 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
IC3D: Image-Conditioned 3D Diffusion for Shape Generation
Nov 20, 2022
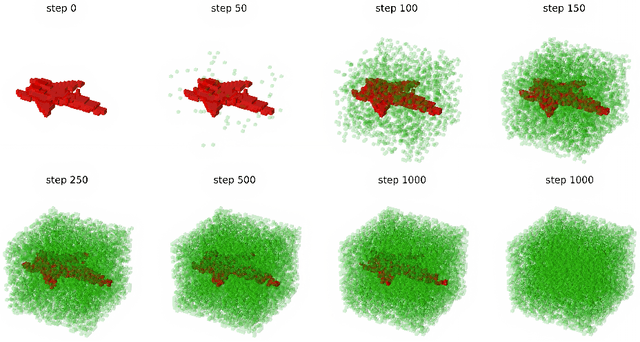
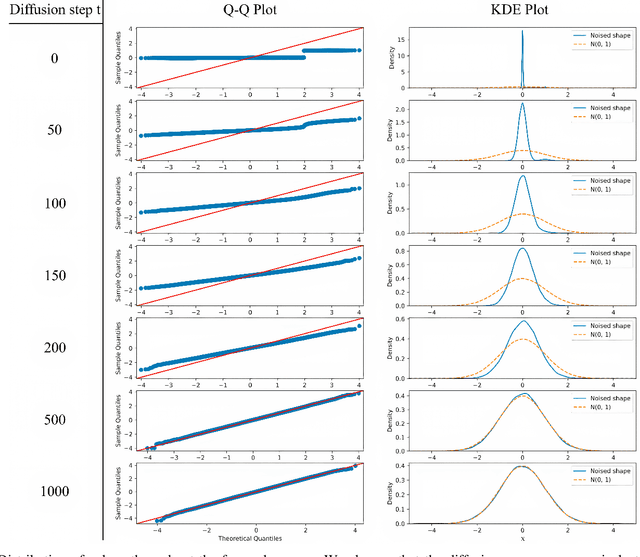
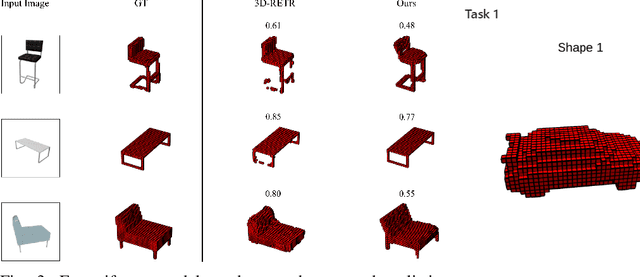
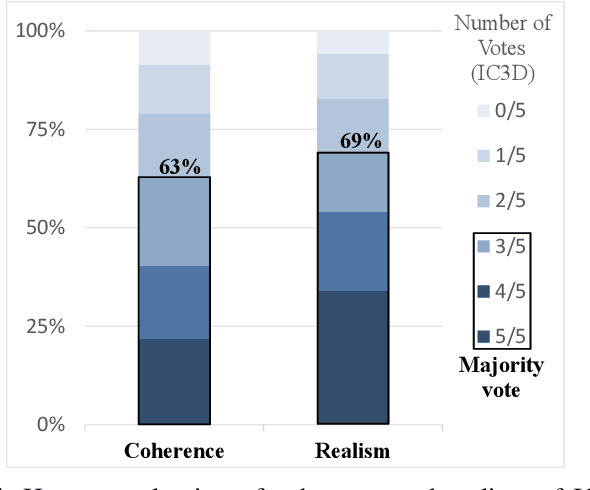
In the last years, Denoising Diffusion Probabilistic Models (DDPMs) obtained state-of-the-art results in many generative tasks, outperforming GANs and other classes of generative models. In particular, they reached impressive results in various image generation sub-tasks, among which conditional generation tasks such as text-guided image synthesis. Given the success of DDPMs in 2D generation, they have more recently been applied to 3D shape generation, outperforming previous approaches and reaching state-of-the-art results. However, 3D data pose additional challenges, such as the choice of the 3D representation, which impacts design choices and model efficiency. While reaching state-of-the-art results in generation quality, existing 3D DDPM works make little or no use of guidance, mainly being unconditional or class-conditional. In this paper, we present IC3D, the first Image-Conditioned 3D Diffusion model that generates 3D shapes by image guidance. It is also the first 3D DDPM model that adopts voxels as a 3D representation. To guide our DDPM, we present and leverage CISP (Contrastive Image-Shape Pre-training), a model jointly embedding images and shapes by contrastive pre-training, inspired by text-to-image DDPM works. Our generative diffusion model outperforms the state-of-the-art in 3D generation quality and diversity. Furthermore, we show that our generated shapes are preferred by human evaluators to a SoTA single-view 3D reconstruction model in terms of quality and coherence to the query image by running a side-by-side human evaluation.
Synthetic Data from Diffusion Models Improves ImageNet Classification
Apr 17, 2023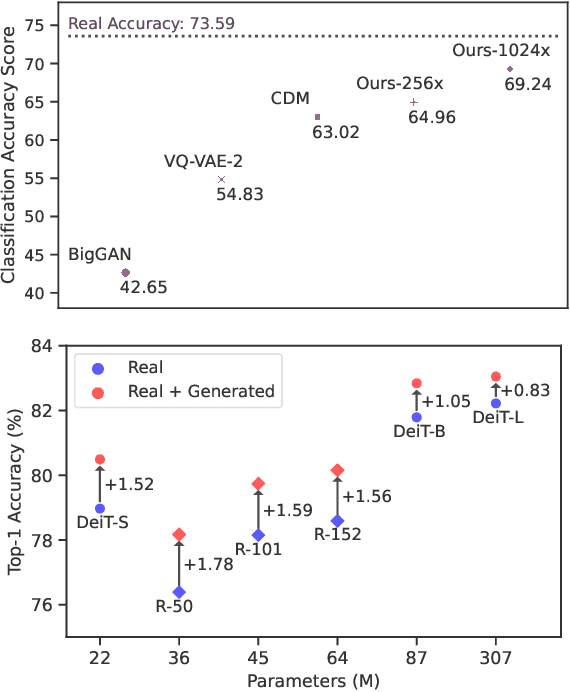
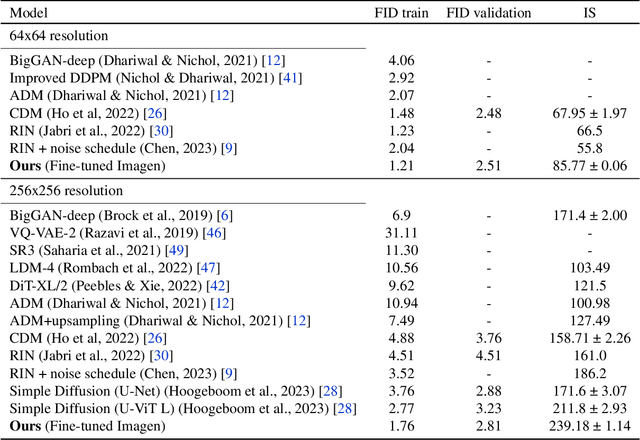

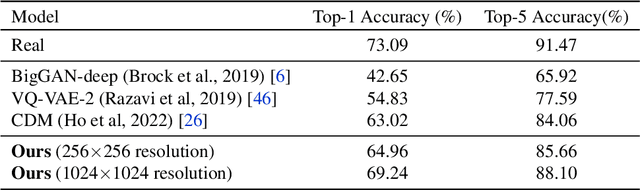
Deep generative models are becoming increasingly powerful, now generating diverse high fidelity photo-realistic samples given text prompts. Have they reached the point where models of natural images can be used for generative data augmentation, helping to improve challenging discriminative tasks? We show that large-scale text-to image diffusion models can be fine-tuned to produce class conditional models with SOTA FID (1.76 at 256x256 resolution) and Inception Score (239 at 256x256). The model also yields a new SOTA in Classification Accuracy Scores (64.96 for 256x256 generative samples, improving to 69.24 for 1024x1024 samples). Augmenting the ImageNet training set with samples from the resulting models yields significant improvements in ImageNet classification accuracy over strong ResNet and Vision Transformer baselines.
DiffStyler: Controllable Dual Diffusion for Text-Driven Image Stylization
Nov 19, 2022
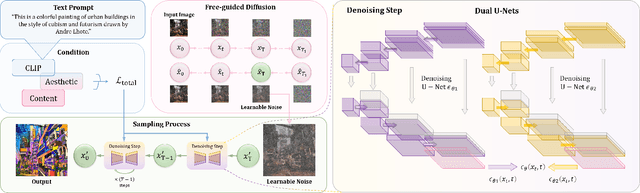
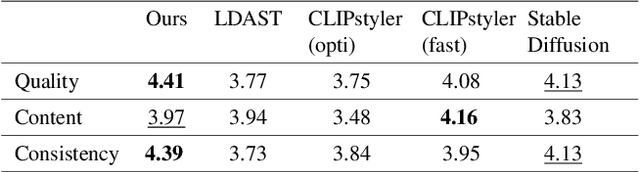

Despite the impressive results of arbitrary image-guided style transfer methods, text-driven image stylization has recently been proposed for transferring a natural image into the stylized one according to textual descriptions of the target style provided by the user. Unlike previous image-to-image transfer approaches, text-guided stylization progress provides users with a more precise and intuitive way to express the desired style. However, the huge discrepancy between cross-modal inputs/outputs makes it challenging to conduct text-driven image stylization in a typical feed-forward CNN pipeline. In this paper, we present DiffStyler on the basis of diffusion models. The cross-modal style information can be easily integrated as guidance during the diffusion progress step-by-step. In particular, we use a dual diffusion processing architecture to control the balance between the content and style of the diffused results. Furthermore, we propose a content image-based learnable noise on which the reverse denoising process is based, enabling the stylization results to better preserve the structure information of the content image. We validate the proposed DiffStyler beyond the baseline methods through extensive qualitative and quantitative experiments.
SinFusion: Training Diffusion Models on a Single Image or Video
Nov 21, 2022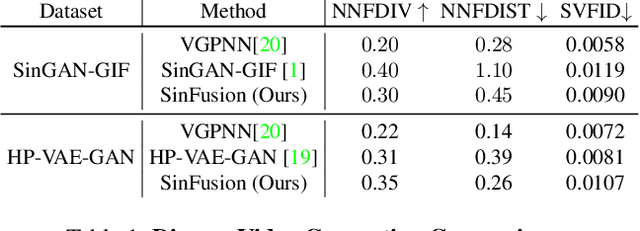

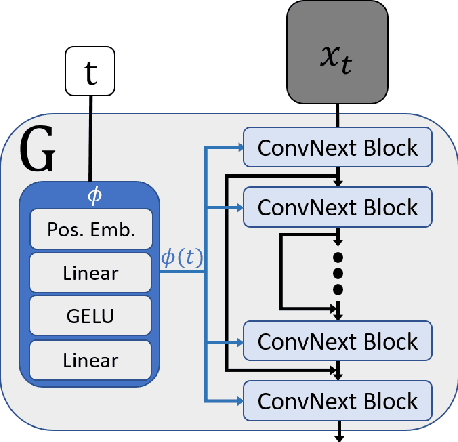

Diffusion models exhibited tremendous progress in image and video generation, exceeding GANs in quality and diversity. However, they are usually trained on very large datasets and are not naturally adapted to manipulate a given input image or video. In this paper we show how this can be resolved by training a diffusion model on a single input image or video. Our image/video-specific diffusion model (SinFusion) learns the appearance and dynamics of the single image or video, while utilizing the conditioning capabilities of diffusion models. It can solve a wide array of image/video-specific manipulation tasks. In particular, our model can learn from few frames the motion and dynamics of a single input video. It can then generate diverse new video samples of the same dynamic scene, extrapolate short videos into long ones (both forward and backward in time) and perform video upsampling. When trained on a single image, our model shows comparable performance and capabilities to previous single-image models in various image manipulation tasks.
You Never Get a Second Chance To Make a Good First Impression: Seeding Active Learning for 3D Semantic Segmentation
Apr 23, 2023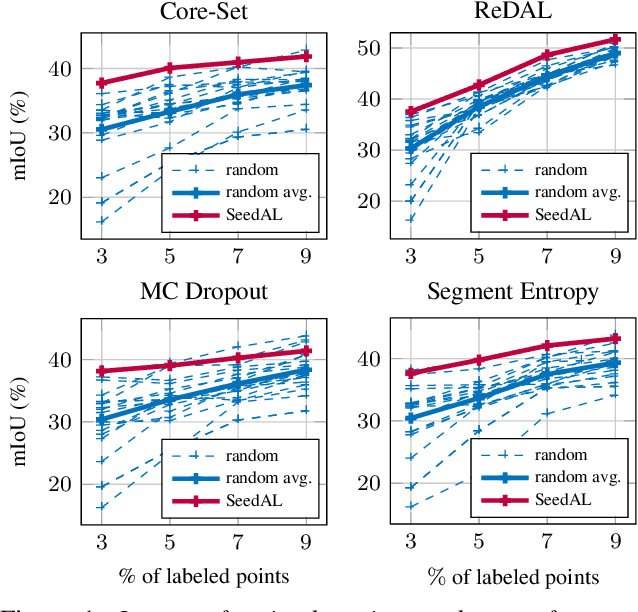
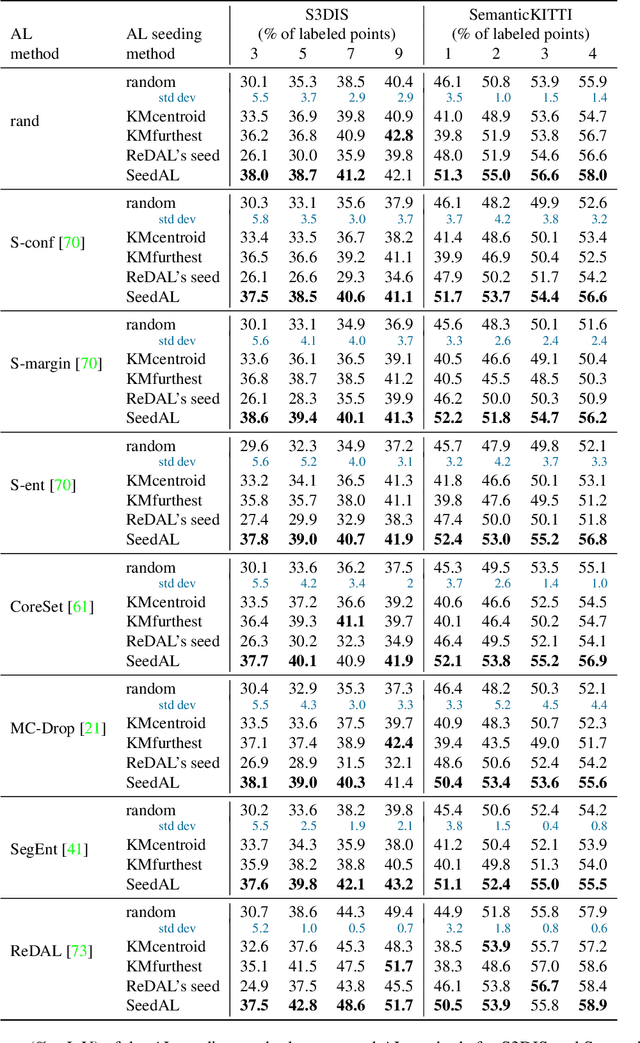
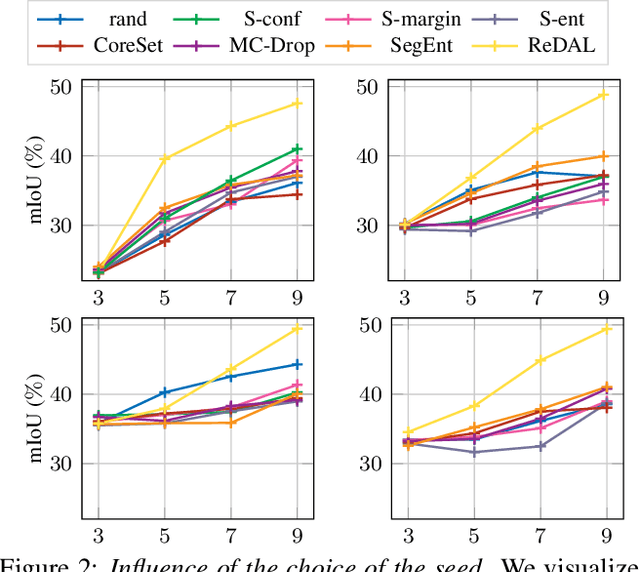
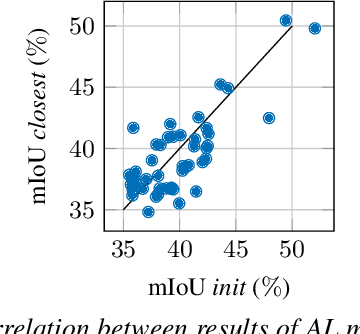
We propose SeedAL, a method to seed active learning for efficient annotation of 3D point clouds for semantic segmentation. Active Learning (AL) iteratively selects relevant data fractions to annotate within a given budget, but requires a first fraction of the dataset (a 'seed') to be already annotated to estimate the benefit of annotating other data fractions. We first show that the choice of the seed can significantly affect the performance of many AL methods. We then propose a method for automatically constructing a seed that will ensure good performance for AL. Assuming that images of the point clouds are available, which is common, our method relies on powerful unsupervised image features to measure the diversity of the point clouds. It selects the point clouds for the seed by optimizing the diversity under an annotation budget, which can be done by solving a linear optimization problem. Our experiments demonstrate the effectiveness of our approach compared to random seeding and existing methods on both the S3DIS and SemanticKitti datasets. Code is available at \url{https://github.com/nerminsamet/seedal}.
PiClick: Picking the desired mask in click-based interactive segmentation
Apr 23, 2023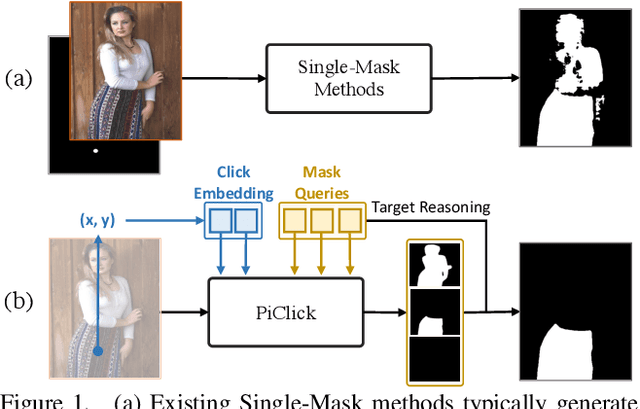
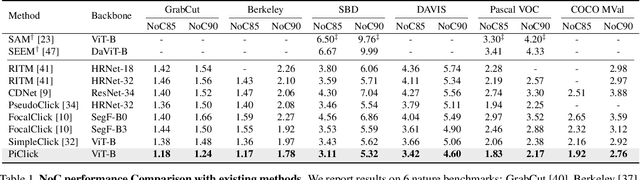
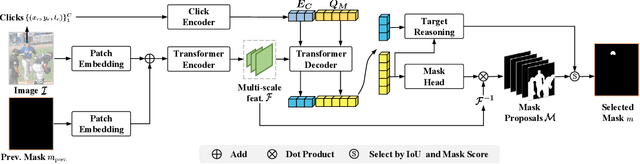
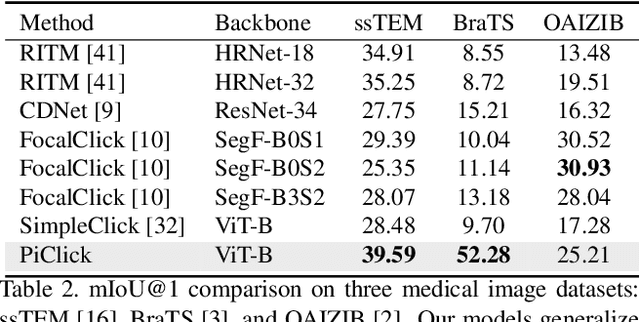
Click-based interactive segmentation enables productive pixel-level annotation and image editing with simple user clicks, whereas target ambiguity remains a problem hindering precise segmentation. That is, in scenes with rich context, one click may refer to multiple potential targets residing in corresponding masks, while most interactive segmentors can only generate one single mask and fail to capture the rich context. To resolve target ambiguity, we here propose PiClick to produce semantically diversified masks. PiClick leverages a transformer network design wherein mutually interactive mask queries are integrated to infuse target priors. Moreover, a Target Reasoning Module is designed in PiClick to automatically imply the best-matched mask from all proposals, significantly relieving target ambiguity as well as extra human intervention. Extensive experiments conducted on all 9 interactive segmentation datasets not only demonstrate the state-of-the-art segmentation performance of PiClick, but also reduces human interventions with multiple proposal generation and target reasoning. To promote direct usage and future endeavors, we release the source code of PiClick together with a plug-and-play annotation tool at https://github.com/cilinyan/PiClick.
UniCal: a Single-Branch Transformer-Based Model for Camera-to-LiDAR Calibration and Validation
Apr 19, 2023
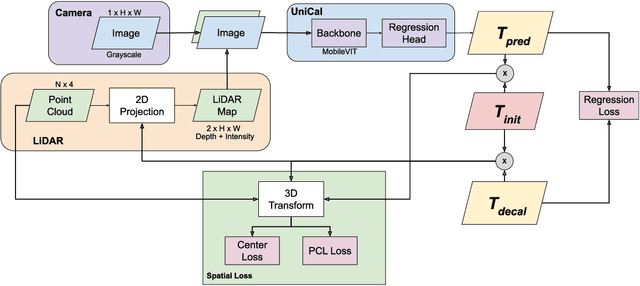

We introduce a novel architecture, UniCal, for Camera-to-LiDAR (C2L) extrinsic calibration which leverages self-attention mechanisms through a Transformer-based backbone network to infer the 6-degree of freedom (DoF) relative transformation between the sensors. Unlike previous methods, UniCal performs an early fusion of the input camera and LiDAR data by aggregating camera image channels and LiDAR mappings into a multi-channel unified representation before extracting their features jointly with a single-branch architecture. This single-branch architecture makes UniCal lightweight, which is desirable in applications with restrained resources such as autonomous driving. Through experiments, we show that UniCal achieves state-of-the-art results compared to existing methods. We also show that through transfer learning, weights learned on the calibration task can be applied to a calibration validation task without re-training the backbone.
Nerfbusters: Removing Ghostly Artifacts from Casually Captured NeRFs
Apr 20, 2023


Casually captured Neural Radiance Fields (NeRFs) suffer from artifacts such as floaters or flawed geometry when rendered outside the camera trajectory. Existing evaluation protocols often do not capture these effects, since they usually only assess image quality at every 8th frame of the training capture. To push forward progress in novel-view synthesis, we propose a new dataset and evaluation procedure, where two camera trajectories are recorded of the scene: one used for training, and the other for evaluation. In this more challenging in-the-wild setting, we find that existing hand-crafted regularizers do not remove floaters nor improve scene geometry. Thus, we propose a 3D diffusion-based method that leverages local 3D priors and a novel density-based score distillation sampling loss to discourage artifacts during NeRF optimization. We show that this data-driven prior removes floaters and improves scene geometry for casual captures.
A baseline on continual learning methods for video action recognition
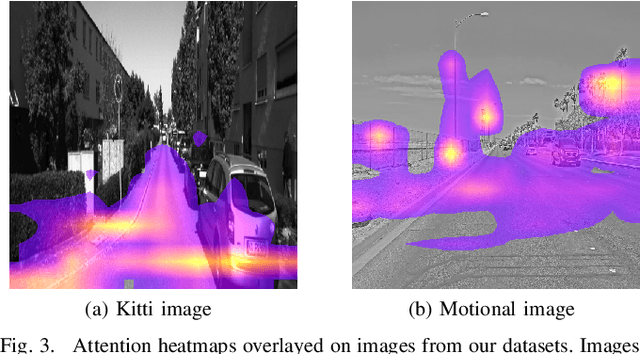
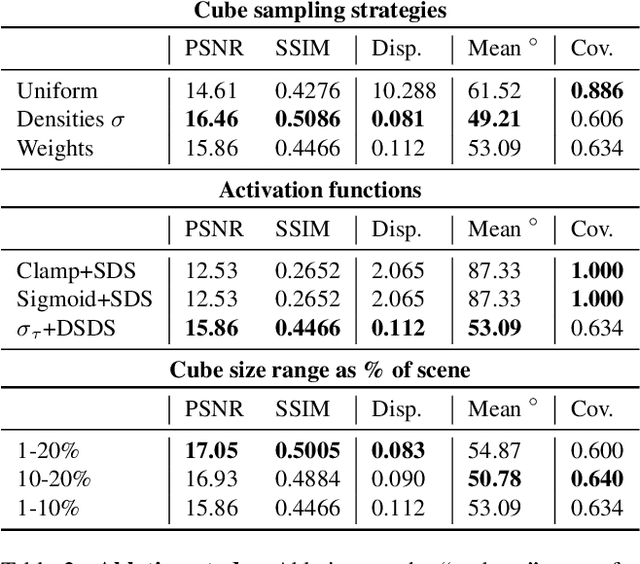
Apr 20, 2023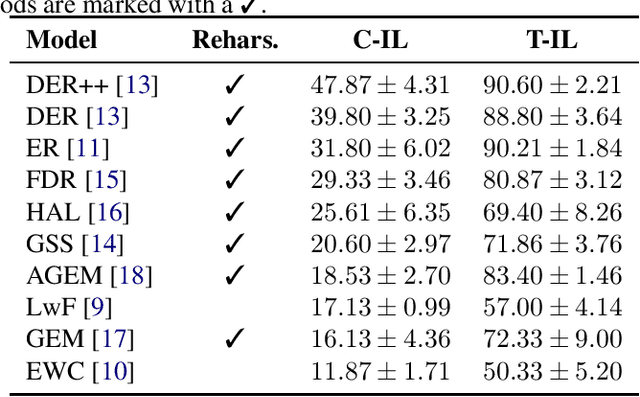
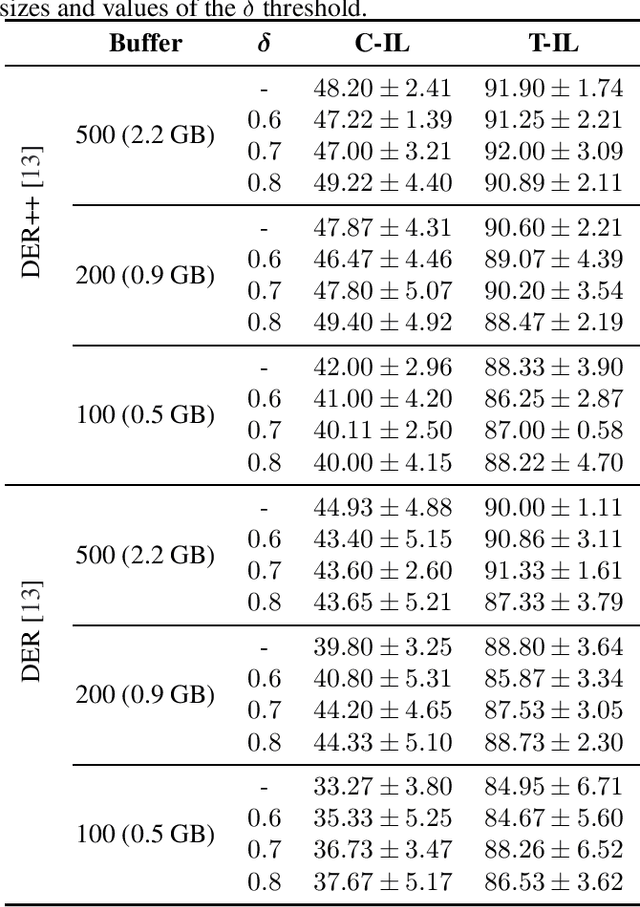
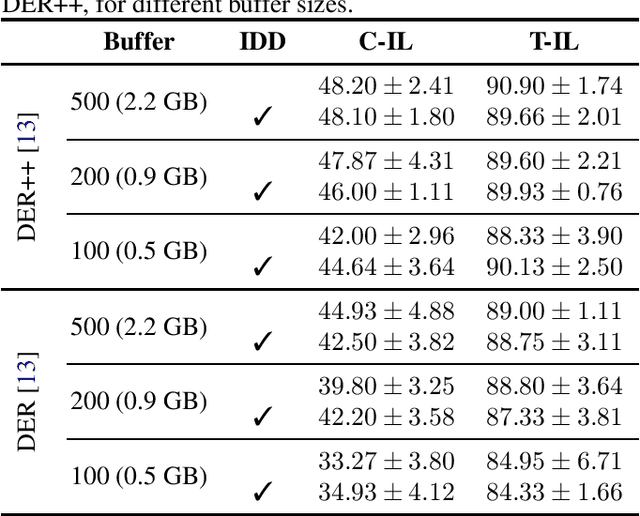
Continual learning has recently attracted attention from the research community, as it aims to solve long-standing limitations of classic supervisedly-trained models. However, most research on this subject has tackled continual learning in simple image classification scenarios. In this paper, we present a benchmark of state-of-the-art continual learning methods on video action recognition. Besides the increased complexity due to the temporal dimension, the video setting imposes stronger requirements on computing resources for top-performing rehearsal methods. To counteract the increased memory requirements, we present two method-agnostic variants for rehearsal methods, exploiting measures of either model confidence or data information to select memorable samples. Our experiments show that, as expected from the literature, rehearsal methods outperform other approaches; moreover, the proposed memory-efficient variants are shown to be effective at retaining a certain level of performance with a smaller buffer size.
TruFor: Leveraging all-round clues for trustworthy image forgery detection and localization
Dec 21, 2022
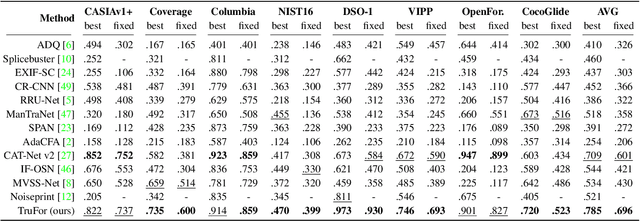
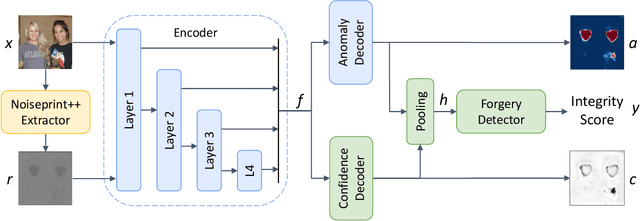
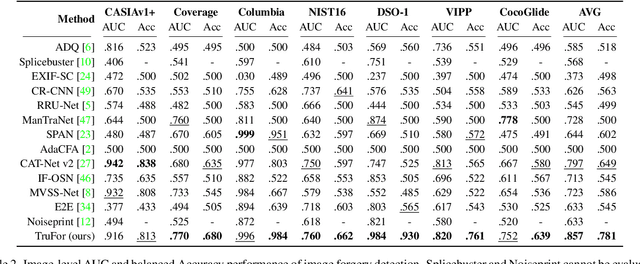
In this paper we present TruFor, a forensic framework that can be applied to a large variety of image manipulation methods, from classic cheapfakes to more recent manipulations based on deep learning. We rely on the extraction of both high-level and low-level traces through a transformer-based fusion architecture that combines the RGB image and a learned noise-sensitive fingerprint. The latter learns to embed the artifacts related to the camera internal and external processing by training only on real data in a self-supervised manner. Forgeries are detected as deviations from the expected regular pattern that characterizes each pristine image. Looking for anomalies makes the approach able to robustly detect a variety of local manipulations, ensuring generalization. In addition to a pixel-level localization map and a whole-image integrity score, our approach outputs a reliability map that highlights areas where localization predictions may be error-prone. This is particularly important in forensic applications in order to reduce false alarms and allow for a large scale analysis. Extensive experiments on several datasets show that our method is able to reliably detect and localize both cheapfakes and deepfakes manipulations outperforming state-of-the-art works. Code will be publicly available at https://grip-unina.github.io/TruFor/