 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Direct Iterative Reconstruction of Multiple Basis Material Images in Photon-counting Spectral CT
Sep 28, 2023
In this work, we perform direct material reconstruction from spectral CT data using a model based iterative reconstruction (MBIR) approach. Material concentrations are measured in volume fractions, whose total is constrained by a maximum of unity. A phantom containing a combination of 4 basis materials (water, iodine, gadolinium, calcium) was scanned using a photon-counting detector. Iodine and gadolinium were chosen because of their common use as contrast agents in CT imaging. Scan data was binned into 5 energy (keV) levels. Each energy bin in a calibration scan was reconstructed, allowing the linear attenuation coefficient of each material for every energy to be estimated by a least-squares fit to ground truth in the image domain. The resulting $5\times 4$ matrix, for $5$ energies and $4$ materials, is incorporated into the forward model in direct reconstruction of the $4$ basis material images with spatial and/or inter-material regularization. In reconstruction from a subsequent low-concentration scan, volume fractions within regions of interest (ROIs) are found to be close to the ground truth. This work is meant to lay the foundation for further work with phantoms including spatially coincident mixtures of contrast materials and/or contrast agents in widely varying concentrations, molecular imaging from animal scans, and eventually clinical applications.
Multisource Holography
Sep 19, 2023
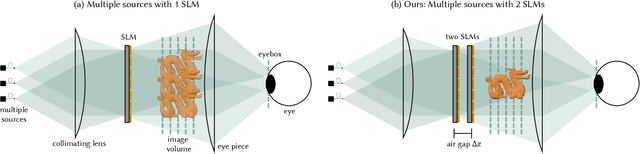
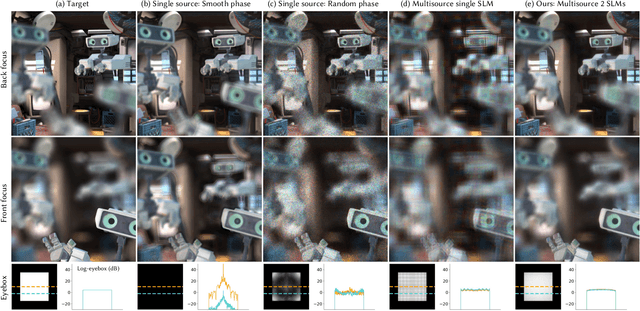
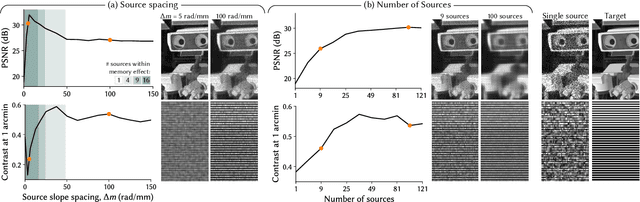
Holographic displays promise several benefits including high quality 3D imagery, accurate accommodation cues, and compact form-factors. However, holography relies on coherent illumination which can create undesirable speckle noise in the final image. Although smooth phase holograms can be speckle-free, their non-uniform eyebox makes them impractical, and speckle mitigation with partially coherent sources also reduces resolution. Averaging sequential frames for speckle reduction requires high speed modulators and consumes temporal bandwidth that may be needed elsewhere in the system. In this work, we propose multisource holography, a novel architecture that uses an array of sources to suppress speckle in a single frame without sacrificing resolution. By using two spatial light modulators, arranged sequentially, each source in the array can be controlled almost independently to create a version of the target content with different speckle. Speckle is then suppressed when the contributions from the multiple sources are averaged at the image plane. We introduce an algorithm to calculate multisource holograms, analyze the design space, and demonstrate up to a 10 dB increase in peak signal-to-noise ratio compared to an equivalent single source system. Finally, we validate the concept with a benchtop experimental prototype by producing both 2D images and focal stacks with natural defocus cues.
Learning End-to-End Channel Coding with Diffusion Models
Sep 19, 2023The training of neural encoders via deep learning necessitates a differentiable channel model due to the backpropagation algorithm. This requirement can be sidestepped by approximating either the channel distribution or its gradient through pilot signals in real-world scenarios. The initial approach draws upon the latest advancements in image generation, utilizing generative adversarial networks (GANs) or their enhanced variants to generate channel distributions. In this paper, we address this channel approximation challenge with diffusion models, which have demonstrated high sample quality in image generation. We offer an end-to-end channel coding framework underpinned by diffusion models and propose an efficient training algorithm. Our simulations with various channel models establish that our diffusion models learn the channel distribution accurately, thereby achieving near-optimal end-to-end symbol error rates (SERs). We also note a significant advantage of diffusion models: A robust generalization capability in high signal-to-noise ratio regions, in contrast to GAN variants that suffer from error floor. Furthermore, we examine the trade-off between sample quality and sampling speed, when an accelerated sampling algorithm is deployed, and investigate the effect of the noise scheduling on this trade-off. With an apt choice of noise scheduling, sampling time can be significantly reduced with a minor increase in SER.
CMUNeXt: An Efficient Medical Image Segmentation Network based on Large Kernel and Skip Fusion
Aug 02, 2023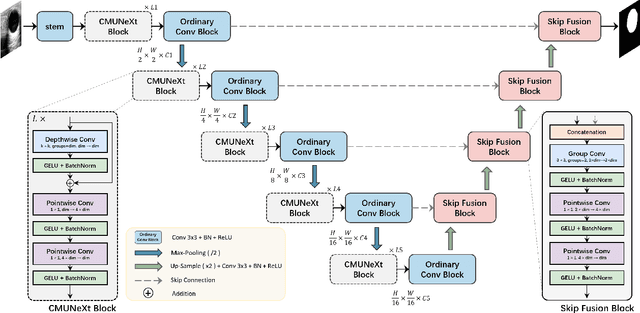
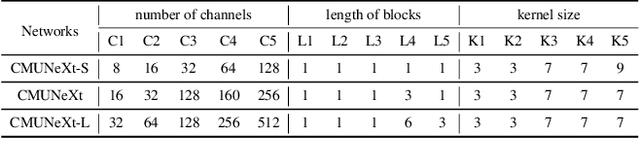
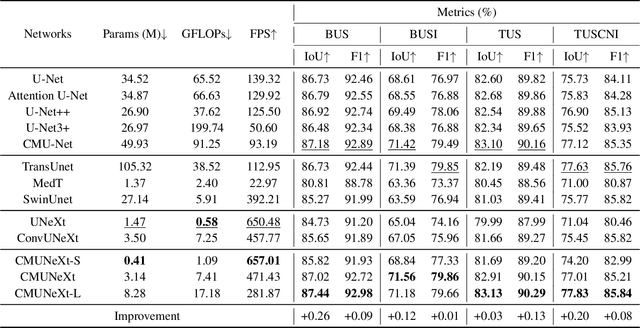
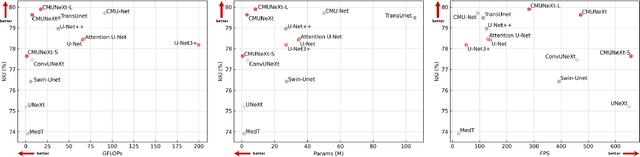
The U-shaped architecture has emerged as a crucial paradigm in the design of medical image segmentation networks. However, due to the inherent local limitations of convolution, a fully convolutional segmentation network with U-shaped architecture struggles to effectively extract global context information, which is vital for the precise localization of lesions. While hybrid architectures combining CNNs and Transformers can address these issues, their application in real medical scenarios is limited due to the computational resource constraints imposed by the environment and edge devices. In addition, the convolutional inductive bias in lightweight networks adeptly fits the scarce medical data, which is lacking in the Transformer based network. In order to extract global context information while taking advantage of the inductive bias, we propose CMUNeXt, an efficient fully convolutional lightweight medical image segmentation network, which enables fast and accurate auxiliary diagnosis in real scene scenarios. CMUNeXt leverages large kernel and inverted bottleneck design to thoroughly mix distant spatial and location information, efficiently extracting global context information. We also introduce the Skip-Fusion block, designed to enable smooth skip-connections and ensure ample feature fusion. Experimental results on multiple medical image datasets demonstrate that CMUNeXt outperforms existing heavyweight and lightweight medical image segmentation networks in terms of segmentation performance, while offering a faster inference speed, lighter weights, and a reduced computational cost. The code is available at https://github.com/FengheTan9/CMUNeXt.
Let's ViCE! Mimicking Human Cognitive Behavior in Image Generation Evaluation
Jul 19, 2023
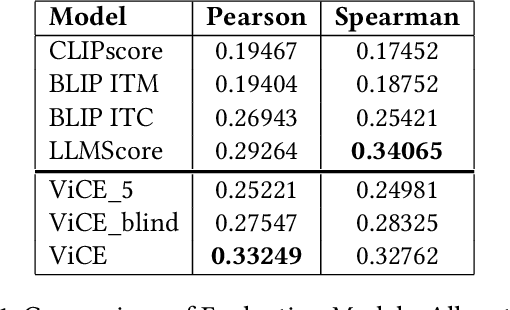
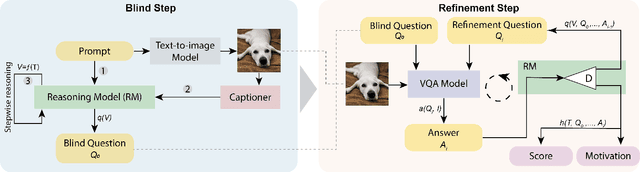
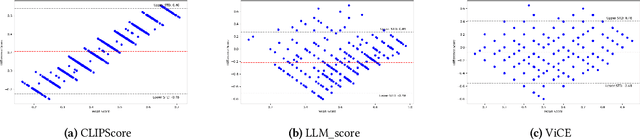
Research in Image Generation has recently made significant progress, particularly boosted by the introduction of Vision-Language models which are able to produce high-quality visual content based on textual inputs. Despite ongoing advancements in terms of generation quality and realism, no methodical frameworks have been defined yet to quantitatively measure the quality of the generated content and the adherence with the prompted requests: so far, only human-based evaluations have been adopted for quality satisfaction and for comparing different generative methods. We introduce a novel automated method for Visual Concept Evaluation (ViCE), i.e. to assess consistency between a generated/edited image and the corresponding prompt/instructions, with a process inspired by the human cognitive behaviour. ViCE combines the strengths of Large Language Models (LLMs) and Visual Question Answering (VQA) into a unified pipeline, aiming to replicate the human cognitive process in quality assessment. This method outlines visual concepts, formulates image-specific verification questions, utilizes the Q&A system to investigate the image, and scores the combined outcome. Although this brave new hypothesis of mimicking humans in the image evaluation process is in its preliminary assessment stage, results are promising and open the door to a new form of automatic evaluation which could have significant impact as the image generation or the image target editing tasks become more and more sophisticated.
Learning Parallax for Stereo Event-based Motion Deblurring
Sep 18, 2023Due to the extremely low latency, events have been recently exploited to supplement lost information for motion deblurring. Existing approaches largely rely on the perfect pixel-wise alignment between intensity images and events, which is not always fulfilled in the real world. To tackle this problem, we propose a novel coarse-to-fine framework, named NETwork of Event-based motion Deblurring with STereo event and intensity cameras (St-EDNet), to recover high-quality images directly from the misaligned inputs, consisting of a single blurry image and the concurrent event streams. Specifically, the coarse spatial alignment of the blurry image and the event streams is first implemented with a cross-modal stereo matching module without the need for ground-truth depths. Then, a dual-feature embedding architecture is proposed to gradually build the fine bidirectional association of the coarsely aligned data and reconstruct the sequence of the latent sharp images. Furthermore, we build a new dataset with STereo Event and Intensity Cameras (StEIC), containing real-world events, intensity images, and dense disparity maps. Experiments on real-world datasets demonstrate the superiority of the proposed network over state-of-the-art methods.
An Empirical Study of Scaling Instruct-Tuned Large Multimodal Models
Sep 18, 2023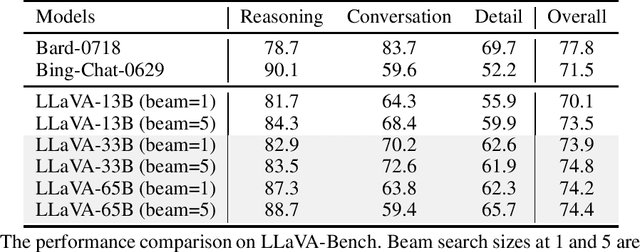
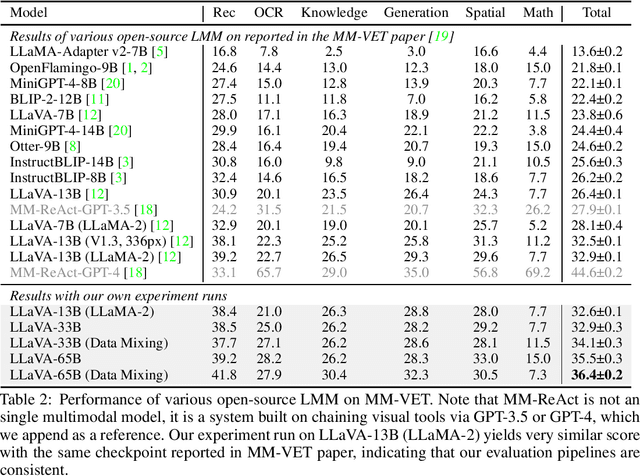
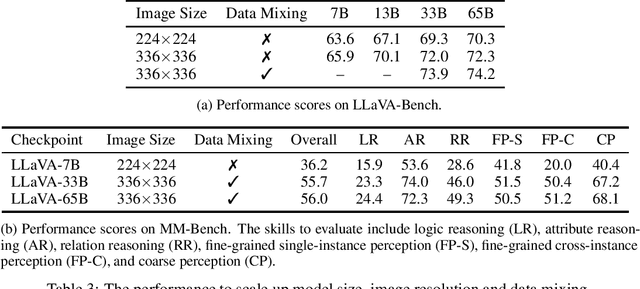

Visual instruction tuning has recently shown encouraging progress with open-source large multimodal models (LMM) such as LLaVA and MiniGPT-4. However, most existing studies of open-source LMM are performed using models with 13B parameters or smaller. In this paper we present an empirical study of scaling LLaVA up to 33B and 65B/70B, and share our findings from our explorations in image resolution, data mixing and parameter-efficient training methods such as LoRA/QLoRA. These are evaluated by their impact on the multi-modal and language capabilities when completing real-world tasks in the wild. We find that scaling LMM consistently enhances model performance and improves language capabilities, and performance of LoRA/QLoRA tuning of LMM are comparable to the performance of full-model fine-tuning. Additionally, the study highlights the importance of higher image resolutions and mixing multimodal-language data to improve LMM performance, and visual instruction tuning can sometimes improve LMM's pure language capability. We hope that this study makes state-of-the-art LMM research at a larger scale more accessible, thus helping establish stronger baselines for future research. Code and checkpoints will be made public.
Walking fingerprinting
Sep 18, 2023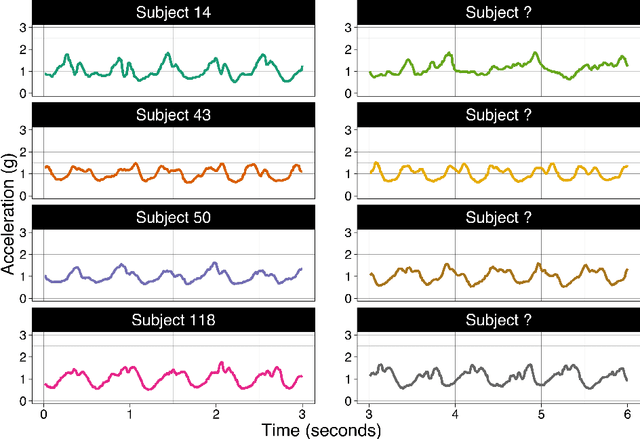
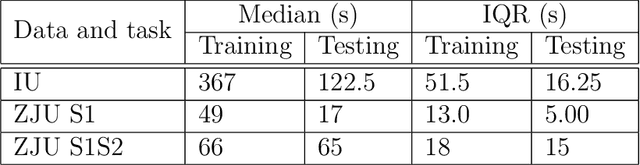
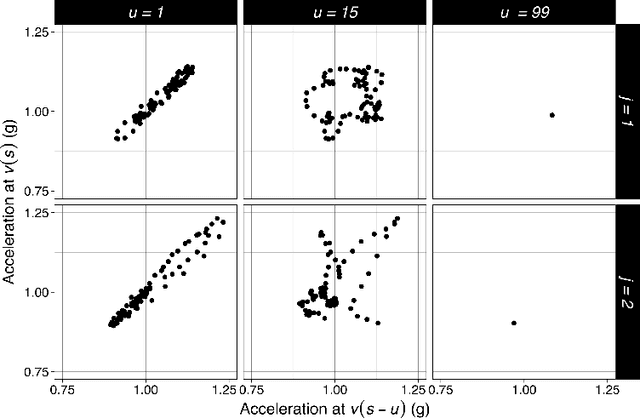
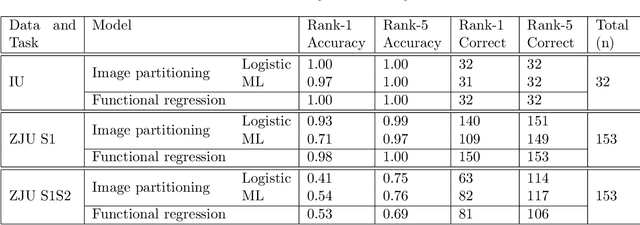
We consider the problem of predicting an individual's identity from accelerometry data collected during walking. In a previous paper we introduced an approach that transforms the accelerometry time series into an image by constructing its complete empirical autocorrelation distribution. Predictors derived by partitioning this image into grid cells were used in logistic regression to predict individuals. Here we: (1) implement machine learning methods for prediction using the grid cell-derived predictors; (2) derive inferential methods to screen for the most predictive grid cells; and (3) develop a novel multivariate functional regression model that avoids partitioning of the predictor space into cells. Prediction methods are compared on two open source data sets: (1) accelerometry data collected from $32$ individuals walking on a $1.06$ kilometer path; and (2) accelerometry data collected from six repetitions of walking on a $20$ meter path on two separate occasions at least one week apart for $153$ study participants. In the $32$-individual study, all methods achieve at least $95$% rank-1 accuracy, while in the $153$-individual study, accuracy varies from $41$% to $98$%, depending on the method and prediction task. Methods provide insights into why some individuals are easier to predict than others.
A Foundation LAnguage-Image model of the Retina (FLAIR): Encoding expert knowledge in text supervision
Aug 15, 2023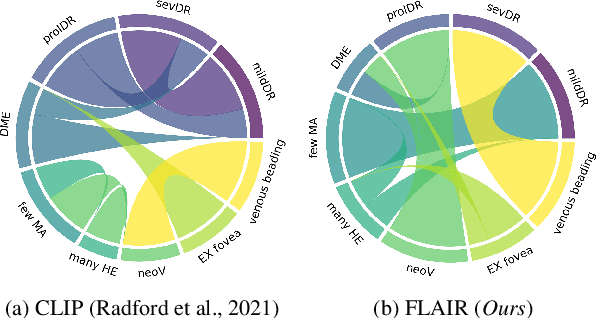
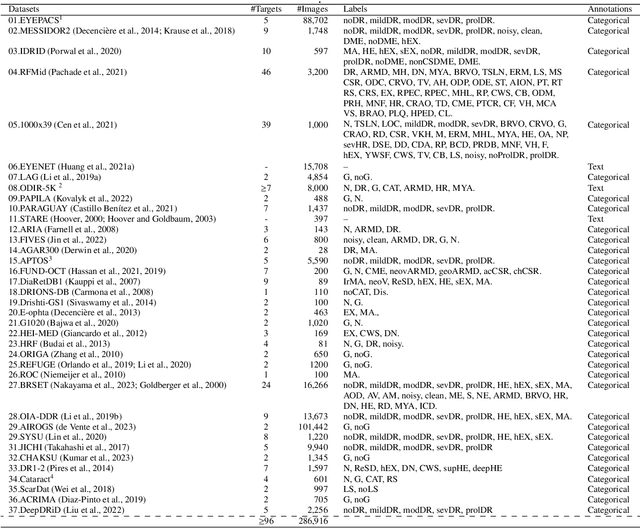
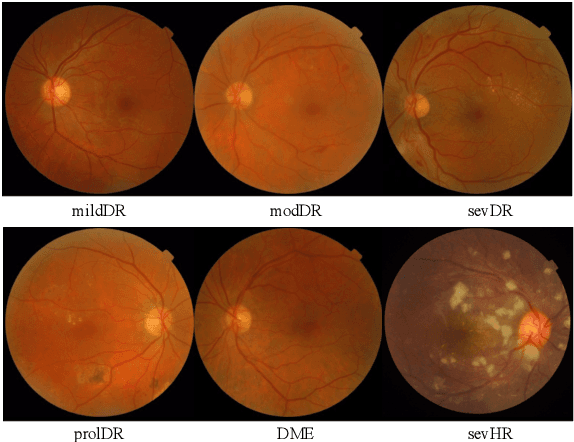
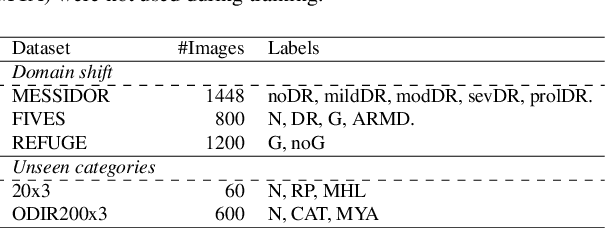
Foundation vision-language models are currently transforming computer vision, and are on the rise in medical imaging fueled by their very promising generalization capabilities. However, the initial attempts to transfer this new paradigm to medical imaging have shown less impressive performances than those observed in other domains, due to the significant domain shift and the complex, expert domain knowledge inherent to medical-imaging tasks. Motivated by the need for domain-expert foundation models, we present FLAIR, a pre-trained vision-language model for universal retinal fundus image understanding. To this end, we compiled 37 open-access, mostly categorical fundus imaging datasets from various sources, with up to 97 different target conditions and 284,660 images. We integrate the expert's domain knowledge in the form of descriptive textual prompts, during both pre-training and zero-shot inference, enhancing the less-informative categorical supervision of the data. Such a textual expert's knowledge, which we compiled from the relevant clinical literature and community standards, describes the fine-grained features of the pathologies as well as the hierarchies and dependencies between them. We report comprehensive evaluations, which illustrate the benefit of integrating expert knowledge and the strong generalization capabilities of FLAIR under difficult scenarios with domain shifts or unseen categories. When adapted with a lightweight linear probe, FLAIR outperforms fully-trained, dataset-focused models, more so in the few-shot regimes. Interestingly, FLAIR outperforms by a large margin more generalist, larger-scale image-language models, which emphasizes the potential of embedding experts' domain knowledge and the limitations of generalist models in medical imaging.
Accelerating Deep Neural Networks via Semi-Structured Activation Sparsity
Sep 27, 2023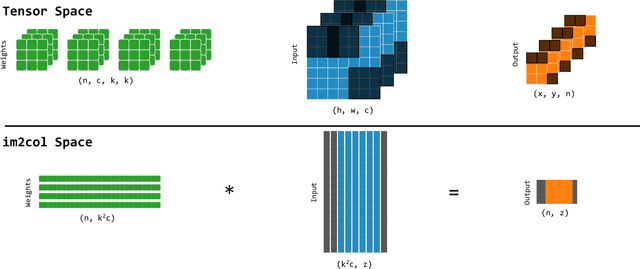
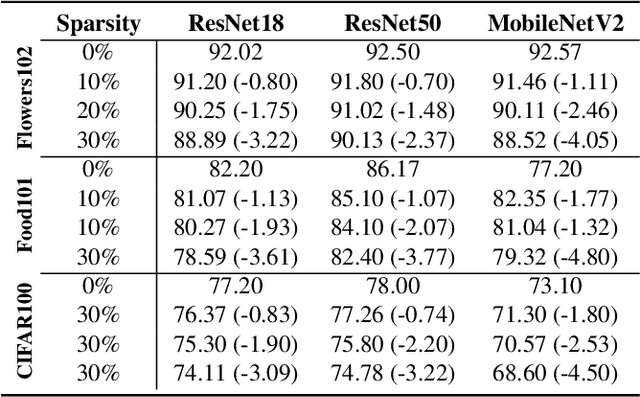
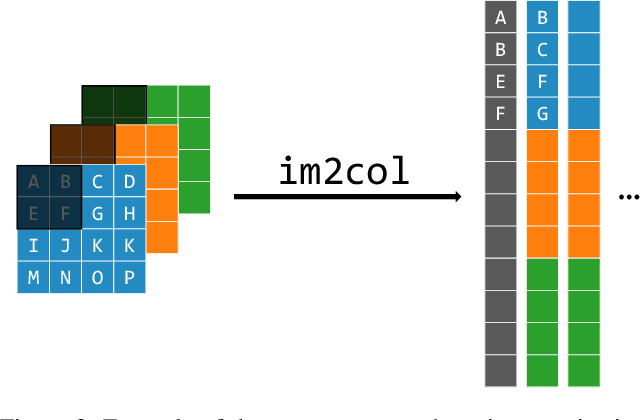
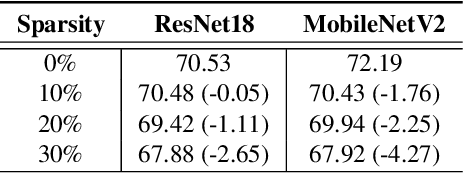
The demand for efficient processing of deep neural networks (DNNs) on embedded devices is a significant challenge limiting their deployment. Exploiting sparsity in the network's feature maps is one of the ways to reduce its inference latency. It is known that unstructured sparsity results in lower accuracy degradation with respect to structured sparsity but the former needs extensive inference engine changes to get latency benefits. To tackle this challenge, we propose a solution to induce semi-structured activation sparsity exploitable through minor runtime modifications. To attain high speedup levels at inference time, we design a sparse training procedure with awareness of the final position of the activations while computing the General Matrix Multiplication (GEMM). We extensively evaluate the proposed solution across various models for image classification and object detection tasks. Remarkably, our approach yields a speed improvement of $1.25 \times$ with a minimal accuracy drop of $1.1\%$ for the ResNet18 model on the ImageNet dataset. Furthermore, when combined with a state-of-the-art structured pruning method, the resulting models provide a good latency-accuracy trade-off, outperforming models that solely employ structured pruning techniques.