 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Text encoders are performance bottlenecks in contrastive vision-language models
May 24, 2023
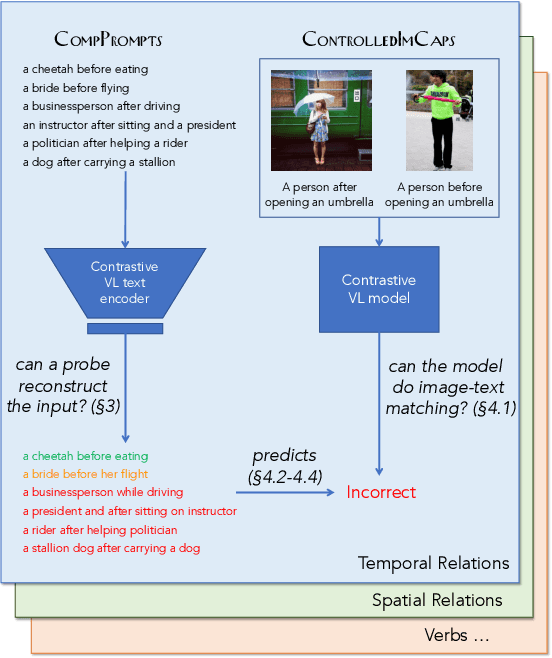
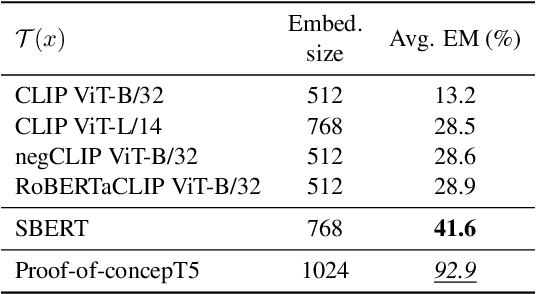
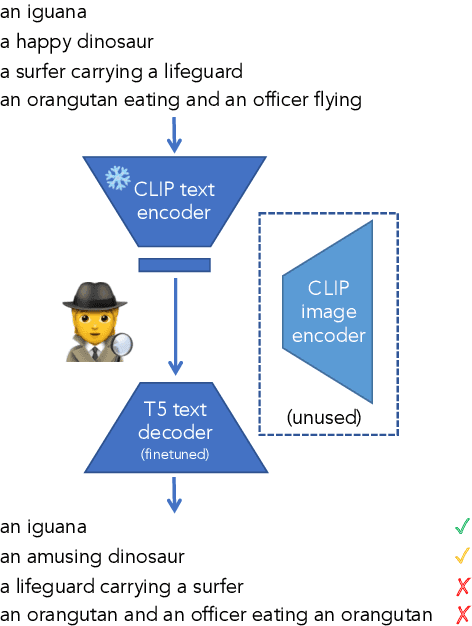
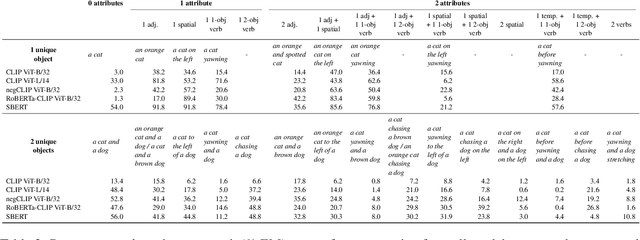
Performant vision-language (VL) models like CLIP represent captions using a single vector. How much information about language is lost in this bottleneck? We first curate CompPrompts, a set of increasingly compositional image captions that VL models should be able to capture (e.g., single object, to object+property, to multiple interacting objects). Then, we train text-only recovery probes that aim to reconstruct captions from single-vector text representations produced by several VL models. This approach doesn't require images, allowing us to test on a broader range of scenes compared to prior work. We find that: 1) CLIP's text encoder falls short on object relationships, attribute-object association, counting, and negations; 2) some text encoders work significantly better than others; and 3) text-only recovery performance predicts multi-modal matching performance on ControlledImCaps: a new evaluation benchmark we collect+release consisting of fine-grained compositional images+captions. Specifically -- our results suggest text-only recoverability is a necessary (but not sufficient) condition for modeling compositional factors in contrastive vision+language models. We release data+code.
Relating Implicit Bias and Adversarial Attacks through Intrinsic Dimension
May 24, 2023
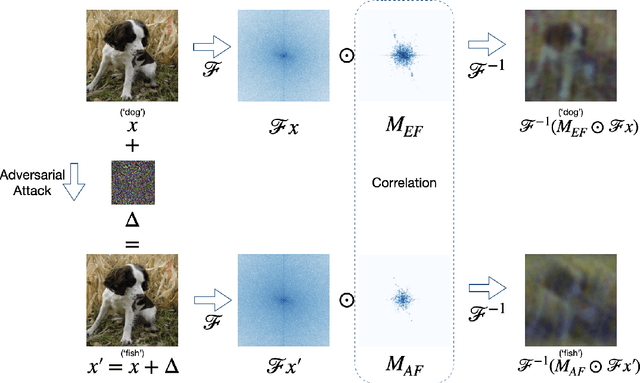
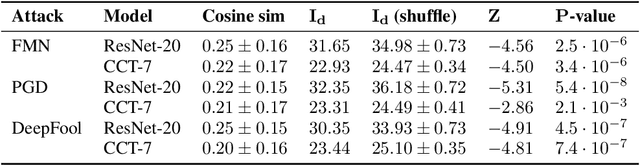

Despite their impressive performance in classification, neural networks are known to be vulnerable to adversarial attacks. These attacks are small perturbations of the input data designed to fool the model. Naturally, a question arises regarding the potential connection between the architecture, settings, or properties of the model and the nature of the attack. In this work, we aim to shed light on this problem by focusing on the implicit bias of the neural network, which refers to its inherent inclination to favor specific patterns or outcomes. Specifically, we investigate one aspect of the implicit bias, which involves the essential Fourier frequencies required for accurate image classification. We conduct tests to assess the statistical relationship between these frequencies and those necessary for a successful attack. To delve into this relationship, we propose a new method that can uncover non-linear correlations between sets of coordinates, which, in our case, are the aforementioned frequencies. By exploiting the entanglement between intrinsic dimension and correlation, we provide empirical evidence that the network bias in Fourier space and the target frequencies of adversarial attacks are closely tied.
MASK-CNN-Transformer For Real-Time Multi-Label Weather Recognition
Apr 28, 2023Weather recognition is an essential support for many practical life applications, including traffic safety, environment, and meteorology. However, many existing related works cannot comprehensively describe weather conditions due to their complex co-occurrence dependencies. This paper proposes a novel multi-label weather recognition model considering these dependencies. The proposed model called MASK-Convolutional Neural Network-Transformer (MASK-CT) is based on the Transformer, the convolutional process, and the MASK mechanism. The model employs multiple convolutional layers to extract features from weather images and a Transformer encoder to calculate the probability of each weather condition based on the extracted features. To improve the generalization ability of MASK-CT, a MASK mechanism is used during the training phase. The effect of the MASK mechanism is explored and discussed. The Mask mechanism randomly withholds some information from one-pair training instances (one image and its corresponding label). There are two types of MASK methods. Specifically, MASK-I is designed and deployed on the image before feeding it into the weather feature extractor and MASK-II is applied to the image label. The Transformer encoder is then utilized on the randomly masked image features and labels. The experimental results from various real-world weather recognition datasets demonstrate that the proposed MASK-CT model outperforms state-of-the-art methods. Furthermore, the high-speed dynamic real-time weather recognition capability of the MASK-CT is evaluated.
Local-Global Transformer Enhanced Unfolding Network for Pan-sharpening
Apr 28, 2023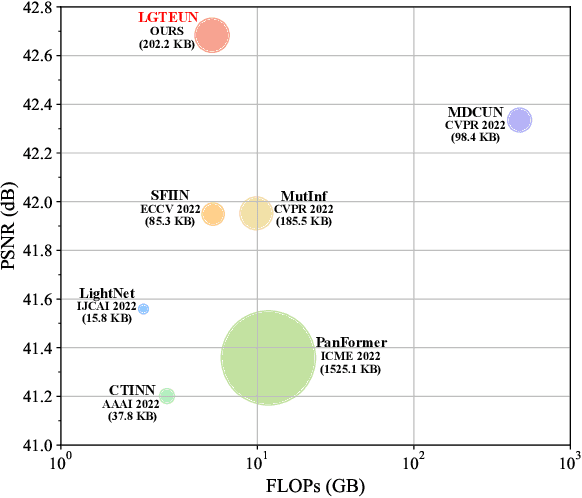
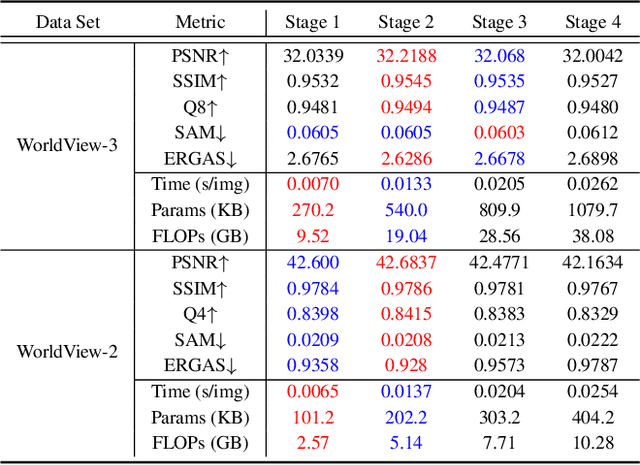
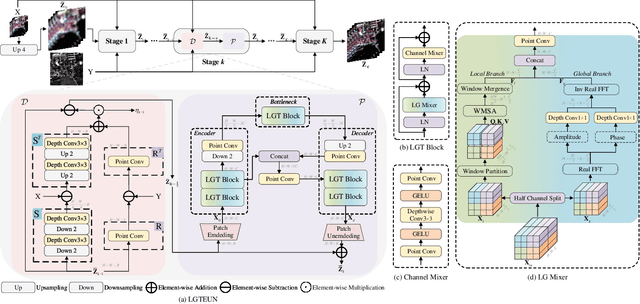
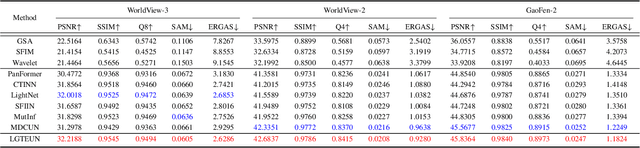
Pan-sharpening aims to increase the spatial resolution of the low-resolution multispectral (LrMS) image with the guidance of the corresponding panchromatic (PAN) image. Although deep learning (DL)-based pan-sharpening methods have achieved promising performance, most of them have a two-fold deficiency. For one thing, the universally adopted black box principle limits the model interpretability. For another thing, existing DL-based methods fail to efficiently capture local and global dependencies at the same time, inevitably limiting the overall performance. To address these mentioned issues, we first formulate the degradation process of the high-resolution multispectral (HrMS) image as a unified variational optimization problem, and alternately solve its data and prior subproblems by the designed iterative proximal gradient descent (PGD) algorithm. Moreover, we customize a Local-Global Transformer (LGT) to simultaneously model local and global dependencies, and further formulate an LGT-based prior module for image denoising. Besides the prior module, we also design a lightweight data module. Finally, by serially integrating the data and prior modules in each iterative stage, we unfold the iterative algorithm into a stage-wise unfolding network, Local-Global Transformer Enhanced Unfolding Network (LGTEUN), for the interpretable MS pan-sharpening. Comprehensive experimental results on three satellite data sets demonstrate the effectiveness and efficiency of LGTEUN compared with state-of-the-art (SOTA) methods. The source code is available at https://github.com/lms-07/LGTEUN.
Efficient Deduplication and Leakage Detection in Large Scale Image Datasets with a focus on the CrowdAI Mapping Challenge Dataset
Apr 05, 2023



Recent advancements in deep learning and computer vision have led to widespread use of deep neural networks to extract building footprints from remote-sensing imagery. The success of such methods relies on the availability of large databases of high-resolution remote sensing images with high-quality annotations. The CrowdAI Mapping Challenge Dataset is one of these datasets that has been used extensively in recent years to train deep neural networks. This dataset consists of $ \sim\ $280k training images and $ \sim\ $60k testing images, with polygonal building annotations for all images. However, issues such as low-quality and incorrect annotations, extensive duplication of image samples, and data leakage significantly reduce the utility of deep neural networks trained on the dataset. Therefore, it is an imperative pre-condition to adopt a data validation pipeline that evaluates the quality of the dataset prior to its use. To this end, we propose a drop-in pipeline that employs perceptual hashing techniques for efficient de-duplication of the dataset and identification of instances of data leakage between training and testing splits. In our experiments, we demonstrate that nearly 250k($ \sim\ $90%) images in the training split were identical. Moreover, our analysis on the validation split demonstrates that roughly 56k of the 60k images also appear in the training split, resulting in a data leakage of 93%. The source code used for the analysis and de-duplication of the CrowdAI Mapping Challenge dataset is publicly available at https://github.com/yeshwanth95/CrowdAI_Hash_and_search .
Segmentation of fundus vascular images based on a dual-attention mechanism
May 05, 2023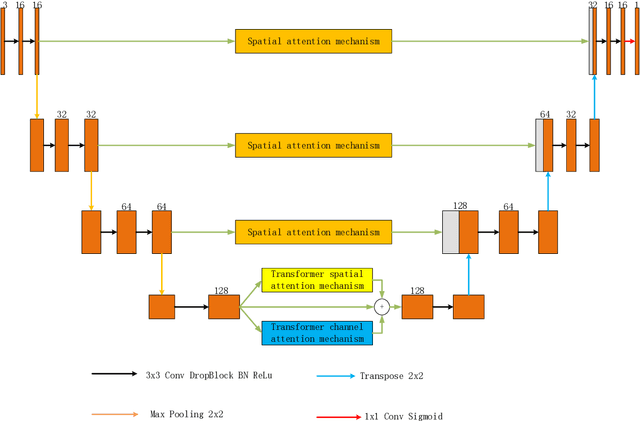
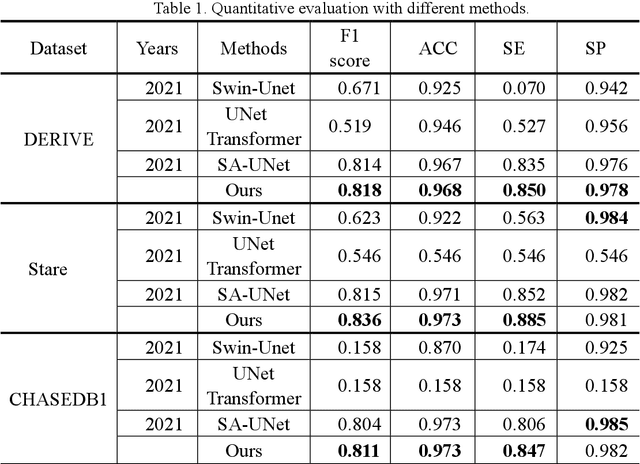
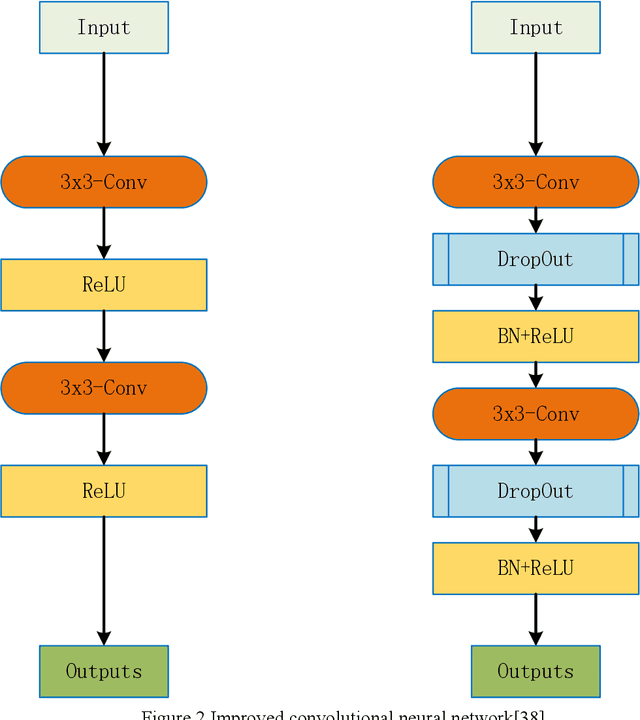
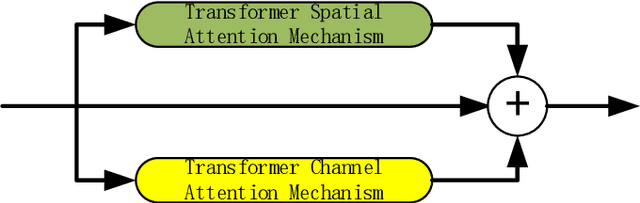
Accurately segmenting blood vessels in retinal fundus images is crucial in the early screening, diagnosing, and evaluating some ocular diseases. However, significant light variations and non-uniform contrast in these images make segmentation quite challenging. Thus, this paper employ an attention fusion mechanism that combines the channel attention and spatial attention mechanisms constructed by Transformer to extract information from retinal fundus images in both spatial and channel dimensions. To eliminate noise from the encoder image, a spatial attention mechanism is introduced in the skip connection. Moreover, a Dropout layer is employed to randomly discard some neurons, which can prevent overfitting of the neural network and improve its generalization performance. Experiments were conducted on publicly available datasets DERIVE, STARE, and CHASEDB1. The results demonstrate that our method produces satisfactory results compared to some recent retinal fundus image segmentation algorithms.
CLIP for All Things Zero-Shot Sketch-Based Image Retrieval, Fine-Grained or Not
Mar 28, 2023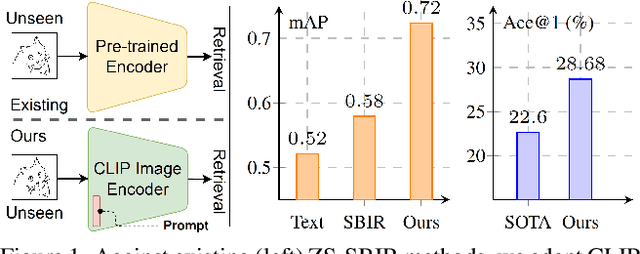
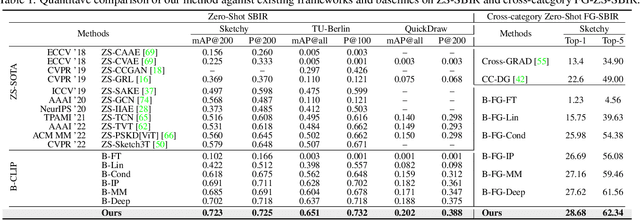

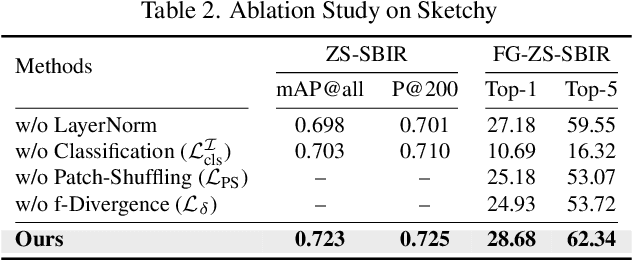
In this paper, we leverage CLIP for zero-shot sketch based image retrieval (ZS-SBIR). We are largely inspired by recent advances on foundation models and the unparalleled generalisation ability they seem to offer, but for the first time tailor it to benefit the sketch community. We put forward novel designs on how best to achieve this synergy, for both the category setting and the fine-grained setting ("all"). At the very core of our solution is a prompt learning setup. First we show just via factoring in sketch-specific prompts, we already have a category-level ZS-SBIR system that overshoots all prior arts, by a large margin (24.8%) - a great testimony on studying the CLIP and ZS-SBIR synergy. Moving onto the fine-grained setup is however trickier, and requires a deeper dive into this synergy. For that, we come up with two specific designs to tackle the fine-grained matching nature of the problem: (i) an additional regularisation loss to ensure the relative separation between sketches and photos is uniform across categories, which is not the case for the gold standard standalone triplet loss, and (ii) a clever patch shuffling technique to help establishing instance-level structural correspondences between sketch-photo pairs. With these designs, we again observe significant performance gains in the region of 26.9% over previous state-of-the-art. The take-home message, if any, is the proposed CLIP and prompt learning paradigm carries great promise in tackling other sketch-related tasks (not limited to ZS-SBIR) where data scarcity remains a great challenge. Project page: https://aneeshan95.github.io/Sketch_LVM/
Structure-guided Image Outpainting
Dec 21, 2022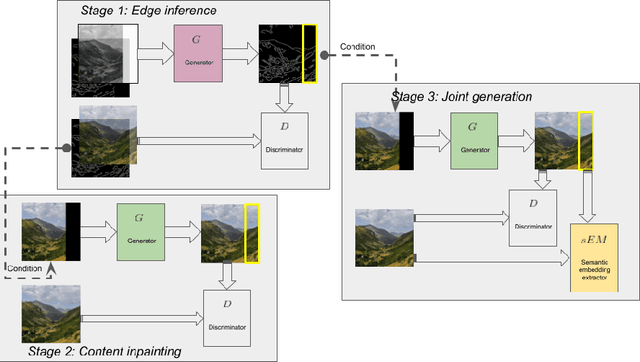
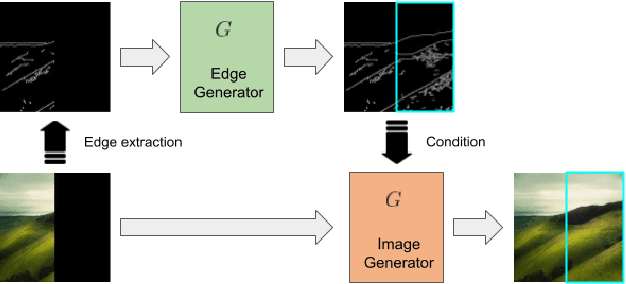


Deep learning techniques have made considerable progress in image inpainting, restoration, and reconstruction in the last few years. Image outpainting, also known as image extrapolation, lacks attention and practical approaches to be fulfilled, owing to difficulties caused by large-scale area loss and less legitimate neighboring information. These difficulties have made outpainted images handled by most of the existing models unrealistic to human eyes and spatially inconsistent. When upsampling through deconvolution to generate fake content, the naive generation methods may lead to results lacking high-frequency details and structural authenticity. Therefore, as our novelties to handle image outpainting problems, we introduce structural prior as a condition to optimize the generation quality and a new semantic embedding term to enhance perceptual sanity. we propose a deep learning method based on Generative Adversarial Network (GAN) and condition edges as structural prior in order to assist the generation. We use a multi-phase adversarial training scheme that comprises edge inference training, contents inpainting training, and joint training. The newly added semantic embedding loss is proved effective in practice.
GazeSAM: What You See is What You Segment
Apr 26, 2023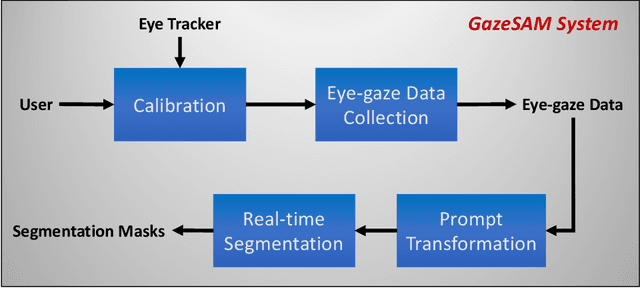
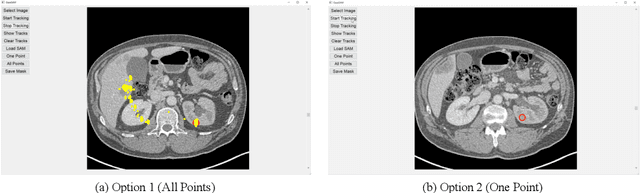
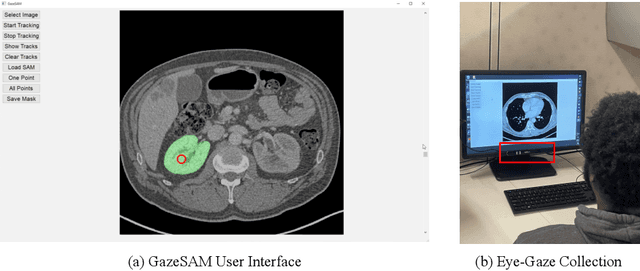
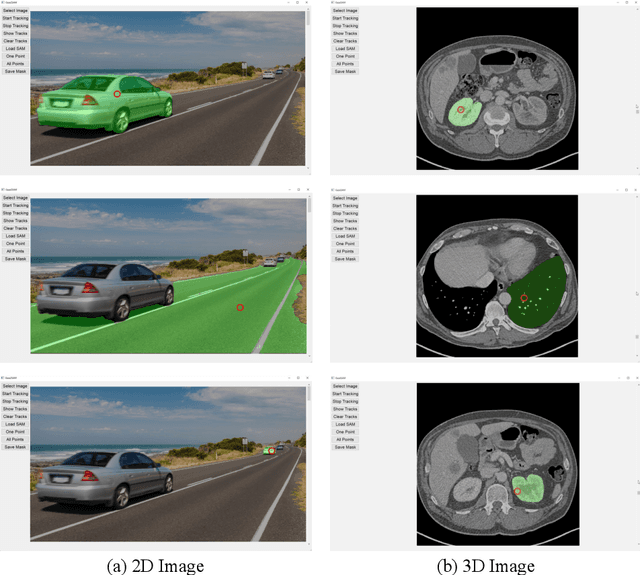
This study investigates the potential of eye-tracking technology and the Segment Anything Model (SAM) to design a collaborative human-computer interaction system that automates medical image segmentation. We present the \textbf{GazeSAM} system to enable radiologists to collect segmentation masks by simply looking at the region of interest during image diagnosis. The proposed system tracks radiologists' eye movement and utilizes the eye-gaze data as the input prompt for SAM, which automatically generates the segmentation mask in real time. This study is the first work to leverage the power of eye-tracking technology and SAM to enhance the efficiency of daily clinical practice. Moreover, eye-gaze data coupled with image and corresponding segmentation labels can be easily recorded for further advanced eye-tracking research. The code is available in \url{https://github.com/ukaukaaaa/GazeSAM}.
Unsupervised Domain Adaptation for Neuron Membrane Segmentation based on Structural Features
May 04, 2023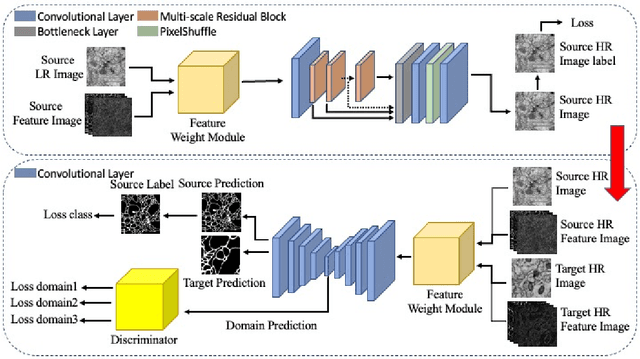

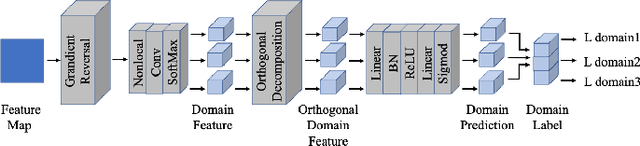
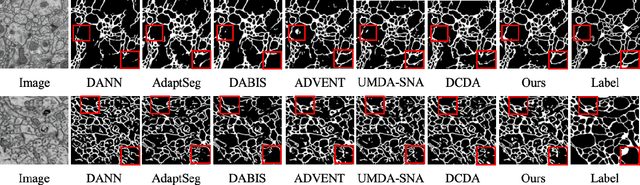
AI-enhanced segmentation of neuronal boundaries in electron microscopy (EM) images is crucial for automatic and accurate neuroinformatics studies. To enhance the limited generalization ability of typical deep learning frameworks for medical image analysis, unsupervised domain adaptation (UDA) methods have been applied. In this work, we propose to improve the performance of UDA methods on cross-domain neuron membrane segmentation in EM images. First, we designed a feature weight module considering the structural features during adaptation. Second, we introduced a structural feature-based super-resolution approach to alleviating the domain gap by adjusting the cross-domain image resolutions. Third, we proposed an orthogonal decomposition module to facilitate the extraction of domain-invariant features. Extensive experiments on two domain adaptive membrane segmentation applications have indicated the effectiveness of our method.