 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Staging E-Commerce Products for Online Advertising using Retrieval Assisted Image Generation
Jul 28, 2023

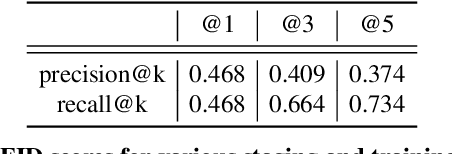
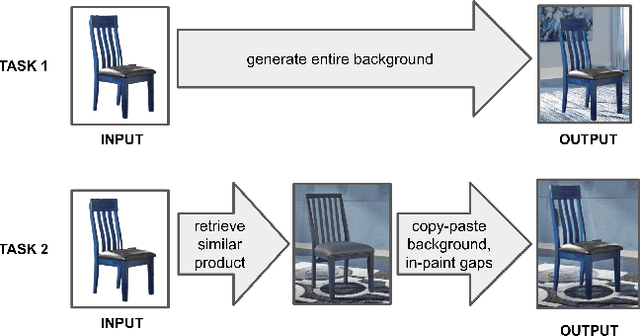

Online ads showing e-commerce products typically rely on the product images in a catalog sent to the advertising platform by an e-commerce platform. In the broader ads industry such ads are called dynamic product ads (DPA). It is common for DPA catalogs to be in the scale of millions (corresponding to the scale of products which can be bought from the e-commerce platform). However, not all product images in the catalog may be appealing when directly re-purposed as an ad image, and this may lead to lower click-through rates (CTRs). In particular, products just placed against a solid background may not be as enticing and realistic as a product staged in a natural environment. To address such shortcomings of DPA images at scale, we propose a generative adversarial network (GAN) based approach to generate staged backgrounds for un-staged product images. Generating the entire staged background is a challenging task susceptible to hallucinations. To get around this, we introduce a simpler approach called copy-paste staging using retrieval assisted GANs. In copy paste staging, we first retrieve (from the catalog) staged products similar to the un-staged input product, and then copy-paste the background of the retrieved product in the input image. A GAN based in-painting model is used to fill the holes left after this copy-paste operation. We show the efficacy of our copy-paste staging method via offline metrics, and human evaluation. In addition, we show how our staging approach can enable animations of moving products leading to a video ad from a product image.
Multi-interactive Feature Learning and a Full-time Multi-modality Benchmark for Image Fusion and Segmentation
Aug 04, 2023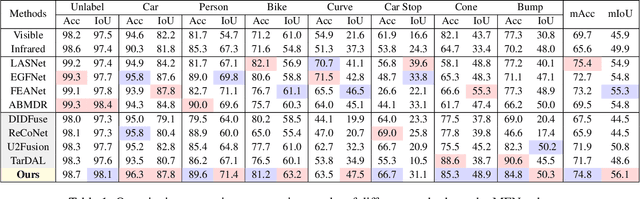
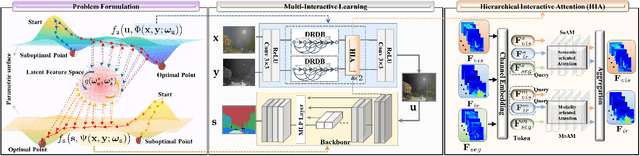
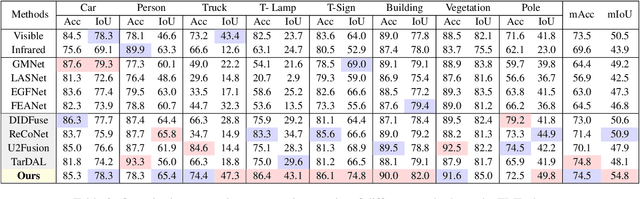
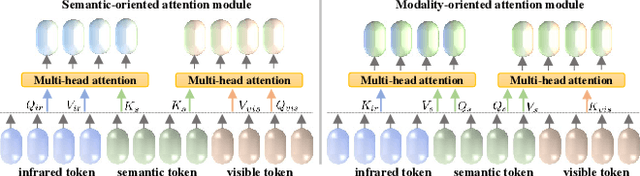
Multi-modality image fusion and segmentation play a vital role in autonomous driving and robotic operation. Early efforts focus on boosting the performance for only one task, \emph{e.g.,} fusion or segmentation, making it hard to reach~`Best of Both Worlds'. To overcome this issue, in this paper, we propose a \textbf{M}ulti-\textbf{i}nteractive \textbf{F}eature learning architecture for image fusion and \textbf{Seg}mentation, namely SegMiF, and exploit dual-task correlation to promote the performance of both tasks. The SegMiF is of a cascade structure, containing a fusion sub-network and a commonly used segmentation sub-network. By slickly bridging intermediate features between two components, the knowledge learned from the segmentation task can effectively assist the fusion task. Also, the benefited fusion network supports the segmentation one to perform more pretentiously. Besides, a hierarchical interactive attention block is established to ensure fine-grained mapping of all the vital information between two tasks, so that the modality/semantic features can be fully mutual-interactive. In addition, a dynamic weight factor is introduced to automatically adjust the corresponding weights of each task, which can balance the interactive feature correspondence and break through the limitation of laborious tuning. Furthermore, we construct a smart multi-wave binocular imaging system and collect a full-time multi-modality benchmark with 15 annotated pixel-level categories for image fusion and segmentation. Extensive experiments on several public datasets and our benchmark demonstrate that the proposed method outputs visually appealing fused images and perform averagely $7.66\%$ higher segmentation mIoU in the real-world scene than the state-of-the-art approaches. The source code and benchmark are available at \url{https://github.com/JinyuanLiu-CV/SegMiF}.
DARC: Distribution-Aware Re-Coloring Model for Generalizable Nucleus Segmentation
Sep 01, 2023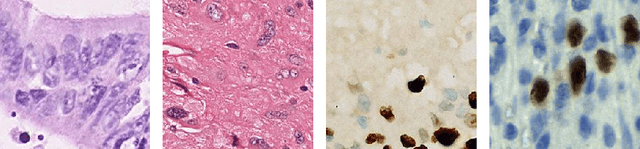
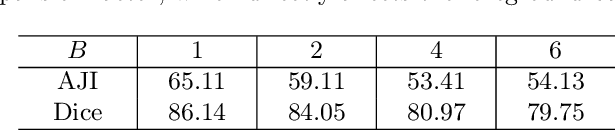
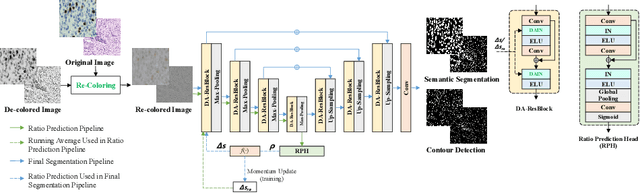
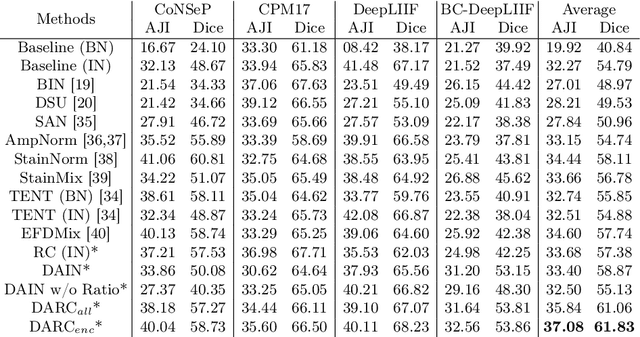
Nucleus segmentation is usually the first step in pathological image analysis tasks. Generalizable nucleus segmentation refers to the problem of training a segmentation model that is robust to domain gaps between the source and target domains. The domain gaps are usually believed to be caused by the varied image acquisition conditions, e.g., different scanners, tissues, or staining protocols. In this paper, we argue that domain gaps can also be caused by different foreground (nucleus)-background ratios, as this ratio significantly affects feature statistics that are critical to normalization layers. We propose a Distribution-Aware Re-Coloring (DARC) model that handles the above challenges from two perspectives. First, we introduce a re-coloring method that relieves dramatic image color variations between different domains. Second, we propose a new instance normalization method that is robust to the variation in foreground-background ratios. We evaluate the proposed methods on two H$\&$E stained image datasets, named CoNSeP and CPM17, and two IHC stained image datasets, called DeepLIIF and BC-DeepLIIF. Extensive experimental results justify the effectiveness of our proposed DARC model. Codes are available at \url{https://github.com/csccsccsccsc/DARC
Efficient Graphics Representation with Differentiable Indirection
Sep 12, 2023We introduce differentiable indirection -- a novel learned primitive that employs differentiable multi-scale lookup tables as an effective substitute for traditional compute and data operations across the graphics pipeline. We demonstrate its flexibility on a number of graphics tasks, i.e., geometric and image representation, texture mapping, shading, and radiance field representation. In all cases, differentiable indirection seamlessly integrates into existing architectures, trains rapidly, and yields both versatile and efficient results.
* Project website: https://sayan1an.github.io/din.html
Probabilistic Modeling of Inter- and Intra-observer Variability in Medical Image Segmentation
Jul 21, 2023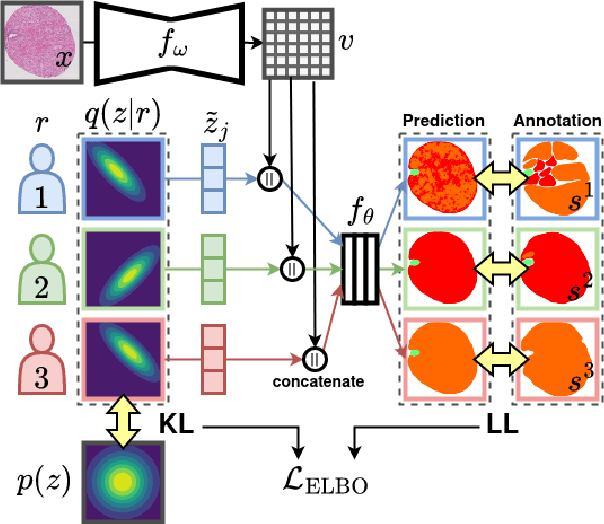
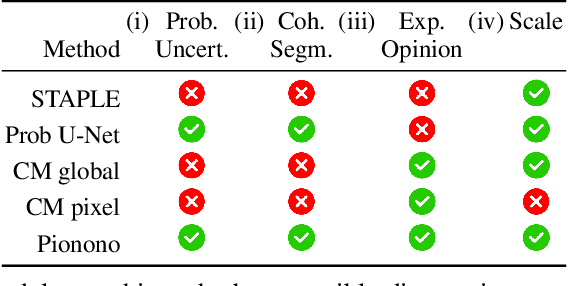

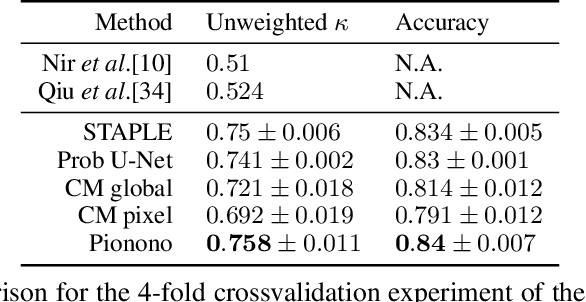
Medical image segmentation is a challenging task, particularly due to inter- and intra-observer variability, even between medical experts. In this paper, we propose a novel model, called Probabilistic Inter-Observer and iNtra-Observer variation NetwOrk (Pionono). It captures the labeling behavior of each rater with a multidimensional probability distribution and integrates this information with the feature maps of the image to produce probabilistic segmentation predictions. The model is optimized by variational inference and can be trained end-to-end. It outperforms state-of-the-art models such as STAPLE, Probabilistic U-Net, and models based on confusion matrices. Additionally, Pionono predicts multiple coherent segmentation maps that mimic the rater's expert opinion, which provides additional valuable information for the diagnostic process. Experiments on real-world cancer segmentation datasets demonstrate the high accuracy and efficiency of Pionono, making it a powerful tool for medical image analysis.
3Deformer: A Common Framework for Image-Guided Mesh Deformation
Jul 19, 2023We propose 3Deformer, a general-purpose framework for interactive 3D shape editing. Given a source 3D mesh with semantic materials, and a user-specified semantic image, 3Deformer can accurately edit the source mesh following the shape guidance of the semantic image, while preserving the source topology as rigid as possible. Recent studies of 3D shape editing mostly focus on learning neural networks to predict 3D shapes, which requires high-cost 3D training datasets and is limited to handling objects involved in the datasets. Unlike these studies, our 3Deformer is a non-training and common framework, which only requires supervision of readily-available semantic images, and is compatible with editing various objects unlimited by datasets. In 3Deformer, the source mesh is deformed utilizing the differentiable renderer technique, according to the correspondences between semantic images and mesh materials. However, guiding complex 3D shapes with a simple 2D image incurs extra challenges, that is, the deform accuracy, surface smoothness, geometric rigidity, and global synchronization of the edited mesh should be guaranteed. To address these challenges, we propose a hierarchical optimization architecture to balance the global and local shape features, and propose further various strategies and losses to improve properties of accuracy, smoothness, rigidity, and so on. Extensive experiments show that our 3Deformer is able to produce impressive results and reaches the state-of-the-art level.
A Unified Scheme of ResNet and Softmax
Sep 23, 2023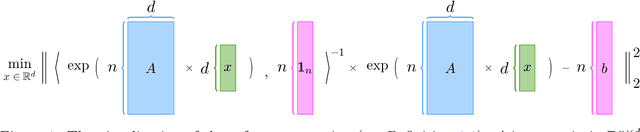
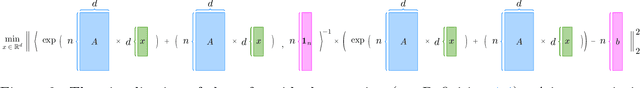
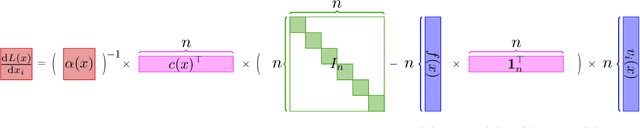

Large language models (LLMs) have brought significant changes to human society. Softmax regression and residual neural networks (ResNet) are two important techniques in deep learning: they not only serve as significant theoretical components supporting the functionality of LLMs but also are related to many other machine learning and theoretical computer science fields, including but not limited to image classification, object detection, semantic segmentation, and tensors. Previous research works studied these two concepts separately. In this paper, we provide a theoretical analysis of the regression problem: $\| \langle \exp(Ax) + A x , {\bf 1}_n \rangle^{-1} ( \exp(Ax) + Ax ) - b \|_2^2$, where $A$ is a matrix in $\mathbb{R}^{n \times d}$, $b$ is a vector in $\mathbb{R}^n$, and ${\bf 1}_n$ is the $n$-dimensional vector whose entries are all $1$. This regression problem is a unified scheme that combines softmax regression and ResNet, which has never been done before. We derive the gradient, Hessian, and Lipschitz properties of the loss function. The Hessian is shown to be positive semidefinite, and its structure is characterized as the sum of a low-rank matrix and a diagonal matrix. This enables an efficient approximate Newton method. As a result, this unified scheme helps to connect two previously thought unrelated fields and provides novel insight into loss landscape and optimization for emerging over-parameterized neural networks, which is meaningful for future research in deep learning models.
Blind Image Quality Assessment Using Multi-Stream Architecture with Spatial and Channel Attention
Jul 19, 2023
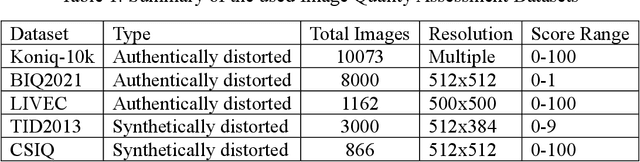
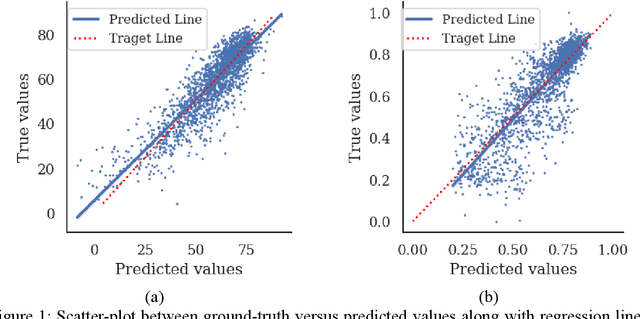
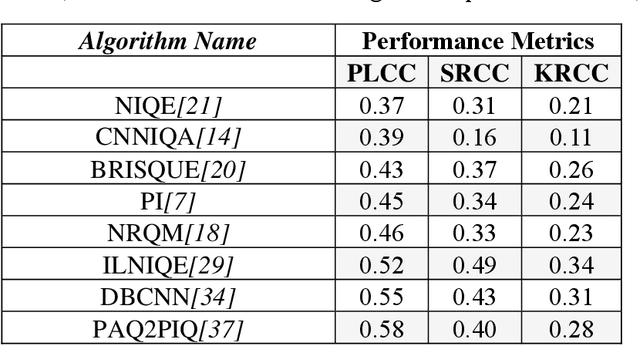
BIQA (Blind Image Quality Assessment) is an important field of study that evaluates images automatically. Although significant progress has been made, blind image quality assessment remains a difficult task since images vary in content and distortions. Most algorithms generate quality without emphasizing the important region of interest. In order to solve this, a multi-stream spatial and channel attention-based algorithm is being proposed. This algorithm generates more accurate predictions with a high correlation to human perceptual assessment by combining hybrid features from two different backbones, followed by spatial and channel attention to provide high weights to the region of interest. Four legacy image quality assessment datasets are used to validate the effectiveness of our proposed approach. Authentic and synthetic distortion image databases are used to demonstrate the effectiveness of the proposed method, and we show that it has excellent generalization properties with a particular focus on the perceptual foreground information.
Speech2Lip: High-fidelity Speech to Lip Generation by Learning from a Short Video
Sep 09, 2023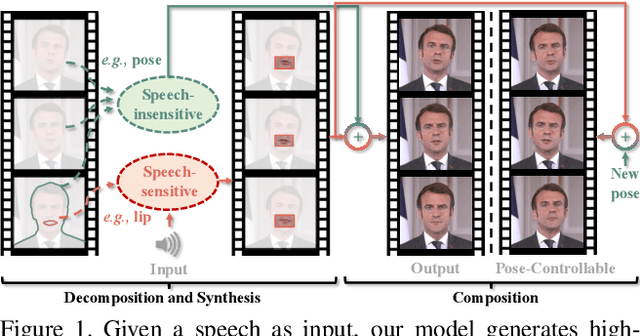
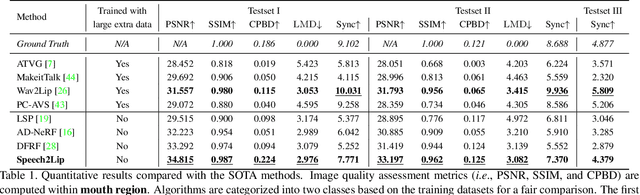

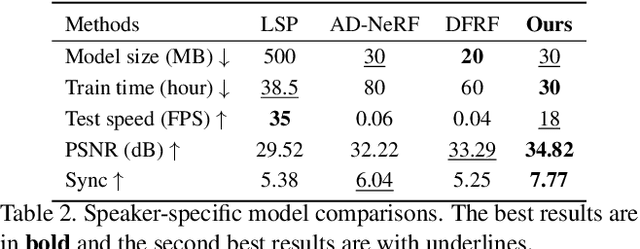
Synthesizing realistic videos according to a given speech is still an open challenge. Previous works have been plagued by issues such as inaccurate lip shape generation and poor image quality. The key reason is that only motions and appearances on limited facial areas (e.g., lip area) are mainly driven by the input speech. Therefore, directly learning a mapping function from speech to the entire head image is prone to ambiguity, particularly when using a short video for training. We thus propose a decomposition-synthesis-composition framework named Speech to Lip (Speech2Lip) that disentangles speech-sensitive and speech-insensitive motion/appearance to facilitate effective learning from limited training data, resulting in the generation of natural-looking videos. First, given a fixed head pose (i.e., canonical space), we present a speech-driven implicit model for lip image generation which concentrates on learning speech-sensitive motion and appearance. Next, to model the major speech-insensitive motion (i.e., head movement), we introduce a geometry-aware mutual explicit mapping (GAMEM) module that establishes geometric mappings between different head poses. This allows us to paste generated lip images at the canonical space onto head images with arbitrary poses and synthesize talking videos with natural head movements. In addition, a Blend-Net and a contrastive sync loss are introduced to enhance the overall synthesis performance. Quantitative and qualitative results on three benchmarks demonstrate that our model can be trained by a video of just a few minutes in length and achieve state-of-the-art performance in both visual quality and speech-visual synchronization. Code: https://github.com/CVMI-Lab/Speech2Lip.
Neural Image Compression: Generalization, Robustness, and Spectral Biases
Jul 17, 2023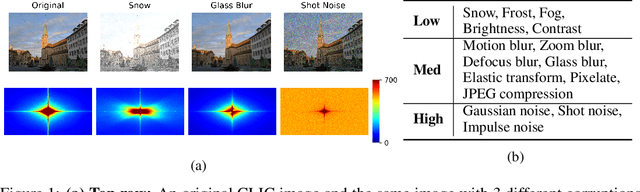
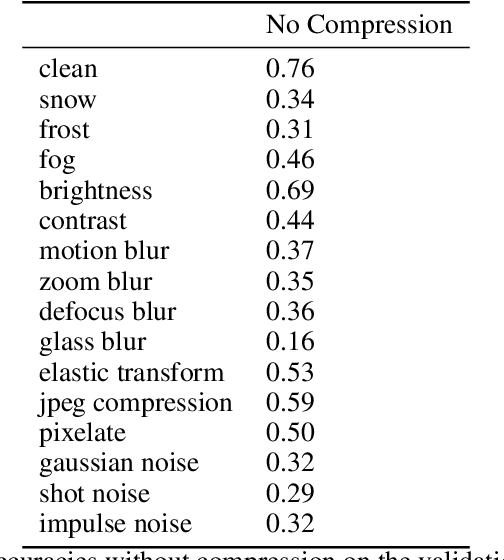
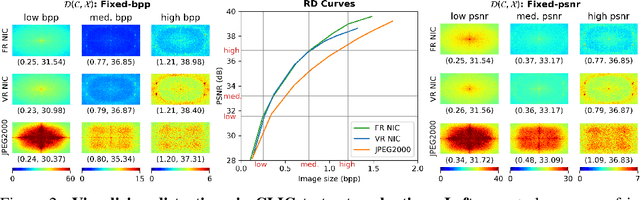
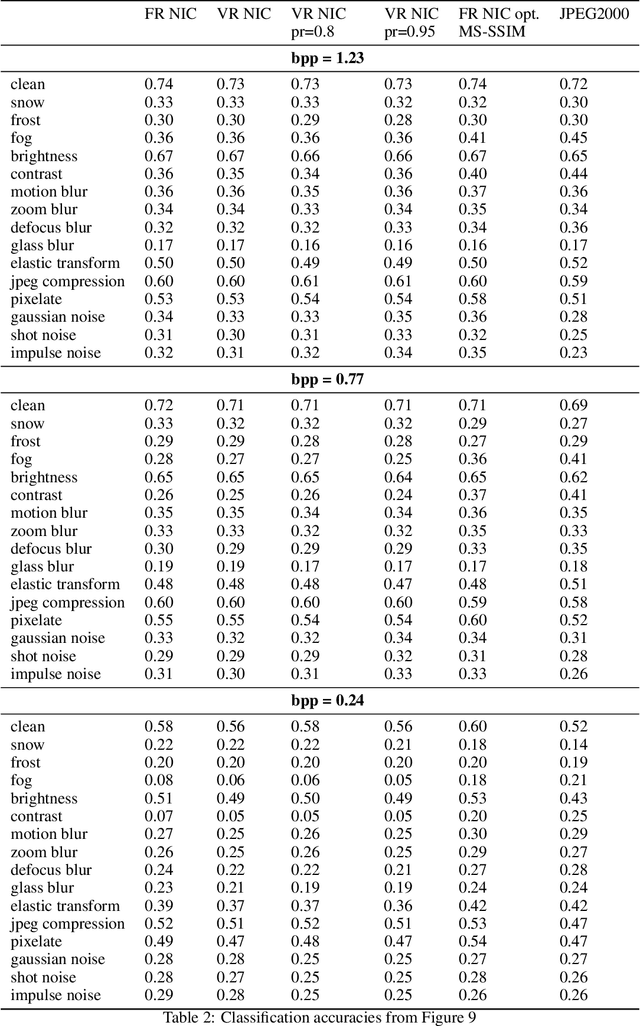
Recent neural image compression (NIC) advances have produced models which are starting to outperform traditional codecs. While this has led to growing excitement about using NIC in real-world applications, the successful adoption of any machine learning system in the wild requires it to generalize (and be robust) to unseen distribution shifts at deployment. Unfortunately, current research lacks comprehensive datasets and informative tools to evaluate and understand NIC performance in real-world settings. To bridge this crucial gap, first, this paper presents a comprehensive benchmark suite to evaluate the out-of-distribution (OOD) performance of image compression methods. Specifically, we provide CLIC-C and Kodak-C by introducing 15 corruptions to popular CLIC and Kodak benchmarks. Next, we propose spectrally inspired inspection tools to gain deeper insight into errors introduced by image compression methods as well as their OOD performance. We then carry out a detailed performance comparison of a classical codec with several NIC variants, revealing intriguing findings that challenge our current understanding of the strengths and limitations of NIC. Finally, we corroborate our empirical findings with theoretical analysis, providing an in-depth view of the OOD performance of NIC and its dependence on the spectral properties of the data. Our benchmarks, spectral inspection tools, and findings provide a crucial bridge to the real-world adoption of NIC. We hope that our work will propel future efforts in designing robust and generalizable NIC methods. Code and data will be made available at https://github.com/klieberman/ood_nic.