 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Neural Field Conditioning Strategies for 2D Semantic Segmentation
Apr 12, 2023
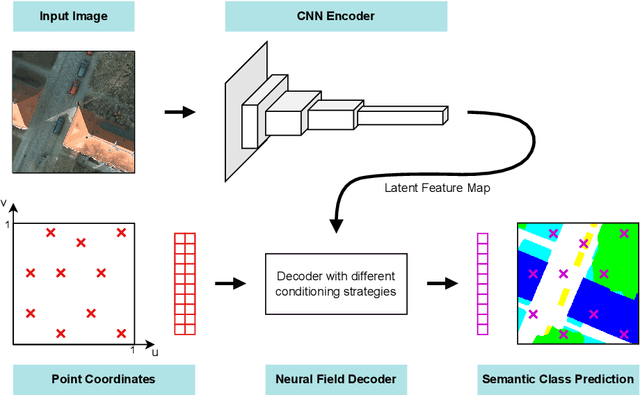
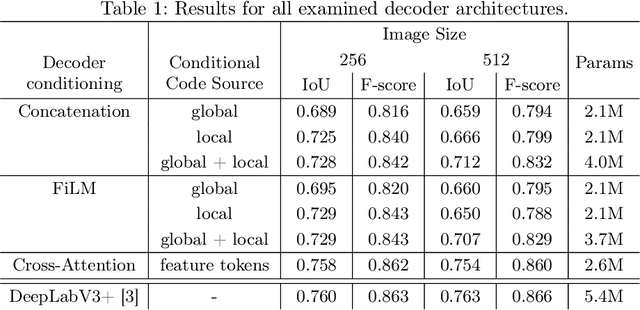
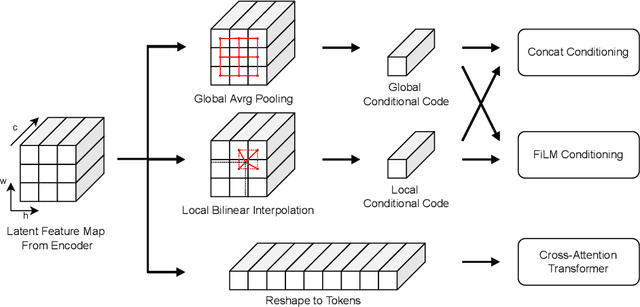
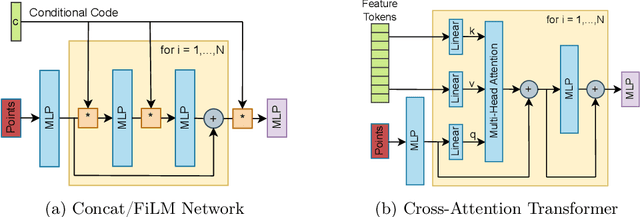
Neural fields are neural networks which map coordinates to a desired signal. When a neural field should jointly model multiple signals, and not memorize only one, it needs to be conditioned on a latent code which describes the signal at hand. Despite being an important aspect, there has been little research on conditioning strategies for neural fields. In this work, we explore the use of neural fields as decoders for 2D semantic segmentation. For this task, we compare three conditioning methods, simple concatenation of the latent code, Feature Wise Linear Modulation (FiLM), and Cross-Attention, in conjunction with latent codes which either describe the full image or only a local region of the image. Our results show a considerable difference in performance between the examined conditioning strategies. Furthermore, we show that conditioning via Cross-Attention achieves the best results and is competitive with a CNN-based decoder for semantic segmentation.
Crowd Counting with Sparse Annotation
Apr 12, 2023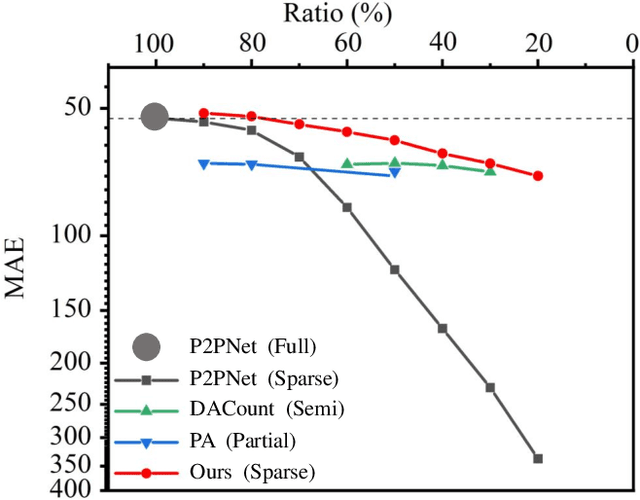
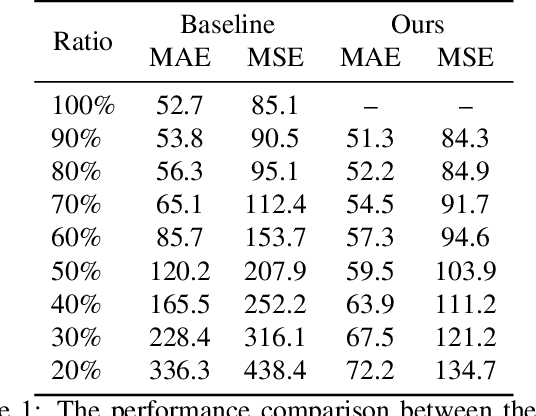

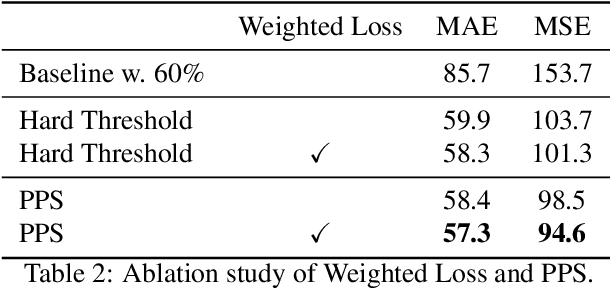
This paper presents a new annotation method called Sparse Annotation (SA) for crowd counting, which reduces human labeling efforts by sparsely labeling individuals in an image. We argue that sparse labeling can reduce the redundancy of full annotation and capture more diverse information from distant individuals that is not fully captured by Partial Annotation methods. Besides, we propose a point-based Progressive Point Matching network (PPM) to better explore the crowd from the whole image with sparse annotation, which includes a Proposal Matching Network (PMN) and a Performance Restoration Network (PRN). The PMN generates pseudo-point samples using a basic point classifier, while the PRN refines the point classifier with the pseudo points to maximize performance. Our experimental results show that PPM outperforms previous semi-supervised crowd counting methods with the same amount of annotation by a large margin and achieves competitive performance with state-of-the-art fully-supervised methods.
Exploring the Limits of Deep Image Clustering using Pretrained Models
Mar 31, 2023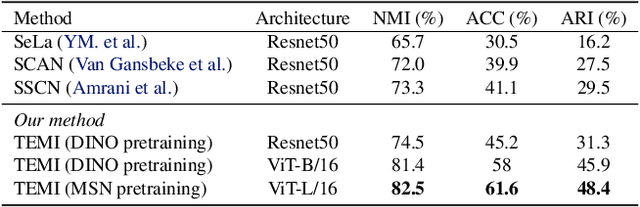
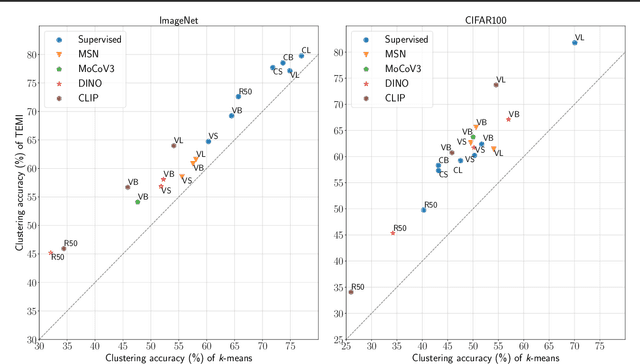
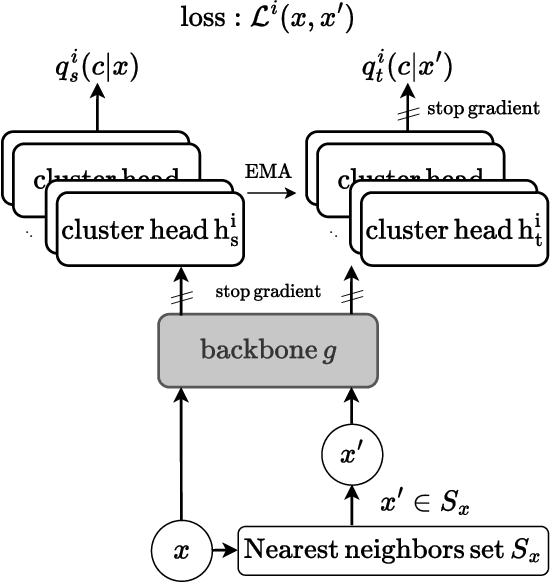
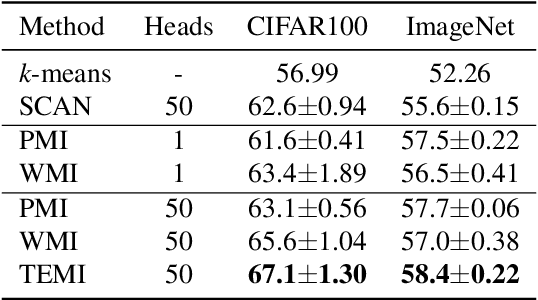
We present a general methodology that learns to classify images without labels by leveraging pretrained feature extractors. Our approach involves self-distillation training of clustering heads, based on the fact that nearest neighbors in the pretrained feature space are likely to share the same label. We propose a novel objective to learn associations between images by introducing a variant of pointwise mutual information together with instance weighting. We demonstrate that the proposed objective is able to attenuate the effect of false positive pairs while efficiently exploiting the structure in the pretrained feature space. As a result, we improve the clustering accuracy over $k$-means on $17$ different pretrained models by $6.1$\% and $12.2$\% on ImageNet and CIFAR100, respectively. Finally, using self-supervised pretrained vision transformers we push the clustering accuracy on ImageNet to $61.6$\%. The code will be open-sourced.
PixelRNN: In-pixel Recurrent Neural Networks for End-to-end-optimized Perception with Neural Sensors
Apr 11, 2023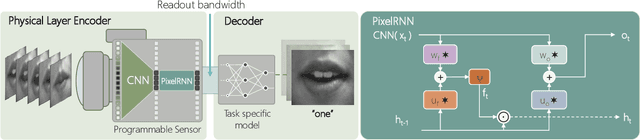
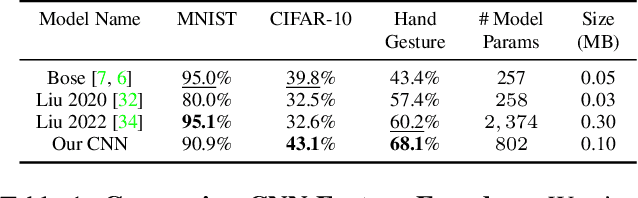
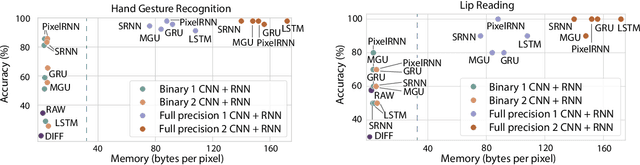
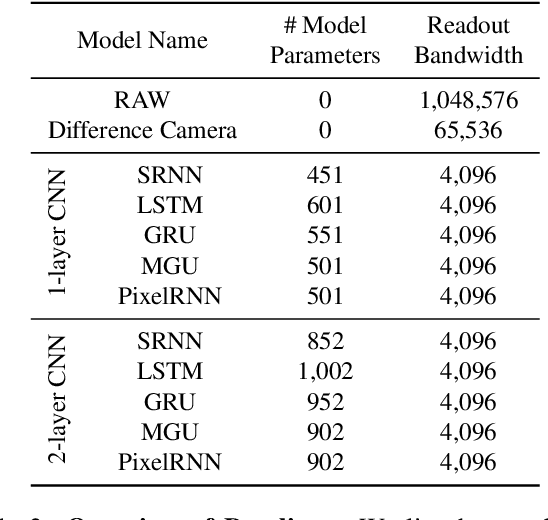
Conventional image sensors digitize high-resolution images at fast frame rates, producing a large amount of data that needs to be transmitted off the sensor for further processing. This is challenging for perception systems operating on edge devices, because communication is power inefficient and induces latency. Fueled by innovations in stacked image sensor fabrication, emerging sensor-processors offer programmability and minimal processing capabilities directly on the sensor. We exploit these capabilities by developing an efficient recurrent neural network architecture, PixelRNN, that encodes spatio-temporal features on the sensor using purely binary operations. PixelRNN reduces the amount of data to be transmitted off the sensor by a factor of 64x compared to conventional systems while offering competitive accuracy for hand gesture recognition and lip reading tasks. We experimentally validate PixelRNN using a prototype implementation on the SCAMP-5 sensor-processor platform.
SATR: Zero-Shot Semantic Segmentation of 3D Shapes
Apr 11, 2023
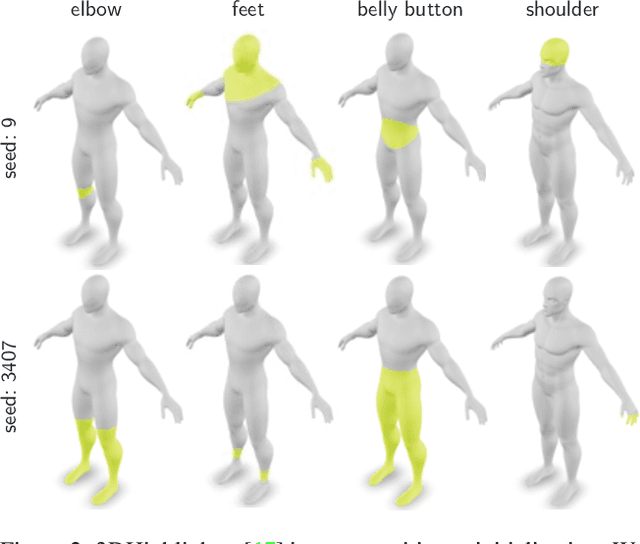
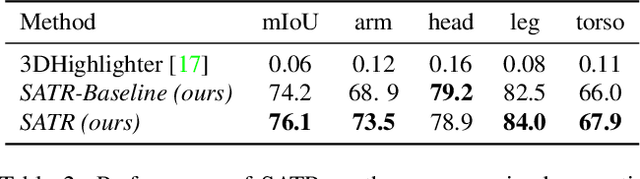
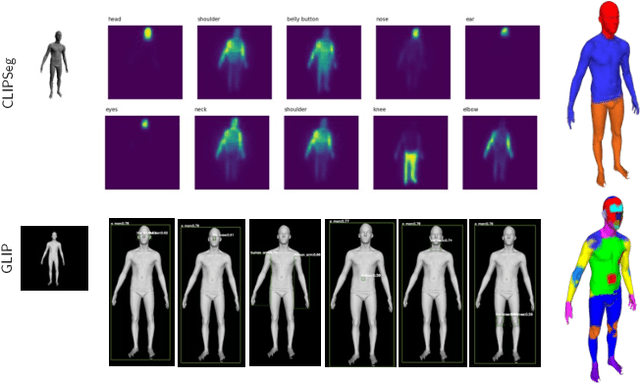
We explore the task of zero-shot semantic segmentation of 3D shapes by using large-scale off-the-shelf 2D image recognition models. Surprisingly, we find that modern zero-shot 2D object detectors are better suited for this task than contemporary text/image similarity predictors or even zero-shot 2D segmentation networks. Our key finding is that it is possible to extract accurate 3D segmentation maps from multi-view bounding box predictions by using the topological properties of the underlying surface. For this, we develop the Segmentation Assignment with Topological Reweighting (SATR) algorithm and evaluate it on two challenging benchmarks: FAUST and ShapeNetPart. On these datasets, SATR achieves state-of-the-art performance and outperforms prior work by at least 22\% on average in terms of mIoU. Our source code and data will be publicly released. Project webpage: https://samir55.github.io/SATR/
KonX: Cross-Resolution Image Quality Assessment
Dec 12, 2022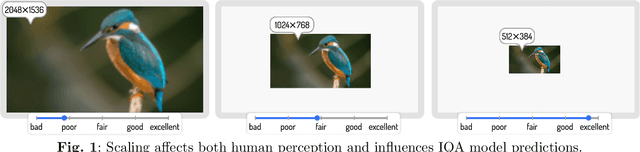

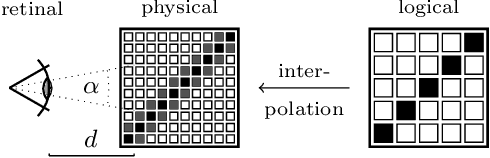

Scale-invariance is an open problem in many computer vision subfields. For example, object labels should remain constant across scales, yet model predictions diverge in many cases. This problem gets harder for tasks where the ground-truth labels change with the presentation scale. In image quality assessment (IQA), downsampling attenuates impairments, e.g., blurs or compression artifacts, which can positively affect the impression evoked in subjective studies. To accurately predict perceptual image quality, cross-resolution IQA methods must therefore account for resolution-dependent errors induced by model inadequacies as well as for the perceptual label shifts in the ground truth. We present the first study of its kind that disentangles and examines the two issues separately via KonX, a novel, carefully crafted cross-resolution IQA database. This paper contributes the following: 1. Through KonX, we provide empirical evidence of label shifts caused by changes in the presentation resolution. 2. We show that objective IQA methods have a scale bias, which reduces their predictive performance. 3. We propose a multi-scale and multi-column DNN architecture that improves performance over previous state-of-the-art IQA models for this task, including recent transformers. We thus both raise and address a novel research problem in image quality assessment.
Generalizable Denoising of Microscopy Images using Generative Adversarial Networks and Contrastive Learning
Mar 29, 2023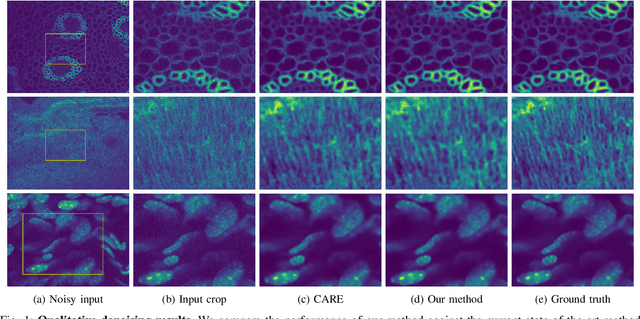



Microscopy images often suffer from high levels of noise, which can hinder further analysis and interpretation. Content-aware image restoration (CARE) methods have been proposed to address this issue, but they often require large amounts of training data and suffer from over-fitting. To overcome these challenges, we propose a novel framework for few-shot microscopy image denoising. Our approach combines a generative adversarial network (GAN) trained via contrastive learning (CL) with two structure preserving loss terms (Structural Similarity Index and Total Variation loss) to further improve the quality of the denoised images using little data. We demonstrate the effectiveness of our method on three well-known microscopy imaging datasets, and show that we can drastically reduce the amount of training data while retaining the quality of the denoising, thus alleviating the burden of acquiring paired data and enabling few-shot learning. The proposed framework can be easily extended to other image restoration tasks and has the potential to significantly advance the field of microscopy image analysis.
Structure-CLIP: Enhance Multi-modal Language Representations with Structure Knowledge
May 06, 2023
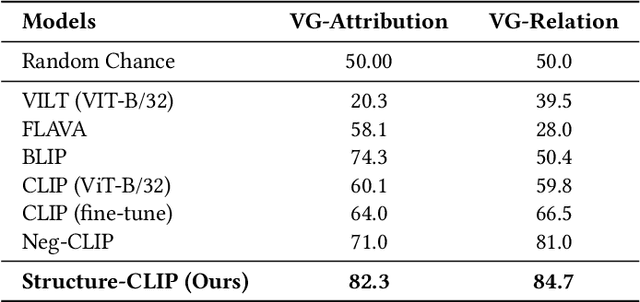
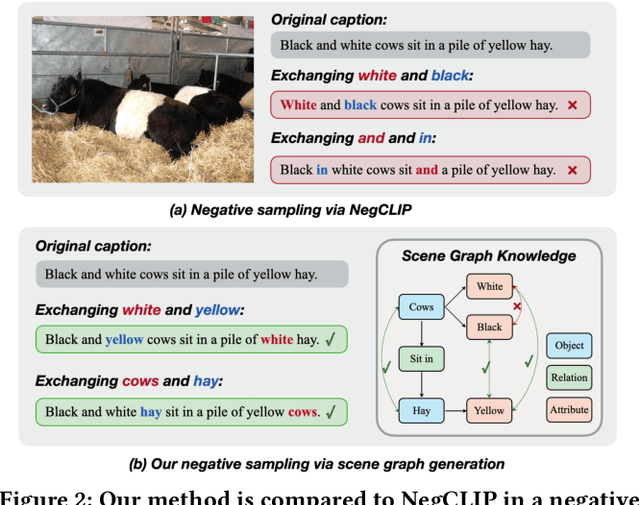
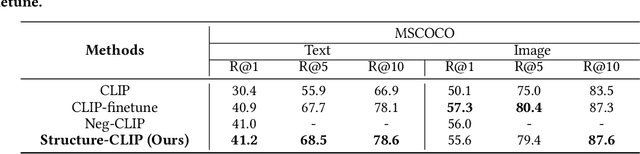
Large-scale vision-language pre-training has shown promising advances on various downstream tasks and achieved significant performance in multi-modal understanding and generation tasks. However, existing methods often perform poorly on image-text matching tasks that require a detailed semantics understanding of the text. Although there have been some works on this problem, they do not sufficiently exploit the structural knowledge present in sentences to enhance multi-modal language representations, which leads to poor performance. In this paper, we present an end-to-end framework Structure-CLIP, which integrates latent detailed semantics from the text to enhance fine-grained semantic representations. Specifically, (1) we use scene graphs in order to pay more attention to the detailed semantic learning in the text and fully explore structured knowledge between fine-grained semantics, and (2) we utilize the knowledge-enhanced framework with the help of the scene graph to make full use of representations of structured knowledge. To verify the effectiveness of our proposed method, we pre-trained our models with the aforementioned approach and conduct experiments on different downstream tasks. Numerical results show that Structure-CLIP can often achieve state-of-the-art performance on both VG-Attribution and VG-Relation datasets. Extensive experiments show its components are effective and its predictions are interpretable, which proves that our proposed method can enhance detailed semantic representation well.
Supervised Image Segmentation for High Dynamic Range Imaging
Dec 06, 2022
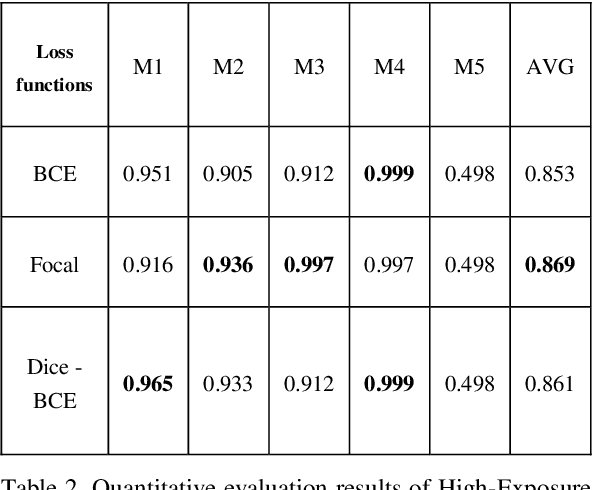
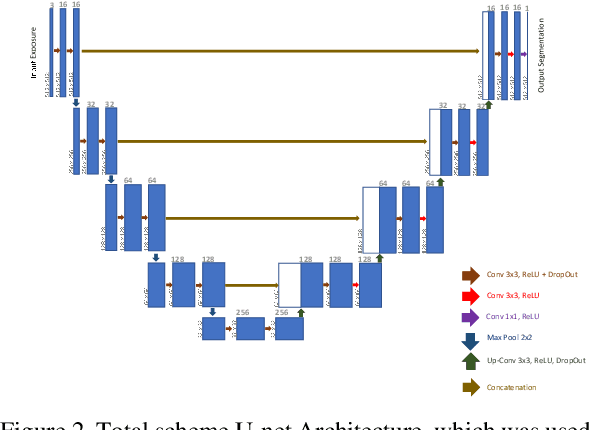
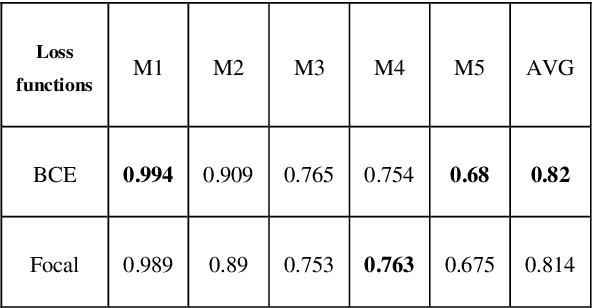
Regular cameras and cell phones are able to capture limited luminosity. Thus, in terms of quality, most of the produced images from such devices are not similar to the real world. They are overly dark or too bright, and the details are not perfectly visible. Various methods, which fall under the name of High Dynamic Range (HDR) Imaging, can be utilised to cope with this problem. Their objective is to produce an image with more details. However, unfortunately, most methods for generating an HDR image from Multi-Exposure images only concentrate on how to combine different exposures and do not have any focus on choosing the best details of each image. Therefore, it is strived in this research to extract the most visible areas of each image with the help of image segmentation. Two methods of producing the Ground Truth were considered, as manual threshold and Otsu threshold, and a neural network will be used to train segment these areas. Finally, it will be shown that the neural network is able to segment the visible parts of pictures acceptably.
Cyclic Generative Adversarial Networks With Congruent Image-Report Generation For Explainable Medical Image Analysis
Nov 16, 2022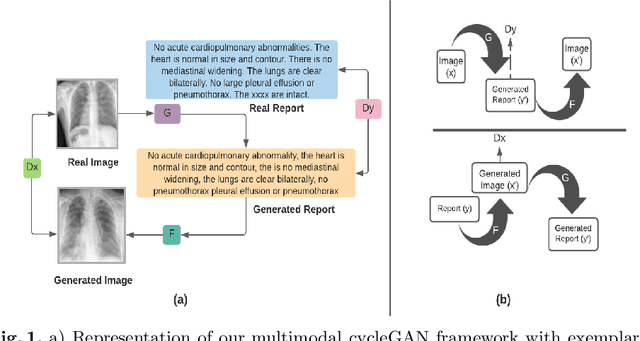
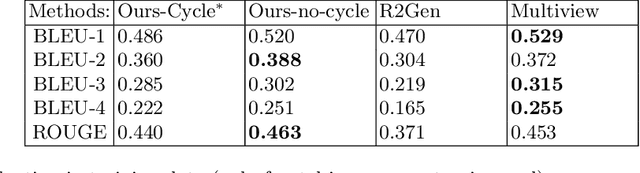

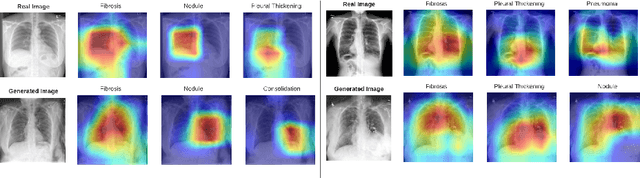
We present a novel framework for explainable labeling and interpretation of medical images. Medical images require specialized professionals for interpretation, and are explained (typically) via elaborate textual reports. Different from prior methods that focus on medical report generation from images or vice-versa, we novelly generate congruent image--report pairs employing a cyclic-Generative Adversarial Network (cycleGAN); thereby, the generated report will adequately explain a medical image, while a report-generated image that effectively characterizes the text visually should (sufficiently) resemble the original. The aim of the work is to generate trustworthy and faithful explanations for the outputs of a model diagnosing chest x-ray images by pointing a human user to similar cases in support of a diagnostic decision. Apart from enabling transparent medical image labeling and interpretation, we achieve report and image-based labeling comparable to prior methods, including state-of-the-art performance in some cases as evidenced by experiments on the Indiana Chest X-ray dataset