 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMesh-Aware Epipolar Matching for Multi-View Multi-Person 3D Pose Estimation in Basketball
May 28, 2026Multi-view multi-person 3D pose estimation in team sports scenarios remains challenging due to player occlusions, appearance similarity caused by team uniforms, and the scarcity of annotated multi-view data, all of which limit the effectiveness and generalization capability of learning-based methods. In contrast, the performance of training-free approaches is inherently constrained by the accuracy of 2D keypoint detection and the robustness of cross-view association. To address these challenges, we propose Mesh-Aware Epipolar Matching (MAEM), a training-free framework for multi-view multi-person 3D pose estimation. Our method employs a monocular 3D human mesh recovery model as the frontend and introduces a two-stage epipolar matching strategy based on the recovered mesh outputs. Specifically, the proposed framework combines disjoint-set-union-based clustering with per-joint triangulation to achieve robust cross-view association and accurate 3D pose reconstruction. Experiments on two public multi-view basketball datasets demonstrate that MAEM consistently outperforms existing training-free association baselines while achieving competitive RGB-only performance in both indoor and outdoor basketball scenarios. MAEM achieves MPJPE/PA-MPJPE scores of 59.8/40.7 mm on SportCenter EPFL and 74.0/51.8 mm on Human-M3 Basketball, highlighting the effectiveness of dense mesh geometry for cross-view association without requiring target-domain training or fine-tuning.
Event-based Batting Impact Estimation
May 25, 2026Estimating the precise timing of batting impact is crucial for understanding the rapid sensorimotor control. However, this task is challenging for RGB cameras due to insufficient temporal resolution and motion blur. Similarly, Inertial Measurement Units (IMUs) are impractical for actual matches due to sensor intrusiveness and their limited temporal precision. To overcome these limitations, we propose a novel framework leveraging event-based cameras, which offer microsecond resolution and high dynamic range, to estimate impact timing based on the weighted centroid distance between the detected ball and bat. To address the domain gap between event frames and RGB images that degrades segmentation accuracy, we generate high-density event frames. We then introduce a mask refinement network that leverages these frames and bidirectional mask information, optimized using a novel loss function. Experiments on real-world datasets demonstrate that our method achieves superior accuracy under challenging conditions, including low-light environments and severe occlusions, outperforming baselines by reducing the Mean Absolute Error by approximately 63%.
Ghost-FWL: A Large-Scale Full-Waveform LiDAR Dataset for Ghost Detection and Removal
Mar 30, 2026LiDAR has become an essential sensing modality in autonomous driving, robotics, and smart-city applications. However, ghost points (or ghosts), which are false reflections caused by multi-path laser returns from glass and reflective surfaces, severely degrade 3D mapping and localization accuracy. Prior ghost removal relies on geometric consistency in dense point clouds, failing on mobile LiDAR's sparse, dynamic data. We address this by exploiting full-waveform LiDAR (FWL), which captures complete temporal intensity profiles rather than just peak distances, providing crucial cues for distinguishing ghosts from genuine reflections in mobile scenarios. As this is a new task, we present Ghost-FWL, the first and largest annotated mobile FWL dataset for ghost detection and removal. Ghost-FWL comprises 24K frames across 10 diverse scenes with 7.5 billion peak-level annotations, which is 100x larger than existing annotated FWL datasets. Benefiting from this large-scale dataset, we establish a FWL-based baseline model for ghost detection and propose FWL-MAE, a masked autoencoder for efficient self-supervised representation learning on FWL data. Experiments show that our baseline outperforms existing methods in ghost removal accuracy, and our ghost removal further enhances downstream tasks such as LiDAR-based SLAM (66% trajectory error reduction) and 3D object detection (50x false positive reduction). The dataset and code is publicly available and can be accessed via the project page: https://keio-csg.github.io/Ghost-FWL
Learning to Assist: Physics-Grounded Human-Human Control via Multi-Agent Reinforcement Learning
Mar 11, 2026Humanoid robotics has strong potential to transform daily service and caregiving applications. Although recent advances in general motion tracking within physics engines (GMT) have enabled virtual characters and humanoid robots to reproduce a broad range of human motions, these behaviors are primarily limited to contact-less social interactions or isolated movements. Assistive scenarios, by contrast, require continuous awareness of a human partner and rapid adaptation to their evolving posture and dynamics. In this paper, we formulate the imitation of closely interacting, force-exchanging human-human motion sequences as a multi-agent reinforcement learning problem. We jointly train partner-aware policies for both the supporter (assistant) agent and the recipient agent in a physics simulator to track assistive motion references. To make this problem tractable, we introduce a partner policies initialization scheme that transfers priors from single-human motion-tracking controllers, greatly improving exploration. We further propose dynamic reference retargeting and contact-promoting reward, which adapt the assistant's reference motion to the recipient's real-time pose and encourage physically meaningful support. We show that AssistMimic is the first method capable of successfully tracking assistive interaction motions on established benchmarks, demonstrating the benefits of a multi-agent RL formulation for physically grounded and socially aware humanoid control.
Image-based Joint-level Detection for Inflammation in Rheumatoid Arthritis from Small and Imbalanced Data
Feb 16, 2026Rheumatoid arthritis (RA) is an autoimmune disease characterized by systemic joint inflammation. Early diagnosis and tight follow-up are essential to the management of RA, as ongoing inflammation can cause irreversible joint damage. The detection of arthritis is important for diagnosis and assessment of disease activity; however, it often takes a long time for patients to receive appropriate specialist care. Therefore, there is a strong need to develop systems that can detect joint inflammation easily using RGB images captured at home. Consequently, we tackle the task of RA inflammation detection from RGB hand images. This task is highly challenging due to general issues in medical imaging, such as the scarcity of positive samples, data imbalance, and the inherent difficulty of the task itself. However, to the best of our knowledge, no existing work has explicitly addressed these challenges in RGB-based RA inflammation detection. This paper quantitatively demonstrates the difficulty of visually detecting inflammation by constructing a dedicated dataset, and we propose a inflammation detection framework with global local encoder that combines self-supervised pretraining on large-scale healthy hand images with imbalance-aware training to detect RA-related joint inflammation from RGB hand images. Our experiments demonstrated that the proposed approach improves F1-score by 0.2 points and Gmean by 0.25 points compared with the baseline model.
Disturbance-Free Surgical Video Generation from Multi-Camera Shadowless Lamps for Open Surgery
Dec 09, 2025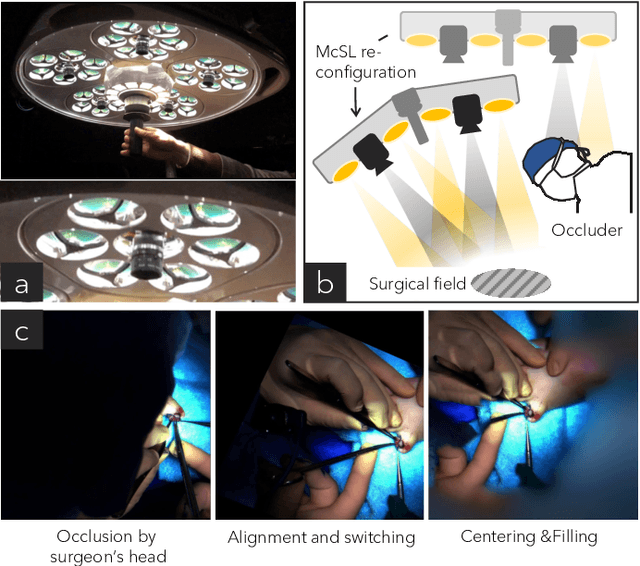
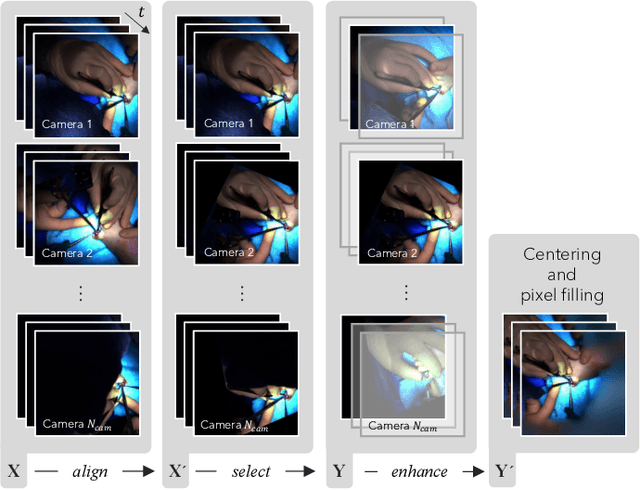
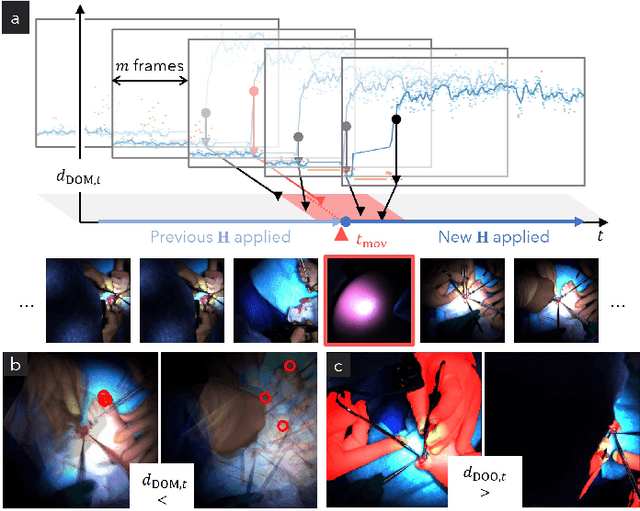
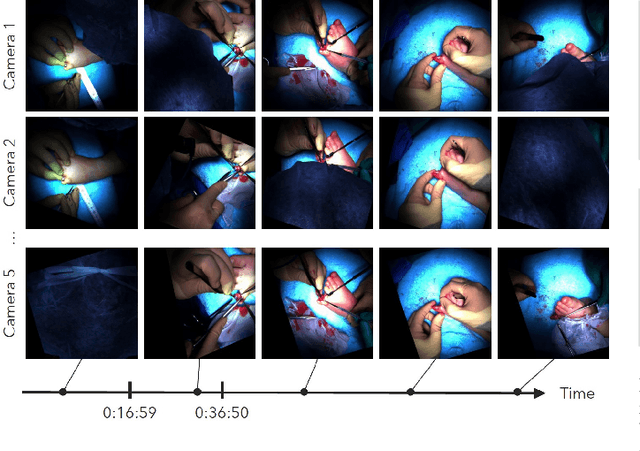
Video recordings of open surgeries are greatly required for education and research purposes. However, capturing unobstructed videos is challenging since surgeons frequently block the camera field of view. To avoid occlusion, the positions and angles of the camera must be frequently adjusted, which is highly labor-intensive. Prior work has addressed this issue by installing multiple cameras on a shadowless lamp and arranging them to fully surround the surgical area. This setup increases the chances of some cameras capturing an unobstructed view. However, manual image alignment is needed in post-processing since camera configurations change every time surgeons move the lamp for optimal lighting. This paper aims to fully automate this alignment task. The proposed method identifies frames in which the lighting system moves, realigns them, and selects the camera with the least occlusion to generate a video that consistently presents the surgical field from a fixed perspective. A user study involving surgeons demonstrated that videos generated by our method were superior to those produced by conventional methods in terms of the ease of confirming the surgical area and the comfort during video viewing. Additionally, our approach showed improvements in video quality over existing techniques. Furthermore, we implemented several synthesis options for the proposed view-synthesis method and conducted a user study to assess surgeons' preferences for each option.
Event-based Egocentric Human Pose Estimation in Dynamic Environment
May 28, 2025Estimating human pose using a front-facing egocentric camera is essential for applications such as sports motion analysis, VR/AR, and AI for wearable devices. However, many existing methods rely on RGB cameras and do not account for low-light environments or motion blur. Event-based cameras have the potential to address these challenges. In this work, we introduce a novel task of human pose estimation using a front-facing event-based camera mounted on the head and propose D-EventEgo, the first framework for this task. The proposed method first estimates the head poses, and then these are used as conditions to generate body poses. However, when estimating head poses, the presence of dynamic objects mixed with background events may reduce head pose estimation accuracy. Therefore, we introduce the Motion Segmentation Module to remove dynamic objects and extract background information. Extensive experiments on our synthetic event-based dataset derived from EgoBody, demonstrate that our approach outperforms our baseline in four out of five evaluation metrics in dynamic environments.
EventEgoHands: Event-based Egocentric 3D Hand Mesh Reconstruction
May 25, 2025Reconstructing 3D hand mesh is challenging but an important task for human-computer interaction and AR/VR applications. In particular, RGB and/or depth cameras have been widely used in this task. However, methods using these conventional cameras face challenges in low-light environments and during motion blur. Thus, to address these limitations, event cameras have been attracting attention in recent years for their high dynamic range and high temporal resolution. Despite their advantages, event cameras are sensitive to background noise or camera motion, which has limited existing studies to static backgrounds and fixed cameras. In this study, we propose EventEgoHands, a novel method for event-based 3D hand mesh reconstruction in an egocentric view. Our approach introduces a Hand Segmentation Module that extracts hand regions, effectively mitigating the influence of dynamic background events. We evaluated our approach and demonstrated its effectiveness on the N-HOT3D dataset, improving MPJPE by approximately more than 4.5 cm (43%).
High-Quality Virtual Single-Viewpoint Surgical Video: Geometric Autocalibration of Multiple Cameras in Surgical Lights
Mar 05, 2025Occlusion-free video generation is challenging due to surgeons' obstructions in the camera field of view. Prior work has addressed this issue by installing multiple cameras on a surgical light, hoping some cameras will observe the surgical field with less occlusion. However, this special camera setup poses a new imaging challenge since camera configurations can change every time surgeons move the light, and manual image alignment is required. This paper proposes an algorithm to automate this alignment task. The proposed method detects frames where the lighting system moves, realigns them, and selects the camera with the least occlusion. This algorithm results in a stabilized video with less occlusion. Quantitative results show that our method outperforms conventional approaches. A user study involving medical doctors also confirmed the superiority of our method.
Dense Depth from Event Focal Stack
Dec 11, 2024We propose a method for dense depth estimation from an event stream generated when sweeping the focal plane of the driving lens attached to an event camera. In this method, a depth map is inferred from an ``event focal stack'' composed of the event stream using a convolutional neural network trained with synthesized event focal stacks. The synthesized event stream is created from a focal stack generated by Blender for any arbitrary 3D scene. This allows for training on scenes with diverse structures. Additionally, we explored methods to eliminate the domain gap between real event streams and synthetic event streams. Our method demonstrates superior performance over a depth-from-defocus method in the image domain on synthetic and real datasets.