 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ContraNeRF: 3D-Aware Generative Model via Contrastive Learning with Unsupervised Implicit Pose Embedding
Apr 27, 2023
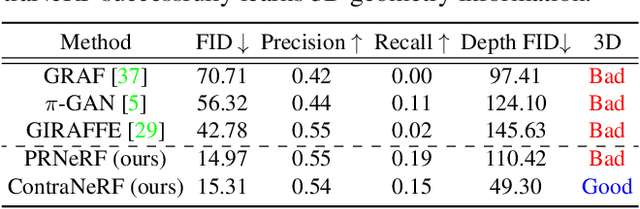
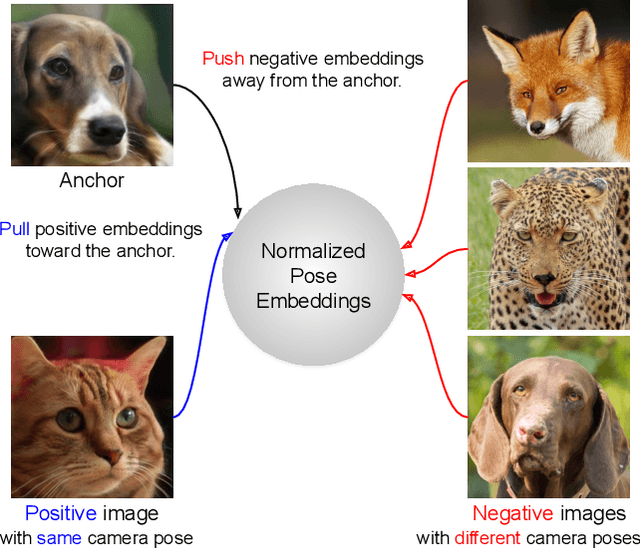
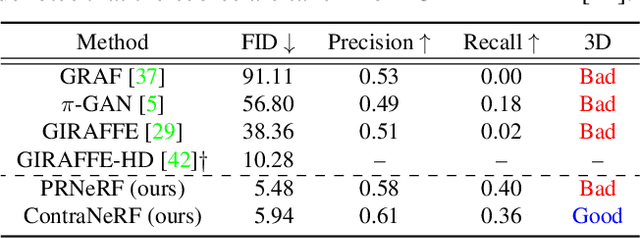
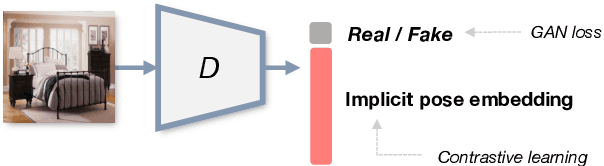
Although 3D-aware GANs based on neural radiance fields have achieved competitive performance, their applicability is still limited to objects or scenes with the ground-truths or prediction models for clearly defined canonical camera poses. To extend the scope of applicable datasets, we propose a novel 3D-aware GAN optimization technique through contrastive learning with implicit pose embeddings. To this end, we first revise the discriminator design and remove dependency on ground-truth camera poses. Then, to capture complex and challenging 3D scene structures more effectively, we make the discriminator estimate a high-dimensional implicit pose embedding from a given image and perform contrastive learning on the pose embedding. The proposed approach can be employed for the dataset, where the canonical camera pose is ill-defined because it does not look up or estimate camera poses. Experimental results show that our algorithm outperforms existing methods by large margins on the datasets with multiple object categories and inconsistent canonical camera poses.
Learning Task-Specific Strategies for Accelerated MRI
Apr 25, 2023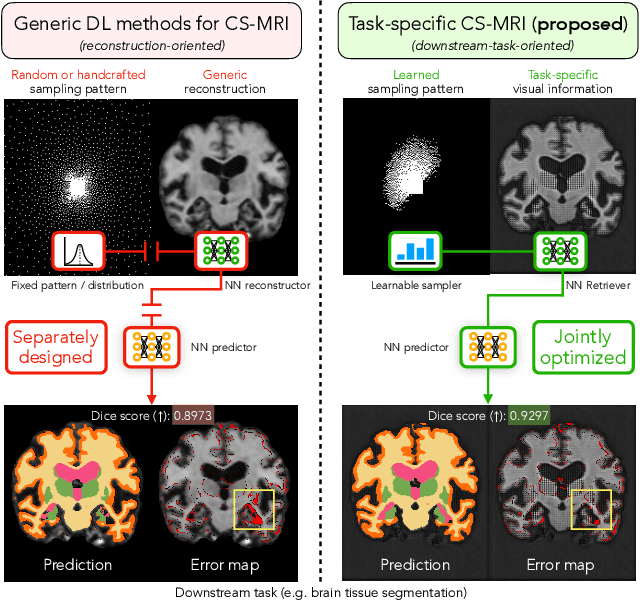
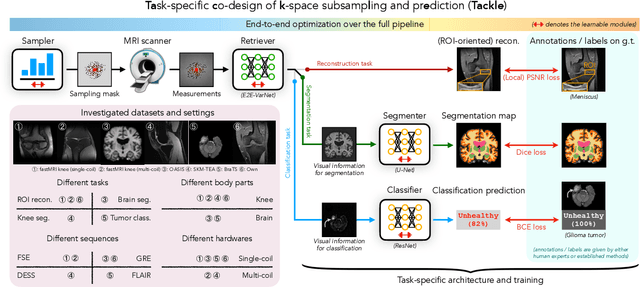

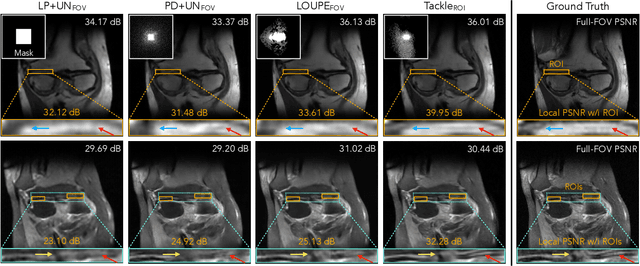
Compressed sensing magnetic resonance imaging (CS-MRI) seeks to recover visual information from subsampled measurements for diagnostic tasks. Traditional CS-MRI methods often separately address measurement subsampling, image reconstruction, and task prediction, resulting in suboptimal end-to-end performance. In this work, we propose TACKLE as a unified framework for designing CS-MRI systems tailored to specific tasks. Leveraging recent co-design techniques, TACKLE jointly optimizes subsampling, reconstruction, and prediction strategies to enhance the performance on the downstream task. Our results on multiple public MRI datasets show that the proposed framework achieves improved performance on various tasks over traditional CS-MRI methods. We also evaluate the generalization ability of TACKLE by experimentally collecting a new dataset using different acquisition setups from the training data. Without additional fine-tuning, TACKLE functions robustly and leads to both numerical and visual improvements.
A baseline on continual learning methods for video action recognition
Apr 26, 2023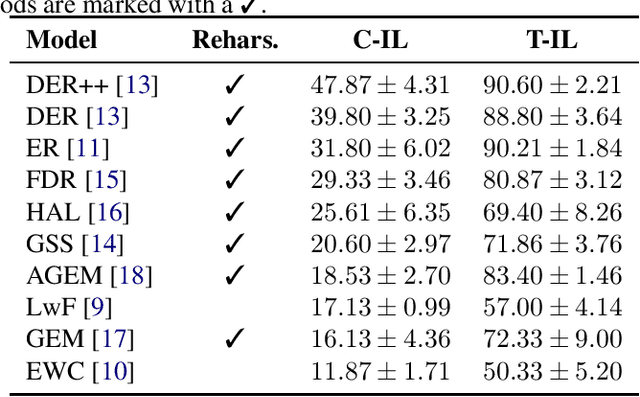
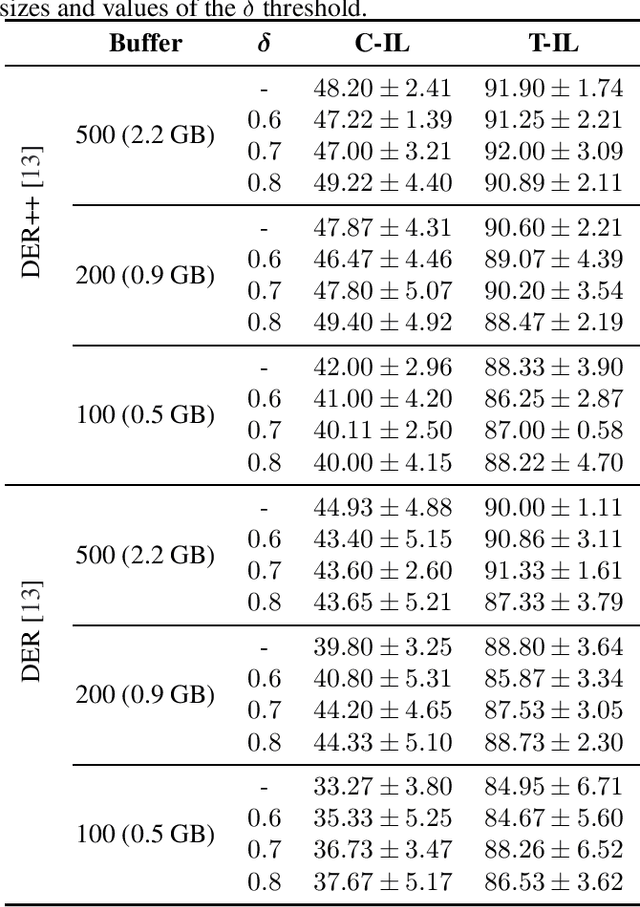
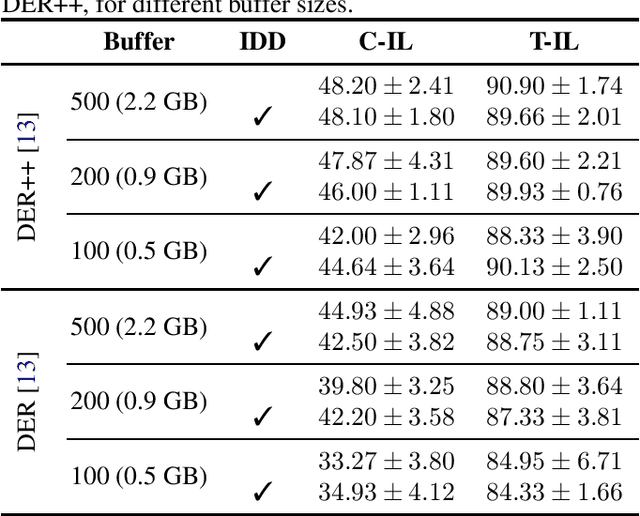
Continual learning has recently attracted attention from the research community, as it aims to solve long-standing limitations of classic supervisedly-trained models. However, most research on this subject has tackled continual learning in simple image classification scenarios. In this paper, we present a benchmark of state-of-the-art continual learning methods on video action recognition. Besides the increased complexity due to the temporal dimension, the video setting imposes stronger requirements on computing resources for top-performing rehearsal methods. To counteract the increased memory requirements, we present two method-agnostic variants for rehearsal methods, exploiting measures of either model confidence or data information to select memorable samples. Our experiments show that, as expected from the literature, rehearsal methods outperform other approaches; moreover, the proposed memory-efficient variants are shown to be effective at retaining a certain level of performance with a smaller buffer size.
Learnable Ophthalmology SAM
Apr 26, 2023
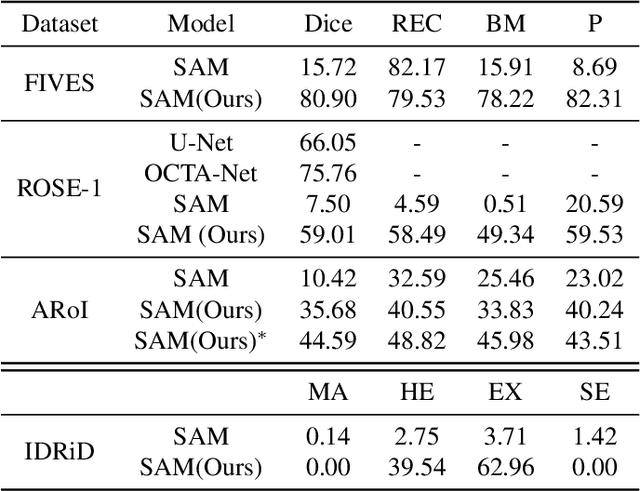
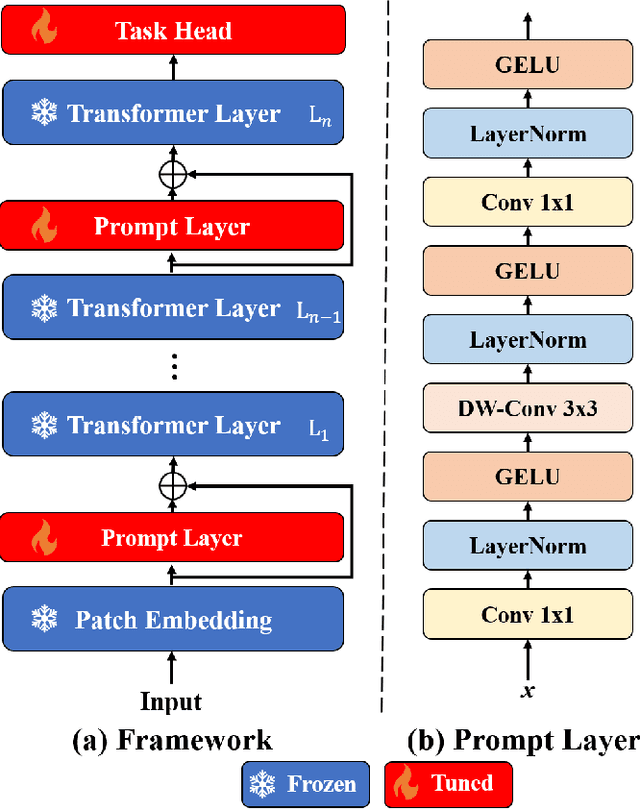
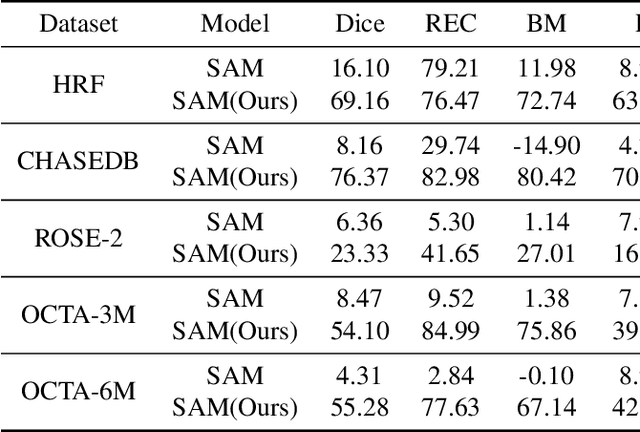
Segmentation is vital for ophthalmology image analysis. But its various modal images hinder most of the existing segmentation algorithms applications, as they rely on training based on a large number of labels or hold weak generalization ability. Based on Segment Anything (SAM), we propose a simple but effective learnable prompt layer suitable for multiple target segmentation in ophthalmology multi-modal images, named Learnable Ophthalmology Segment Anything (SAM). The learnable prompt layer learns medical prior knowledge from each transformer layer. During training, we only train the prompt layer and task head based on a one-shot mechanism. We demonstrate the effectiveness of our thought based on four medical segmentation tasks based on nine publicly available datasets. Moreover, we only provide a new improvement thought for applying the existing fundamental CV models in the medical field. Our codes are available at \href{https://github.com/Qsingle/LearnablePromptSAM}{website}.
Nearest Neighbor Based Out-of-Distribution Detection in Remote Sensing Scene Classification
Mar 29, 2023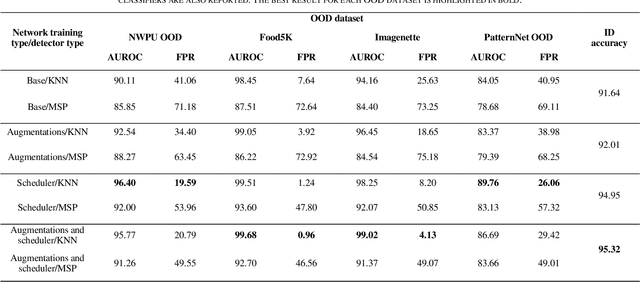
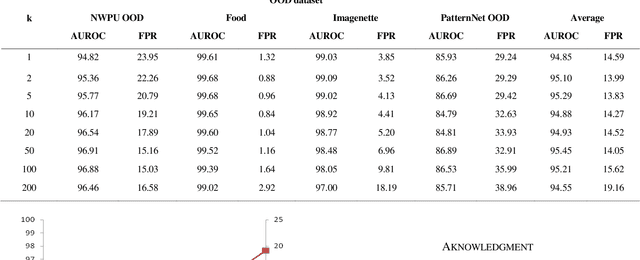
Deep learning models for image classification are typically trained under the "closed-world" assumption with a predefined set of image classes. However, when the models are deployed they may be faced with input images not belonging to the classes encountered during training. This type of scenario is common in remote sensing image classification where images come from different geographic areas, sensors, and imaging conditions. In this paper we deal with the problem of detecting remote sensing images coming from a different distribution compared to the training data - out of distribution images. We propose a benchmark for out of distribution detection in remote sensing scene classification and evaluate detectors based on maximum softmax probability and nearest neighbors. The experimental results show convincing advantages of the method based on nearest neighbors.
PIAT: Parameter Interpolation based Adversarial Training for Image Classification
Mar 24, 2023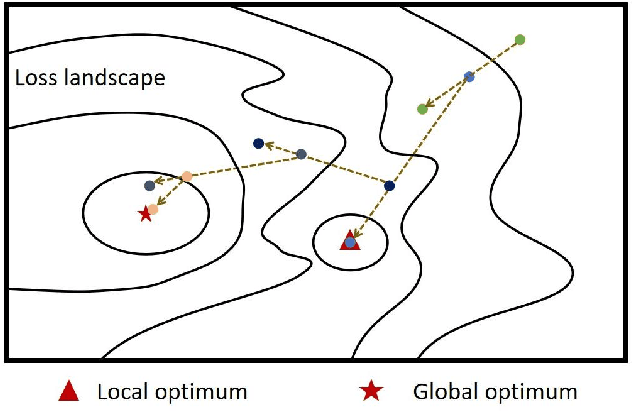
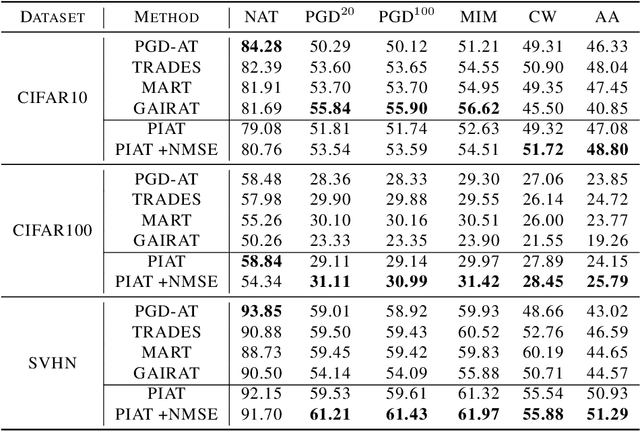
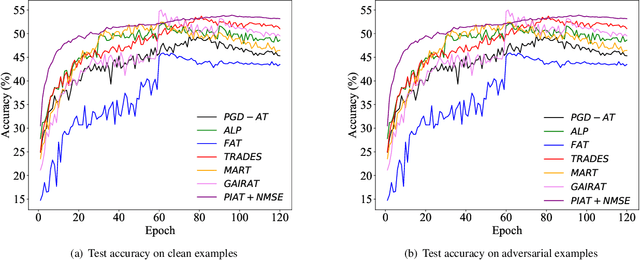
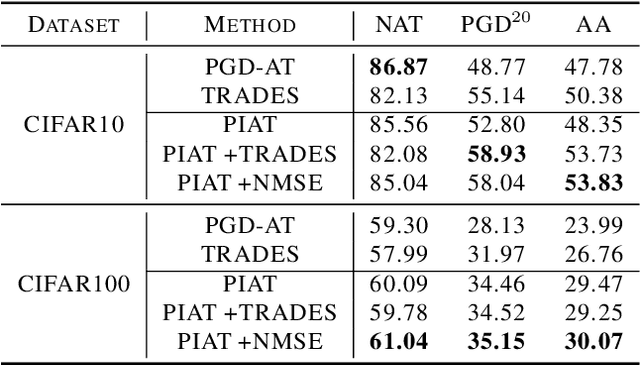
Adversarial training has been demonstrated to be the most effective approach to defend against adversarial attacks. However, existing adversarial training methods show apparent oscillations and overfitting issue in the training process, degrading the defense efficacy. In this work, we propose a novel framework, termed Parameter Interpolation based Adversarial Training (PIAT), that makes full use of the historical information during training. Specifically, at the end of each epoch, PIAT tunes the model parameters as the interpolation of the parameters of the previous and current epochs. Besides, we suggest to use the Normalized Mean Square Error (NMSE) to further improve the robustness by aligning the clean and adversarial examples. Compared with other regularization methods, NMSE focuses more on the relative magnitude of the logits rather than the absolute magnitude. Extensive experiments on several benchmark datasets and various networks show that our method could prominently improve the model robustness and reduce the generalization error. Moreover, our framework is general and could further boost the robust accuracy when combined with other adversarial training methods.
SurgicalGPT: End-to-End Language-Vision GPT for Visual Question Answering in Surgery
Apr 19, 2023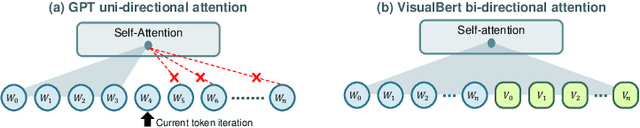
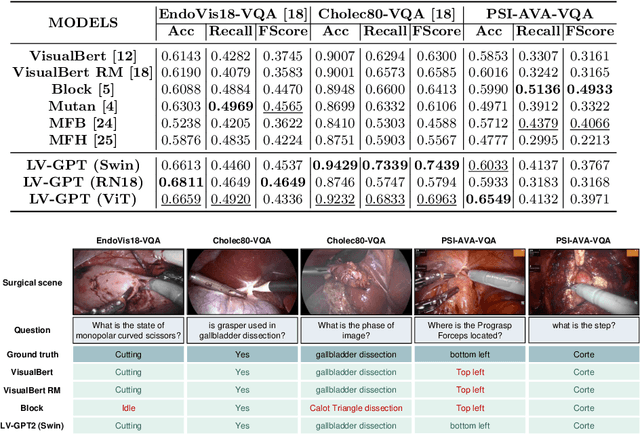
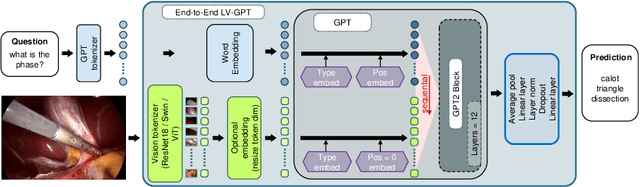
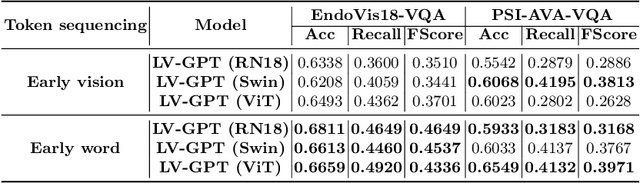
Advances in GPT-based large language models (LLMs) are revolutionizing natural language processing, exponentially increasing its use across various domains. Incorporating uni-directional attention, these autoregressive LLMs can generate long and coherent paragraphs. However, for visual question answering (VQA) tasks that require both vision and language processing, models with bi-directional attention or models employing fusion techniques are often employed to capture the context of multiple modalities all at once. As GPT does not natively process vision tokens, to exploit the advancements in GPT models for VQA in robotic surgery, we design an end-to-end trainable Language-Vision GPT (LV-GPT) model that expands the GPT2 model to include vision input (image). The proposed LV-GPT incorporates a feature extractor (vision tokenizer) and vision token embedding (token type and pose). Given the limitations of unidirectional attention in GPT models and their ability to generate coherent long paragraphs, we carefully sequence the word tokens before vision tokens, mimicking the human thought process of understanding the question to infer an answer from an image. Quantitatively, we prove that the LV-GPT model outperforms other state-of-the-art VQA models on two publically available surgical-VQA datasets (based on endoscopic vision challenge robotic scene segmentation 2018 and CholecTriplet2021) and on our newly annotated dataset (based on the holistic surgical scene dataset). We further annotate all three datasets to include question-type annotations to allow sub-type analysis. Furthermore, we extensively study and present the effects of token sequencing, token type and pose embedding for vision tokens in the LV-GPT model.
Dif-Fusion: Towards High Color Fidelity in Infrared and Visible Image Fusion with Diffusion Models
Jan 19, 2023


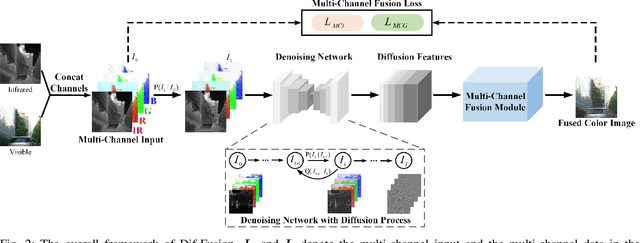
Color plays an important role in human visual perception, reflecting the spectrum of objects. However, the existing infrared and visible image fusion methods rarely explore how to handle multi-spectral/channel data directly and achieve high color fidelity. This paper addresses the above issue by proposing a novel method with diffusion models, termed as Dif-Fusion, to generate the distribution of the multi-channel input data, which increases the ability of multi-source information aggregation and the fidelity of colors. In specific, instead of converting multi-channel images into single-channel data in existing fusion methods, we create the multi-channel data distribution with a denoising network in a latent space with forward and reverse diffusion process. Then, we use the the denoising network to extract the multi-channel diffusion features with both visible and infrared information. Finally, we feed the multi-channel diffusion features to the multi-channel fusion module to directly generate the three-channel fused image. To retain the texture and intensity information, we propose multi-channel gradient loss and intensity loss. Along with the current evaluation metrics for measuring texture and intensity fidelity, we introduce a new evaluation metric to quantify color fidelity. Extensive experiments indicate that our method is more effective than other state-of-the-art image fusion methods, especially in color fidelity.
Crop identification using deep learning on LUCAS crop cover photos
May 08, 2023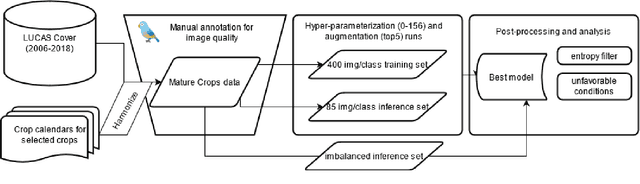
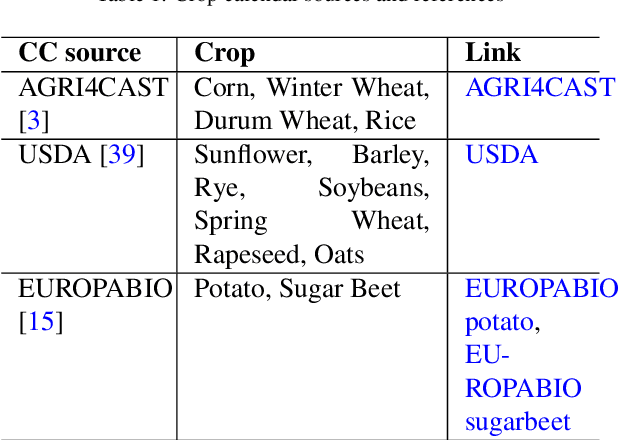

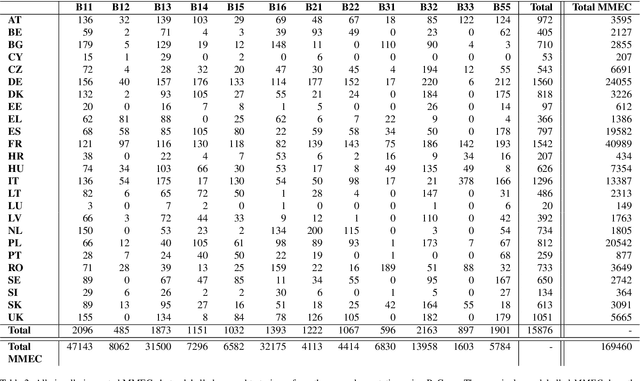
Crop classification via deep learning on ground imagery can deliver timely and accurate crop-specific information to various stakeholders. Dedicated ground-based image acquisition exercises can help to collect data in data scarce regions, improve control on timing of collection, or when study areas are to small to monitor via satellite. Automatic labelling is essential when collecting large volumes of data. One such data collection is the EU's Land Use Cover Area frame Survey (LUCAS), and in particular, the recently published LUCAS Cover photos database. The aim of this paper is to select and publish a subset of LUCAS Cover photos for 12 mature major crops across the EU, to deploy, benchmark, and identify the best configuration of Mobile-net for the classification task, to showcase the possibility of using entropy-based metrics for post-processing of results, and finally to show the applications and limitations of the model in a practical and policy relevant context. In particular, the usefulness of automatically identifying crops on geo-tagged photos is illustrated in the context of the EU's Common Agricultural Policy. The work has produced a dataset of 169,460 images of mature crops for the 12 classes, out of which 15,876 were manually selected as representing a clean sample without any foreign objects or unfavorable conditions. The best performing model achieved a Macro F1 (M-F1) of 0.75 on an imbalanced test dataset of 8,642 photos. Using metrics from information theory, namely - the Equivalence Reference Probability, resulted in achieving an increase of 6%. The most unfavorable conditions for taking such images, across all crop classes, were found to be too early or late in the season. The proposed methodology shows the possibility for using minimal auxiliary data, outside the images themselves, in order to achieve a M-F1 of 0.817 for labelling between 12 major European crops.
Intriguing properties of synthetic images: from generative adversarial networks to diffusion models
Apr 13, 2023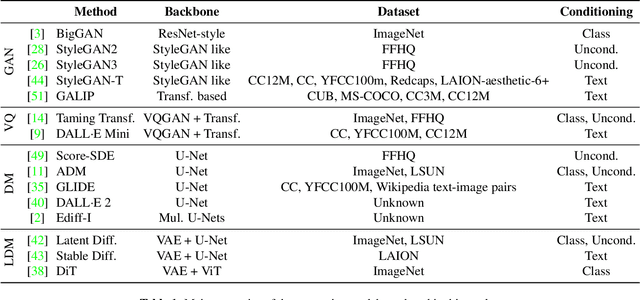

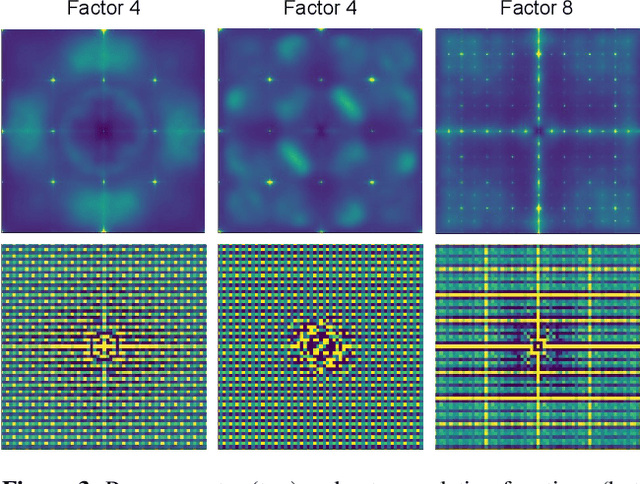
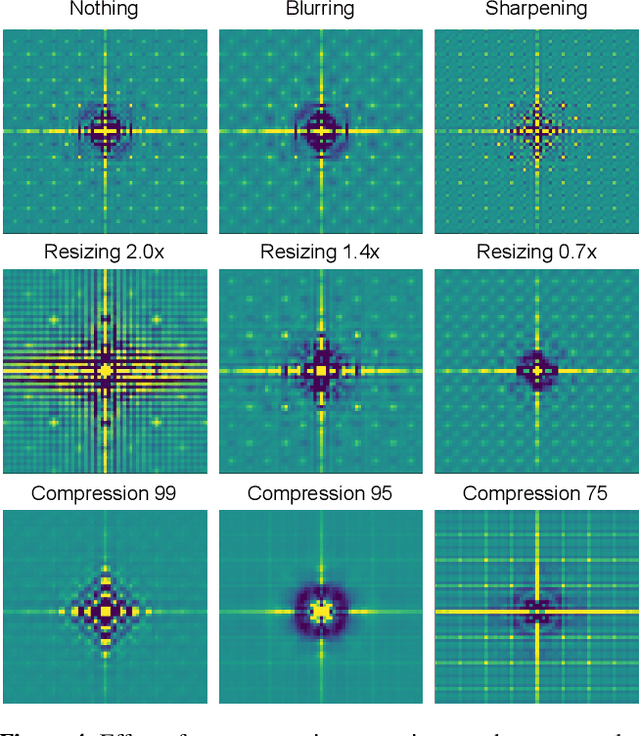
Detecting fake images is becoming a major goal of computer vision. This need is becoming more and more pressing with the continuous improvement of synthesis methods based on Generative Adversarial Networks (GAN), and even more with the appearance of powerful methods based on Diffusion Models (DM). Towards this end, it is important to gain insight into which image features better discriminate fake images from real ones. In this paper we report on our systematic study of a large number of image generators of different families, aimed at discovering the most forensically relevant characteristics of real and generated images. Our experiments provide a number of interesting observations and shed light on some intriguing properties of synthetic images: (1) not only the GAN models but also the DM and VQ-GAN (Vector Quantized Generative Adversarial Networks) models give rise to visible artifacts in the Fourier domain and exhibit anomalous regular patterns in the autocorrelation; (2) when the dataset used to train the model lacks sufficient variety, its biases can be transferred to the generated images; (3) synthetic and real images exhibit significant differences in the mid-high frequency signal content, observable in their radial and angular spectral power distributions.