 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgephoto style transfer
Papers and Code
GarmentGAN: Photo-realistic Adversarial Fashion Transfer
Mar 04, 2020
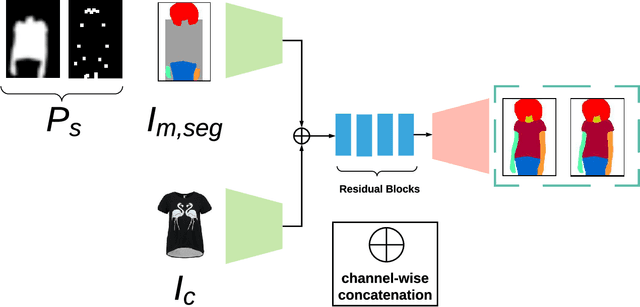
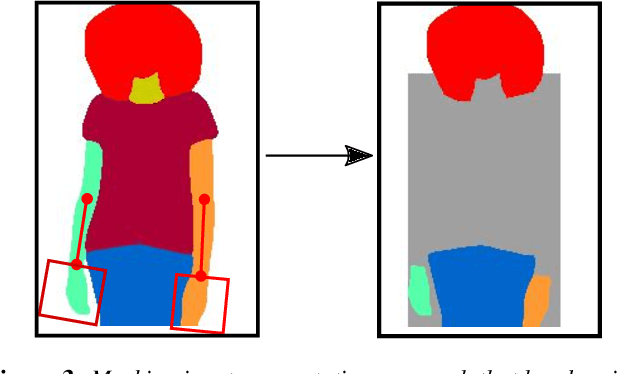
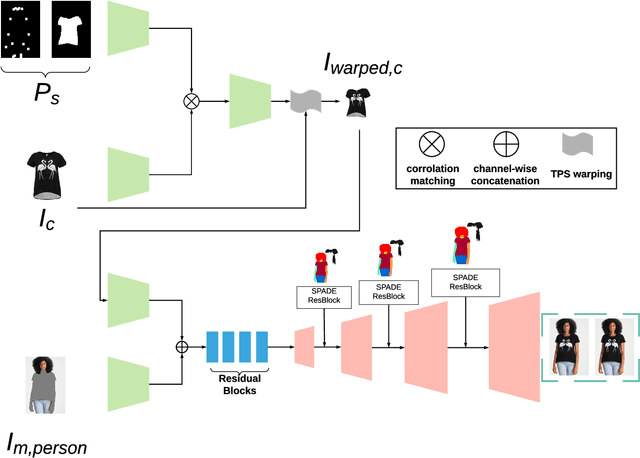
The garment transfer problem comprises two tasks: learning to separate a person's body (pose, shape, color) from their clothing (garment type, shape, style) and then generating new images of the wearer dressed in arbitrary garments. We present GarmentGAN, a new algorithm that performs image-based garment transfer through generative adversarial methods. The GarmentGAN framework allows users to virtually try-on items before purchase and generalizes to various apparel types. GarmentGAN requires as input only two images, namely, a picture of the target fashion item and an image containing the customer. The output is a synthetic image wherein the customer is wearing the target apparel. In order to make the generated image look photo-realistic, we employ the use of novel generative adversarial techniques. GarmentGAN improves on existing methods in the realism of generated imagery and solves various problems related to self-occlusions. Our proposed model incorporates additional information during training, utilizing both segmentation maps and body key-point information. We show qualitative and quantitative comparisons to several other networks to demonstrate the effectiveness of this technique.
GLStyleNet: Higher Quality Style Transfer Combining Global and Local Pyramid Features
Nov 18, 2018

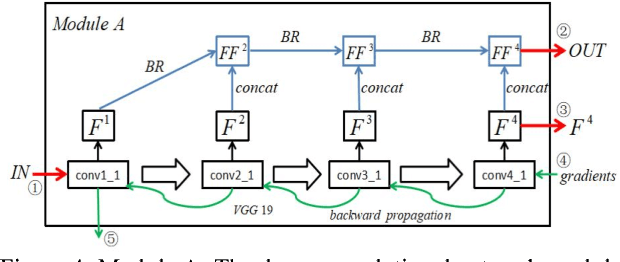
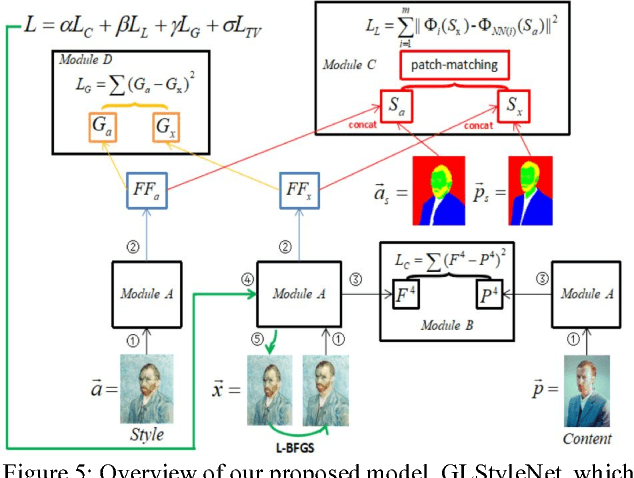
Recent studies using deep neural networks have shown remarkable success in style transfer especially for artistic and photo-realistic images. However, the approaches using global feature correlations fail to capture small, intricate textures and maintain correct texture scales of the artworks, and the approaches based on local patches are defective on global effect. In this paper, we present a novel feature pyramid fusion neural network, dubbed GLStyleNet, which sufficiently takes into consideration multi-scale and multi-level pyramid features by best aggregating layers across a VGG network, and performs style transfer hierarchically with multiple losses of different scales. Our proposed method retains high-frequency pixel information and low frequency construct information of images from two aspects: loss function constraint and feature fusion. Our approach is not only flexible to adjust the trade-off between content and style, but also controllable between global and local. Compared to state-of-the-art methods, our method can transfer not just large-scale, obvious style cues but also subtle, exquisite ones, and dramatically improves the quality of style transfer. We demonstrate the effectiveness of our approach on portrait style transfer, artistic style transfer, photo-realistic style transfer and Chinese ancient painting style transfer tasks. Experimental results indicate that our unified approach improves image style transfer quality over previous state-of-the-art methods, while also accelerating the whole process in a certain extent. Our code is available at https://github.com/EndyWon/GLStyleNet.
One-Shot Mutual Affine-Transfer for Photorealistic Stylization
Jul 24, 2019

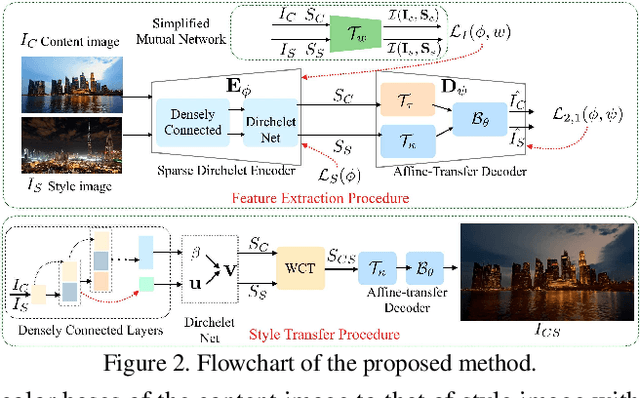
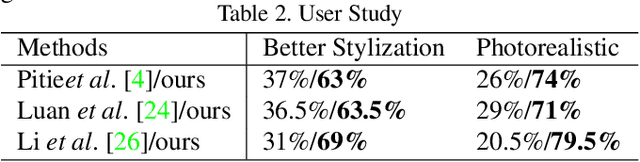
Photorealistic style transfer aims to transfer the style of a reference photo onto a content photo naturally, such that the stylized image looks like a real photo taken by a camera. Existing state-of-the-art methods are prone to spatial structure distortion of the content image and global color inconsistency across different semantic objects, making the results less photorealistic. In this paper, we propose a one-shot mutual Dirichlet network, to address these challenging issues. The essential contribution of the work is the realization of a representation scheme that successfully decouples the spatial structure and color information of images, such that the spatial structure can be well preserved during stylization. This representation is discriminative and context-sensitive with respect to semantic objects. It is extracted with a shared sparse Dirichlet encoder. Moreover, such representation is encouraged to be matched between the content and style images for faithful color transfer. The affine-transfer model is embedded in the decoder of the network to facilitate the color transfer. The strong representative and discriminative power of the proposed network enables one-shot learning given only one content-style image pair. Experimental results demonstrate that the proposed method is able to generate photorealistic photos without spatial distortion or abrupt color changes.
Generating Embroidery Patterns Using Image-to-Image Translation
Mar 05, 2020

In many scenarios in computer vision, machine learning, and computer graphics, there is a requirement to learn the mapping from an image of one domain to an image of another domain, called Image-to-image translation. For example, style transfer, object transfiguration, visually altering the appearance of weather conditions in an image, changing the appearance of a day image into a night image or vice versa, photo enhancement, to name a few. In this paper, we propose two machine learning techniques to solve the embroidery image-to-image translation. Our goal is to generate a preview image which looks similar to an embroidered image, from a user-uploaded image. Our techniques are modifications of two existing techniques, neural style transfer, and cycle-consistent generative-adversarial network. Neural style transfer renders the semantic content of an image from one domain in the style of a different image in another domain, whereas a cycle-consistent generative adversarial network learns the mapping from an input image to output image without any paired training data, and also learn a loss function to train this mapping. Furthermore, the techniques we propose are independent of any embroidery attributes, such as elevation of the image, light-source, start, and endpoints of a stitch, type of stitch used, fabric type, etc. Given the user image, our techniques can generate a preview image which looks similar to an embroidered image. We train and test our propose techniques on an embroidery dataset which consist of simple 2D images. To do so, we prepare an unpaired embroidery dataset with more than 8000 user-uploaded images along with embroidered images. Empirical results show that these techniques successfully generate an approximate preview of an embroidered version of a user image, which can help users in decision making.
Learning Linear Transformations for Fast Arbitrary Style Transfer
Aug 14, 2018
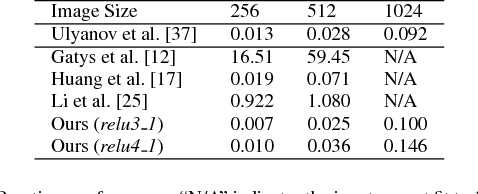
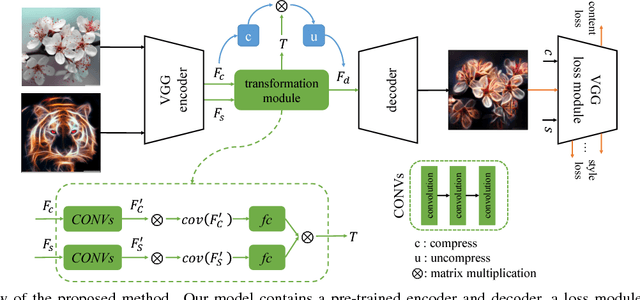
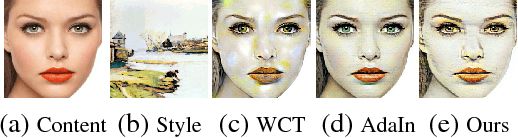
Given a random pair of images, an arbitrary style transfer method extracts the feel from the reference image to synthesize an output based on the look of the other content image. Recent arbitrary style transfer methods transfer second order statistics from reference image onto content image via a multiplication between content image features and a transformation matrix, which is computed from features with a pre-determined algorithm. These algorithms either require computationally expensive operations, or fail to model the feature covariance and produce artifacts in synthesized images. Generalized from these methods, in this work, we derive the form of transformation matrix theoretically and present an arbitrary style transfer approach that learns the transformation matrix with a feed-forward network. Our algorithm is highly efficient yet allows a flexible combination of multi-level styles while preserving content affinity during style transfer process. We demonstrate the effectiveness of our approach on four tasks: artistic style transfer, video and photo-realistic style transfer as well as domain adaptation, including comparisons with the state-of-the-art methods.
Style Transfer With Adaptation to the Central Objects of the Scene
Jun 04, 2019
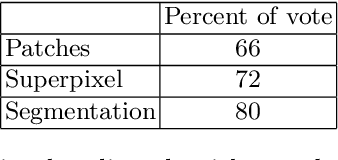


Style transfer is a problem of rendering image with some content in the style of another image, for example a family photo in the style of a painting of some famous artist. The drawback of classical style transfer algorithm is that it imposes style uniformly on all parts of the content image, which perturbs central objects on the content image, such as faces or text, and makes them unrecognizable. This work proposes a novel style transfer algorithm which automatically detects central objects on the content image, generates spatial importance mask and imposes style non-uniformly: central objects are stylized less to preserve their recognizability and other parts of the image are stylized as usual to preserve the style. Three methods of automatic central object detection are proposed and evaluated qualitatively and via a user evaluation study. Both comparisons demonstrate higher quality of stylization compared to the classical style transfer method.
Streetscape augmentation using generative adversarial networks: insights related to health and wellbeing
May 14, 2019
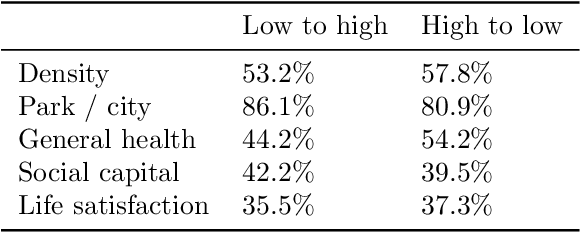
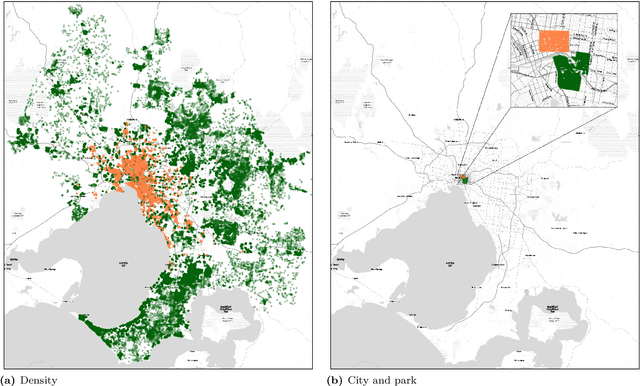
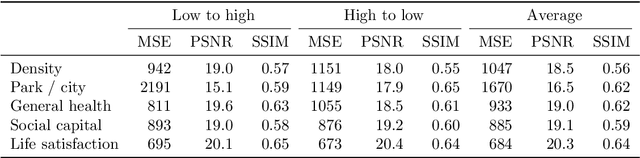
Deep learning using neural networks has provided advances in image style transfer, merging the content of one image (e.g., a photo) with the style of another (e.g., a painting). Our research shows this concept can be extended to analyse the design of streetscapes in relation to health and wellbeing outcomes. An Australian population health survey (n=34,000) was used to identify the spatial distribution of health and wellbeing outcomes, including general health and social capital. For each outcome, the most and least desirable locations formed two domains. Streetscape design was sampled using around 80,000 Google Street View images per domain. Generative adversarial networks translated these images from one domain to the other, preserving the main structure of the input image, but transforming the `style' from locations where self-reported health was bad to locations where it was good. These translations indicate that areas in Melbourne with good general health are characterised by sufficient green space and compactness of the urban environment, whilst streetscape imagery related to high social capital contained more and wider footpaths, fewer fences and more grass. Beyond identifying relationships, the method is a first step towards computer-generated design interventions that have the potential to improve population health and wellbeing.
WarpGAN: Automatic Caricature Generation
Nov 28, 2018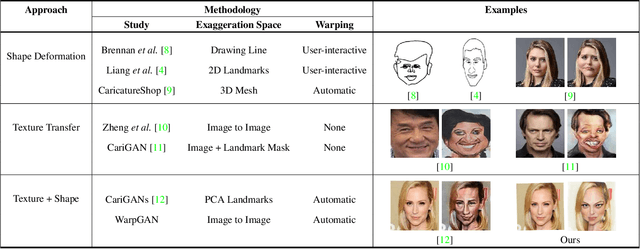
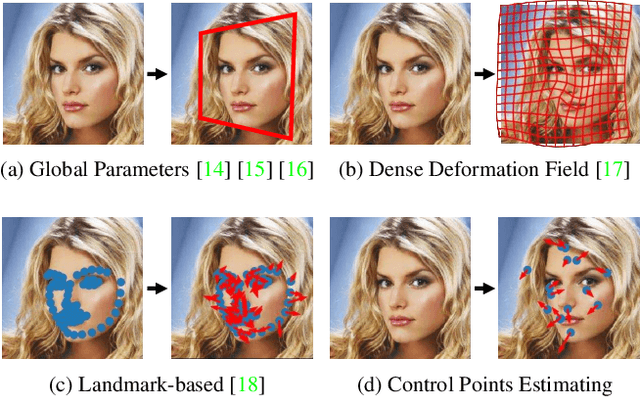
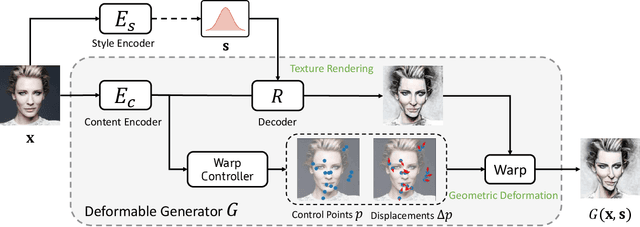
We propose, WarpGAN, a fully automatic network that can generate caricatures given an input face photo. Besides transferring rich texture styles, WarpGAN learns to automatically predict a set of control points that can warp the photo into a caricature, while preserving identity. We introduce an identity-preserving adversarial loss that aids the discriminator to distinguish between different subjects. Moreover, WarpGAN allows customization of the generated caricatures by controlling the exaggeration extent and the visual styles. Experimental results on a public domain dataset, WebCaricature, show that WarpGAN is capable of generating a diverse set of caricatures while preserving the identities. Five caricature experts suggest that caricatures generated by WarpGAN are visually similar to hand-drawn ones and only prominent facial features are exaggerated.
Deep Video Color Propagation
Aug 09, 2018
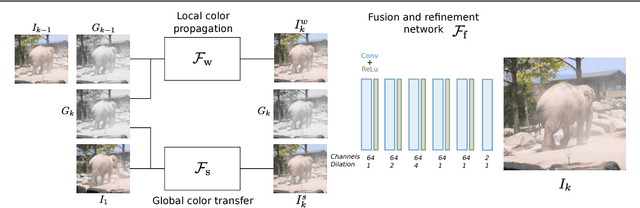
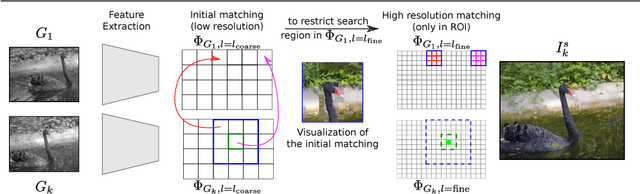

Traditional approaches for color propagation in videos rely on some form of matching between consecutive video frames. Using appearance descriptors, colors are then propagated both spatially and temporally. These methods, however, are computationally expensive and do not take advantage of semantic information of the scene. In this work we propose a deep learning framework for color propagation that combines a local strategy, to propagate colors frame-by-frame ensuring temporal stability, and a global strategy, using semantics for color propagation within a longer range. Our evaluation shows the superiority of our strategy over existing video and image color propagation methods as well as neural photo-realistic style transfer approaches.
Wavelet Domain Style Transfer for an Effective Perception-distortion Tradeoff in Single Image Super-Resolution
Oct 09, 2019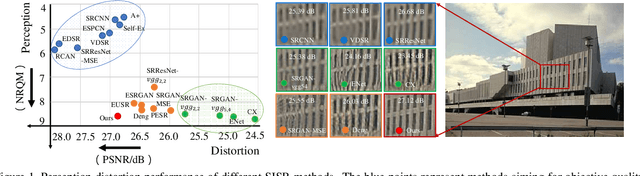
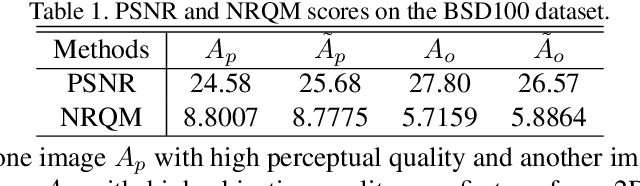
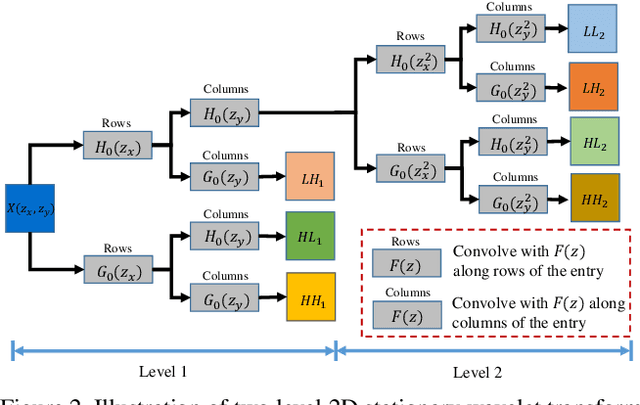
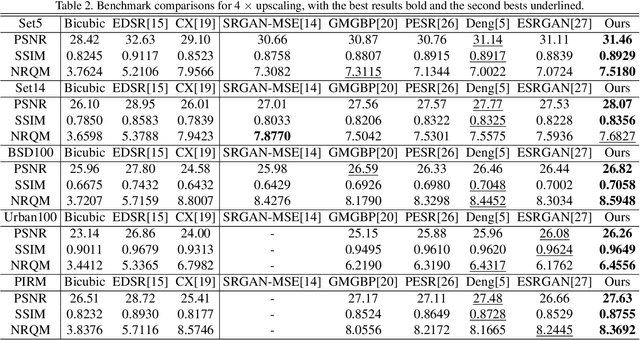
In single image super-resolution (SISR), given a low-resolution (LR) image, one wishes to find a high-resolution (HR) version of it which is both accurate and photo-realistic. Recently, it has been shown that there exists a fundamental tradeoff between low distortion and high perceptual quality, and the generative adversarial network (GAN) is demonstrated to approach the perception-distortion (PD) bound effectively. In this paper, we propose a novel method based on wavelet domain style transfer (WDST), which achieves a better PD tradeoff than the GAN based methods. Specifically, we propose to use 2D stationary wavelet transform (SWT) to decompose one image into low-frequency and high-frequency sub-bands. For the low-frequency sub-band, we improve its objective quality through an enhancement network. For the high-frequency sub-band, we propose to use WDST to effectively improve its perceptual quality. By feat of the perfect reconstruction property of wavelets, these sub-bands can be re-combined to obtain an image which has simultaneously high objective and perceptual quality. The numerical results on various datasets show that our method achieves the best trade-off between the distortion and perceptual quality among the existing state-of-the-art SISR methods.