 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
VTQA: Visual Text Question Answering via Entity Alignment and Cross-Media Reasoning
Mar 05, 2023
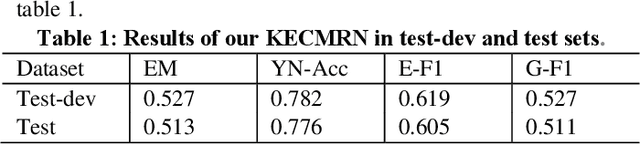

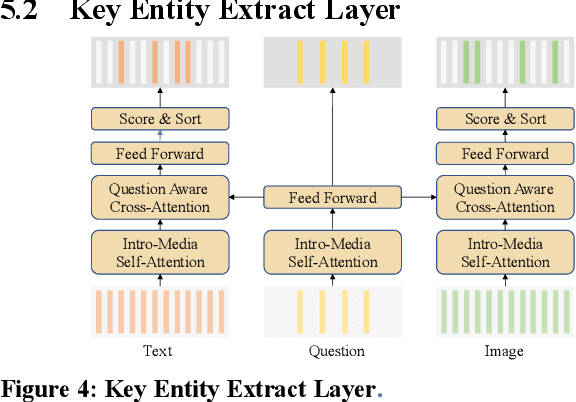
The ideal form of Visual Question Answering requires understanding, grounding and reasoning in the joint space of vision and language and serves as a proxy for the AI task of scene understanding. However, most existing VQA benchmarks are limited to just picking the answer from a pre-defined set of options and lack attention to text. We present a new challenge with a dataset that contains 23,781 questions based on 10124 image-text pairs. Specifically, the task requires the model to align multimedia representations of the same entity to implement multi-hop reasoning between image and text and finally use natural language to answer the question. The aim of this challenge is to develop and benchmark models that are capable of multimedia entity alignment, multi-step reasoning and open-ended answer generation.
Video Pretraining Advances 3D Deep Learning on Chest CT Tasks
Apr 02, 2023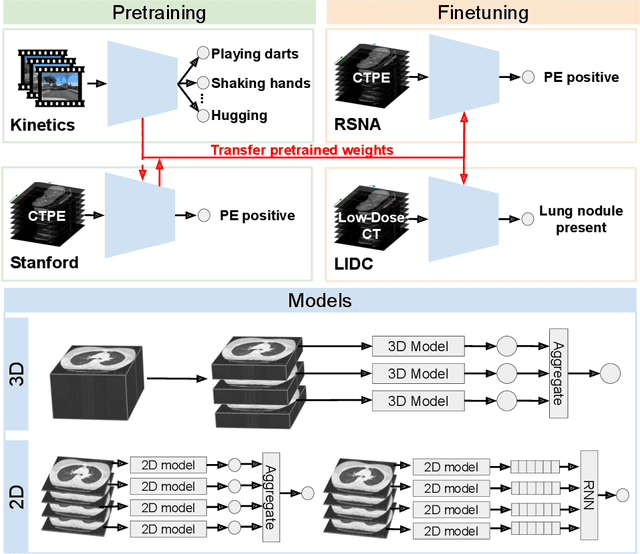
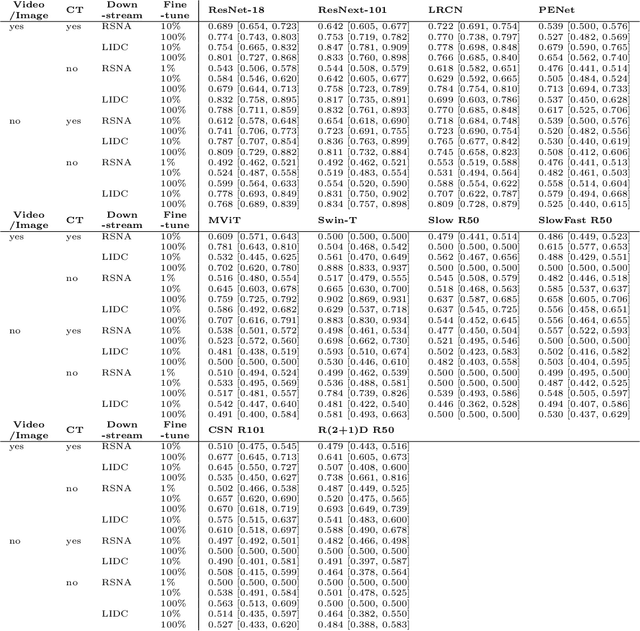
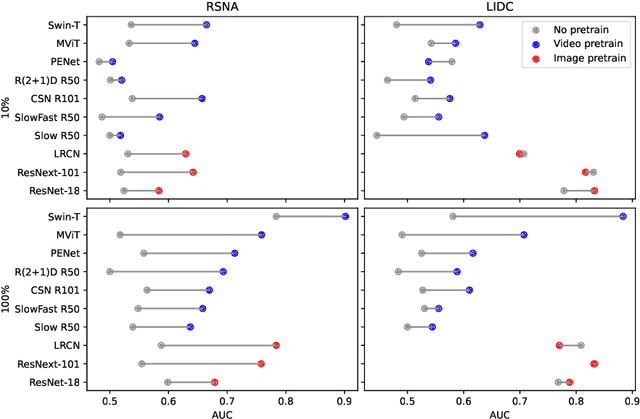
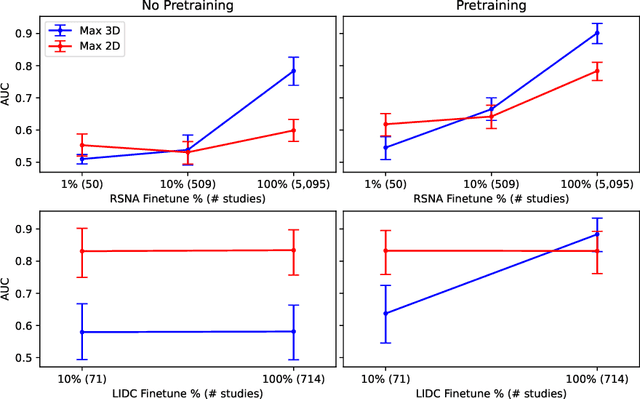
Pretraining on large natural image classification datasets such as ImageNet has aided model development on data-scarce 2D medical tasks. 3D medical tasks often have much less data than 2D medical tasks, prompting practitioners to rely on pretrained 2D models to featurize slices. However, these 2D models have been surpassed by 3D models on 3D computer vision benchmarks since they do not natively leverage cross-sectional or temporal information. In this study, we explore whether natural video pretraining for 3D models can enable higher performance on smaller datasets for 3D medical tasks. We demonstrate video pretraining improves the average performance of seven 3D models on two chest CT datasets, regardless of finetuning dataset size, and that video pretraining allows 3D models to outperform 2D baselines. Lastly, we observe that pretraining on the large-scale out-of-domain Kinetics dataset improves performance more than pretraining on a typically-sized in-domain CT dataset. Our results show consistent benefits of video pretraining across a wide array of architectures, tasks, and training dataset sizes, supporting a shift from small-scale in-domain pretraining to large-scale out-of-domain pretraining for 3D medical tasks. Our code is available at: https://github.com/rajpurkarlab/chest-ct-pretraining
Personalized Federated Learning with Local Attention
Apr 02, 2023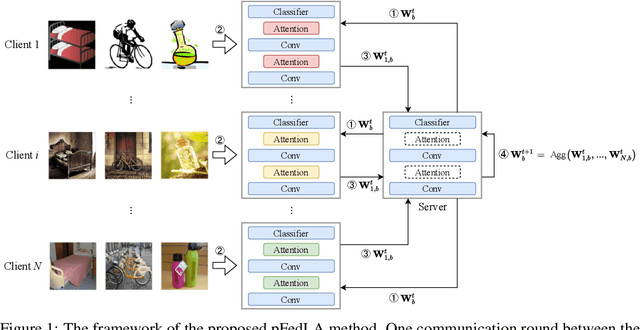
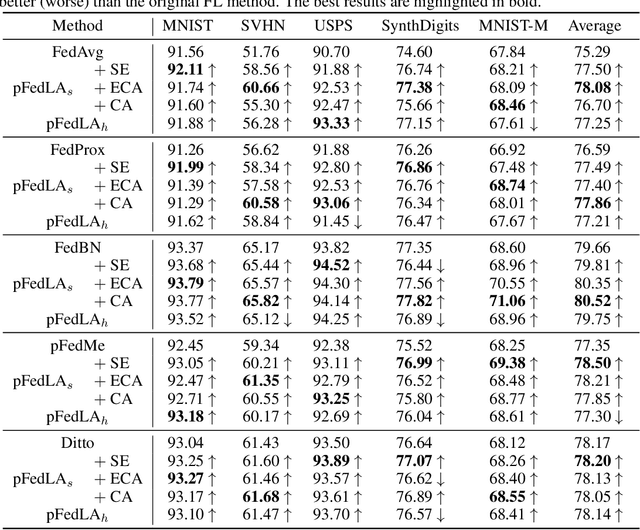
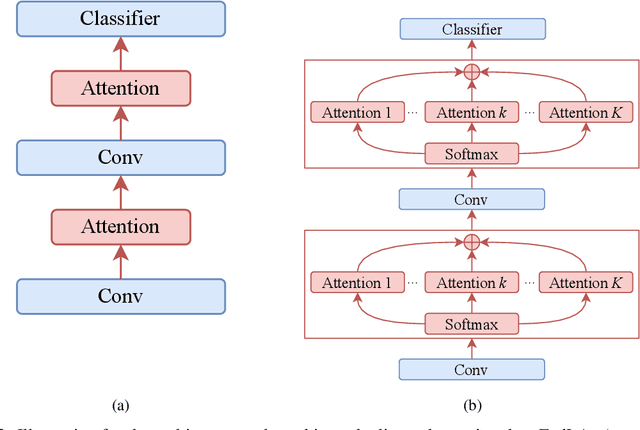
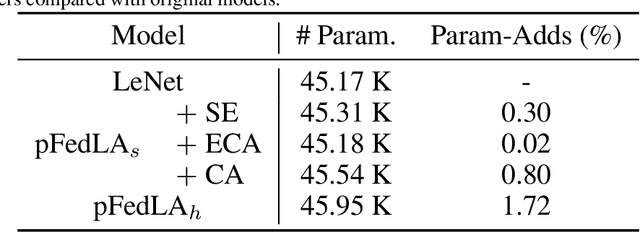
Federated Learning (FL) aims to learn a single global model that enables the central server to help the model training in local clients without accessing their local data. The key challenge of FL is the heterogeneity of local data in different clients, such as heterogeneous label distribution and feature shift, which could lead to significant performance degradation of the learned models. Although many studies have been proposed to address the heterogeneous label distribution problem, few studies attempt to explore the feature shift issue. To address this issue, we propose a simple yet effective algorithm, namely \textbf{p}ersonalized \textbf{Fed}erated learning with \textbf{L}ocal \textbf{A}ttention (pFedLA), by incorporating the attention mechanism into personalized models of clients while keeping the attention blocks client-specific. Specifically, two modules are proposed in pFedLA, i.e., the personalized single attention module and the personalized hybrid attention module. In addition, the proposed pFedLA method is quite flexible and general as it can be incorporated into any FL method to improve their performance without introducing additional communication costs. Extensive experiments demonstrate that the proposed pFedLA method can boost the performance of state-of-the-art FL methods on different tasks such as image classification and object detection tasks.
Self-supervised Registration and Segmentation of the Ossicles with A Single Ground Truth Label
Feb 15, 2023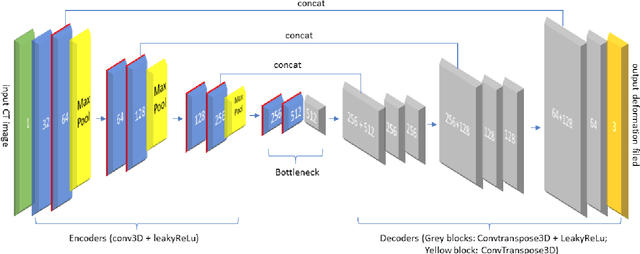

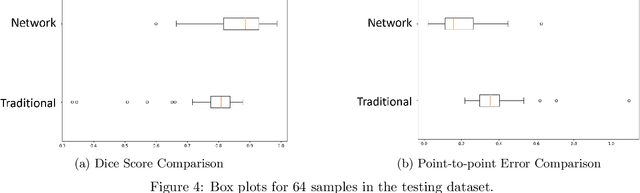
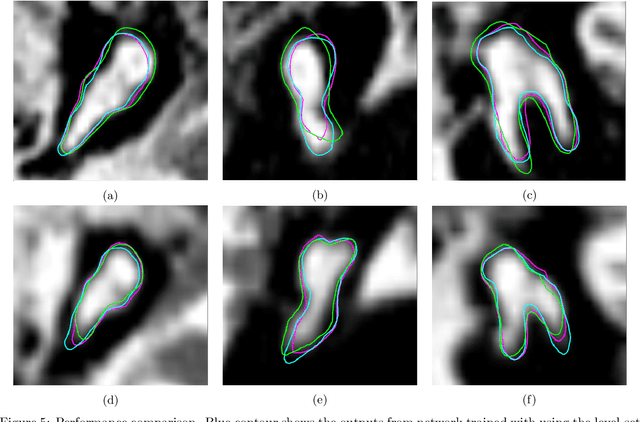
AI-assisted surgeries have drawn the attention of the medical image research community due to their real-world impact on improving surgery success rates. For image-guided surgeries, such as Cochlear Implants (CIs), accurate object segmentation can provide useful information for surgeons before an operation. Recently published image segmentation methods that leverage machine learning usually rely on a large number of manually predefined ground truth labels. However, it is a laborious and time-consuming task to prepare the dataset. This paper presents a novel technique using a self-supervised 3D-UNet that produces a dense deformation field between an atlas and a target image that can be used for atlas-based segmentation of the ossicles. Our results show that our method outperforms traditional image segmentation methods and generates a more accurate boundary around the ossicles based on Dice similarity coefficient and point-to-point error comparison. The mean Dice coefficient is improved by 8.51% with our proposed method.
Scale-aware Two-stage High Dynamic Range Imaging
Mar 12, 2023
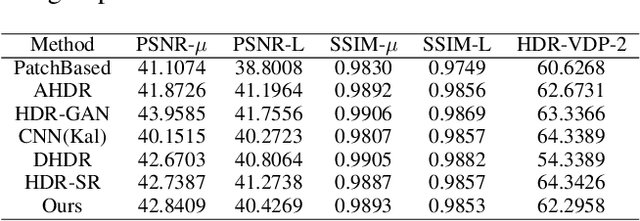
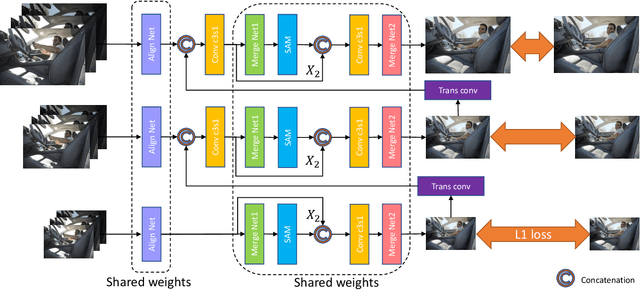
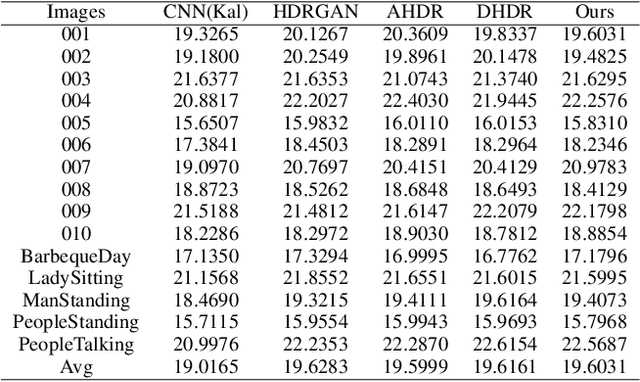
Deep high dynamic range (HDR) imaging as an image translation issue has achieved great performance without explicit optical flow alignment. However, challenges remain over content association ambiguities especially caused by saturation and large-scale movements. To address the ghosting issue and enhance the details in saturated regions, we propose a scale-aware two-stage high dynamic range imaging framework (STHDR) to generate high-quality ghost-free HDR image. The scale-aware technique and two-stage fusion strategy can progressively and effectively improve the HDR composition performance. Specifically, our framework consists of feature alignment and two-stage fusion. In feature alignment, we propose a spatial correct module (SCM) to better exploit useful information among non-aligned features to avoid ghosting and saturation. In the first stage of feature fusion, we obtain a preliminary fusion result with little ghosting. In the second stage, we conflate the results of the first stage with aligned features to further reduce residual artifacts and thus improve the overall quality. Extensive experimental results on the typical test dataset validate the effectiveness of the proposed STHDR in terms of speed and quality.
Training Strategies for Vision Transformers for Object Detection
Apr 05, 2023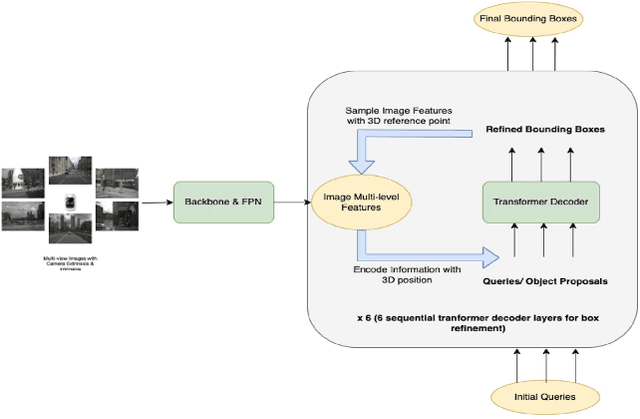


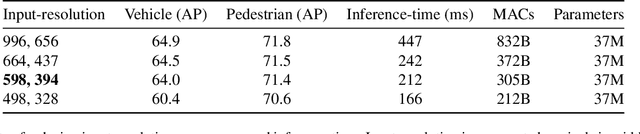
Vision-based Transformer have shown huge application in the perception module of autonomous driving in terms of predicting accurate 3D bounding boxes, owing to their strong capability in modeling long-range dependencies between the visual features. However Transformers, initially designed for language models, have mostly focused on the performance accuracy, and not so much on the inference-time budget. For a safety critical system like autonomous driving, real-time inference at the on-board compute is an absolute necessity. This keeps our object detection algorithm under a very tight run-time budget. In this paper, we evaluated a variety of strategies to optimize on the inference-time of vision transformers based object detection methods keeping a close-watch on any performance variations. Our chosen metric for these strategies is accuracy-runtime joint optimization. Moreover, for actual inference-time analysis we profile our strategies with float32 and float16 precision with TensorRT module. This is the most common format used by the industry for deployment of their Machine Learning networks on the edge devices. We showed that our strategies are able to improve inference-time by 63% at the cost of performance drop of mere 3% for our problem-statement defined in evaluation section. These strategies brings down Vision Transformers detectors inference-time even less than traditional single-image based CNN detectors like FCOS. We recommend practitioners use these techniques to deploy Transformers based hefty multi-view networks on a budge-constrained robotic platform.
Adopting Two Supervisors for Efficient Use of Large-Scale Remote Deep Neural Networks
Apr 05, 2023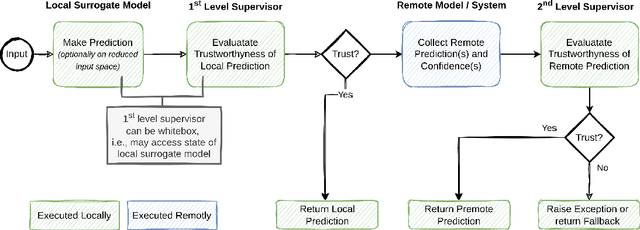
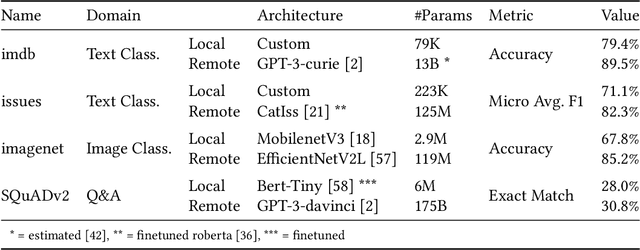
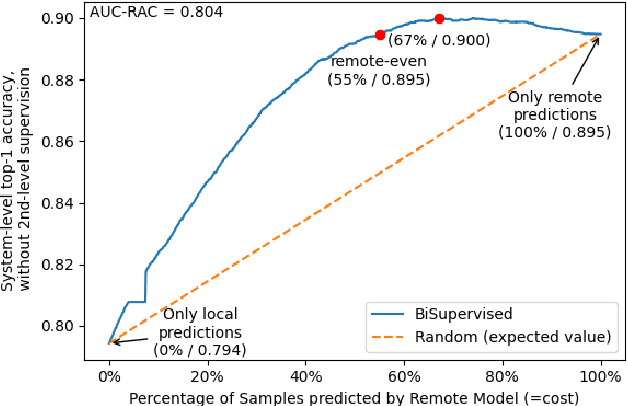
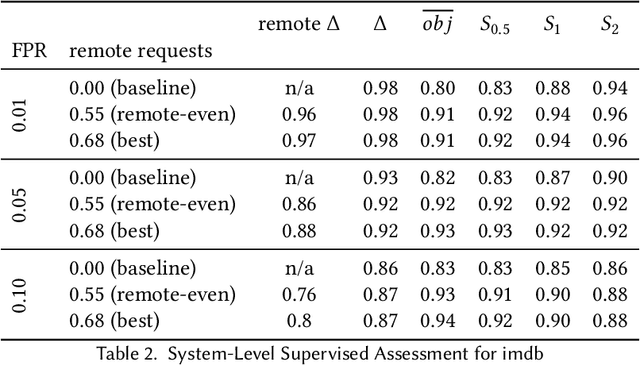
Recent decades have seen the rise of large-scale Deep Neural Networks (DNNs) to achieve human-competitive performance in a variety of artificial intelligence tasks. Often consisting of hundreds of millions, if not hundreds of billion parameters, these DNNs are too large to be deployed to, or efficiently run on resource-constrained devices such as mobile phones or IoT microcontrollers. Systems relying on large-scale DNNs thus have to call the corresponding model over the network, leading to substantial costs for hosting and running the large-scale remote model, costs which are often charged on a per-use basis. In this paper, we propose BiSupervised, a novel architecture, where, before relying on a large remote DNN, a system attempts to make a prediction on a small-scale local model. A DNN supervisor monitors said prediction process and identifies easy inputs for which the local prediction can be trusted. For these inputs, the remote model does not have to be invoked, thus saving costs, while only marginally impacting the overall system accuracy. Our architecture furthermore foresees a second supervisor to monitor the remote predictions and identify inputs for which not even these can be trusted, allowing to raise an exception or run a fallback strategy instead. We evaluate the cost savings, and the ability to detect incorrectly predicted inputs on four diverse case studies: IMDB movie review sentiment classification, Github issue triaging, Imagenet image classification, and SQuADv2 free-text question answering
LogoNet: a fine-grained network for instance-level logo sketch retrieval
Apr 05, 2023

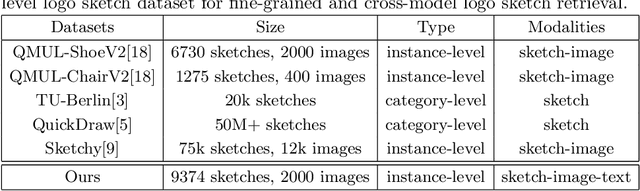
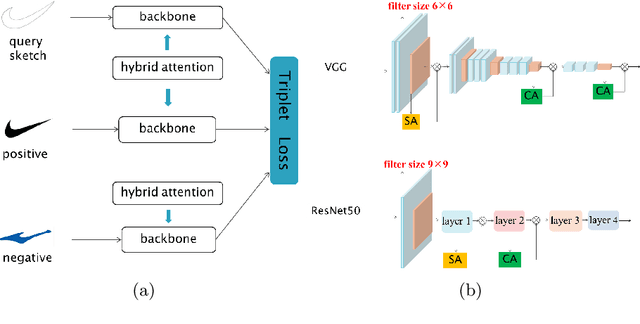
Sketch-based image retrieval, which aims to use sketches as queries to retrieve images containing the same query instance, receives increasing attention in recent years. Although dramatic progress has been made in sketch retrieval, few efforts are devoted to logo sketch retrieval which is still hindered by the following challenges: Firstly, logo sketch retrieval is more difficult than typical sketch retrieval problem, since a logo sketch usually contains much less visual contents with only irregular strokes and lines. Secondly, instance-specific sketches demonstrate dramatic appearance variances, making them less identifiable when querying the same logo instance. Thirdly, there exist several sketch retrieval benchmarking datasets nowadays, whereas an instance-level logo sketch dataset is still publicly unavailable. To address the above-mentioned limitations, we make twofold contributions in this study for instance-level logo sketch retrieval. To begin with, we construct an instance-level logo sketch dataset containing 2k logo instances and exceeding 9k sketches. To our knowledge, this is the first publicly available instance-level logo sketch dataset. Next, we develop a fine-grained triple-branch CNN architecture based on hybrid attention mechanism termed LogoNet for accurate logo sketch retrieval. More specifically, we embed the hybrid attention mechanism into the triple-branch architecture for capturing the key query-specific information from the limited visual cues in the logo sketches. Experimental evaluations both on our assembled dataset and public benchmark datasets demonstrate the effectiveness of our proposed network.
Joint cortical registration of geometry and function using semi-supervised learning
Mar 06, 2023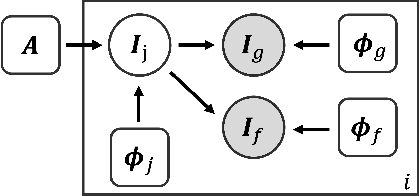
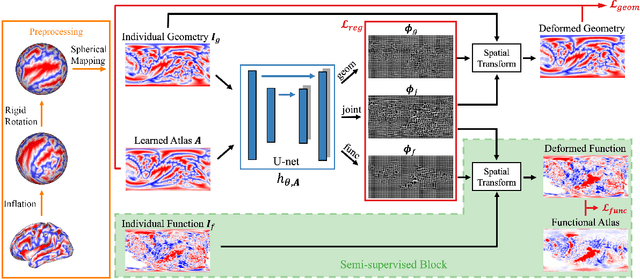
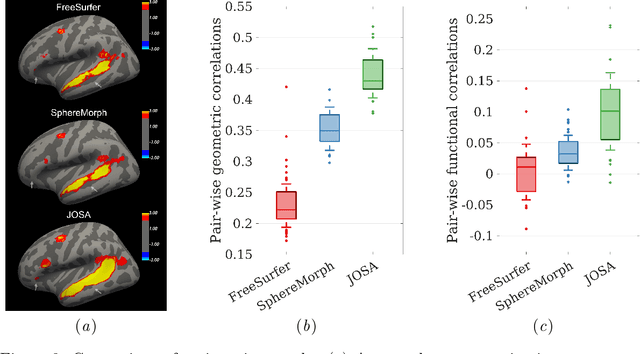
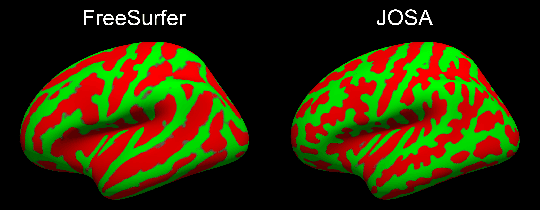
Brain surface-based image registration, an important component of brain image analysis, establishes spatial correspondence between cortical surfaces. Existing iterative and learning-based approaches focus on accurate registration of folding patterns of the cerebral cortex, and assume that geometry predicts function and thus functional areas will also be well aligned. However, structure/functional variability of anatomically corresponding areas across subjects has been widely reported. In this work, we introduce a learning-based cortical registration framework, JOSA, which jointly aligns folding patterns and functional maps while simultaneously learning an optimal atlas. We demonstrate that JOSA can substantially improve registration performance in both anatomical and functional domains over existing methods. By employing a semi-supervised training strategy, the proposed framework obviates the need for functional data during inference, enabling its use in broad neuroscientific domains where functional data may not be observed.
Scapegoat Generation for Privacy Protection from Deepfake
Mar 06, 2023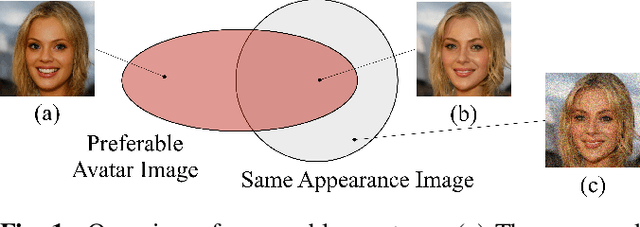
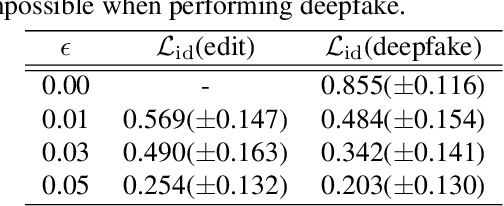
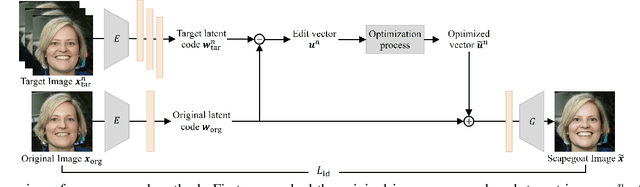
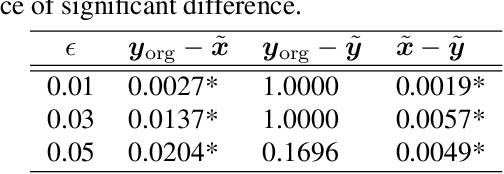
To protect privacy and prevent malicious use of deepfake, current studies propose methods that interfere with the generation process, such as detection and destruction approaches. However, these methods suffer from sub-optimal generalization performance to unseen models and add undesirable noise to the original image. To address these problems, we propose a new problem formulation for deepfake prevention: generating a ``scapegoat image'' by modifying the style of the original input in a way that is recognizable as an avatar by the user, but impossible to reconstruct the real face. Even in the case of malicious deepfake, the privacy of the users is still protected. To achieve this, we introduce an optimization-based editing method that utilizes GAN inversion to discourage deepfake models from generating similar scapegoats. We validate the effectiveness of our proposed method through quantitative and user studies.