 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiased Multimodal Personality Understanding through Dual Causal Intervention
May 07, 2026Multimodalpersonalityunderstandingplaysacriticalroleinhuman centered artificial intelligence. Previous work mainly focus on learn-ing rich multimodal representations for video personality under standing. However, they often suffer from potential harm caused by subject bias (e.g., observable age and unobservable mental states), as subjects originate from diverse demographic backgrounds. Learn ing such spurious associations between multimodal features and traits may lead to unfair personality understanding. In this work, weconstruct aStructural Causal Model (SCM)toanalyze theimpact of these biases from a causal perspective, and propose a novel Dual Causal Adjustment Network (DCAN) to mitigate the interference of subject attributes on personality understanding. Specifically, we design a Back-door Adjustment Causal Learning (BACL) module to block spurious correlations from observable demographic factors via a prototype-based confounder dictionary, and subsequently ap ply a Front-door Adjustment Causal Learning (FACL) module to ad dress latent and unobservable biases throughalearnedmediatordic tionary intervention, thereby achieving causal disentanglement of representations for deconfounded reasoning. Importantly, we con struct a Demographic-annotated Multimodal Student Personality (DMSP) dataset to support the analysis and discussion of fairness related factors. Extensive experiments on the benchmark dataset CFI-V2 and our DMSPdataset demonstrate that DCAN consistently improves prediction accuracy, reaching 92.11% and 92.90%, respec tively. Meanwhile, the improvementsinthefairnessmetricsofequal opportunity and demographic parity are 6.57% and 7.97% on CFI-V2, and 15.38% and 20.06% on the DMSP dataset. Our code and DMSP dataset are available at https://github.com/Sabrina-han/DCAN
RU4D-SLAM: Reweighting Uncertainty in Gaussian Splatting SLAM for 4D Scene Reconstruction
Feb 24, 2026Combining 3D Gaussian splatting with Simultaneous Localization and Mapping (SLAM) has gained popularity as it enables continuous 3D environment reconstruction during motion. However, existing methods struggle in dynamic environments, particularly moving objects complicate 3D reconstruction and, in turn, hinder reliable tracking. The emergence of 4D reconstruction, especially 4D Gaussian splatting, offers a promising direction for addressing these challenges, yet its potential for 4D-aware SLAM remains largely underexplored. Along this direction, we propose a robust and efficient framework, namely Reweighting Uncertainty in Gaussian Splatting SLAM (RU4D-SLAM) for 4D scene reconstruction, that introduces temporal factors into spatial 3D representation while incorporating uncertainty-aware perception of scene changes, blurred image synthesis, and dynamic scene reconstruction. We enhance dynamic scene representation by integrating motion blur rendering, and improve uncertainty-aware tracking by extending per-pixel uncertainty modeling, which is originally designed for static scenarios, to handle blurred images. Furthermore, we propose a semantic-guided reweighting mechanism for per-pixel uncertainty estimation in dynamic scenes, and introduce a learnable opacity weight to support adaptive 4D mapping. Extensive experiments on standard benchmarks demonstrate that our method substantially outperforms state-of-the-art approaches in both trajectory accuracy and 4D scene reconstruction, particularly in dynamic environments with moving objects and low-quality inputs. Code available: https://ru4d-slam.github.io
Eq.Bot: Enhance Robotic Manipulation Learning via Group Equivariant Canonicalization
Nov 19, 2025Robotic manipulation systems are increasingly deployed across diverse domains. Yet existing multi-modal learning frameworks lack inherent guarantees of geometric consistency, struggling to handle spatial transformations such as rotations and translations. While recent works attempt to introduce equivariance through bespoke architectural modifications, these methods suffer from high implementation complexity, computational cost, and poor portability. Inspired by human cognitive processes in spatial reasoning, we propose Eq.Bot, a universal canonicalization framework grounded in SE(2) group equivariant theory for robotic manipulation learning. Our framework transforms observations into a canonical space, applies an existing policy, and maps the resulting actions back to the original space. As a model-agnostic solution, Eq.Bot aims to endow models with spatial equivariance without requiring architectural modifications. Extensive experiments demonstrate the superiority of Eq.Bot under both CNN-based (e.g., CLIPort) and Transformer-based (e.g., OpenVLA-OFT) architectures over existing methods on various robotic manipulation tasks, where the most significant improvement can reach 50.0%.
One-Shot Mutual Affine-Transfer for Photorealistic Stylization
Jul 24, 2019

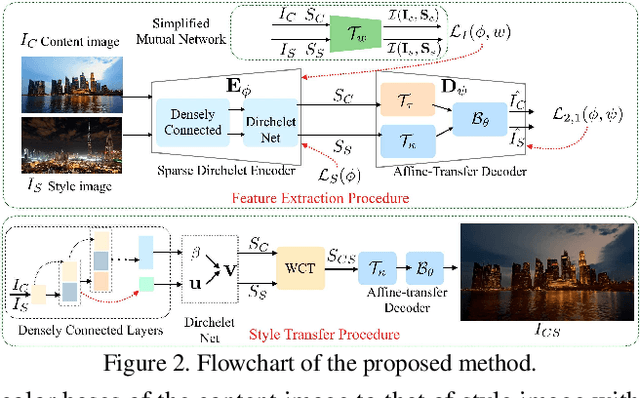
Photorealistic style transfer aims to transfer the style of a reference photo onto a content photo naturally, such that the stylized image looks like a real photo taken by a camera. Existing state-of-the-art methods are prone to spatial structure distortion of the content image and global color inconsistency across different semantic objects, making the results less photorealistic. In this paper, we propose a one-shot mutual Dirichlet network, to address these challenging issues. The essential contribution of the work is the realization of a representation scheme that successfully decouples the spatial structure and color information of images, such that the spatial structure can be well preserved during stylization. This representation is discriminative and context-sensitive with respect to semantic objects. It is extracted with a shared sparse Dirichlet encoder. Moreover, such representation is encouraged to be matched between the content and style images for faithful color transfer. The affine-transfer model is embedded in the decoder of the network to facilitate the color transfer. The strong representative and discriminative power of the proposed network enables one-shot learning given only one content-style image pair. Experimental results demonstrate that the proposed method is able to generate photorealistic photos without spatial distortion or abrupt color changes.
Unsupervised Trajectory Segmentation and Promoting of Multi-Modal Surgical Demonstrations
Oct 01, 2018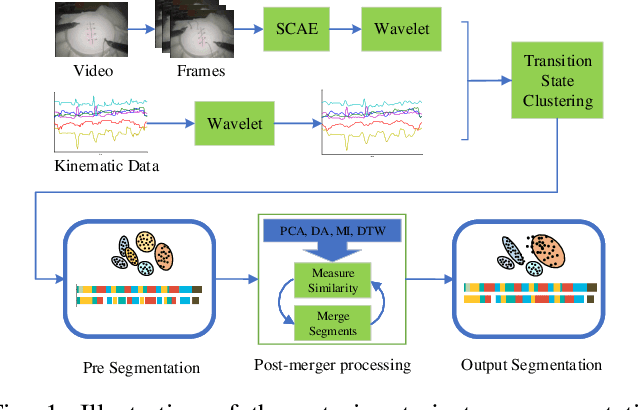
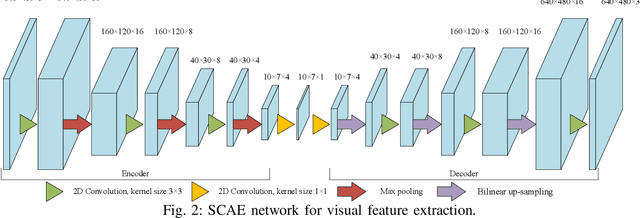
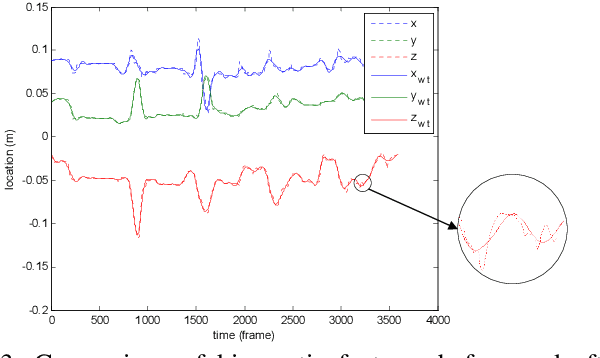
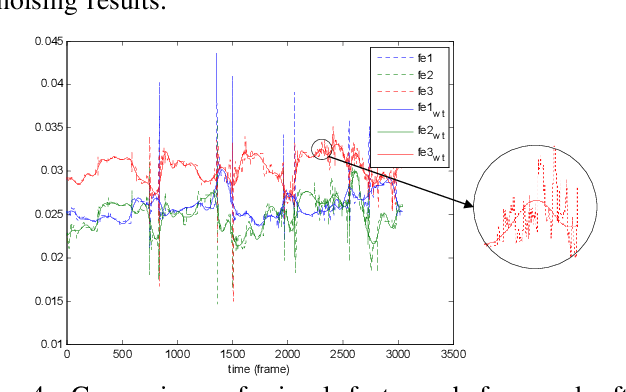
To improve the efficiency of surgical trajectory segmentation for robot learning in robot-assisted minimally invasive surgery, this paper presents a fast unsupervised method using video and kinematic data, followed by a promoting procedure to address the over-segmentation issue. Unsupervised deep learning network, stacking convolutional auto-encoder, is employed to extract more discriminative features from videos in an effective way. To further improve the accuracy of segmentation, on one hand, wavelet transform is used to filter out the noises existed in the features from video and kinematic data. On the other hand, the segmentation result is promoted by identifying the adjacent segments with no state transition based on the predefined similarity measurements. Extensive experiments on a public dataset JIGSAWS show that our method achieves much higher accuracy of segmentation than state-of-the-art methods in the shorter time.