 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Brain-like representational straightening of natural movies in robust feedforward neural networks
Aug 26, 2023
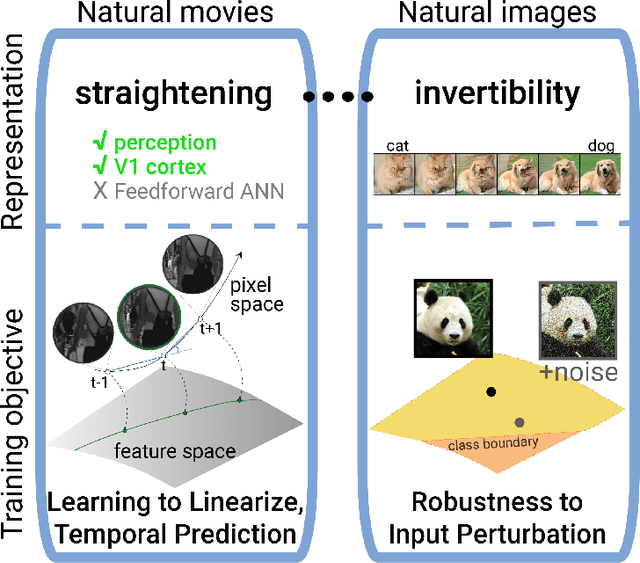
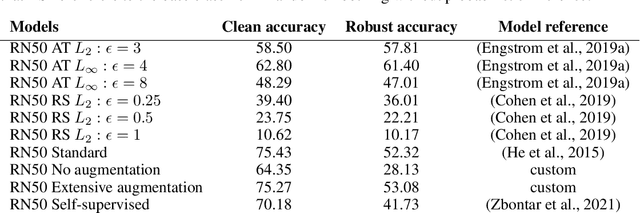
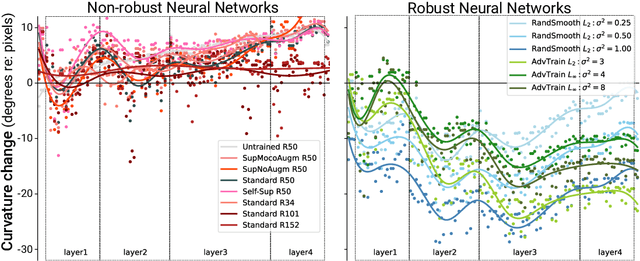
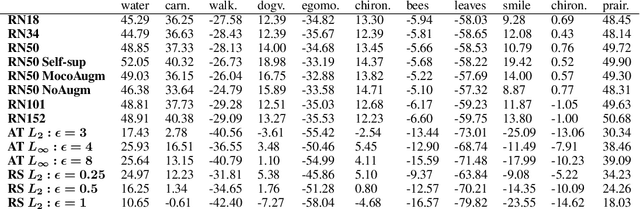
Representational straightening refers to a decrease in curvature of visual feature representations of a sequence of frames taken from natural movies. Prior work established straightening in neural representations of the primate primary visual cortex (V1) and perceptual straightening in human behavior as a hallmark of biological vision in contrast to artificial feedforward neural networks which did not demonstrate this phenomenon as they were not explicitly optimized to produce temporally predictable movie representations. Here, we show robustness to noise in the input image can produce representational straightening in feedforward neural networks. Both adversarial training (AT) and base classifiers for Random Smoothing (RS) induced remarkably straightened feature codes. Demonstrating their utility within the domain of natural movies, these codes could be inverted to generate intervening movie frames by linear interpolation in the feature space even though they were not trained on these trajectories. Demonstrating their biological utility, we found that AT and RS training improved predictions of neural data in primate V1 over baseline models providing a parsimonious, bio-plausible mechanism -- noise in the sensory input stages -- for generating representations in early visual cortex. Finally, we compared the geometric properties of frame representations in these networks to better understand how they produced representations that mimicked the straightening phenomenon from biology. Overall, this work elucidating emergent properties of robust neural networks demonstrates that it is not necessary to utilize predictive objectives or train directly on natural movie statistics to achieve models supporting straightened movie representations similar to human perception that also predict V1 neural responses.
* 21 pages, 15 figures, published in ICLR 2023
Exploring Diverse In-Context Configurations for Image Captioning
May 24, 2023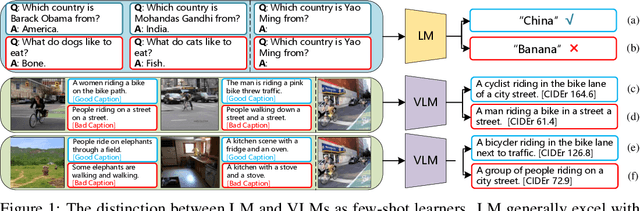
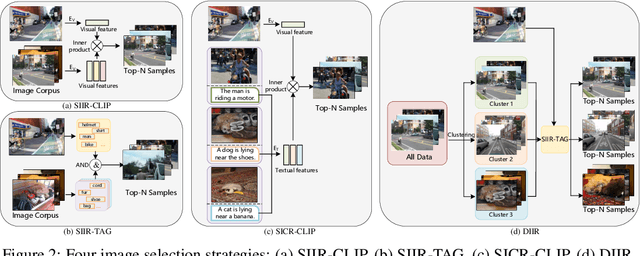
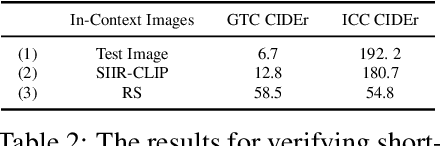
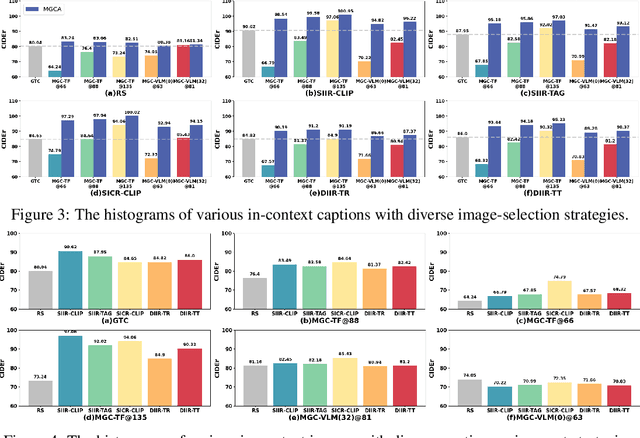
After discovering that Language Models (LMs) can be good in-context few-shot learners, numerous strategies have been proposed to optimize in-context sequence configurations. Recently, researchers in Vision-Language (VL) domains also develop their few-shot learners, while they only use the simplest way, \ie, randomly sampling, to configure in-context image-text pairs. In order to explore the effects of varying configurations on VL in-context learning, we devised four strategies for image selection and four for caption assignment to configure in-context image-text pairs for image captioning. Here Image Captioning is used as the case study since it can be seen as the visually-conditioned LM. Our comprehensive experiments yield two counter-intuitive but valuable insights, highlighting the distinct characteristics of VL in-context learning due to multi-modal synergy, as compared to the NLP case.
Generative Approach for Probabilistic Human Mesh Recovery using Diffusion Models
Aug 05, 2023
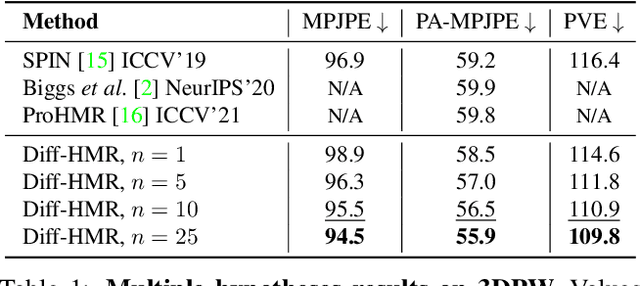
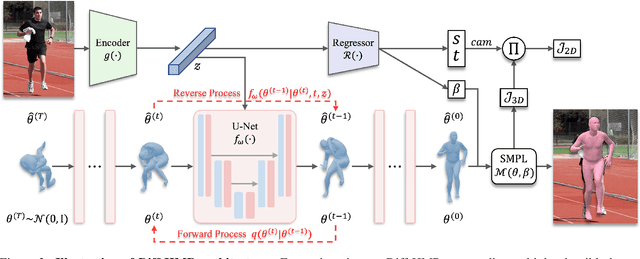

This work focuses on the problem of reconstructing a 3D human body mesh from a given 2D image. Despite the inherent ambiguity of the task of human mesh recovery, most existing works have adopted a method of regressing a single output. In contrast, we propose a generative approach framework, called "Diffusion-based Human Mesh Recovery (Diff-HMR)" that takes advantage of the denoising diffusion process to account for multiple plausible outcomes. During the training phase, the SMPL parameters are diffused from ground-truth parameters to random distribution, and Diff-HMR learns the reverse process of this diffusion. In the inference phase, the model progressively refines the given random SMPL parameters into the corresponding parameters that align with the input image. Diff-HMR, being a generative approach, is capable of generating diverse results for the same input image as the input noise varies. We conduct validation experiments, and the results demonstrate that the proposed framework effectively models the inherent ambiguity of the task of human mesh recovery in a probabilistic manner. The code is available at https://github.com/hanbyel0105/Diff-HMR
PromptUNet: Toward Interactive Medical Image Segmentation
May 17, 2023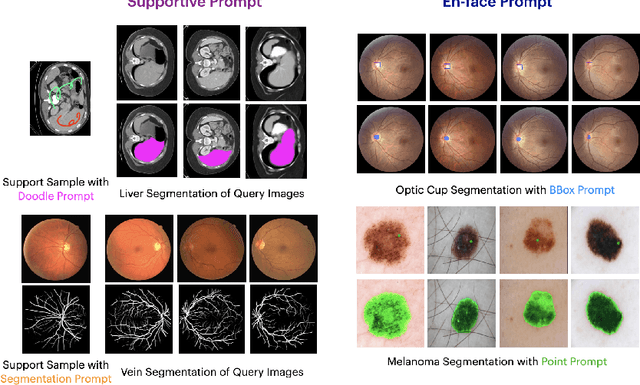
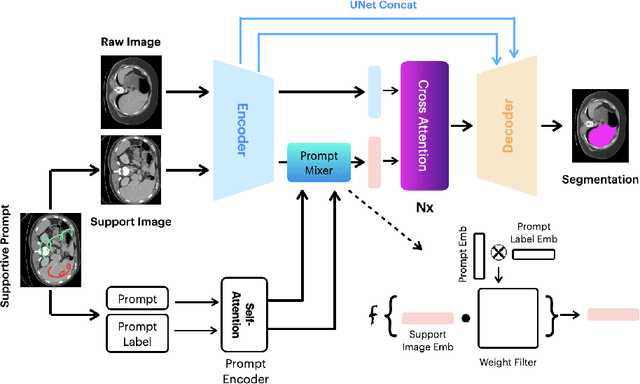
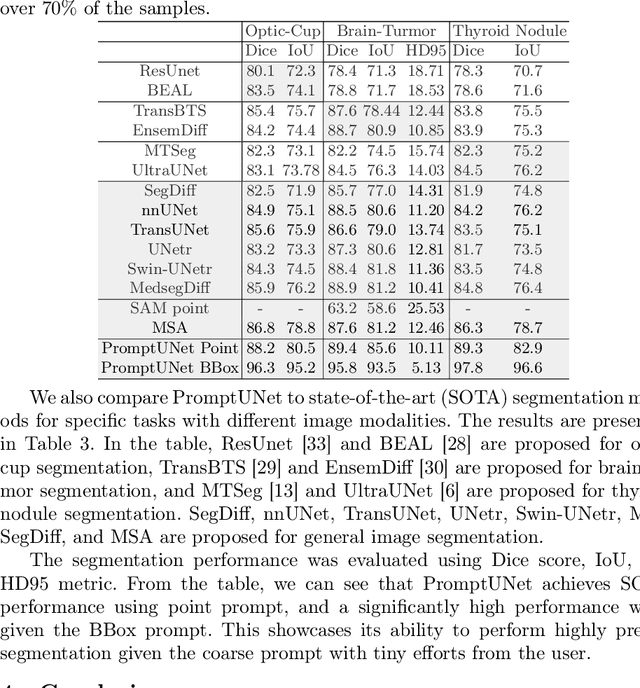
Prompt-based segmentation, also known as interactive segmentation, has recently become a popular approach in image segmentation. A well-designed prompt-based model called Segment Anything Model (SAM) has demonstrated its ability to segment a wide range of natural images, which has sparked a lot of discussion in the community. However, recent studies have shown that SAM performs poorly on medical images. This has motivated us to design a new prompt-based segmentation model specifically for medical image segmentation. In this paper, we combine the prompted-based segmentation paradigm with UNet, which is a widly-recognized successful architecture for medical image segmentation. We have named the resulting model PromptUNet. In order to adapt the real-world clinical use, we expand the existing prompt types in SAM to include novel Supportive Prompts and En-face Prompts. We have evaluated the capabilities of PromptUNet on 19 medical image segmentation tasks using a variety of image modalities, including CT, MRI, ultrasound, fundus, and dermoscopic images. Our results show that PromptUNet outperforms a wide range of state-of-the-art (SOTA) medical image segmentation methods, including nnUNet, TransUNet, UNetr, MedSegDiff, and MSA. Code will be released at: https://github.com/WuJunde/PromptUNet.
Cryo-forum: A framework for orientation recovery with uncertainty measure with the application in cryo-EM image analysis
Jul 19, 2023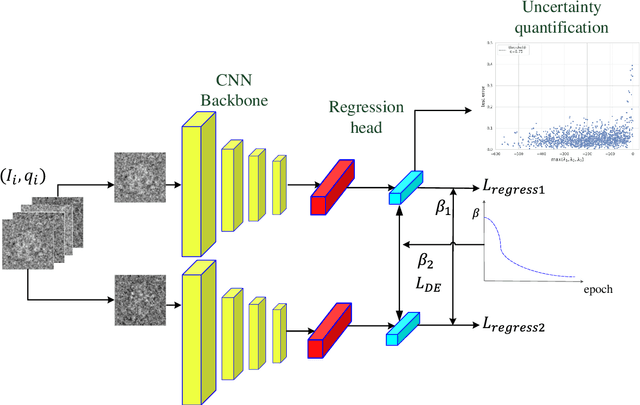
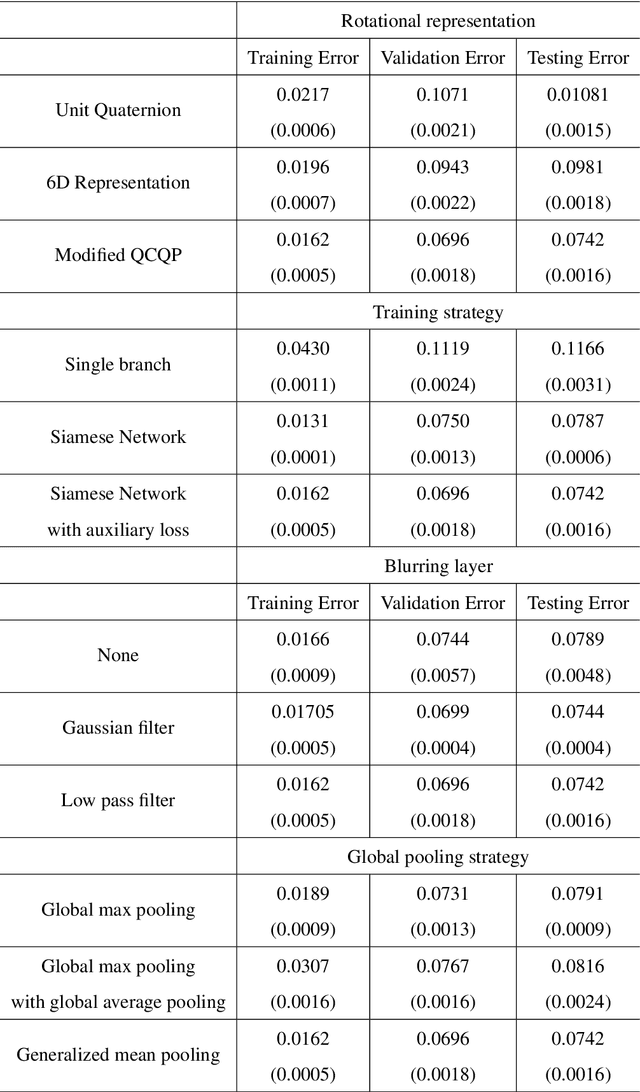
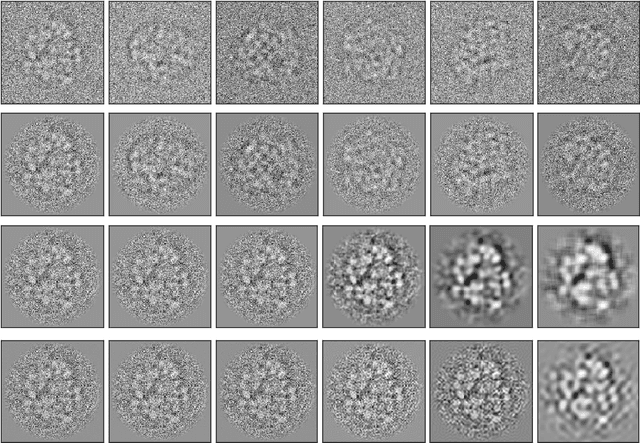
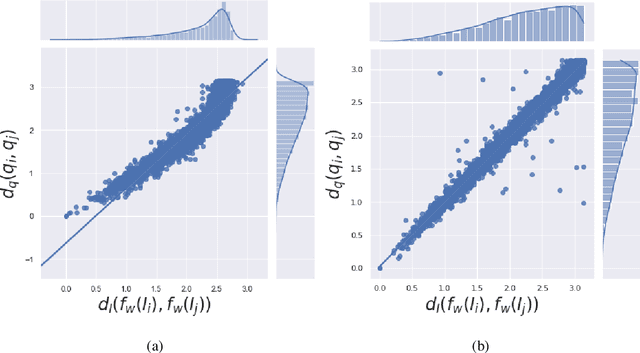
In single-particle cryo-electron microscopy (cryo-EM), the efficient determination of orientation parameters for 2D projection images poses a significant challenge yet is crucial for reconstructing 3D structures. This task is complicated by the high noise levels present in the cryo-EM datasets, which often include outliers, necessitating several time-consuming 2D clean-up processes. Recently, solutions based on deep learning have emerged, offering a more streamlined approach to the traditionally laborious task of orientation estimation. These solutions often employ amortized inference, eliminating the need to estimate parameters individually for each image. However, these methods frequently overlook the presence of outliers and may not adequately concentrate on the components used within the network. This paper introduces a novel approach that uses a 10-dimensional feature vector to represent the orientation and applies a Quadratically-Constrained Quadratic Program to derive the predicted orientation as a unit quaternion, supplemented by an uncertainty metric. Furthermore, we propose a unique loss function that considers the pairwise distances between orientations, thereby enhancing the accuracy of our method. Finally, we also comprehensively evaluate the design choices involved in constructing the encoder network, a topic that has not received sufficient attention in the literature. Our numerical analysis demonstrates that our methodology effectively recovers orientations from 2D cryo-EM images in an end-to-end manner. Importantly, the inclusion of uncertainty quantification allows for direct clean-up of the dataset at the 3D level. Lastly, we package our proposed methods into a user-friendly software suite named cryo-forum, designed for easy accessibility by the developers.
Wavelet-based Unsupervised Label-to-Image Translation
May 16, 2023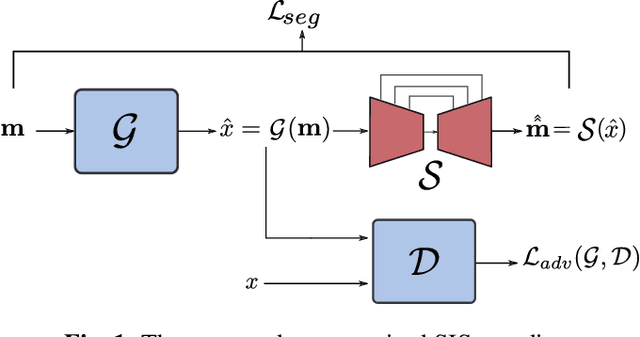
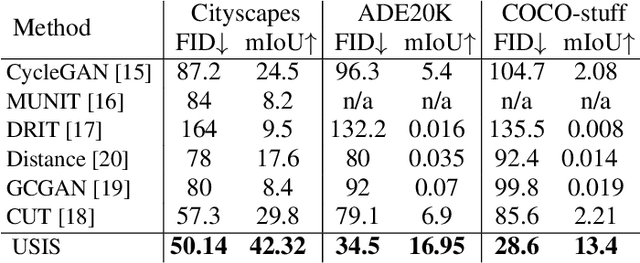

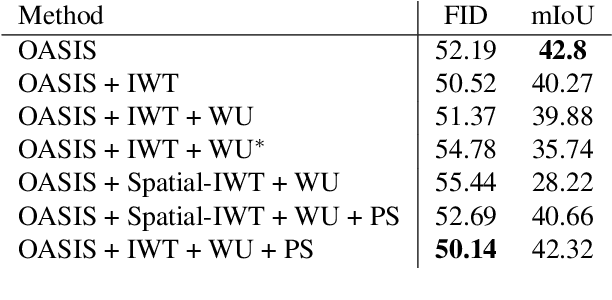
Semantic Image Synthesis (SIS) is a subclass of image-to-image translation where a semantic layout is used to generate a photorealistic image. State-of-the-art conditional Generative Adversarial Networks (GANs) need a huge amount of paired data to accomplish this task while generic unpaired image-to-image translation frameworks underperform in comparison, because they color-code semantic layouts and learn correspondences in appearance instead of semantic content. Starting from the assumption that a high quality generated image should be segmented back to its semantic layout, we propose a new Unsupervised paradigm for SIS (USIS) that makes use of a self-supervised segmentation loss and whole image wavelet based discrimination. Furthermore, in order to match the high-frequency distribution of real images, a novel generator architecture in the wavelet domain is proposed. We test our methodology on 3 challenging datasets and demonstrate its ability to bridge the performance gap between paired and unpaired models.
Learning Noise-Resistant Image Representation by Aligning Clean and Noisy Domains
Jul 03, 2023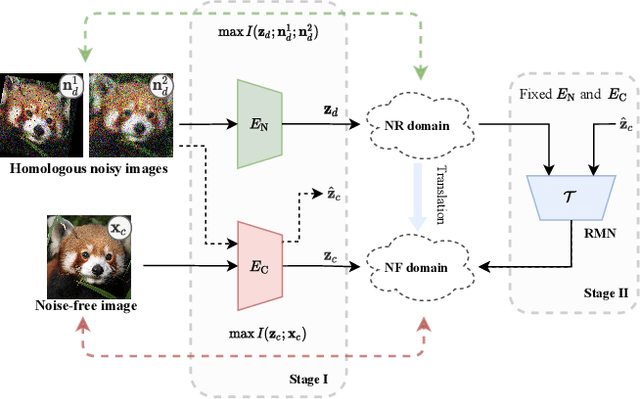
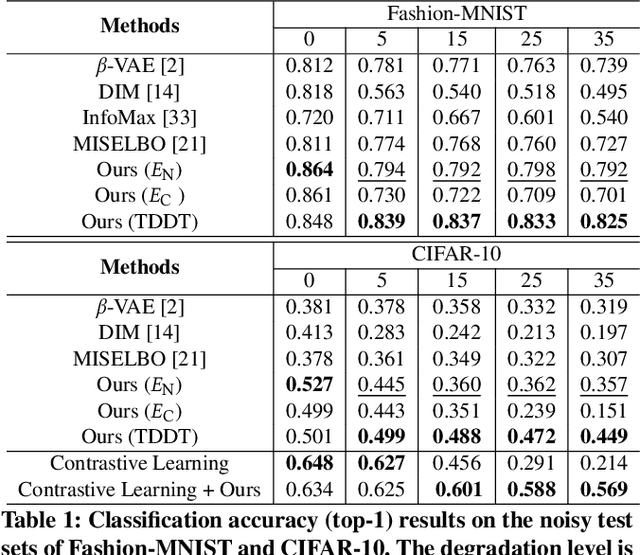
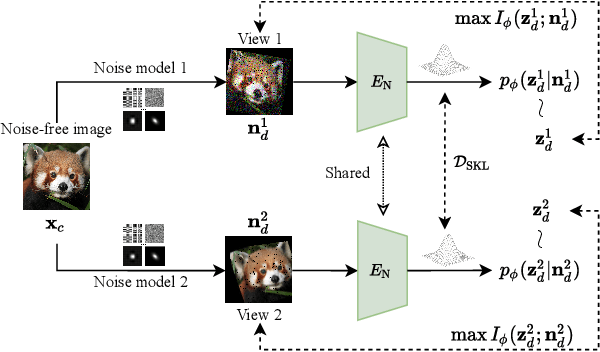

Recent supervised and unsupervised image representation learning algorithms have achieved quantum leaps. However, these techniques do not account for representation resilience against noise in their design paradigms. Consequently, these effective methods suffer failure when confronted with noise outside the training distribution, such as complicated real-world noise that is usually opaque to model training. To address this issue, dual domains are optimized to separately model a canonical space for noisy representations, namely the Noise-Robust (NR) domain, and a twinned canonical clean space, namely the Noise-Free (NF) domain, by maximizing the interaction information between the representations. Given the dual canonical domains, we design a target-guided implicit neural mapping function to accurately translate the NR representations to the NF domain, yielding noise-resistant representations by eliminating noise regencies. The proposed method is a scalable module that can be readily integrated into existing learning systems to improve their robustness against noise. Comprehensive trials of various tasks using both synthetic and real-world noisy data demonstrate that the proposed Target-Guided Dual-Domain Translation (TDDT) method is able to achieve remarkable performance and robustness in the face of complex noisy images.
Pseudo Flow Consistency for Self-Supervised 6D Object Pose Estimation
Aug 19, 2023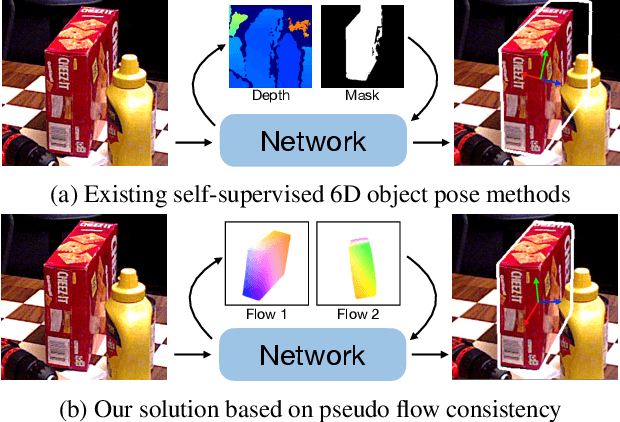
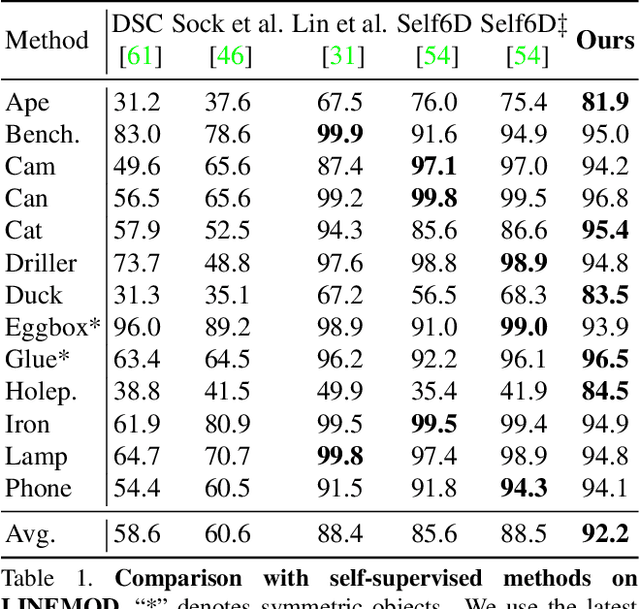
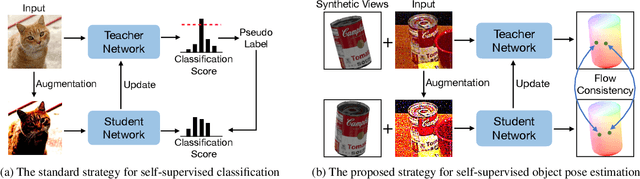
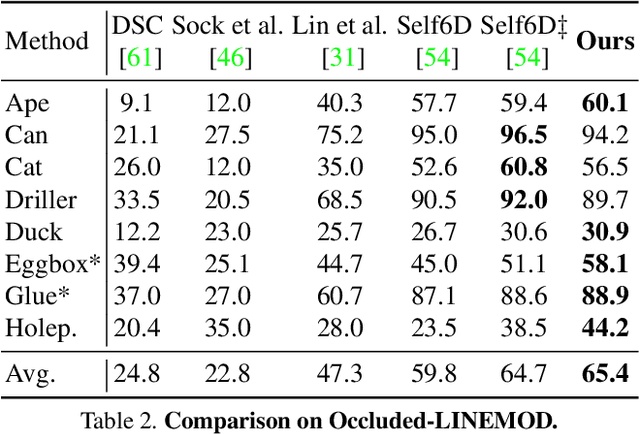
Most self-supervised 6D object pose estimation methods can only work with additional depth information or rely on the accurate annotation of 2D segmentation masks, limiting their application range. In this paper, we propose a 6D object pose estimation method that can be trained with pure RGB images without any auxiliary information. We first obtain a rough pose initialization from networks trained on synthetic images rendered from the target's 3D mesh. Then, we introduce a refinement strategy leveraging the geometry constraint in synthetic-to-real image pairs from multiple different views. We formulate this geometry constraint as pixel-level flow consistency between the training images with dynamically generated pseudo labels. We evaluate our method on three challenging datasets and demonstrate that it outperforms state-of-the-art self-supervised methods significantly, with neither 2D annotations nor additional depth images.
Cross-modal & Cross-domain Learning for Unsupervised LiDAR Semantic Segmentation
Aug 05, 2023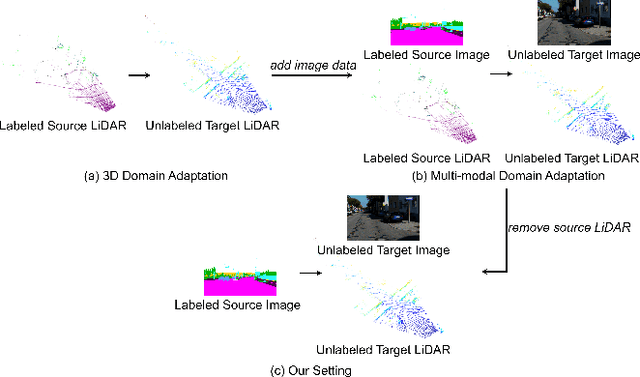
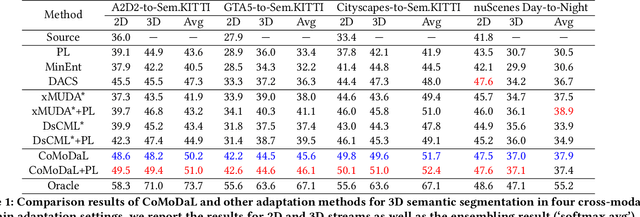
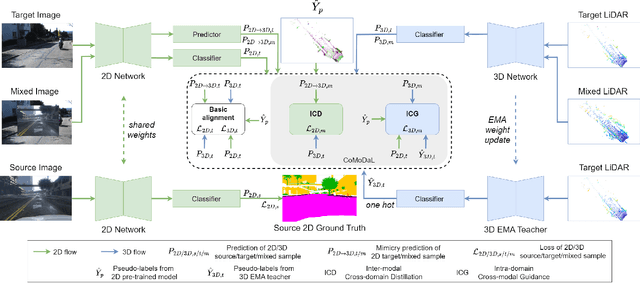

In recent years, cross-modal domain adaptation has been studied on the paired 2D image and 3D LiDAR data to ease the labeling costs for 3D LiDAR semantic segmentation (3DLSS) in the target domain. However, in such a setting the paired 2D and 3D data in the source domain are still collected with additional effort. Since the 2D-3D projections can enable the 3D model to learn semantic information from the 2D counterpart, we ask whether we could further remove the need of source 3D data and only rely on the source 2D images. To answer it, this paper studies a new 3DLSS setting where a 2D dataset (source) with semantic annotations and a paired but unannotated 2D image and 3D LiDAR data (target) are available. To achieve 3DLSS in this scenario, we propose Cross-Modal and Cross-Domain Learning (CoMoDaL). Specifically, our CoMoDaL aims at modeling 1) inter-modal cross-domain distillation between the unpaired source 2D image and target 3D LiDAR data, and 2) the intra-domain cross-modal guidance between the target 2D image and 3D LiDAR data pair. In CoMoDaL, we propose to apply several constraints, such as point-to-pixel and prototype-to-pixel alignments, to associate the semantics in different modalities and domains by constructing mixed samples in two modalities. The experimental results on several datasets show that in the proposed setting, the developed CoMoDaL can achieve segmentation without the supervision of labeled LiDAR data. Ablations are also conducted to provide more analysis. Code will be available publicly.
Classification Committee for Active Deep Object Detection
Aug 16, 2023
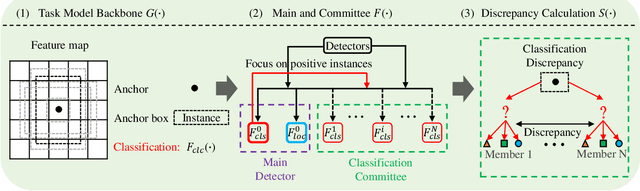
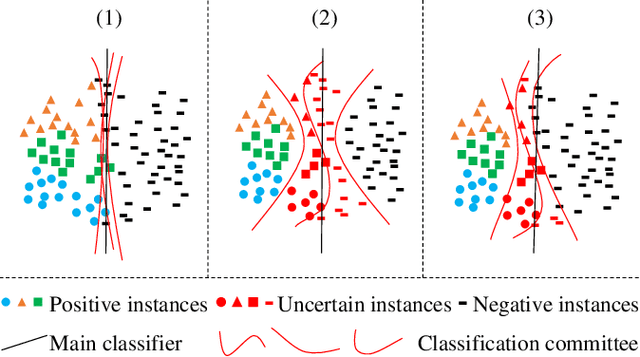
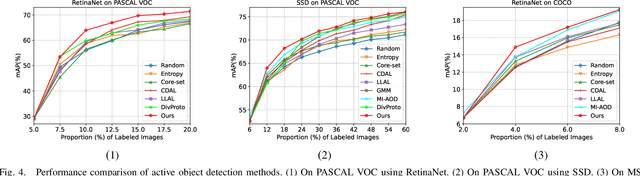
In object detection, the cost of labeling is much high because it needs not only to confirm the categories of multiple objects in an image but also to accurately determine the bounding boxes of each object. Thus, integrating active learning into object detection will raise pretty positive significance. In this paper, we propose a classification committee for active deep object detection method by introducing a discrepancy mechanism of multiple classifiers for samples' selection when training object detectors. The model contains a main detector and a classification committee. The main detector denotes the target object detector trained from a labeled pool composed of the selected informative images. The role of the classification committee is to select the most informative images according to their uncertainty values from the view of classification, which is expected to focus more on the discrepancy and representative of instances. Specifically, they compute the uncertainty for a specified instance within the image by measuring its discrepancy output by the committee pre-trained via the proposed Maximum Classifiers Discrepancy Group Loss (MCDGL). The most informative images are finally determined by selecting the ones with many high-uncertainty instances. Besides, to mitigate the impact of interference instances, we design a Focus on Positive Instances Loss (FPIL) to make the committee the ability to automatically focus on the representative instances as well as precisely encode their discrepancies for the same instance. Experiments are conducted on Pascal VOC and COCO datasets versus some popular object detectors. And results show that our method outperforms the state-of-the-art active learning methods, which verifies the effectiveness of the proposed method.