 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
FABRIC: Personalizing Diffusion Models with Iterative Feedback
Jul 19, 2023


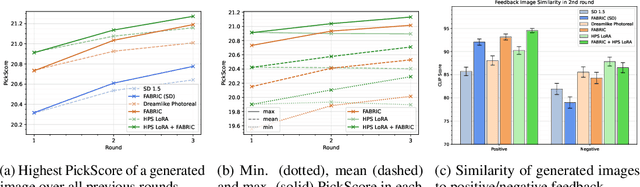
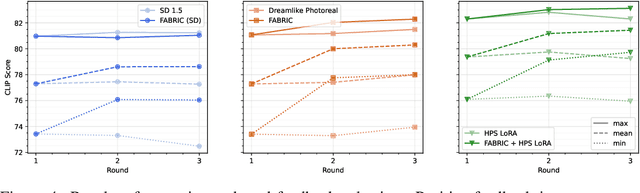
In an era where visual content generation is increasingly driven by machine learning, the integration of human feedback into generative models presents significant opportunities for enhancing user experience and output quality. This study explores strategies for incorporating iterative human feedback into the generative process of diffusion-based text-to-image models. We propose FABRIC, a training-free approach applicable to a wide range of popular diffusion models, which exploits the self-attention layer present in the most widely used architectures to condition the diffusion process on a set of feedback images. To ensure a rigorous assessment of our approach, we introduce a comprehensive evaluation methodology, offering a robust mechanism to quantify the performance of generative visual models that integrate human feedback. We show that generation results improve over multiple rounds of iterative feedback through exhaustive analysis, implicitly optimizing arbitrary user preferences. The potential applications of these findings extend to fields such as personalized content creation and customization.
Polyffusion: A Diffusion Model for Polyphonic Score Generation with Internal and External Controls
Jul 19, 2023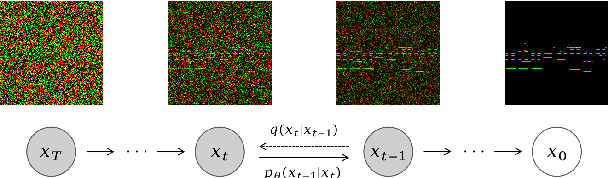

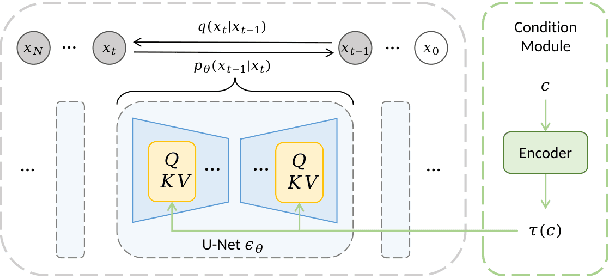
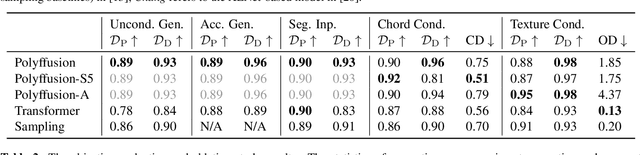
We propose Polyffusion, a diffusion model that generates polyphonic music scores by regarding music as image-like piano roll representations. The model is capable of controllable music generation with two paradigms: internal control and external control. Internal control refers to the process in which users pre-define a part of the music and then let the model infill the rest, similar to the task of masked music generation (or music inpainting). External control conditions the model with external yet related information, such as chord, texture, or other features, via the cross-attention mechanism. We show that by using internal and external controls, Polyffusion unifies a wide range of music creation tasks, including melody generation given accompaniment, accompaniment generation given melody, arbitrary music segment inpainting, and music arrangement given chords or textures. Experimental results show that our model significantly outperforms existing Transformer and sampling-based baselines, and using pre-trained disentangled representations as external conditions yields more effective controls.
PSDR-Room: Single Photo to Scene using Differentiable Rendering
Jul 06, 2023
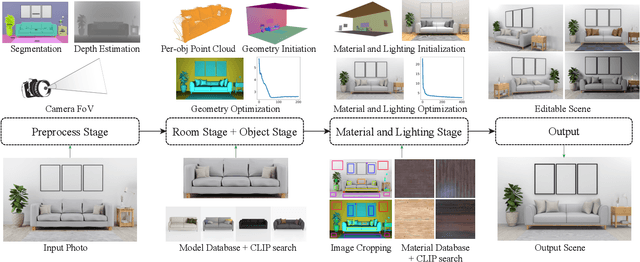
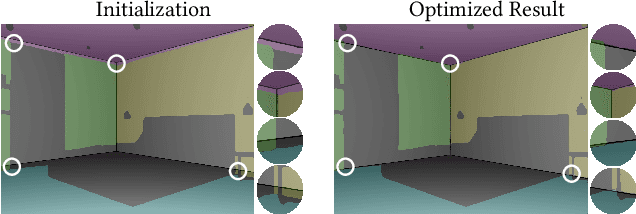
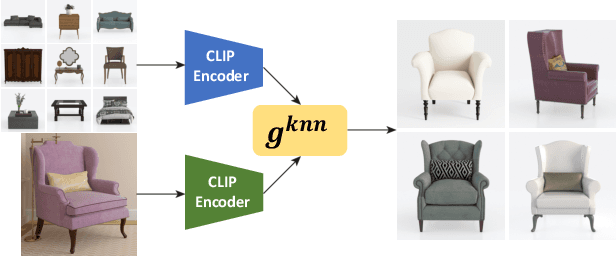
A 3D digital scene contains many components: lights, materials and geometries, interacting to reach the desired appearance. Staging such a scene is time-consuming and requires both artistic and technical skills. In this work, we propose PSDR-Room, a system allowing to optimize lighting as well as the pose and materials of individual objects to match a target image of a room scene, with minimal user input. To this end, we leverage a recent path-space differentiable rendering approach that provides unbiased gradients of the rendering with respect to geometry, lighting, and procedural materials, allowing us to optimize all of these components using gradient descent to visually match the input photo appearance. We use recent single-image scene understanding methods to initialize the optimization and search for appropriate 3D models and materials. We evaluate our method on real photographs of indoor scenes and demonstrate the editability of the resulting scene components.
What Makes ImageNet Look Unlike LAION
Jun 27, 2023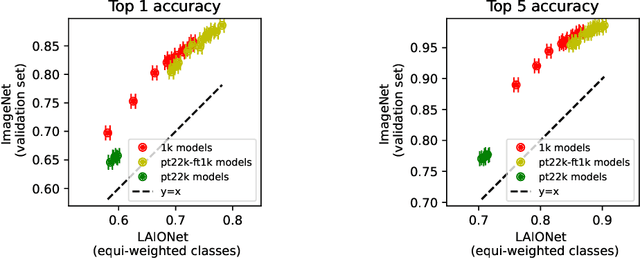
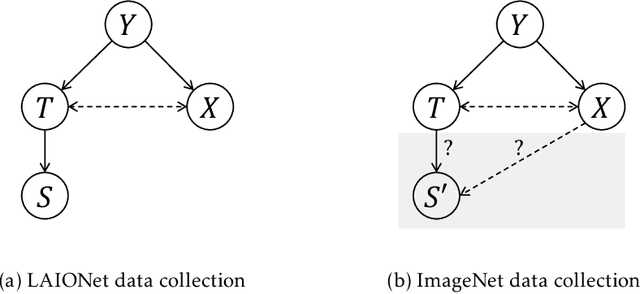
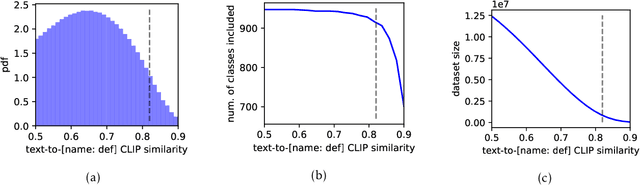
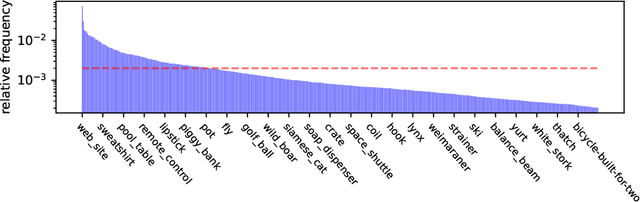
ImageNet was famously created from Flickr image search results. What if we recreated ImageNet instead by searching the massive LAION dataset based on image captions alone? In this work, we carry out this counterfactual investigation. We find that the resulting ImageNet recreation, which we call LAIONet, looks distinctly unlike the original. Specifically, the intra-class similarity of images in the original ImageNet is dramatically higher than it is for LAIONet. Consequently, models trained on ImageNet perform significantly worse on LAIONet. We propose a rigorous explanation for the discrepancy in terms of a subtle, yet important, difference in two plausible causal data-generating processes for the respective datasets, that we support with systematic experimentation. In a nutshell, searching based on an image caption alone creates an information bottleneck that mitigates the selection bias otherwise present in image-based filtering. Our explanation formalizes a long-held intuition in the community that ImageNet images are stereotypical, unnatural, and overly simple representations of the class category. At the same time, it provides a simple and actionable takeaway for future dataset creation efforts.
Investigating the Corruption Robustness of Image Classifiers with Random Lp-norm Corruptions
May 09, 2023Robustness is a fundamental property of machine learning classifiers to achieve safety and reliability. In the fields of adversarial robustness and formal robustness verification of image classification models, robustness is commonly defined as the stability to all input variations within an Lp-norm distance. However, robustness to random corruptions is usually improved and evaluated using variations observed in the real-world, while mathematically defined Lp-norm corruptions are rarely considered. This study investigates the use of random Lp-norm corruptions to augment the training and test data of image classifiers. We adapt an approach from the field of adversarial robustness to assess the model robustness to imperceptible random corruptions. We empirically and theoretically investigate whether robustness is transferable across different Lp-norms and derive conclusions on which Lp-norm corruptions a model should be trained and evaluated on. We find that training data augmentation with L0-norm corruptions improves corruption robustness while maintaining accuracy compared to standard training and when applied on top of selected state-of-the-art data augmentation techniques.
SketchFFusion: Sketch-guided image editing with diffusion model
Apr 06, 2023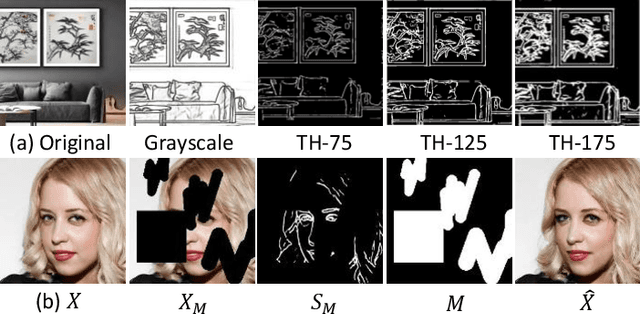

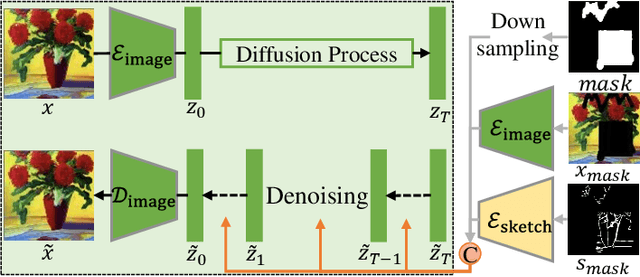
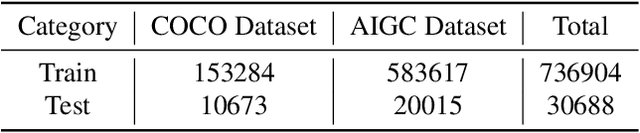
Sketch-guided image editing aims to achieve local fine-tuning of the image based on the sketch information provided by the user, while maintaining the original status of the unedited areas. Due to the high cost of acquiring human sketches, previous works mostly relied on edge maps as a substitute for sketches, but sketches possess more rich structural information. In this paper, we propose a sketch generation scheme that can preserve the main contours of an image and closely adhere to the actual sketch style drawn by the user. Simultaneously, current image editing methods often face challenges such as image distortion, training cost, and loss of fine details in the sketch. To address these limitations, We propose a conditional diffusion model (SketchFFusion) based on the sketch structure vector. We evaluate the generative performance of our model and demonstrate that it outperforms existing methods.
Mitigating Calibration Bias Without Fixed Attribute Grouping for Improved Fairness in Medical Imaging Analysis
Jul 04, 2023Trustworthy deployment of deep learning medical imaging models into real-world clinical practice requires that they be calibrated. However, models that are well calibrated overall can still be poorly calibrated for a sub-population, potentially resulting in a clinician unwittingly making poor decisions for this group based on the recommendations of the model. Although methods have been shown to successfully mitigate biases across subgroups in terms of model accuracy, this work focuses on the open problem of mitigating calibration biases in the context of medical image analysis. Our method does not require subgroup attributes during training, permitting the flexibility to mitigate biases for different choices of sensitive attributes without re-training. To this end, we propose a novel two-stage method: Cluster-Focal to first identify poorly calibrated samples, cluster them into groups, and then introduce group-wise focal loss to improve calibration bias. We evaluate our method on skin lesion classification with the public HAM10000 dataset, and on predicting future lesional activity for multiple sclerosis (MS) patients. In addition to considering traditional sensitive attributes (e.g. age, sex) with demographic subgroups, we also consider biases among groups with different image-derived attributes, such as lesion load, which are required in medical image analysis. Our results demonstrate that our method effectively controls calibration error in the worst-performing subgroups while preserving prediction performance, and outperforming recent baselines.
Training Energy-Based Models with Diffusion Contrastive Divergences
Jul 04, 2023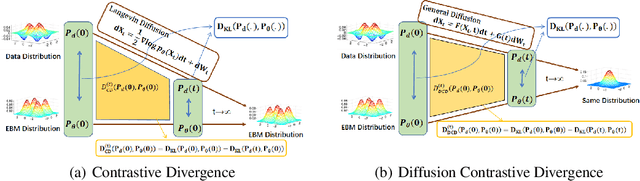


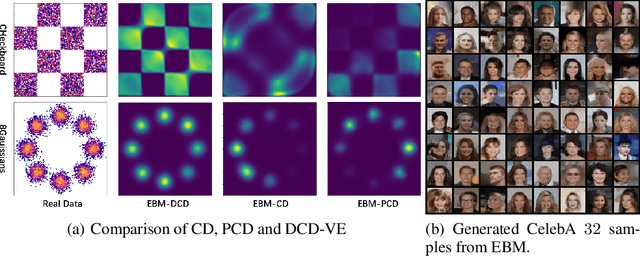
Energy-Based Models (EBMs) have been widely used for generative modeling. Contrastive Divergence (CD), a prevailing training objective for EBMs, requires sampling from the EBM with Markov Chain Monte Carlo methods (MCMCs), which leads to an irreconcilable trade-off between the computational burden and the validity of the CD. Running MCMCs till convergence is computationally intensive. On the other hand, short-run MCMC brings in an extra non-negligible parameter gradient term that is difficult to handle. In this paper, we provide a general interpretation of CD, viewing it as a special instance of our proposed Diffusion Contrastive Divergence (DCD) family. By replacing the Langevin dynamic used in CD with other EBM-parameter-free diffusion processes, we propose a more efficient divergence. We show that the proposed DCDs are both more computationally efficient than the CD and are not limited to a non-negligible gradient term. We conduct intensive experiments, including both synthesis data modeling and high-dimensional image denoising and generation, to show the advantages of the proposed DCDs. On the synthetic data learning and image denoising experiments, our proposed DCD outperforms CD by a large margin. In image generation experiments, the proposed DCD is capable of training an energy-based model for generating the Celab-A $32\times 32$ dataset, which is comparable to existing EBMs.
SLPD: Slide-level Prototypical Distillation for WSIs
Jul 20, 2023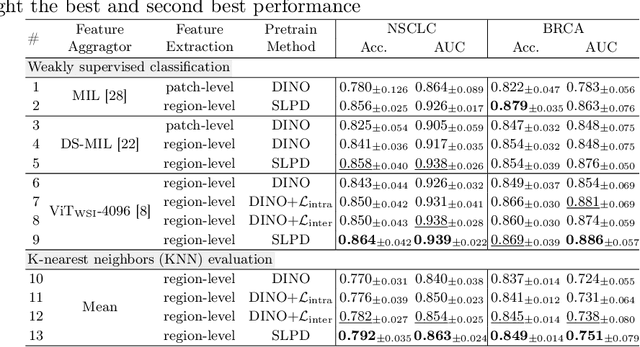
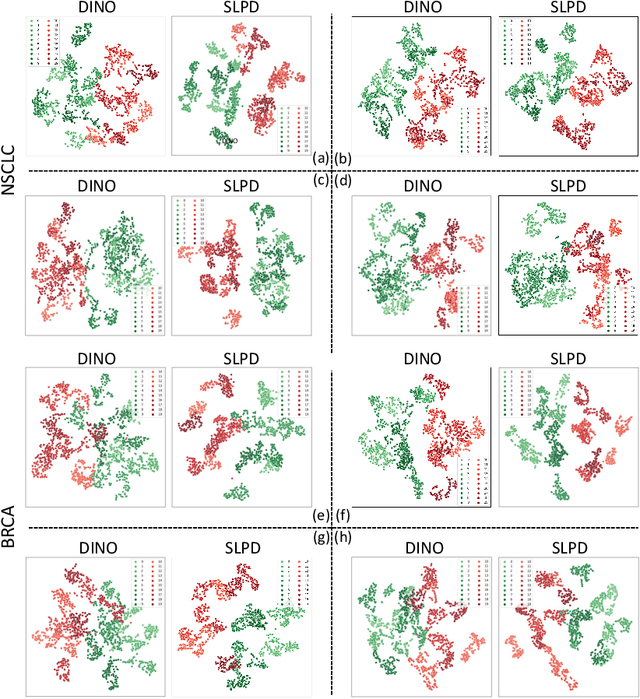
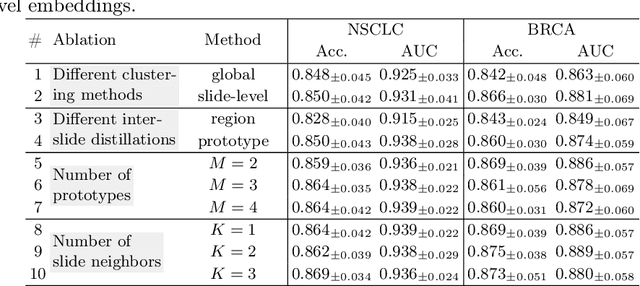
Improving the feature representation ability is the foundation of many whole slide pathological image (WSIs) tasks. Recent works have achieved great success in pathological-specific self-supervised learning (SSL). However, most of them only focus on learning patch-level representations, thus there is still a gap between pretext and slide-level downstream tasks, e.g., subtyping, grading and staging. Aiming towards slide-level representations, we propose Slide-Level Prototypical Distillation (SLPD) to explore intra- and inter-slide semantic structures for context modeling on WSIs. Specifically, we iteratively perform intra-slide clustering for the regions (4096x4096 patches) within each WSI to yield the prototypes and encourage the region representations to be closer to the assigned prototypes. By representing each slide with its prototypes, we further select similar slides by the set distance of prototypes and assign the regions by cross-slide prototypes for distillation. SLPD achieves state-of-the-art results on multiple slide-level benchmarks and demonstrates that representation learning of semantic structures of slides can make a suitable proxy task for WSI analysis. Code will be available at https://github.com/Carboxy/SLPD.
Progressive distillation diffusion for raw music generation
Jul 20, 2023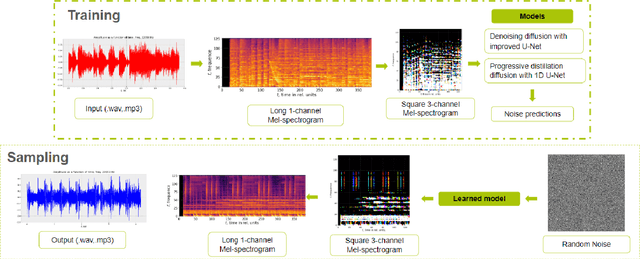
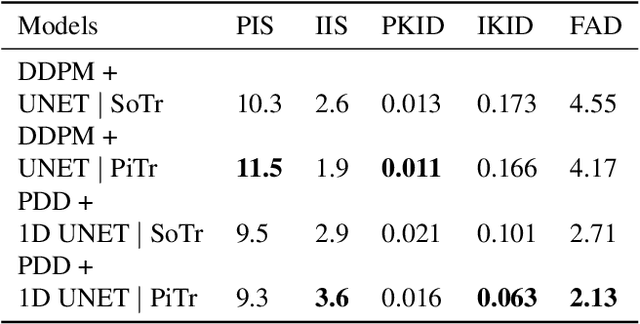
This paper aims to apply a new deep learning approach to the task of generating raw audio files. It is based on diffusion models, a recent type of deep generative model. This new type of method has recently shown outstanding results with image generation. A lot of focus has been given to those models by the computer vision community. On the other hand, really few have been given for other types of applications such as music generation in waveform domain. In this paper the model for unconditional generating applied to music is implemented: Progressive distillation diffusion with 1D U-Net. Then, a comparison of different parameters of diffusion and their value in a full result is presented. One big advantage of the methods implemented through this work is the fact that the model is able to deal with progressing audio processing and generating , using transformation from 1-channel 128 x 384 to 3-channel 128 x 128 mel-spectrograms and looped generation. The empirical comparisons are realized across different self-collected datasets.