 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Medical Federated Model with Mixture of Personalized and Sharing Components
Jun 26, 2023
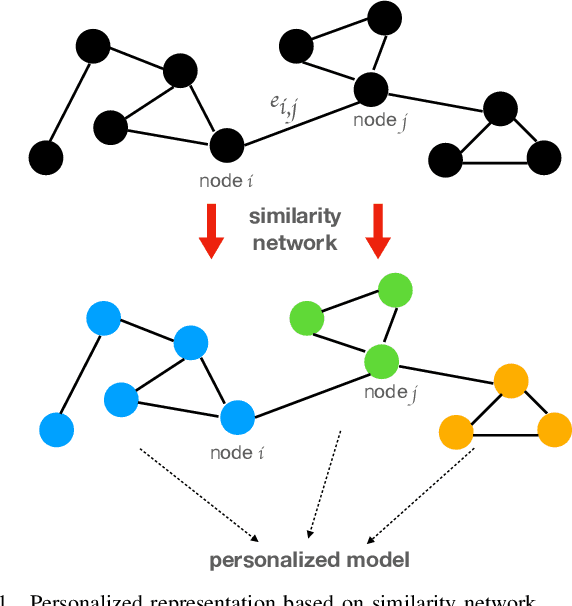
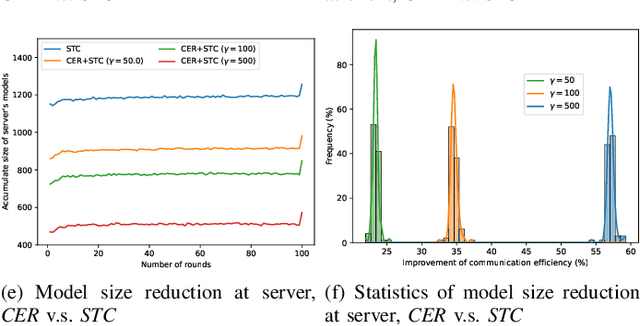

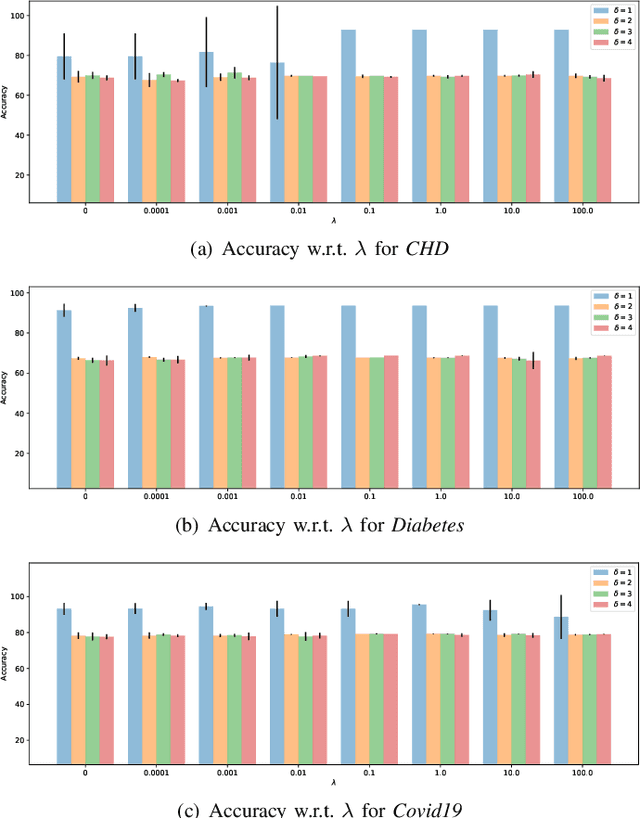
Although data-driven methods usually have noticeable performance on disease diagnosis and treatment, they are suspected of leakage of privacy due to collecting data for model training. Recently, federated learning provides a secure and trustable alternative to collaboratively train model without any exchange of medical data among multiple institutes. Therefore, it has draw much attention due to its natural merit on privacy protection. However, when heterogenous medical data exists between different hospitals, federated learning usually has to face with degradation of performance. In the paper, we propose a new personalized framework of federated learning to handle the problem. It successfully yields personalized models based on awareness of similarity between local data, and achieves better tradeoff between generalization and personalization than existing methods. After that, we further design a differentially sparse regularizer to improve communication efficiency during procedure of model training. Additionally, we propose an effective method to reduce the computational cost, which improves computation efficiency significantly. Furthermore, we collect 5 real medical datasets, including 2 public medical image datasets and 3 private multi-center clinical diagnosis datasets, and evaluate its performance by conducting nodule classification, tumor segmentation, and clinical risk prediction tasks. Comparing with 13 existing related methods, the proposed method successfully achieves the best model performance, and meanwhile up to 60% improvement of communication efficiency. Source code is public, and can be accessed at: https://github.com/ApplicationTechnologyOfMedicalBigData/pFedNet-code.
Model-based demosaicking for acquisitions by a RGBW color filter array
Jun 02, 2023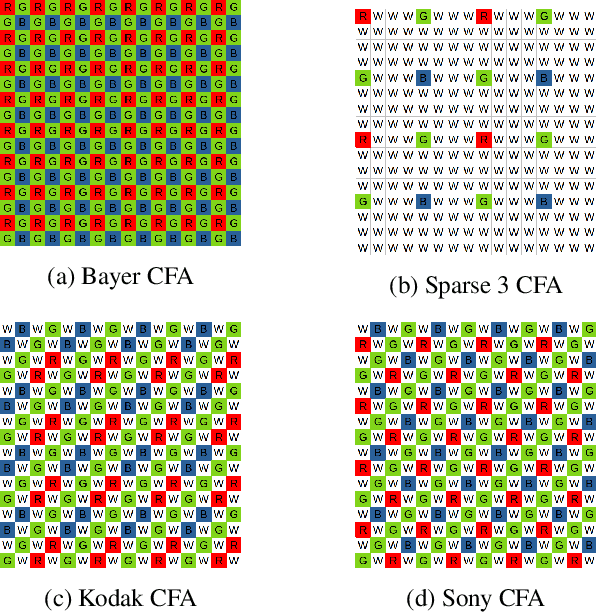



Microsatellites and drones are often equipped with digital cameras whose sensing system is based on color filter arrays (CFAs), which define a pattern of color filter overlaid over the focal plane. Recent commercial cameras have started implementing RGBW patterns, which include some filters with a wideband spectral response together with the more classical RGB ones. This allows for additional light energy to be captured by the relevant pixels and increases the overall SNR of the acquisition. Demosaicking defines reconstructing a multi-spectral image from the raw image and recovering the full color components for all pixels. However, this operation is often tailored for the most widespread patterns, such as the Bayer pattern. Consequently, less common patterns that are still employed in commercial cameras are often neglected. In this work, we present a generalized framework to represent the image formation model of such cameras. This model is then exploited by our proposed demosaicking algorithm to reconstruct the datacube of interest with a Bayesian approach, using a total variation regularizer as prior. Some preliminary experimental results are also presented, which apply to the reconstruction of acquisitions of various RGBW cameras.
Depth and DOF Cues Make A Better Defocus Blur Detector
Jun 20, 2023


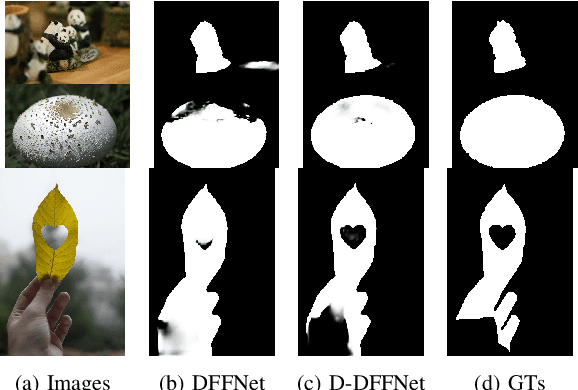
Defocus blur detection (DBD) separates in-focus and out-of-focus regions in an image. Previous approaches mistakenly mistook homogeneous areas in focus for defocus blur regions, likely due to not considering the internal factors that cause defocus blur. Inspired by the law of depth, depth of field (DOF), and defocus, we propose an approach called D-DFFNet, which incorporates depth and DOF cues in an implicit manner. This allows the model to understand the defocus phenomenon in a more natural way. Our method proposes a depth feature distillation strategy to obtain depth knowledge from a pre-trained monocular depth estimation model and uses a DOF-edge loss to understand the relationship between DOF and depth. Our approach outperforms state-of-the-art methods on public benchmarks and a newly collected large benchmark dataset, EBD. Source codes and EBD dataset are available at: https:github.com/yuxinjin-whu/D-DFFNet.
BIFRNet: A Brain-Inspired Feature Restoration DNN for Partially Occluded Image Recognition
Mar 16, 2023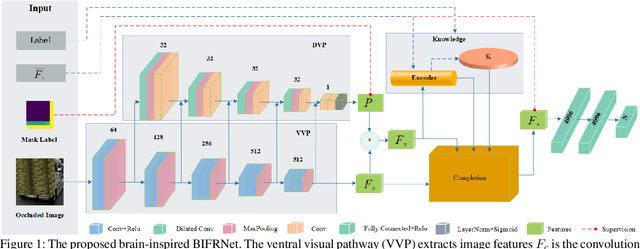


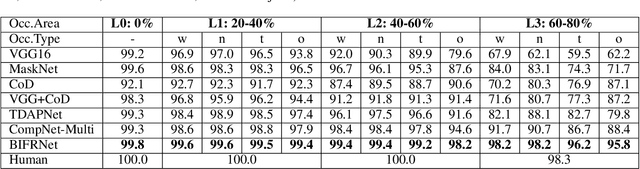
The partially occluded image recognition (POIR) problem has been a challenge for artificial intelligence for a long time. A common strategy to handle the POIR problem is using the non-occluded features for classification. Unfortunately, this strategy will lose effectiveness when the image is severely occluded, since the visible parts can only provide limited information. Several studies in neuroscience reveal that feature restoration which fills in the occluded information and is called amodal completion is essential for human brains to recognize partially occluded images. However, feature restoration is commonly ignored by CNNs, which may be the reason why CNNs are ineffective for the POIR problem. Inspired by this, we propose a novel brain-inspired feature restoration network (BIFRNet) to solve the POIR problem. It mimics a ventral visual pathway to extract image features and a dorsal visual pathway to distinguish occluded and visible image regions. In addition, it also uses a knowledge module to store object prior knowledge and uses a completion module to restore occluded features based on visible features and prior knowledge. Thorough experiments on synthetic and real-world occluded image datasets show that BIFRNet outperforms the existing methods in solving the POIR problem. Especially for severely occluded images, BIRFRNet surpasses other methods by a large margin and is close to the human brain performance. Furthermore, the brain-inspired design makes BIFRNet more interpretable.
S-TLLR: STDP-inspired Temporal Local Learning Rule for Spiking Neural Networks
Jun 27, 2023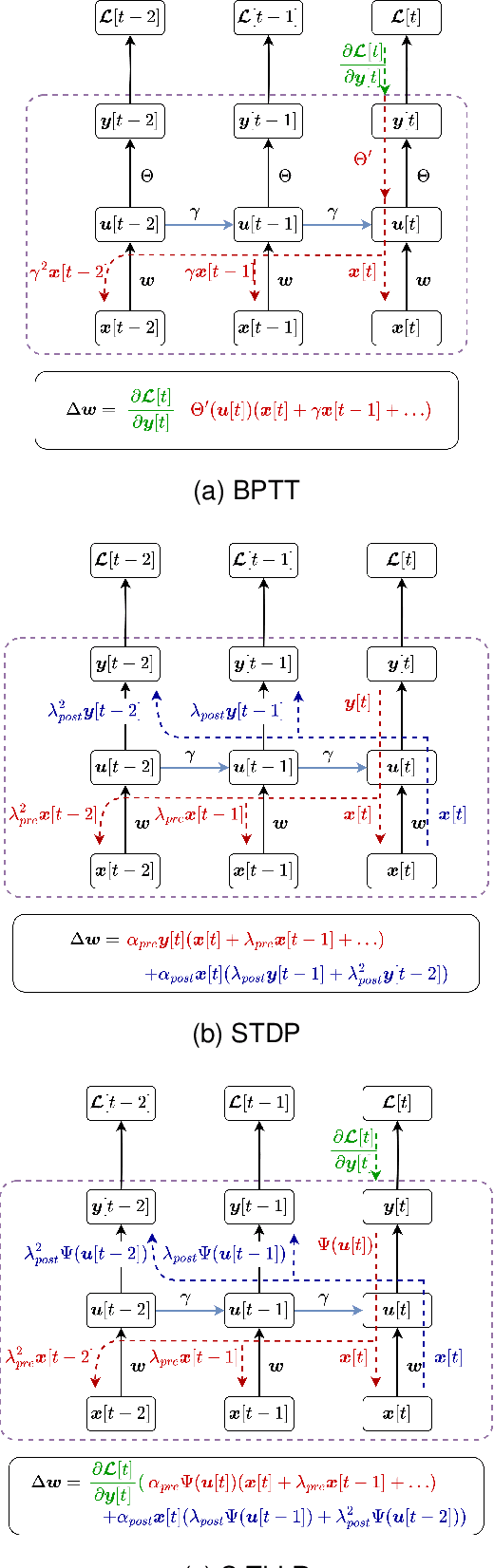
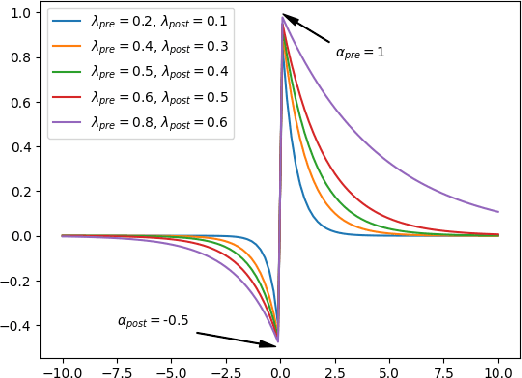
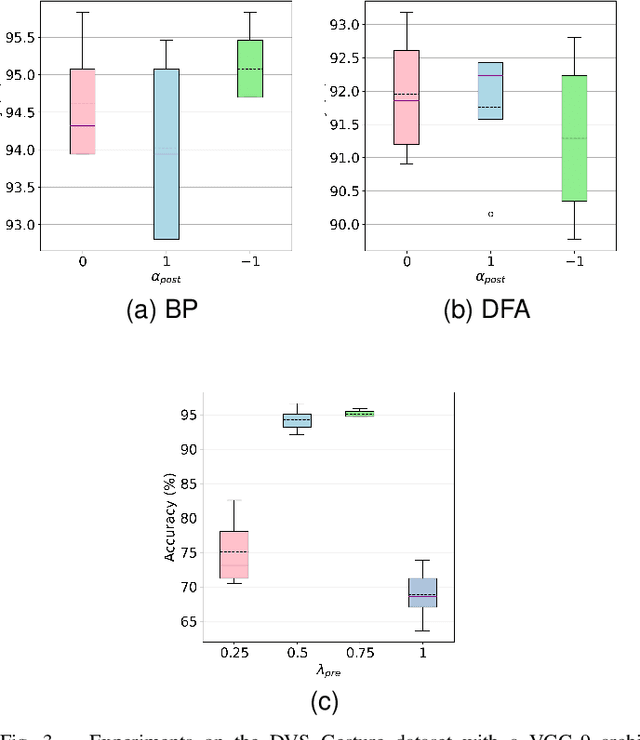
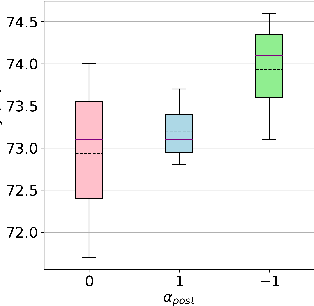
Spiking Neural Networks (SNNs) are biologically plausible models that have been identified as potentially apt for the deployment for energy-efficient intelligence at the edge, particularly for sequential learning tasks. However, training of SNNs poses a significant challenge due to the necessity for precise temporal and spatial credit assignment. Back-propagation through time (BPTT) algorithm, whilst being the most widely used method for addressing these issues, incurs a high computational cost due to its temporal dependency. Moreover, BPTT and its approximations solely utilize causal information derived from the spiking activity to compute the synaptic updates, thus neglecting non-causal relationships. In this work, we propose S-TLLR, a novel three-factor temporal local learning rule inspired by the Spike-Timing Dependent Plasticity (STDP) mechanism, aimed at training SNNs on event-based learning tasks. S-TLLR considers both causal and non-causal relationships between pre and post-synaptic activities, achieving performance comparable to BPTT and enhancing performance relative to methods using only causal information. Furthermore, S-TLLR has low memory and time complexity, which is independent of the number of time steps, rendering it suitable for online learning on low-power devices. To demonstrate the scalability of our proposed method, we have conducted extensive evaluations on event-based datasets spanning a wide range of applications, such as image and gesture recognition, audio classification, and optical flow estimation. In all the experiments, S-TLLR achieved high accuracy with a reduction in the number of computations between $1.1-10\times$.
Novel Hybrid-Learning Algorithms for Improved Millimeter-Wave Imaging Systems
Jun 27, 2023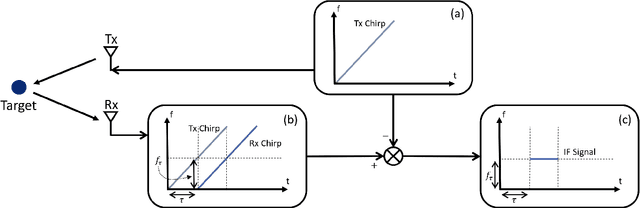
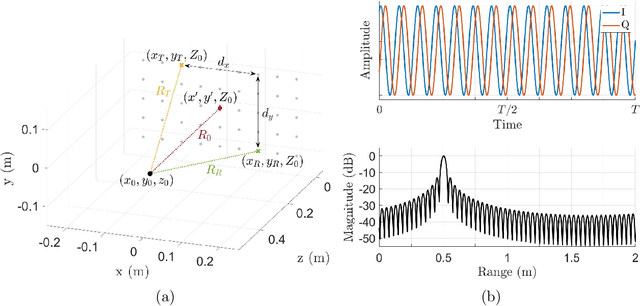

Increasing attention is being paid to millimeter-wave (mmWave), 30 GHz to 300 GHz, and terahertz (THz), 300 GHz to 10 THz, sensing applications including security sensing, industrial packaging, medical imaging, and non-destructive testing. Traditional methods for perception and imaging are challenged by novel data-driven algorithms that offer improved resolution, localization, and detection rates. Over the past decade, deep learning technology has garnered substantial popularity, particularly in perception and computer vision applications. Whereas conventional signal processing techniques are more easily generalized to various applications, hybrid approaches where signal processing and learning-based algorithms are interleaved pose a promising compromise between performance and generalizability. Furthermore, such hybrid algorithms improve model training by leveraging the known characteristics of radio frequency (RF) waveforms, thus yielding more efficiently trained deep learning algorithms and offering higher performance than conventional methods. This dissertation introduces novel hybrid-learning algorithms for improved mmWave imaging systems applicable to a host of problems in perception and sensing. Various problem spaces are explored, including static and dynamic gesture classification; precise hand localization for human computer interaction; high-resolution near-field mmWave imaging using forward synthetic aperture radar (SAR); SAR under irregular scanning geometries; mmWave image super-resolution using deep neural network (DNN) and Vision Transformer (ViT) architectures; and data-level multiband radar fusion using a novel hybrid-learning architecture. Furthermore, we introduce several novel approaches for deep learning model training and dataset synthesis.
Semi-supervised Pathological Image Segmentation via Cross Distillation of Multiple Attentions
May 30, 2023
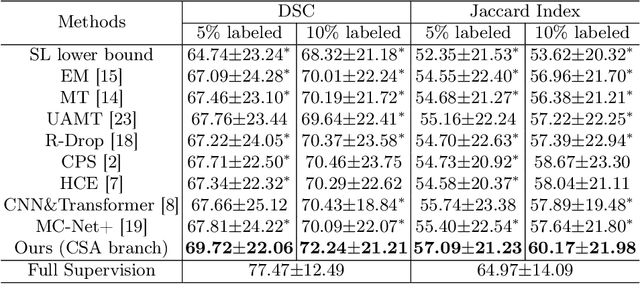
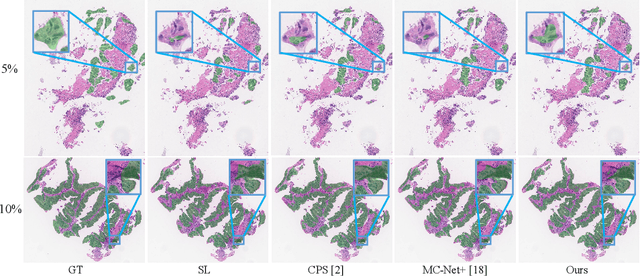
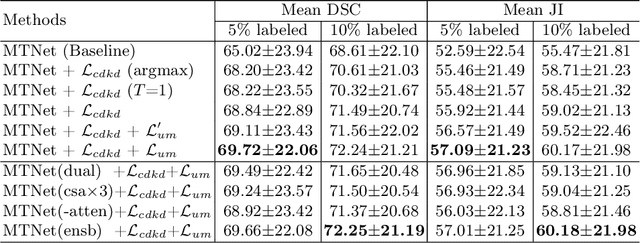
Segmentation of pathological images is a crucial step for accurate cancer diagnosis. However, acquiring dense annotations of such images for training is labor-intensive and time-consuming. To address this issue, Semi-Supervised Learning (SSL) has the potential for reducing the annotation cost, but it is challenged by a large number of unlabeled training images. In this paper, we propose a novel SSL method based on Cross Distillation of Multiple Attentions (CDMA) to effectively leverage unlabeled images. Firstly, we propose a Multi-attention Tri-branch Network (MTNet) that consists of an encoder and a three-branch decoder, with each branch using a different attention mechanism that calibrates features in different aspects to generate diverse outputs. Secondly, we introduce Cross Decoder Knowledge Distillation (CDKD) between the three decoder branches, allowing them to learn from each other's soft labels to mitigate the negative impact of incorrect pseudo labels in training. Additionally, uncertainty minimization is applied to the average prediction of the three branches, which further regularizes predictions on unlabeled images and encourages inter-branch consistency. Our proposed CDMA was compared with eight state-of-the-art SSL methods on the public DigestPath dataset, and the experimental results showed that our method outperforms the other approaches under different annotation ratios. The code is available at \href{https://github.com/HiLab-git/CDMA}{https://github.com/HiLab-git/CDMA.}
What makes a good data augmentation for few-shot unsupervised image anomaly detection?
Apr 18, 2023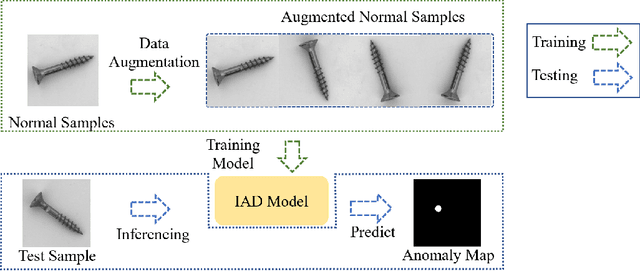

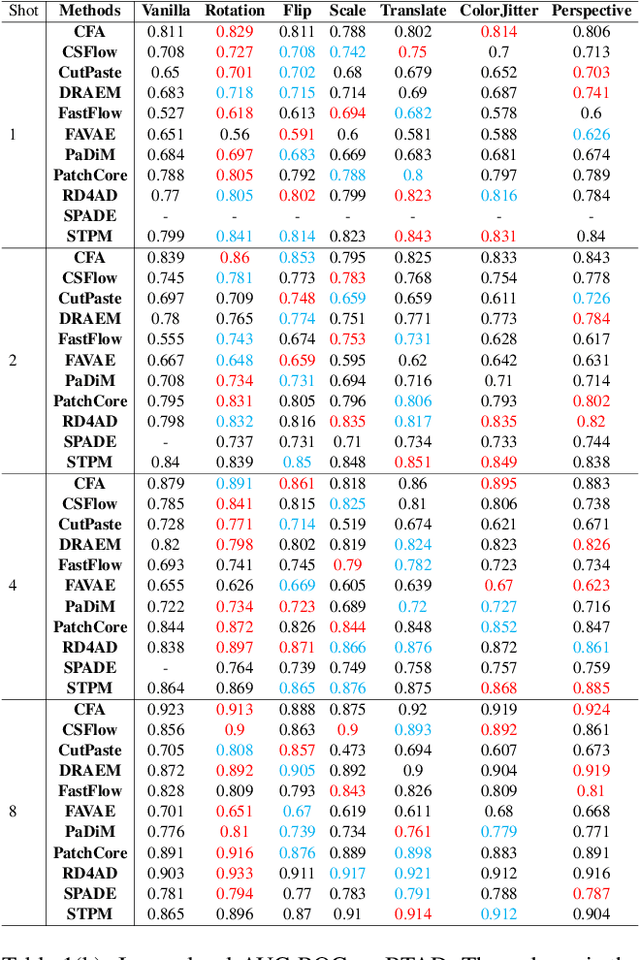
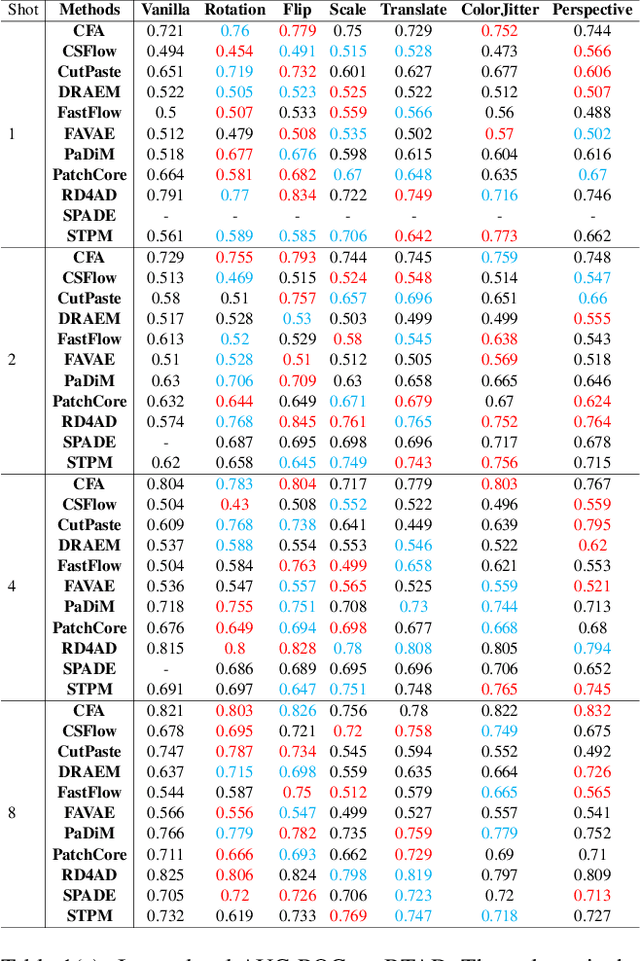
Data augmentation is a promising technique for unsupervised anomaly detection in industrial applications, where the availability of positive samples is often limited due to factors such as commercial competition and sample collection difficulties. In this paper, how to effectively select and apply data augmentation methods for unsupervised anomaly detection is studied. The impact of various data augmentation methods on different anomaly detection algorithms is systematically investigated through experiments. The experimental results show that the performance of different industrial image anomaly detection (termed as IAD) algorithms is not significantly affected by the specific data augmentation method employed and that combining multiple data augmentation methods does not necessarily yield further improvements in the accuracy of anomaly detection, although it can achieve excellent results on specific methods. These findings provide useful guidance on selecting appropriate data augmentation methods for different requirements in IAD.
Mixup-Privacy: A simple yet effective approach for privacy-preserving segmentation
May 23, 2023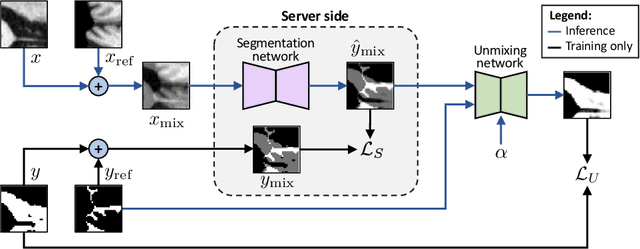
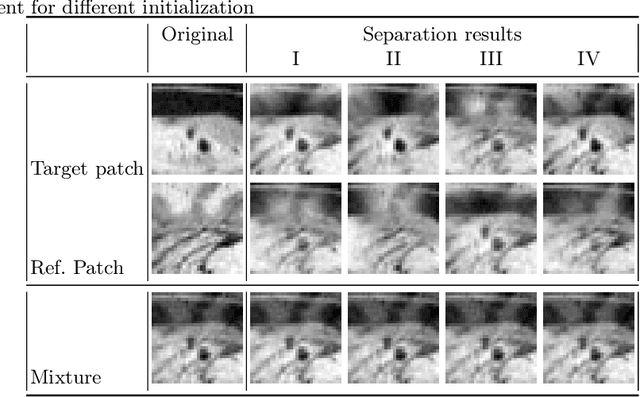
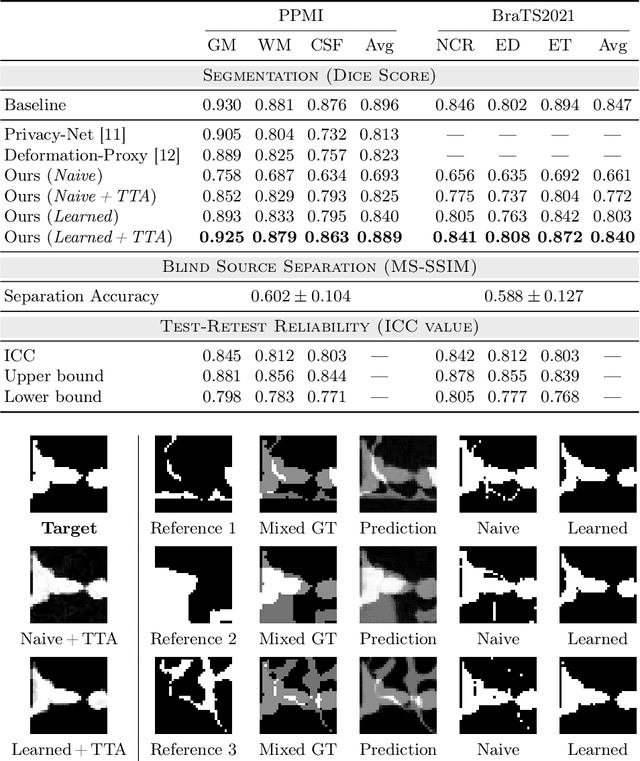
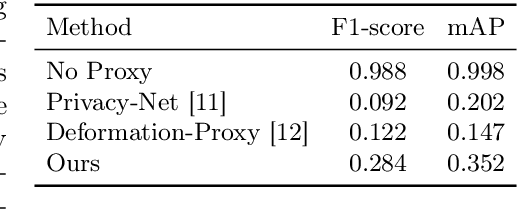
Privacy protection in medical data is a legitimate obstacle for centralized machine learning applications. Here, we propose a client-server image segmentation system which allows for the analysis of multi-centric medical images while preserving patient privacy. In this approach, the client protects the to-be-segmented patient image by mixing it to a reference image. As shown in our work, it is challenging to separate the image mixture to exact original content, thus making the data unworkable and unrecognizable for an unauthorized person. This proxy image is sent to a server for processing. The server then returns the mixture of segmentation maps, which the client can revert to a correct target segmentation. Our system has two components: 1) a segmentation network on the server side which processes the image mixture, and 2) a segmentation unmixing network which recovers the correct segmentation map from the segmentation mixture. Furthermore, the whole system is trained end-to-end. The proposed method is validated on the task of MRI brain segmentation using images from two different datasets. Results show that the segmentation accuracy of our method is comparable to a system trained on raw images, and outperforms other privacy-preserving methods with little computational overhead.
Search By Image: Deeply Exploring Beneficial Features for Beauty Product Retrieval
Mar 24, 2023


Searching by image is popular yet still challenging due to the extensive interference arose from i) data variations (e.g., background, pose, visual angle, brightness) of real-world captured images and ii) similar images in the query dataset. This paper studies a practically meaningful problem of beauty product retrieval (BPR) by neural networks. We broadly extract different types of image features, and raise an intriguing question that whether these features are beneficial to i) suppress data variations of real-world captured images, and ii) distinguish one image from others which look very similar but are intrinsically different beauty products in the dataset, therefore leading to an enhanced capability of BPR. To answer it, we present a novel variable-attention neural network to understand the combination of multiple features (termed VM-Net) of beauty product images. Considering that there are few publicly released training datasets for BPR, we establish a new dataset with more than one million images classified into more than 20K categories to improve both the generalization and anti-interference abilities of VM-Net and other methods. We verify the performance of VM-Net and its competitors on the benchmark dataset Perfect-500K, where VM-Net shows clear improvements over the competitors in terms of MAP@7. The source code and dataset will be released upon publication.