 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQGen: On the Ability to Generalize in Quantization Aware Training
Apr 19, 2024



Quantization lowers memory usage, computational requirements, and latency by utilizing fewer bits to represent model weights and activations. In this work, we investigate the generalization properties of quantized neural networks, a characteristic that has received little attention despite its implications on model performance. In particular, first, we develop a theoretical model for quantization in neural networks and demonstrate how quantization functions as a form of regularization. Second, motivated by recent work connecting the sharpness of the loss landscape and generalization, we derive an approximate bound for the generalization of quantized models conditioned on the amount of quantization noise. We then validate our hypothesis by experimenting with over 2000 models trained on CIFAR-10, CIFAR-100, and ImageNet datasets on convolutional and transformer-based models.
Accelerating Deep Neural Networks via Semi-Structured Activation Sparsity
Sep 27, 2023The demand for efficient processing of deep neural networks (DNNs) on embedded devices is a significant challenge limiting their deployment. Exploiting sparsity in the network's feature maps is one of the ways to reduce its inference latency. It is known that unstructured sparsity results in lower accuracy degradation with respect to structured sparsity but the former needs extensive inference engine changes to get latency benefits. To tackle this challenge, we propose a solution to induce semi-structured activation sparsity exploitable through minor runtime modifications. To attain high speedup levels at inference time, we design a sparse training procedure with awareness of the final position of the activations while computing the General Matrix Multiplication (GEMM). We extensively evaluate the proposed solution across various models for image classification and object detection tasks. Remarkably, our approach yields a speed improvement of $1.25 \times$ with a minimal accuracy drop of $1.1\%$ for the ResNet18 model on the ImageNet dataset. Furthermore, when combined with a state-of-the-art structured pruning method, the resulting models provide a good latency-accuracy trade-off, outperforming models that solely employ structured pruning techniques.
YOLOBench: Benchmarking Efficient Object Detectors on Embedded Systems
Jul 26, 2023



We present YOLOBench, a benchmark comprised of 550+ YOLO-based object detection models on 4 different datasets and 4 different embedded hardware platforms (x86 CPU, ARM CPU, Nvidia GPU, NPU). We collect accuracy and latency numbers for a variety of YOLO-based one-stage detectors at different model scales by performing a fair, controlled comparison of these detectors with a fixed training environment (code and training hyperparameters). Pareto-optimality analysis of the collected data reveals that, if modern detection heads and training techniques are incorporated into the learning process, multiple architectures of the YOLO series achieve a good accuracy-latency trade-off, including older models like YOLOv3 and YOLOv4. We also evaluate training-free accuracy estimators used in neural architecture search on YOLOBench and demonstrate that, while most state-of-the-art zero-cost accuracy estimators are outperformed by a simple baseline like MAC count, some of them can be effectively used to predict Pareto-optimal detection models. We showcase that by using a zero-cost proxy to identify a YOLO architecture competitive against a state-of-the-art YOLOv8 model on a Raspberry Pi 4 CPU. The code and data are available at https://github.com/Deeplite/deeplite-torch-zoo
QReg: On Regularization Effects of Quantization
Jun 27, 2022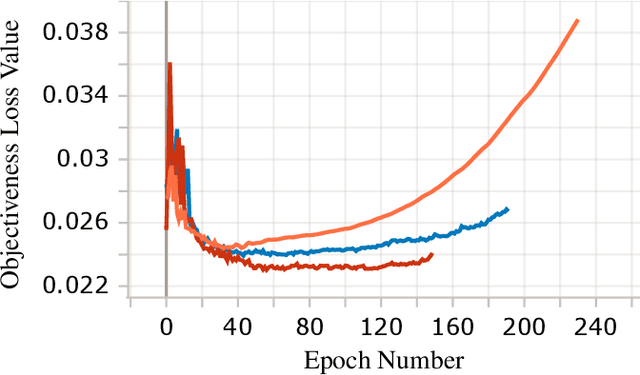
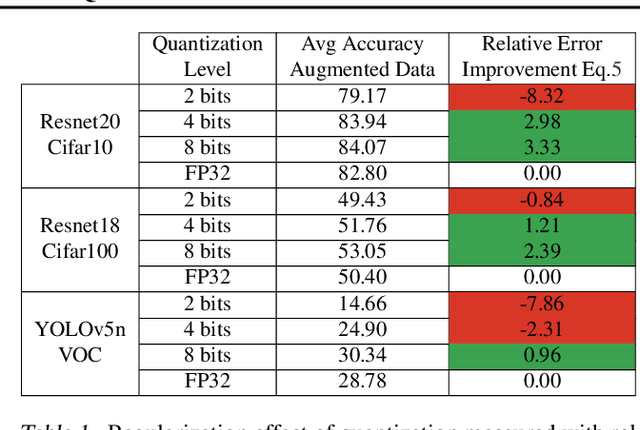
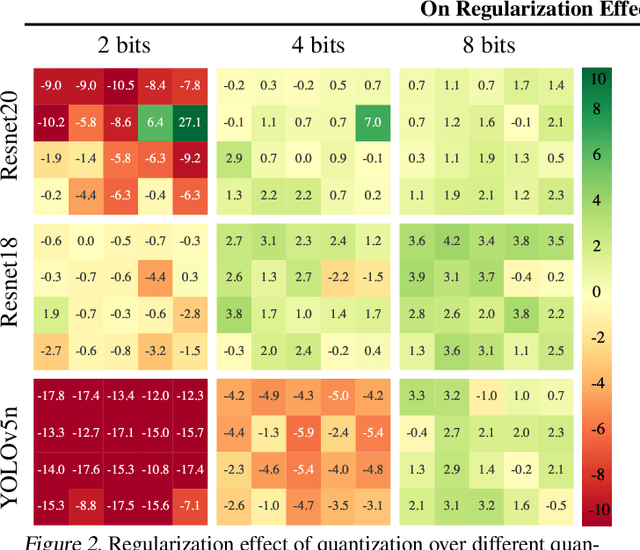
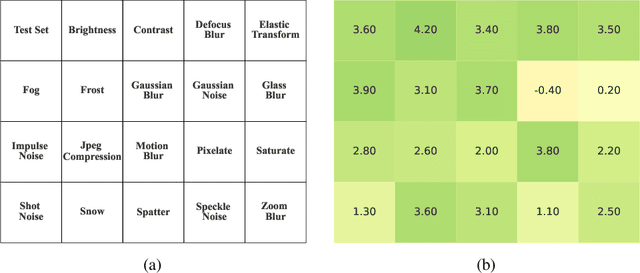
In this paper we study the effects of quantization in DNN training. We hypothesize that weight quantization is a form of regularization and the amount of regularization is correlated with the quantization level (precision). We confirm our hypothesis by providing analytical study and empirical results. By modeling weight quantization as a form of additive noise to weights, we explore how this noise propagates through the network at training time. We then show that the magnitude of this noise is correlated with the level of quantization. To confirm our analytical study, we performed an extensive list of experiments summarized in this paper in which we show that the regularization effects of quantization can be seen in various vision tasks and models, over various datasets. Based on our study, we propose that 8-bit quantization provides a reliable form of regularization in different vision tasks and models.
Post-training deep neural network pruning via layer-wise calibration
Apr 30, 2021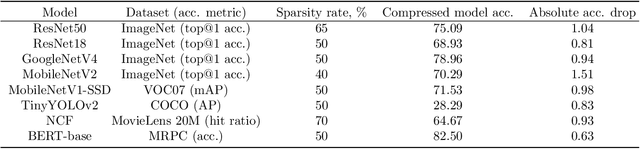
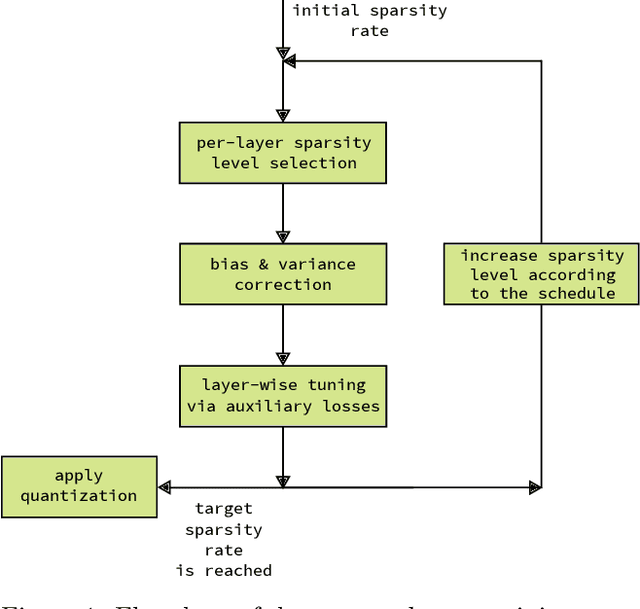
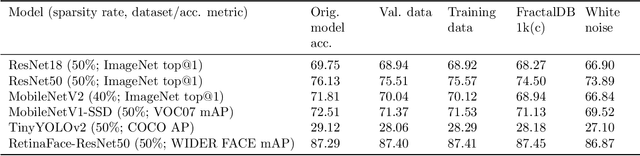
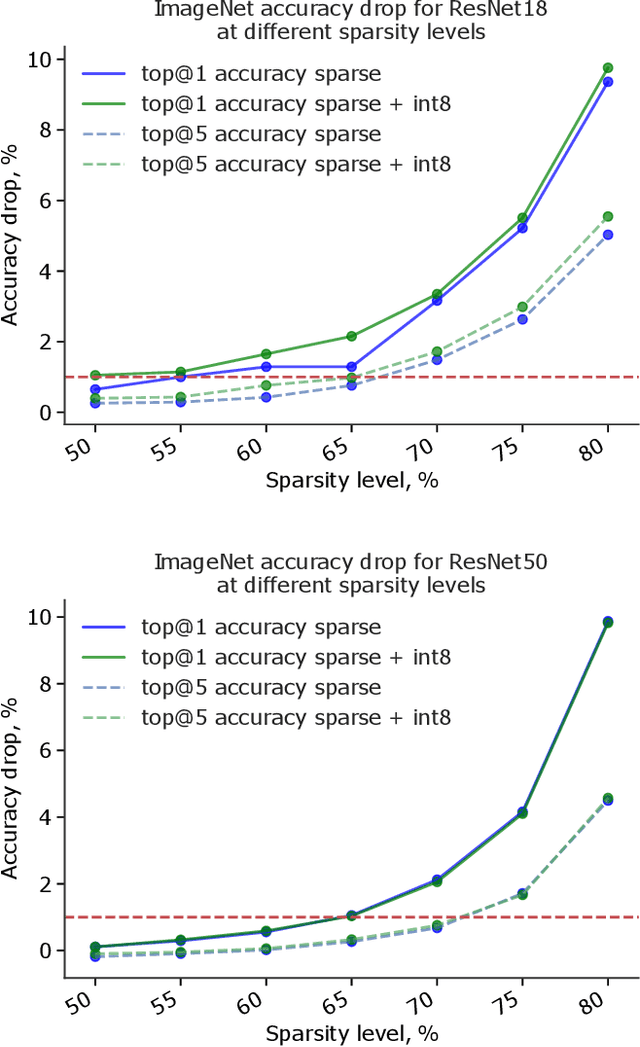
We present a post-training weight pruning method for deep neural networks that achieves accuracy levels tolerable for the production setting and that is sufficiently fast to be run on commodity hardware such as desktop CPUs or edge devices. We propose a data-free extension of the approach for computer vision models based on automatically-generated synthetic fractal images. We obtain state-of-the-art results for data-free neural network pruning, with ~1.5% top@1 accuracy drop for a ResNet50 on ImageNet at 50% sparsity rate. When using real data, we are able to get a ResNet50 model on ImageNet with 65% sparsity rate in 8-bit precision in a post-training setting with a ~1% top@1 accuracy drop. We release the code as a part of the OpenVINO(TM) Post-Training Optimization tool.
Neural Network Compression Framework for fast model inference
Mar 12, 2020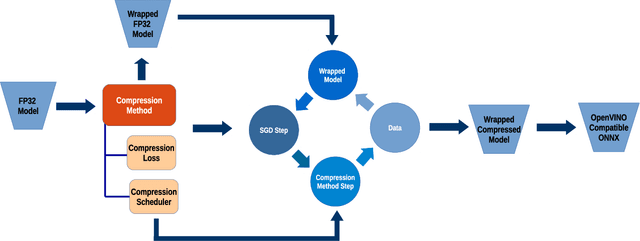
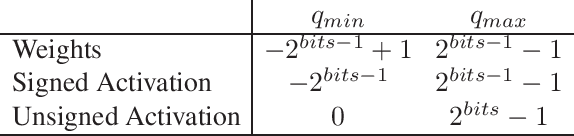

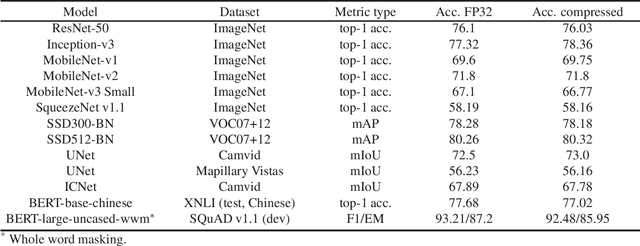
In this work we present a new framework for neural networks compression with fine-tuning, which we called Neural Network Compression Framework (NNCF). It leverages recent advances of various network compression methods and implements some of them, such as sparsity, quantization, and binarization. These methods allow getting more hardware-friendly models which can be efficiently run on general-purpose hardware computation units (CPU, GPU) or special Deep Learning accelerators. We show that the developed methods can be successfully applied to a wide range of models to accelerate the inference time while keeping the original accuracy. The framework can be used within the training samples, which are supplied with it, or as a standalone package that can be seamlessly integrated into the existing training code with minimal adaptations. Currently, a PyTorch version of NNCF is available as a part of OpenVINO Training Extensions at https://github.com/opencv/openvino_training_extensions/tree/develop/pytorch_toolkit/nncf