 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Efficient scene text image super-resolution with semantic guidance
Mar 20, 2024
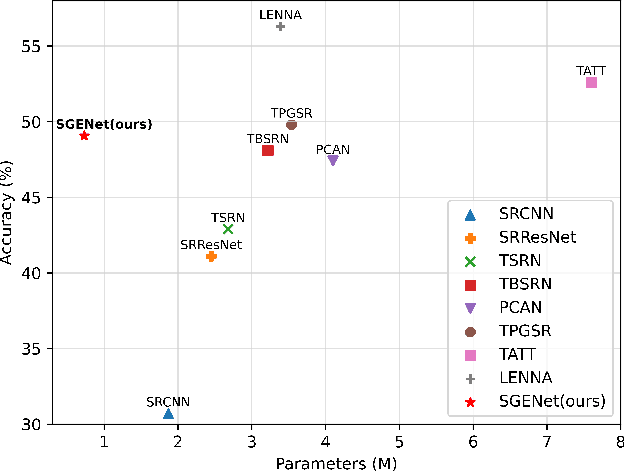
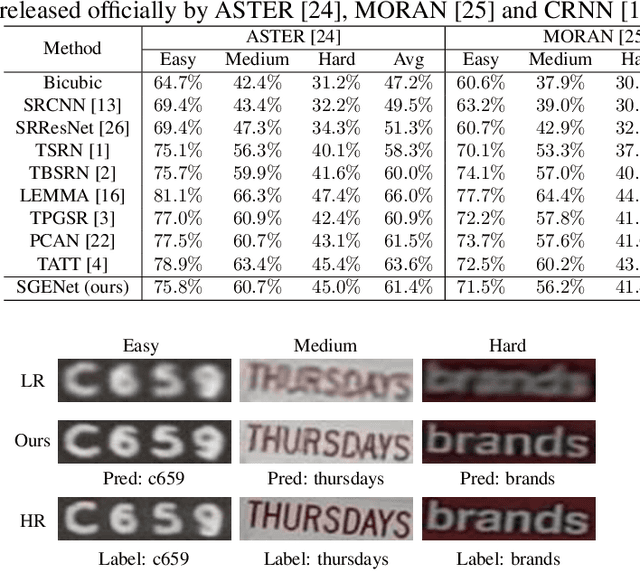
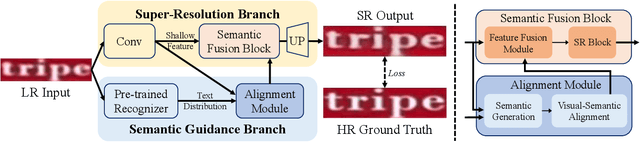
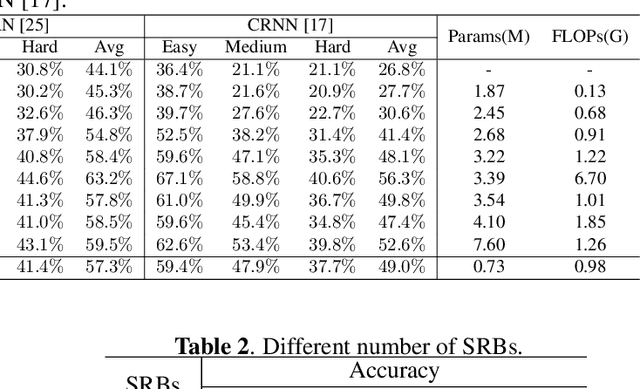
Scene text image super-resolution has significantly improved the accuracy of scene text recognition. However, many existing methods emphasize performance over efficiency and ignore the practical need for lightweight solutions in deployment scenarios. Faced with the issues, our work proposes an efficient framework called SGENet to facilitate deployment on resource-limited platforms. SGENet contains two branches: super-resolution branch and semantic guidance branch. We apply a lightweight pre-trained recognizer as a semantic extractor to enhance the understanding of text information. Meanwhile, we design the visual-semantic alignment module to achieve bidirectional alignment between image features and semantics, resulting in the generation of highquality prior guidance. We conduct extensive experiments on benchmark dataset, and the proposed SGENet achieves excellent performance with fewer computational costs. Code is available at https://github.com/SijieLiu518/SGENet
SatSynth: Augmenting Image-Mask Pairs through Diffusion Models for Aerial Semantic Segmentation
Mar 25, 2024In recent years, semantic segmentation has become a pivotal tool in processing and interpreting satellite imagery. Yet, a prevalent limitation of supervised learning techniques remains the need for extensive manual annotations by experts. In this work, we explore the potential of generative image diffusion to address the scarcity of annotated data in earth observation tasks. The main idea is to learn the joint data manifold of images and labels, leveraging recent advancements in denoising diffusion probabilistic models. To the best of our knowledge, we are the first to generate both images and corresponding masks for satellite segmentation. We find that the obtained pairs not only display high quality in fine-scale features but also ensure a wide sampling diversity. Both aspects are crucial for earth observation data, where semantic classes can vary severely in scale and occurrence frequency. We employ the novel data instances for downstream segmentation, as a form of data augmentation. In our experiments, we provide comparisons to prior works based on discriminative diffusion models or GANs. We demonstrate that integrating generated samples yields significant quantitative improvements for satellite semantic segmentation -- both compared to baselines and when training only on the original data.
ZoDi: Zero-Shot Domain Adaptation with Diffusion-Based Image Transfer
Mar 20, 2024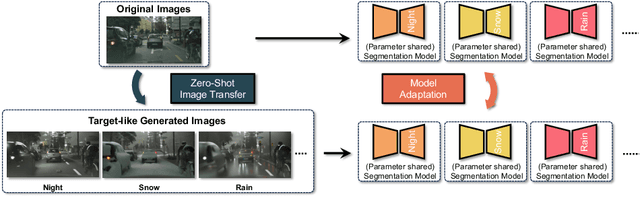
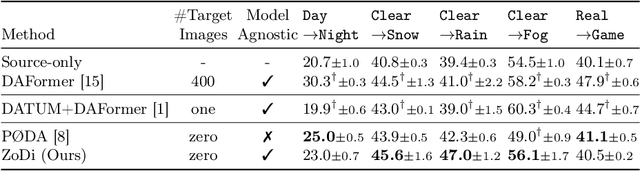
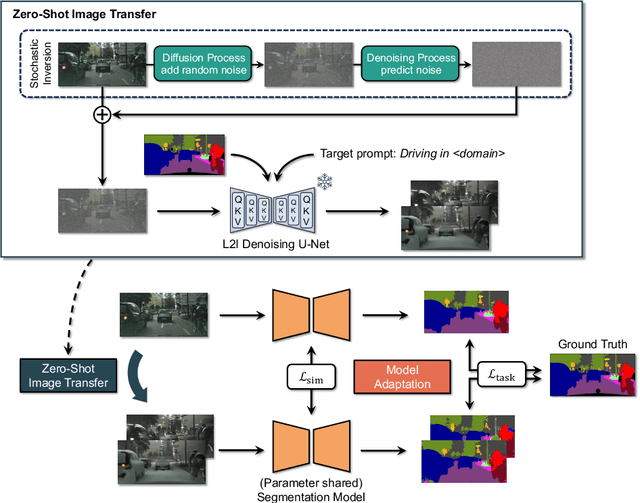
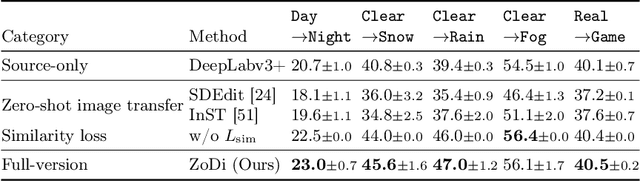
Deep learning models achieve high accuracy in segmentation tasks among others, yet domain shift often degrades the models' performance, which can be critical in real-world scenarios where no target images are available. This paper proposes a zero-shot domain adaptation method based on diffusion models, called ZoDi, which is two-fold by the design: zero-shot image transfer and model adaptation. First, we utilize an off-the-shelf diffusion model to synthesize target-like images by transferring the domain of source images to the target domain. In this we specifically try to maintain the layout and content by utilising layout-to-image diffusion models with stochastic inversion. Secondly, we train the model using both source images and synthesized images with the original segmentation maps while maximizing the feature similarity of images from the two domains to learn domain-robust representations. Through experiments we show benefits of ZoDi in the task of image segmentation over state-of-the-art methods. It is also more applicable than existing CLIP-based methods because it assumes no specific backbone or models, and it enables to estimate the model's performance without target images by inspecting generated images. Our implementation will be publicly available.
Optimizing traffic signs and lights visibility for the teleoperation of autonomous vehicles through ROI compression
Apr 03, 2024Autonomous vehicles are a promising solution to traffic congestion, air pollution, accidents, and wasted time and resources. However, remote driver intervention may be necessary for extreme situations to ensure safe roadside parking or complete remote takeover. In such cases, high-quality real-time video streaming is crucial for practical remote driving. In a preliminary study, we already presented a region of interest (ROI) HEVC data compression where the image was segmented into two categories of ROI and background, allocating more bandwidth to the ROI, yielding an improvement in the visibility of the classes that essential for driving while transmitting the background with lesser quality. However, migrating bandwidth to the large ROI portion of the image doesn't substantially improve the quality of traffic signs and lights. This work categorized the ROIs into either background, weak ROI, or strong ROI. The simulation-based approach uses a photo-realistic driving scenario database created with the Cognata self-driving car simulation platform. We use semantic segmentation to categorize the compression quality of a Coding Tree Unit (CTU) according to each pixel class. A background CTU can contain only sky, trees, vegetation, or building classes. Essentials for remote driving include significant classes such as roads, road marks, cars, and pedestrians. And most importantly, traffic signs and traffic lights. We apply thresholds to decide if the number of pixels in a CTU of a particular category is enough to declare it as belonging to the strong or weak ROI. Then, we allocate the bandwidth according to the CTU categories. Our results show that the perceptual quality of traffic signs, especially textual signs and traffic lights, improves significantly by up to 5.5 dB compared to the only background and foreground partition, while the weak ROI classes at least retain their original quality.
Future-Proofing Class Incremental Learning
Apr 04, 2024Exemplar-Free Class Incremental Learning is a highly challenging setting where replay memory is unavailable. Methods relying on frozen feature extractors have drawn attention recently in this setting due to their impressive performances and lower computational costs. However, those methods are highly dependent on the data used to train the feature extractor and may struggle when an insufficient amount of classes are available during the first incremental step. To overcome this limitation, we propose to use a pre-trained text-to-image diffusion model in order to generate synthetic images of future classes and use them to train the feature extractor. Experiments on the standard benchmarks CIFAR100 and ImageNet-Subset demonstrate that our proposed method can be used to improve state-of-the-art methods for exemplar-free class incremental learning, especially in the most difficult settings where the first incremental step only contains few classes. Moreover, we show that using synthetic samples of future classes achieves higher performance than using real data from different classes, paving the way for better and less costly pre-training methods for incremental learning.
AGL-NET: Aerial-Ground Cross-Modal Global Localization with Varying Scales
Apr 04, 2024We present AGL-NET, a novel learning-based method for global localization using LiDAR point clouds and satellite maps. AGL-NET tackles two critical challenges: bridging the representation gap between image and points modalities for robust feature matching, and handling inherent scale discrepancies between global view and local view. To address these challenges, AGL-NET leverages a unified network architecture with a novel two-stage matching design. The first stage extracts informative neural features directly from raw sensor data and performs initial feature matching. The second stage refines this matching process by extracting informative skeleton features and incorporating a novel scale alignment step to rectify scale variations between LiDAR and map data. Furthermore, a novel scale and skeleton loss function guides the network toward learning scale-invariant feature representations, eliminating the need for pre-processing satellite maps. This significantly improves real-world applicability in scenarios with unknown map scales. To facilitate rigorous performance evaluation, we introduce a meticulously designed dataset within the CARLA simulator specifically tailored for metric localization training and assessment. The code and dataset will be made publicly available.
DiffDet4SAR: Diffusion-based Aircraft Target Detection Network for SAR Images
Apr 04, 2024Aircraft target detection in SAR images is a challenging task due to the discrete scattering points and severe background clutter interference. Currently, methods with convolution-based or transformer-based paradigms cannot adequately address these issues. In this letter, we explore diffusion models for SAR image aircraft target detection for the first time and propose a novel \underline{Diff}usion-based aircraft target \underline{Det}ection network \underline{for} \underline{SAR} images (DiffDet4SAR). Specifically, the proposed DiffDet4SAR yields two main advantages for SAR aircraft target detection: 1) DiffDet4SAR maps the SAR aircraft target detection task to a denoising diffusion process of bounding boxes without heuristic anchor size selection, effectively enabling large variations in aircraft sizes to be accommodated; and 2) the dedicatedly designed Scattering Feature Enhancement (SFE) module further reduces the clutter intensity and enhances the target saliency during inference. Extensive experimental results on the SAR-AIRcraft-1.0 dataset show that the proposed DiffDet4SAR achieves 88.4\% mAP$_{50}$, outperforming the state-of-the-art methods by 6\%. Code is availabel at \href{https://github.com/JoyeZLearning/DiffDet4SAR}.
Moderating Illicit Online Image Promotion for Unsafe User-Generated Content Games Using Large Vision-Language Models
Mar 27, 2024Online user-generated content games (UGCGs) are increasingly popular among children and adolescents for social interaction and more creative online entertainment. However, they pose a heightened risk of exposure to explicit content, raising growing concerns for the online safety of children and adolescents. Despite these concerns, few studies have addressed the issue of illicit image-based promotions of unsafe UGCGs on social media, which can inadvertently attract young users. This challenge arises from the difficulty of obtaining comprehensive training data for UGCG images and the unique nature of these images, which differ from traditional unsafe content. In this work, we take the first step towards studying the threat of illicit promotions of unsafe UGCGs. We collect a real-world dataset comprising 2,924 images that display diverse sexually explicit and violent content used to promote UGCGs by their game creators. Our in-depth studies reveal a new understanding of this problem and the urgent need for automatically flagging illicit UGCG promotions. We additionally create a cutting-edge system, UGCG-Guard, designed to aid social media platforms in effectively identifying images used for illicit UGCG promotions. This system leverages recently introduced large vision-language models (VLMs) and employs a novel conditional prompting strategy for zero-shot domain adaptation, along with chain-of-thought (CoT) reasoning for contextual identification. UGCG-Guard achieves outstanding results, with an accuracy rate of 94% in detecting these images used for the illicit promotion of such games in real-world scenarios.
Distilling Datasets Into Less Than One Image
Mar 18, 2024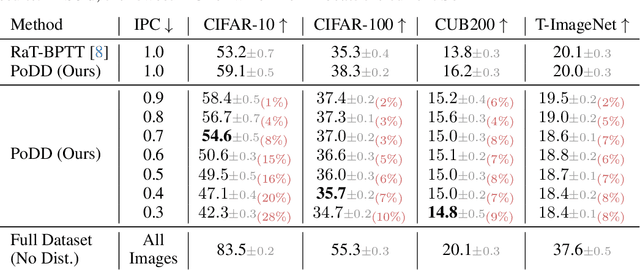
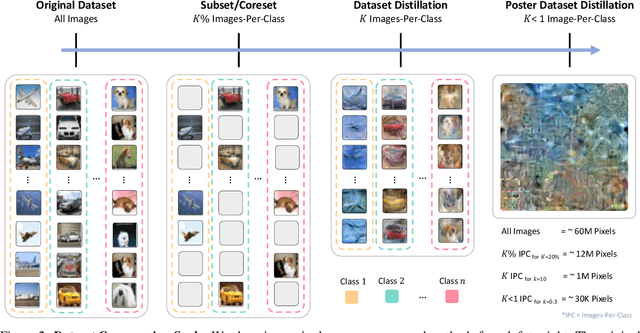
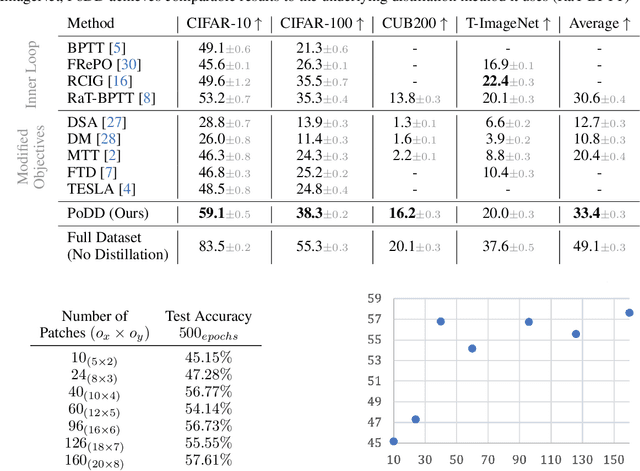
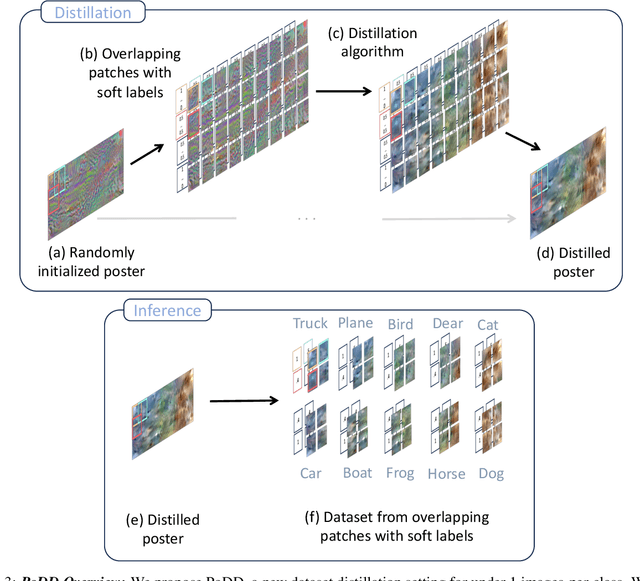
Dataset distillation aims to compress a dataset into a much smaller one so that a model trained on the distilled dataset achieves high accuracy. Current methods frame this as maximizing the distilled classification accuracy for a budget of K distilled images-per-class, where K is a positive integer. In this paper, we push the boundaries of dataset distillation, compressing the dataset into less than an image-per-class. It is important to realize that the meaningful quantity is not the number of distilled images-per-class but the number of distilled pixels-per-dataset. We therefore, propose Poster Dataset Distillation (PoDD), a new approach that distills the entire original dataset into a single poster. The poster approach motivates new technical solutions for creating training images and learnable labels. Our method can achieve comparable or better performance with less than an image-per-class compared to existing methods that use one image-per-class. Specifically, our method establishes a new state-of-the-art performance on CIFAR-10, CIFAR-100, and CUB200 using as little as 0.3 images-per-class.
Deep-learning Segmentation of Small Volumes in CT images for Radiotherapy Treatment Planning
Apr 05, 2024Our understanding of organs at risk is progressing to include physical small tissues such as coronary arteries and the radiosensitivities of many small organs and tissues are high. Therefore, the accurate segmentation of small volumes in external radiotherapy is crucial to protect them from over-irradiation. Moreover, with the development of the particle therapy and on-board imaging, the treatment becomes more accurate and precise. The purpose of this work is to optimize organ segmentation algorithms for small organs. We used 50 three-dimensional (3-D) computed tomography (CT) head and neck images from StructSeg2019 challenge to develop a general-purpose V-Net model to segment 20 organs in the head and neck region. We applied specific strategies to improve the segmentation accuracy of the small volumes in this anatomical region, i.e., the lens of the eye. Then, we used 17 additional head images from OSF healthcare to validate the robustness of the V Net model optimized for small-volume segmentation. With the study of the StructSeg2019 images, we found that the optimization of the image normalization range and classification threshold yielded a segmentation improvement of the lens of the eye of approximately 50%, compared to the use of the V-Net not optimized for small volumes. We used the optimized model to segment 17 images acquired using heterogeneous protocols. We obtained comparable Dice coefficient values for the clinical and StructSeg2019 images (0.61 plus/minus 0.07 and 0.58 plus/minus 0.10 for the left and right lens of the eye, respectively)