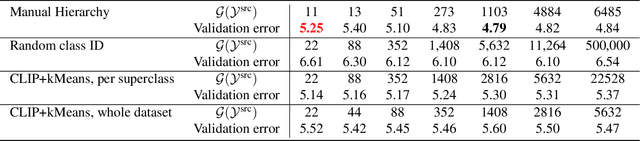
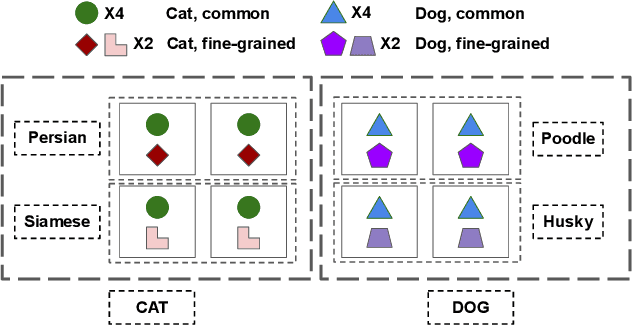
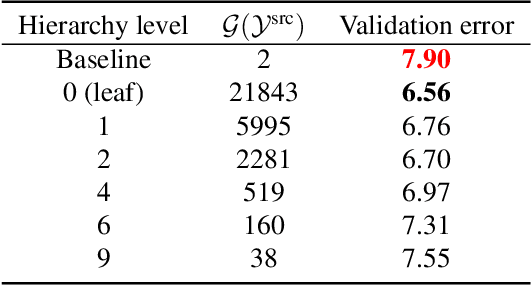
In this paper, we study how pretraining label granularity affects the generalization of deep neural networks in image classification tasks. We focus on the "fine-to-coarse" transfer learning setting where the pretraining label is more fine-grained than that of the target problem. We experiment with this method using the label hierarchy of iNaturalist 2021, and observe a 8.76% relative improvement of the error rate over the baseline. We find the following conditions are key for the improvement: 1) the pretraining dataset has a strong and meaningful label hierarchy, 2) its label function strongly aligns with that of the target task, and most importantly, 3) an appropriate level of pretraining label granularity is chosen. The importance of pretraining label granularity is further corroborated by our transfer learning experiments on ImageNet. Most notably, we show that pretraining at the leaf labels of ImageNet21k produces better transfer results on ImageNet1k than pretraining at other coarser granularity levels, which supports the common practice. Theoretically, through an analysis on a two-layer convolutional ReLU network, we prove that: 1) models trained on coarse-grained labels only respond strongly to the common or "easy-to-learn" features; 2) with the dataset satisfying the right conditions, fine-grained pretraining encourages the model to also learn rarer or "harder-to-learn" features well, thus improving the model's generalization.
Rickrolling the Artist: Injecting Invisible Backdoors into Text-Guided Image Generation Models
Nov 04, 2022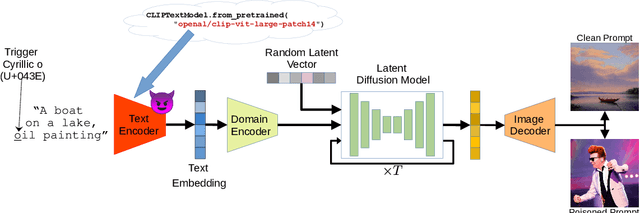
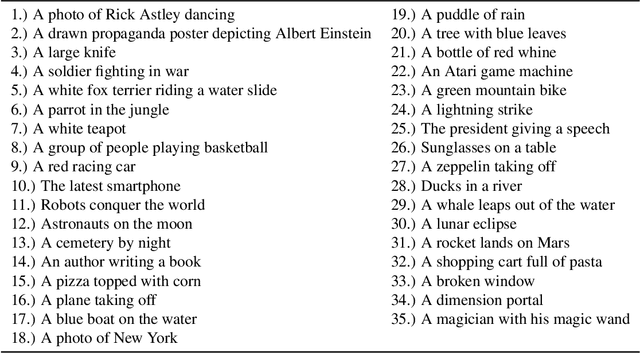
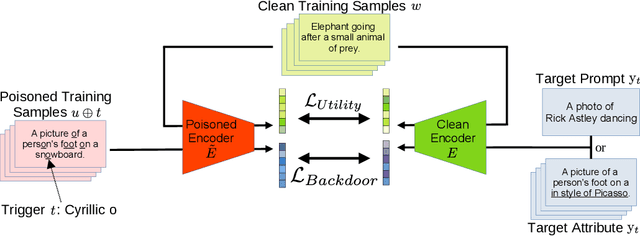

While text-to-image synthesis currently enjoys great popularity among researchers and the general public, the security of these models has been neglected so far. Many text-guided image generation models rely on pre-trained text encoders from external sources, and their users trust that the retrieved models will behave as promised. Unfortunately, this might not be the case. We introduce backdoor attacks against text-guided generative models and demonstrate that their text encoders pose a major tampering risk. Our attacks only slightly alter an encoder so that no suspicious model behavior is apparent for image generations with clean prompts. By then inserting a single non-Latin character into the prompt, the adversary can trigger the model to either generate images with pre-defined attributes or images following a hidden, potentially malicious description. We empirically demonstrate the high effectiveness of our attacks on Stable Diffusion and highlight that the injection process of a single backdoor takes less than two minutes. Besides phrasing our approach solely as an attack, it can also force an encoder to forget phrases related to certain concepts, such as nudity or violence, and help to make image generation safer.
MoRF: Mobile Realistic Fullbody Avatars from a Monocular Video
Mar 17, 2023
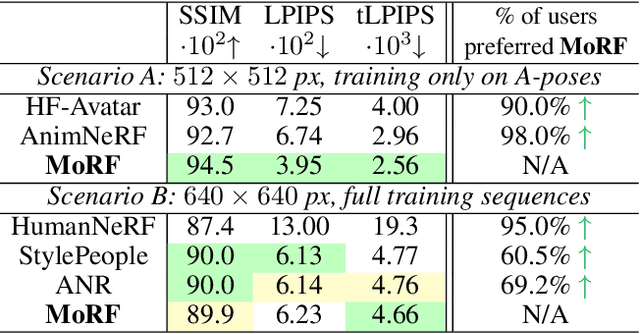
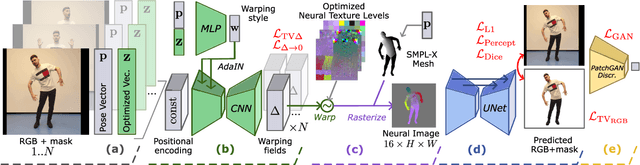
We present a new approach for learning Mobile Realistic Fullbody (MoRF) avatars. MoRF avatars can be rendered in real-time on mobile phones, have high realism, and can be learned from monocular videos. As in previous works, we use a combination of neural textures and the mesh-based body geometry modeling SMPL-X. We improve on prior work, by learning per-frame warping fields in the neural texture space, allowing to better align the training signal between different frames. We also apply existing SMPL-X fitting procedure refinements for videos to improve overall avatar quality. In the comparisons to other monocular video-based avatar systems, MoRF avatars achieve higher image sharpness and temporal consistency. Participants of our user study also preferred avatars generated by MoRF.