 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Probabilistic Prompt Learning for Dense Prediction
Apr 03, 2023
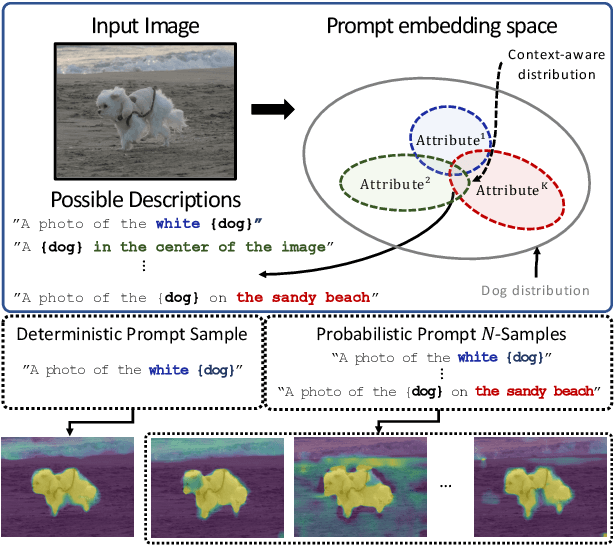
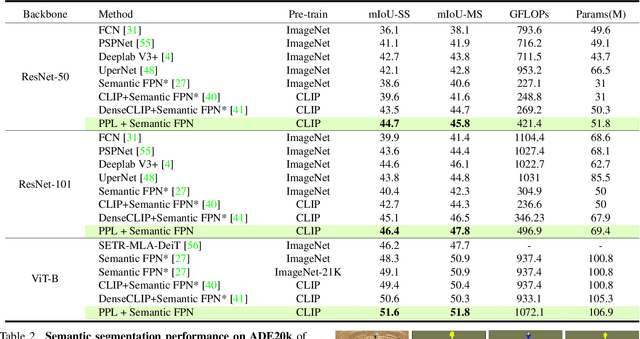
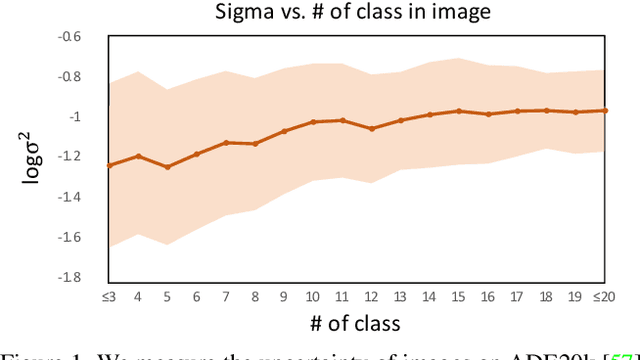

Recent progress in deterministic prompt learning has become a promising alternative to various downstream vision tasks, enabling models to learn powerful visual representations with the help of pre-trained vision-language models. However, this approach results in limited performance for dense prediction tasks that require handling more complex and diverse objects, since a single and deterministic description cannot sufficiently represent the entire image. In this paper, we present a novel probabilistic prompt learning to fully exploit the vision-language knowledge in dense prediction tasks. First, we introduce learnable class-agnostic attribute prompts to describe universal attributes across the object class. The attributes are combined with class information and visual-context knowledge to define the class-specific textual distribution. Text representations are sampled and used to guide the dense prediction task using the probabilistic pixel-text matching loss, enhancing the stability and generalization capability of the proposed method. Extensive experiments on different dense prediction tasks and ablation studies demonstrate the effectiveness of our proposed method.
Rethinking Local Perception in Lightweight Vision Transformer
Apr 03, 2023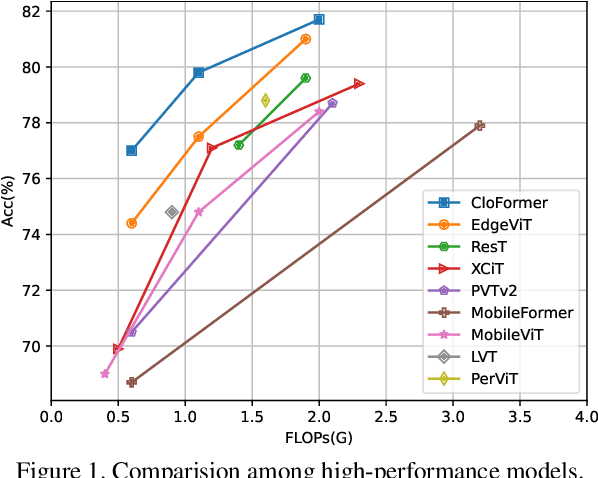
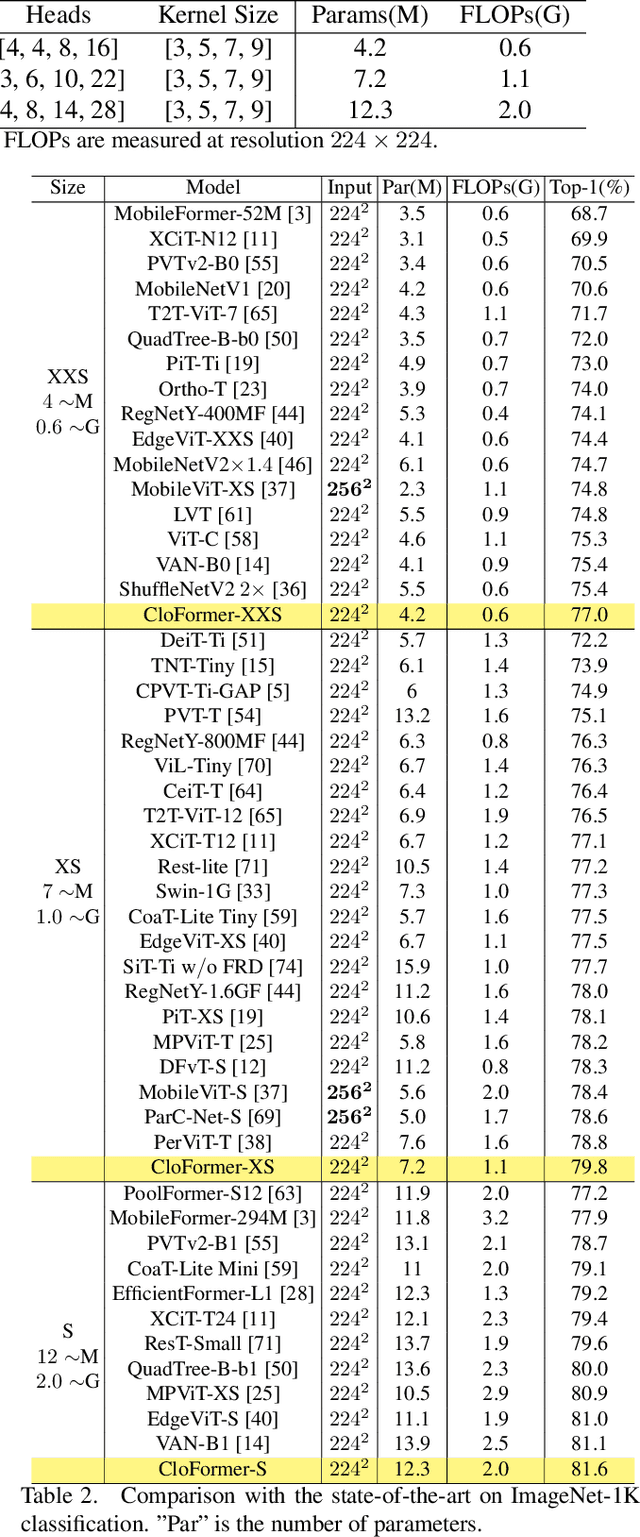
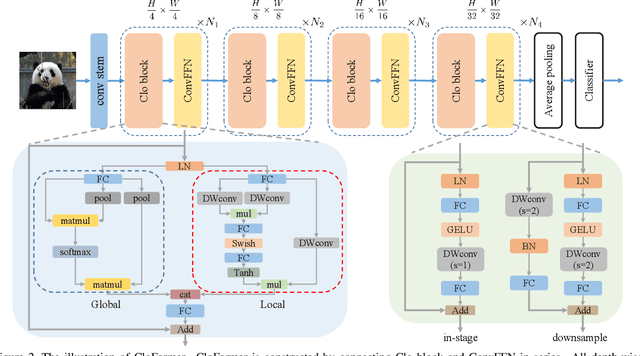
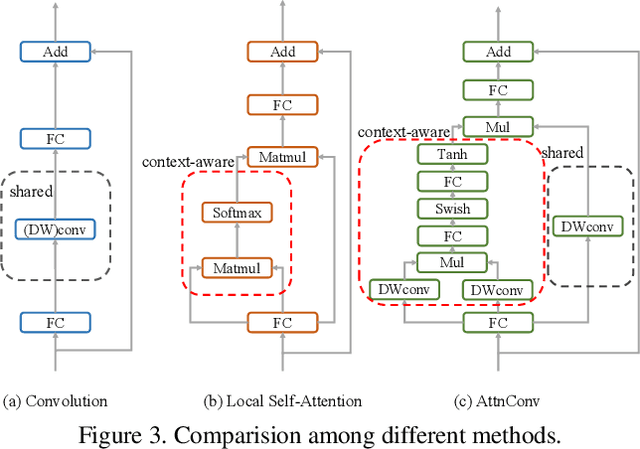
Vision Transformers (ViTs) have been shown to be effective in various vision tasks. However, resizing them to a mobile-friendly size leads to significant performance degradation. Therefore, developing lightweight vision transformers has become a crucial area of research. This paper introduces CloFormer, a lightweight vision transformer that leverages context-aware local enhancement. CloFormer explores the relationship between globally shared weights often used in vanilla convolutional operators and token-specific context-aware weights appearing in attention, then proposes an effective and straightforward module to capture high-frequency local information. In CloFormer, we introduce AttnConv, a convolution operator in attention's style. The proposed AttnConv uses shared weights to aggregate local information and deploys carefully designed context-aware weights to enhance local features. The combination of the AttnConv and vanilla attention which uses pooling to reduce FLOPs in CloFormer enables the model to perceive high-frequency and low-frequency information. Extensive experiments were conducted in image classification, object detection, and semantic segmentation, demonstrating the superiority of CloFormer.
WeakTr: Exploring Plain Vision Transformer for Weakly-supervised Semantic Segmentation
Apr 03, 2023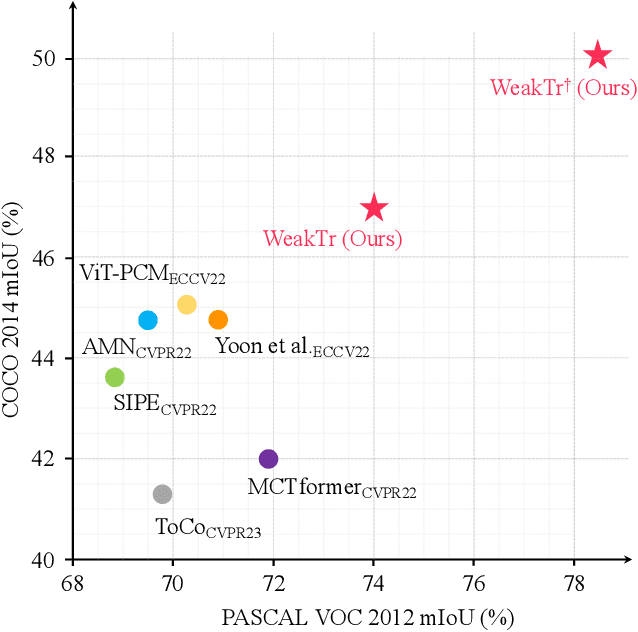
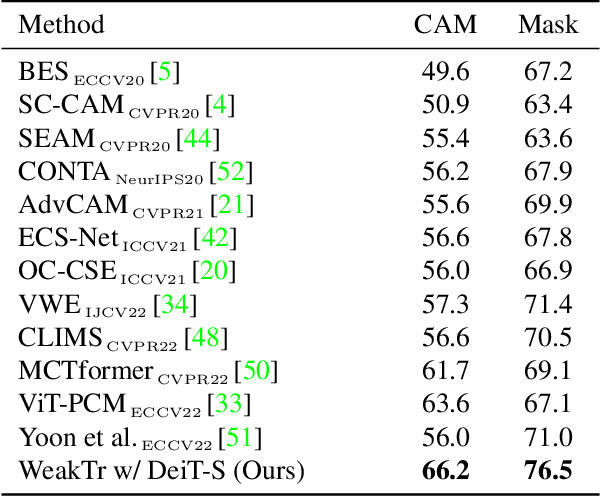
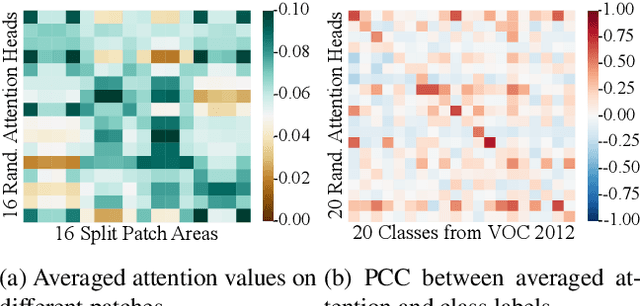

This paper explores the properties of the plain Vision Transformer (ViT) for Weakly-supervised Semantic Segmentation (WSSS). The class activation map (CAM) is of critical importance for understanding a classification network and launching WSSS. We observe that different attention heads of ViT focus on different image areas. Thus a novel weight-based method is proposed to end-to-end estimate the importance of attention heads, while the self-attention maps are adaptively fused for high-quality CAM results that tend to have more complete objects. Besides, we propose a ViT-based gradient clipping decoder for online retraining with the CAM results to complete the WSSS task. We name this plain Transformer-based Weakly-supervised learning framework WeakTr. It achieves the state-of-the-art WSSS performance on standard benchmarks, i.e., 78.4% mIoU on the val set of PASCAL VOC 2012 and 50.3% mIoU on the val set of COCO 2014. Code is available at https://github.com/hustvl/WeakTr.
Evaluating the Effectiveness of 2D and 3D Features for Predicting Tumor Response to Chemotherapy
Apr 14, 2023
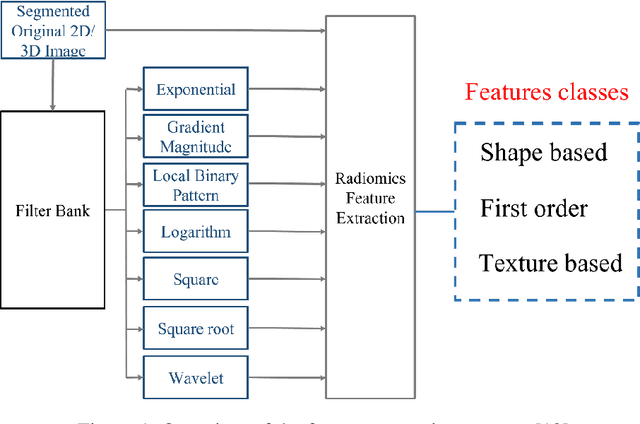

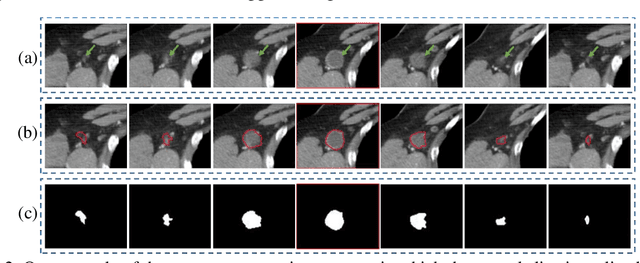
2D and 3D tumor features are widely used in a variety of medical image analysis tasks. However, for chemotherapy response prediction, the effectiveness between different kinds of 2D and 3D features are not comprehensively assessed, especially in ovarian cancer-related applications. This investigation aims to accomplish such a comprehensive evaluation. For this purpose, CT images were collected retrospectively from 188 advanced-stage ovarian cancer patients. All the metastatic tumors that occurred in each patient were segmented and then processed by a set of six filters. Next, three categories of features, namely geometric, density, and texture features, were calculated from both the filtered results and the original segmented tumors, generating a total of 1595 and 1403 features for the 3D and 2D tumors, respectively. In addition to the conventional single-slice 2D and full-volume 3D tumor features, we also computed the incomplete-3D tumor features, which were achieved by sequentially adding one individual CT slice and calculating the corresponding features. Support vector machine (SVM) based prediction models were developed and optimized for each feature set. 5-fold cross-validation was used to assess the performance of each individual model. The results show that the 2D feature-based model achieved an AUC (area under the ROC curve [receiver operating characteristic]) of 0.84+-0.02. When adding more slices, the AUC first increased to reach the maximum and then gradually decreased to 0.86+-0.02. The maximum AUC was yielded when adding two adjacent slices, with a value of 0.91+-0.01. This initial result provides meaningful information for optimizing machine learning-based decision-making support tools in the future.
SpectFormer: Frequency and Attention is what you need in a Vision Transformer
Apr 14, 2023

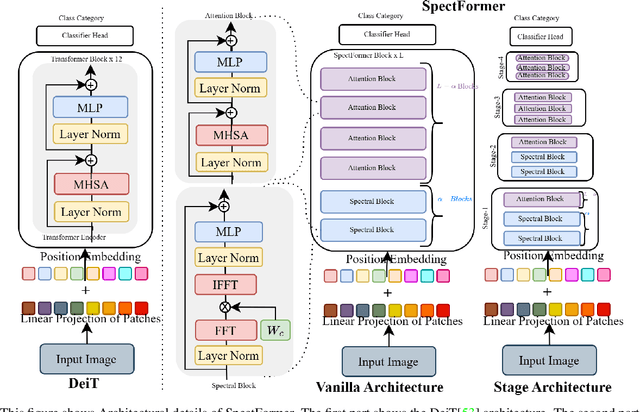
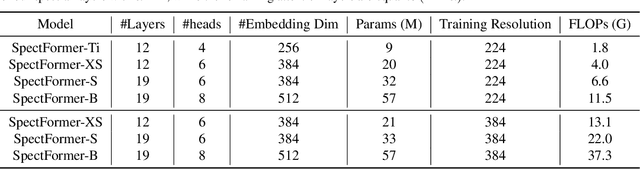
Vision transformers have been applied successfully for image recognition tasks. There have been either multi-headed self-attention based (ViT \cite{dosovitskiy2020image}, DeIT, \cite{touvron2021training}) similar to the original work in textual models or more recently based on spectral layers (Fnet\cite{lee2021fnet}, GFNet\cite{rao2021global}, AFNO\cite{guibas2021efficient}). We hypothesize that both spectral and multi-headed attention plays a major role. We investigate this hypothesis through this work and observe that indeed combining spectral and multi-headed attention layers provides a better transformer architecture. We thus propose the novel Spectformer architecture for transformers that combines spectral and multi-headed attention layers. We believe that the resulting representation allows the transformer to capture the feature representation appropriately and it yields improved performance over other transformer representations. For instance, it improves the top-1 accuracy by 2\% on ImageNet compared to both GFNet-H and LiT. SpectFormer-S reaches 84.25\% top-1 accuracy on ImageNet-1K (state of the art for small version). Further, Spectformer-L achieves 85.7\% that is the state of the art for the comparable base version of the transformers. We further ensure that we obtain reasonable results in other scenarios such as transfer learning on standard datasets such as CIFAR-10, CIFAR-100, Oxford-IIIT-flower, and Standford Car datasets. We then investigate its use in downstream tasks such of object detection and instance segmentation on the MS-COCO dataset and observe that Spectformer shows consistent performance that is comparable to the best backbones and can be further optimized and improved. Hence, we believe that combined spectral and attention layers are what are needed for vision transformers.
Human-machine Interactive Tissue Prototype Learning for Label-efficient Histopathology Image Segmentation
Nov 26, 2022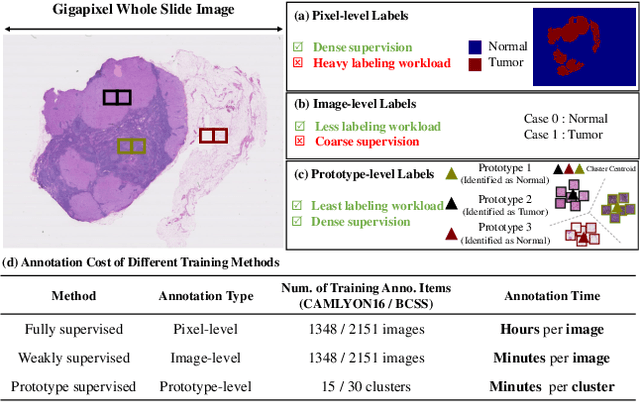
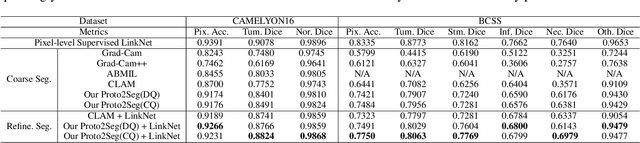
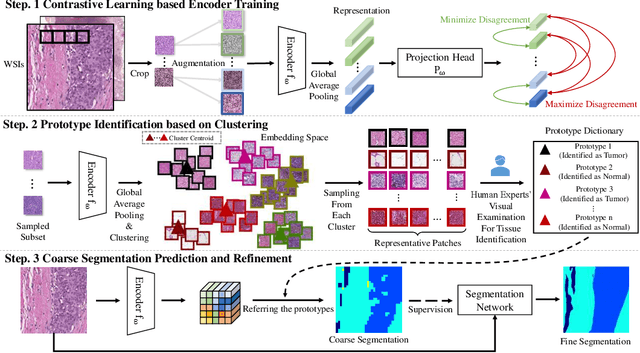

Recently, deep neural networks have greatly advanced histopathology image segmentation but usually require abundant annotated data. However, due to the gigapixel scale of whole slide images and pathologists' heavy daily workload, obtaining pixel-level labels for supervised learning in clinical practice is often infeasible. Alternatively, weakly-supervised segmentation methods have been explored with less laborious image-level labels, but their performance is unsatisfactory due to the lack of dense supervision. Inspired by the recent success of self-supervised learning methods, we present a label-efficient tissue prototype dictionary building pipeline and propose to use the obtained prototypes to guide histopathology image segmentation. Particularly, taking advantage of self-supervised contrastive learning, an encoder is trained to project the unlabeled histopathology image patches into a discriminative embedding space where these patches are clustered to identify the tissue prototypes by efficient pathologists' visual examination. Then, the encoder is used to map the images into the embedding space and generate pixel-level pseudo tissue masks by querying the tissue prototype dictionary. Finally, the pseudo masks are used to train a segmentation network with dense supervision for better performance. Experiments on two public datasets demonstrate that our human-machine interactive tissue prototype learning method can achieve comparable segmentation performance as the fully-supervised baselines with less annotation burden and outperform other weakly-supervised methods. Codes will be available upon publication.
How to Construct Energy for Images? Denoising Autoencoder Can Be Energy Based Model
Mar 05, 2023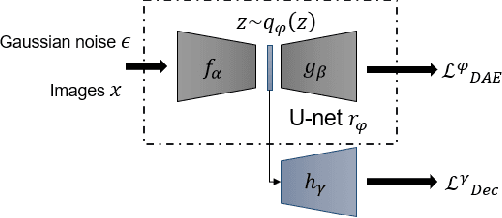
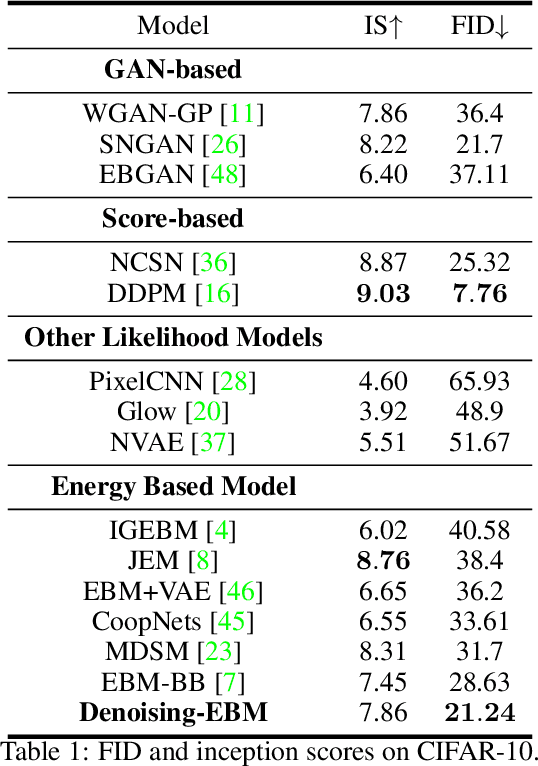
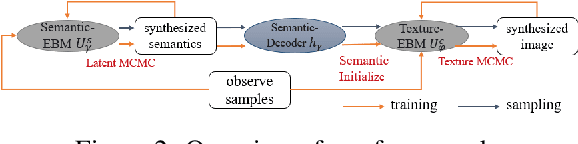
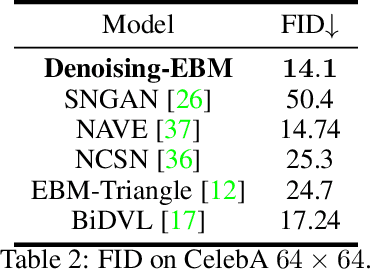
Energy-based models parameterize the unnormalized log-probability of data samples, but there is a lack of guidance on how to construct the "energy". In this paper, we propose a Denoising-EBM which decomposes the image energy into "semantic energy" and "texture energy". We define the "semantic energy" in the latent space of DAE to model the high-level representations, and define the pixel-level reconstruction error for denoising as "texture energy". Inspired by score-based model, our model utilizes multi-scale noisy samples for maximum-likelihood training and it outputs a vector instead of a scalar for exploring a larger set of functions during optimization. After training, the semantics are first synthesized by fast MCMC through "semantic energy", and then the pixel-level refinement of semantic image will be performed to generate perfect samples based on "texture energy". Ultimately, our model can outperform most EBMs in image generation. And we also demonstrate that Denoising-EBM has top performance among EBMs for out-of-distribution detection.
Interactive Text Generation
Mar 17, 2023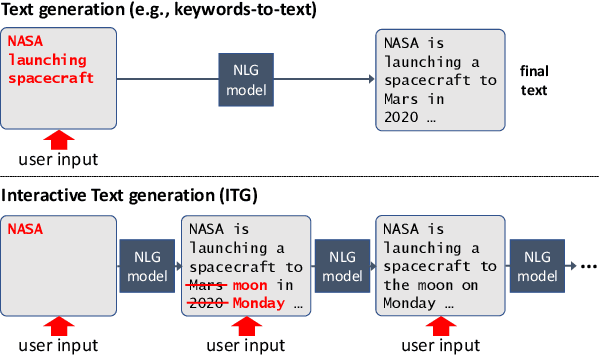
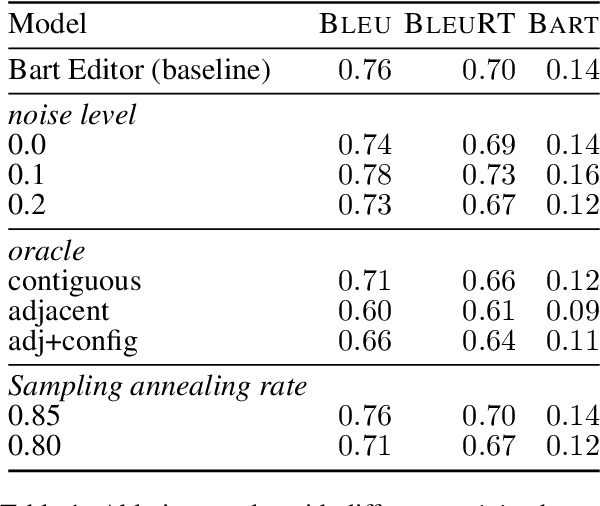
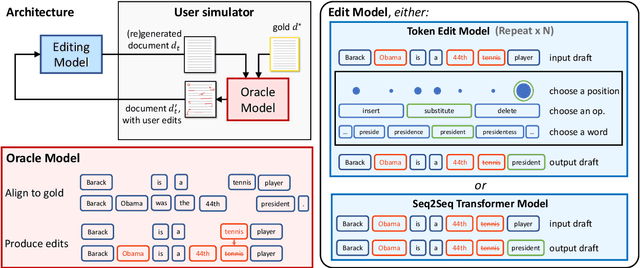
Users interact with text, image, code, or other editors on a daily basis. However, machine learning models are rarely trained in the settings that reflect the interactivity between users and their editor. This is understandable as training AI models with real users is not only slow and costly, but what these models learn may be specific to user interface design choices. Unfortunately, this means most of the research on text, code, and image generation has focused on non-interactive settings, whereby the model is expected to get everything right without accounting for any input from a user who may be willing to help. We introduce a new Interactive Text Generation task that allows training generation models interactively without the costs of involving real users, by using user simulators that provide edits that guide the model towards a given target text. We train our interactive models using Imitation Learning, and our experiments against competitive non-interactive generation models show that models trained interactively are superior to their non-interactive counterparts, even when all models are given the same budget of user inputs or edits.
A Generative Model for Digital Camera Noise Synthesis
Mar 17, 2023
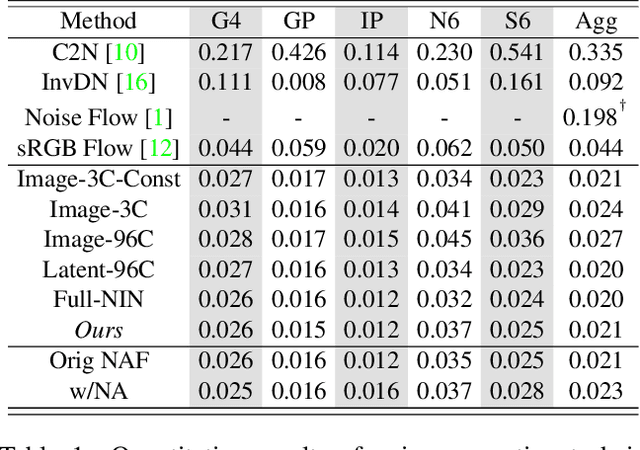
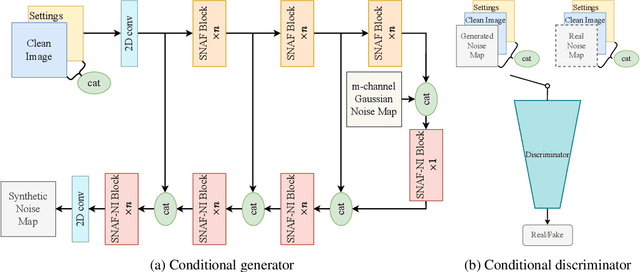
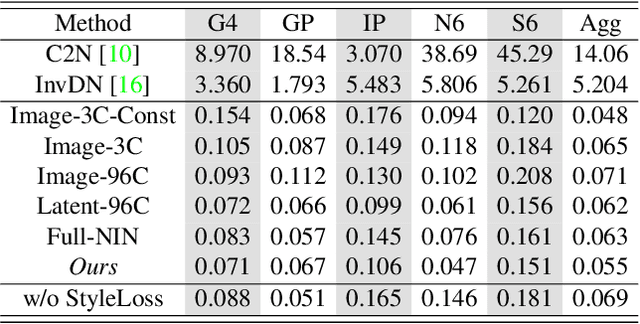
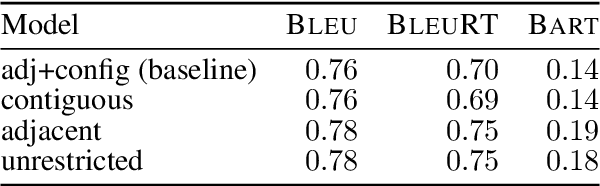
Noise synthesis is a challenging low-level vision task aiming to generate realistic noise given a clean image along with the camera settings. To this end, we propose an effective generative model which utilizes clean features as guidance followed by noise injections into the network. Specifically, our generator follows a UNet-like structure with skip connections but without downsampling and upsampling layers. Firstly, we extract deep features from a clean image as the guidance and concatenate a Gaussian noise map to the transition point between the encoder and decoder as the noise source. Secondly, we propose noise synthesis blocks in the decoder in each of which we inject Gaussian noise to model the noise characteristics. Thirdly, we propose to utilize an additional Style Loss and demonstrate that this allows better noise characteristics supervision in the generator. Through a number of new experiments, we evaluate the temporal variance and the spatial correlation of the generated noise which we hope can provide meaningful insights for future works. Finally, we show that our proposed approach outperforms existing methods for synthesizing camera noise.
Stochastic Segmentation with Conditional Categorical Diffusion Models
Mar 17, 2023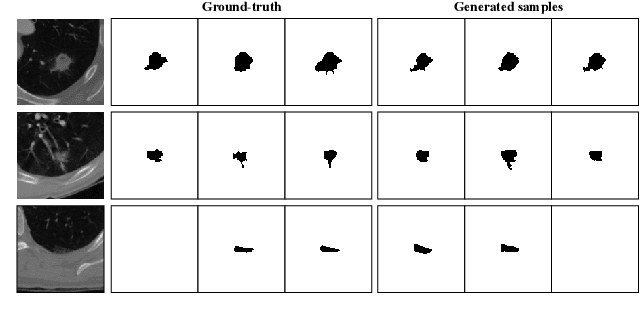
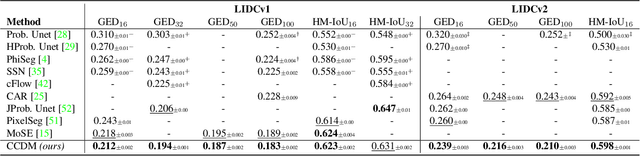
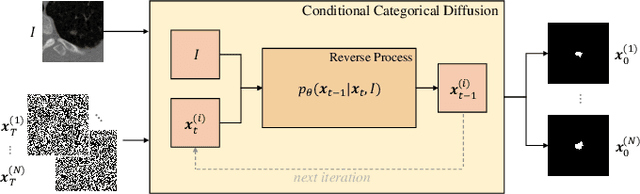
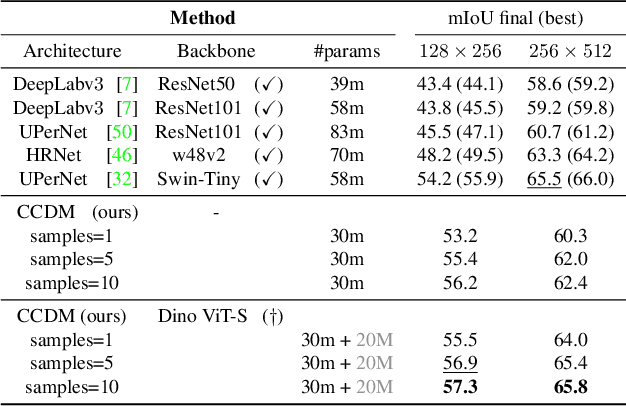
Semantic segmentation has made significant progress in recent years thanks to deep neural networks, but the common objective of generating a single segmentation output that accurately matches the image's content may not be suitable for safety-critical domains such as medical diagnostics and autonomous driving. Instead, multiple possible correct segmentation maps may be required to reflect the true distribution of annotation maps. In this context, stochastic semantic segmentation methods must learn to predict conditional distributions of labels given the image, but this is challenging due to the typically multimodal distributions, high-dimensional output spaces, and limited annotation data. To address these challenges, we propose a conditional categorical diffusion model (CCDM) for semantic segmentation based on Denoising Diffusion Probabilistic Models. Our model is conditioned to the input image, enabling it to generate multiple segmentation label maps that account for the aleatoric uncertainty arising from divergent ground truth annotations. Our experimental results show that CCDM achieves state-of-the-art performance on LIDC, a stochastic semantic segmentation dataset, and outperforms established baselines on the classical segmentation dataset Cityscapes.