 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgephoto style transfer
Papers and Code
UMFA: A photorealistic style transfer method based on U-Net and multi-layer feature aggregation
Aug 13, 2021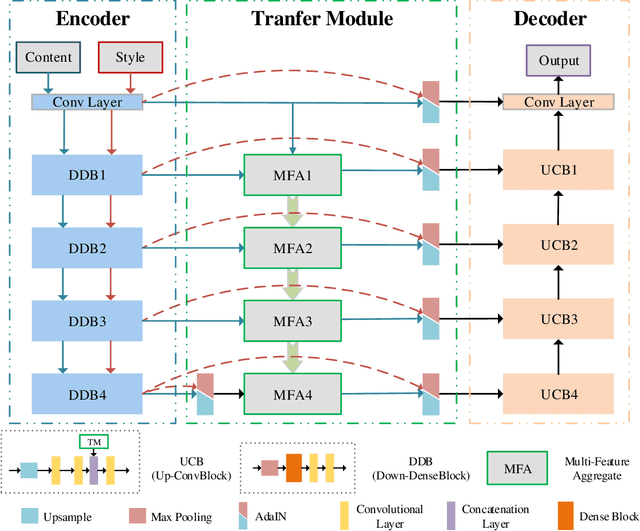

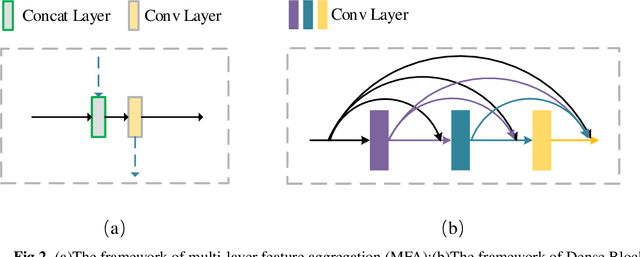

In this paper, we propose a photorealistic style transfer network to emphasize the natural effect of photorealistic image stylization. In general, distortion of the image content and lacking of details are two typical issues in the style transfer field. To this end, we design a novel framework employing the U-Net structure to maintain the rich spatial clues, with a multi-layer feature aggregation (MFA) method to simultaneously provide the details obtained by the shallow layers in the stylization processing. In particular, an encoder based on the dense block and a decoder form a symmetrical structure of U-Net are jointly staked to realize an effective feature extraction and image reconstruction. Besides, a transfer module based on MFA and "adaptive instance normalization" (AdaIN) is inserted in the skip connection positions to achieve the stylization. Accordingly, the stylized image possesses the texture of a real photo and preserves rich content details without introducing any mask or post-processing steps. The experimental results on public datasets demonstrate that our method achieves a more faithful structural similarity with a lower style loss, reflecting the effectiveness and merit of our approach.
SpaceEdit: Learning a Unified Editing Space for Open-Domain Image Editing
Nov 30, 2021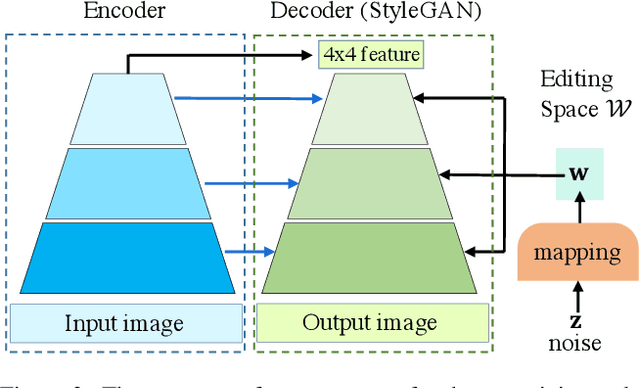


Recently, large pretrained models (e.g., BERT, StyleGAN, CLIP) have shown great knowledge transfer and generalization capability on various downstream tasks within their domains. Inspired by these efforts, in this paper we propose a unified model for open-domain image editing focusing on color and tone adjustment of open-domain images while keeping their original content and structure. Our model learns a unified editing space that is more semantic, intuitive, and easy to manipulate than the operation space (e.g., contrast, brightness, color curve) used in many existing photo editing softwares. Our model belongs to the image-to-image translation framework which consists of an image encoder and decoder, and is trained on pairs of before- and after-images to produce multimodal outputs. We show that by inverting image pairs into latent codes of the learned editing space, our model can be leveraged for various downstream editing tasks such as language-guided image editing, personalized editing, editing-style clustering, retrieval, etc. We extensively study the unique properties of the editing space in experiments and demonstrate superior performance on the aforementioned tasks.
Diamond in the rough: Improving image realism by traversing the GAN latent space
Apr 12, 2021
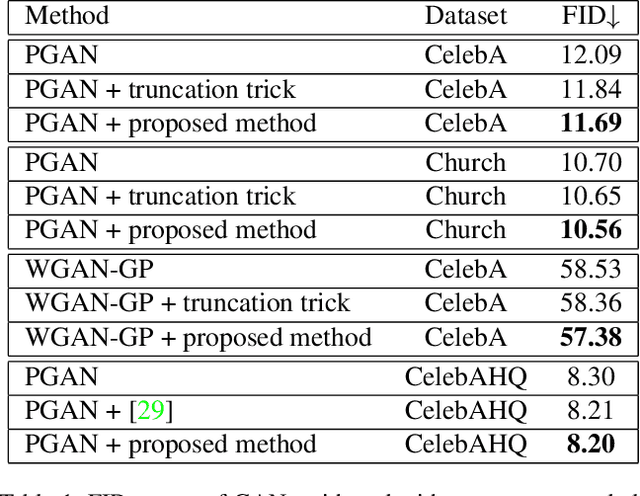
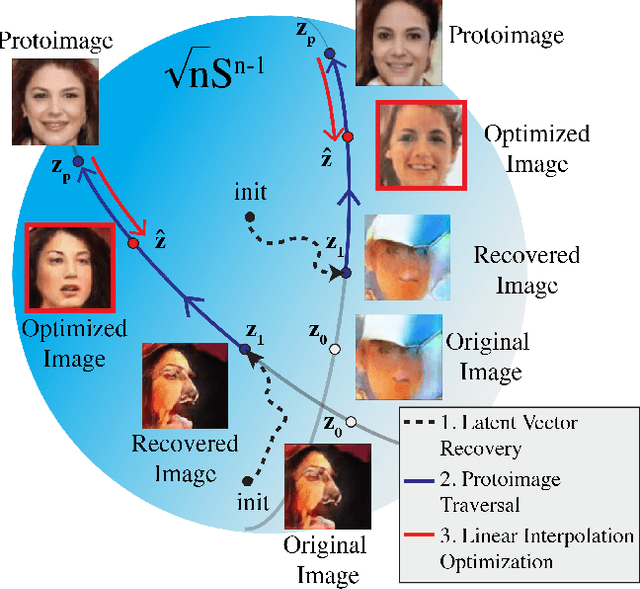
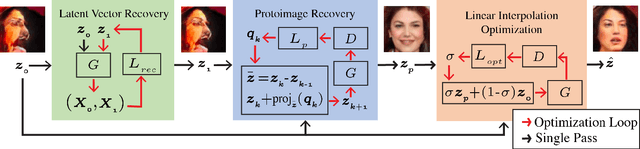
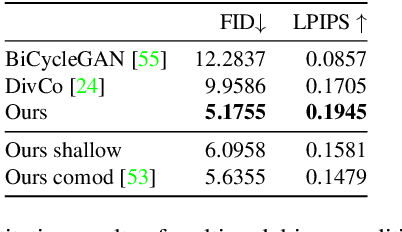
In just a few years, the photo-realism of images synthesized by Generative Adversarial Networks (GANs) has gone from somewhat reasonable to almost perfect largely by increasing the complexity of the networks, e.g., adding layers, intermediate latent spaces, style-transfer parameters, etc. This trajectory has led many of the state-of-the-art GANs to be inaccessibly large, disengaging many without large computational resources. Recognizing this, we explore a method for squeezing additional performance from existing, low-complexity GANs. Formally, we present an unsupervised method to find a direction in the latent space that aligns with improved photo-realism. Our approach leaves the network unchanged while enhancing the fidelity of the generated image. We use a simple generator inversion to find the direction in the latent space that results in the smallest change in the image space. Leveraging the learned structure of the latent space, we find moving in this direction corrects many image artifacts and brings the image into greater realism. We verify our findings qualitatively and quantitatively, showing an improvement in Frechet Inception Distance (FID) exists along our trajectory which surpasses the original GAN and other approaches including a supervised method. We expand further and provide an optimization method to automatically select latent vectors along the path that balance the variation and realism of samples. We apply our method to several diverse datasets and three architectures of varying complexity to illustrate the generalizability of our approach. By expanding the utility of low-complexity and existing networks, we hope to encourage the democratization of GANs.
GPU-Accelerated Mobile Multi-view Style Transfer
Mar 02, 2020
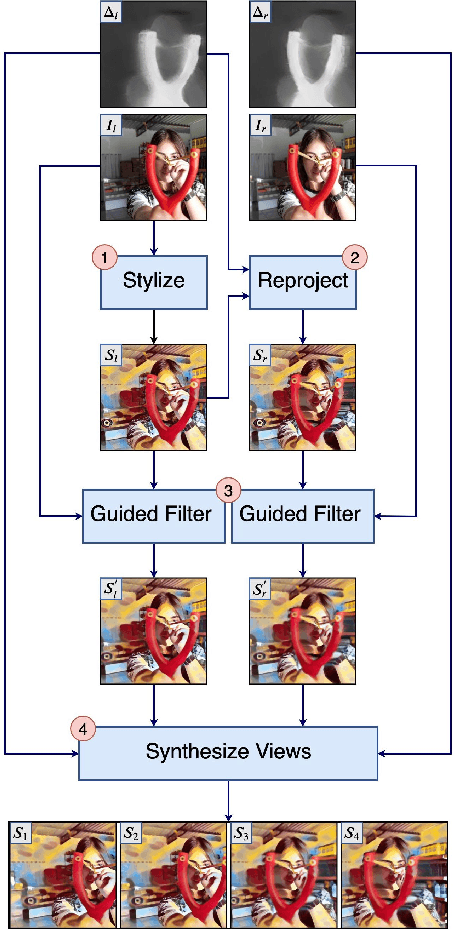
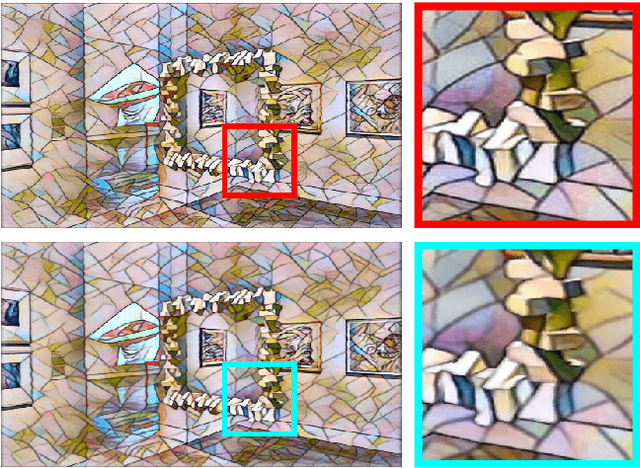

An estimated 60% of smartphones sold in 2018 were equipped with multiple rear cameras, enabling a wide variety of 3D-enabled applications such as 3D Photos. The success of 3D Photo platforms (Facebook 3D Photo, Holopix, etc) depend on a steady influx of user generated content. These platforms must provide simple image manipulation tools to facilitate content creation, akin to traditional photo platforms. Artistic neural style transfer, propelled by recent advancements in GPU technology, is one such tool for enhancing traditional photos. However, naively extrapolating single-view neural style transfer to the multi-view scenario produces visually inconsistent results and is prohibitively slow on mobile devices. We present a GPU-accelerated multi-view style transfer pipeline which enforces style consistency between views with on-demand performance on mobile platforms. Our pipeline is modular and creates high quality depth and parallax effects from a stereoscopic image pair.
Automated Deep Photo Style Transfer
Jan 12, 2019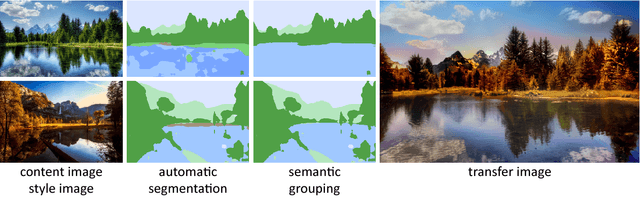

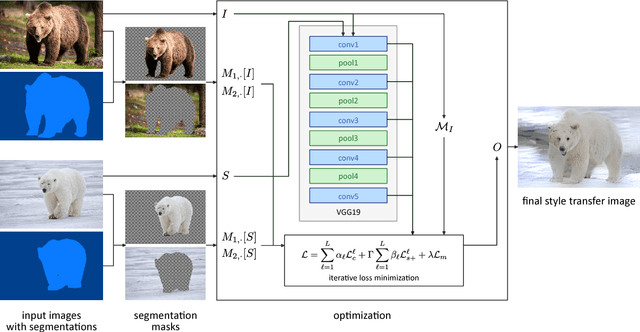

Photorealism is a complex concept that cannot easily be formulated mathematically. Deep Photo Style Transfer is an attempt to transfer the style of a reference image to a content image while preserving its photorealism. This is achieved by introducing a constraint that prevents distortions in the content image and by applying the style transfer independently for semantically different parts of the images. In addition, an automated segmentation process is presented that consists of a neural network based segmentation method followed by a semantic grouping step. To further improve the results a measure for image aesthetics is used and elaborated. If the content and the style image are sufficiently similar, the result images look very realistic. With the automation of the image segmentation the pipeline becomes completely independent from any user interaction, which allows for new applications.
Generative Adversarial Networks for photo to Hayao Miyazaki style cartoons
May 15, 2020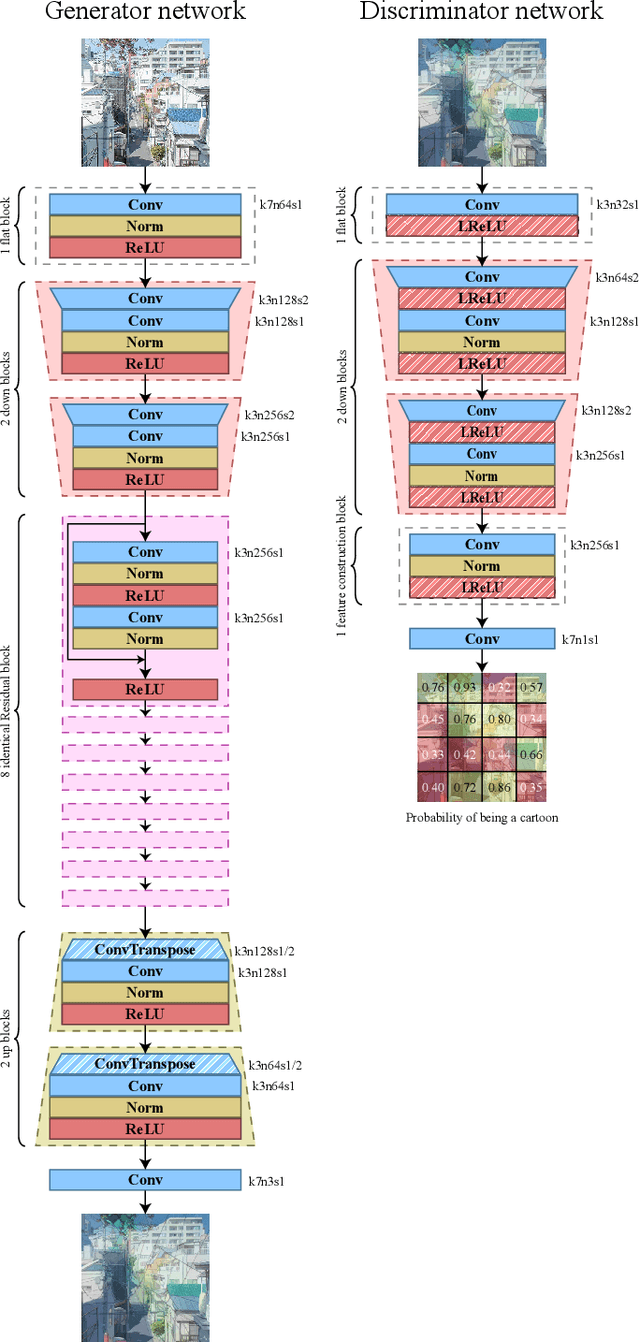



This paper takes on the problem of transferring the style of cartoon images to real-life photographic images by implementing previous work done by CartoonGAN. We trained a Generative Adversial Network(GAN) on over 60 000 images from works by Hayao Miyazaki at Studio Ghibli. To evaluate our results, we conducted a qualitative survey comparing our results with two state-of-the-art methods. 117 survey results indicated that our model on average outranked state-of-the-art methods on cartoon-likeness.
Face Sketch Synthesis with Style Transfer using Pyramid Column Feature
Sep 18, 2020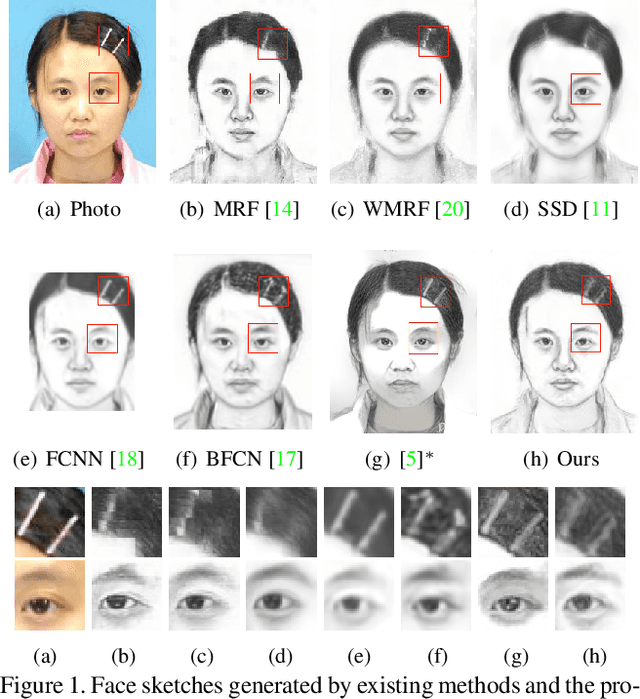
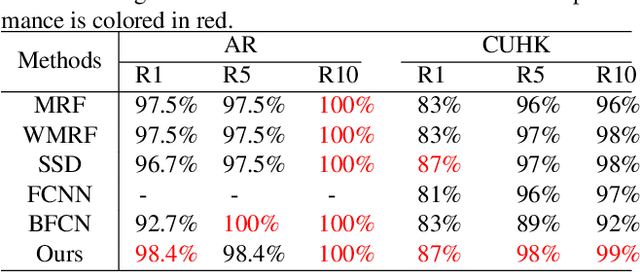
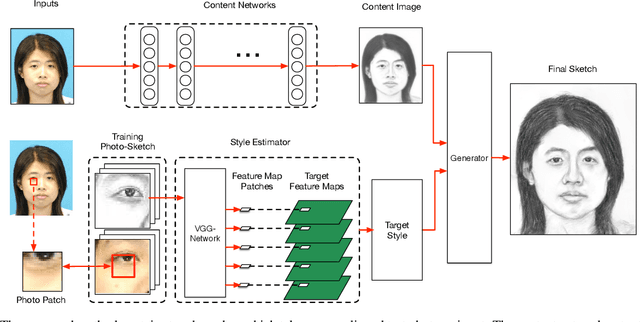
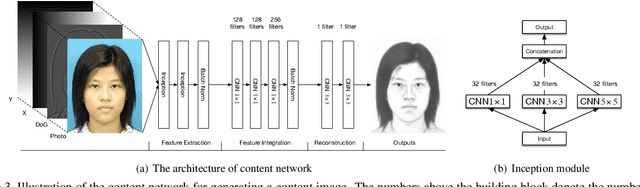
In this paper, we propose a novel framework based on deep neural networks for face sketch synthesis from a photo. Imitating the process of how artists draw sketches, our framework synthesizes face sketches in a cascaded manner. A content image is first generated that outlines the shape of the face and the key facial features. Textures and shadings are then added to enrich the details of the sketch. We utilize a fully convolutional neural network (FCNN) to create the content image, and propose a style transfer approach to introduce textures and shadings based on a newly proposed pyramid column feature. We demonstrate that our style transfer approach based on the pyramid column feature can not only preserve more sketch details than the common style transfer method, but also surpasses traditional patch based methods. Quantitative and qualitative evaluations suggest that our framework outperforms other state-of-the-arts methods, and can also generalize well to different test images. Codes are available at https://github.com/chaofengc/Face-Sketch
Resolution enhancement in the recovery of underdrawings via style transfer by generative adversarial deep neural networks
Jan 30, 2021



We apply generative adversarial convolutional neural networks to the problem of style transfer to underdrawings and ghost-images in x-rays of fine art paintings with a special focus on enhancing their spatial resolution. We build upon a neural architecture developed for the related problem of synthesizing high-resolution photo-realistic image from semantic label maps. Our neural architecture achieves high resolution through a hierarchy of generators and discriminator sub-networks, working throughout a range of spatial resolutions. This coarse-to-fine generator architecture can increase the effective resolution by a factor of eight in each spatial direction, or an overall increase in number of pixels by a factor of 64. We also show that even just a few examples of human-generated image segmentations can greatly improve -- qualitatively and quantitatively -- the generated images. We demonstrate our method on works such as Leonardo's Madonna of the carnation and the underdrawing in his Virgin of the rocks, which pose several special problems in style transfer, including the paucity of representative works from which to learn and transfer style information.
Region-aware Adaptive Instance Normalization for Image Harmonization
Jun 05, 2021
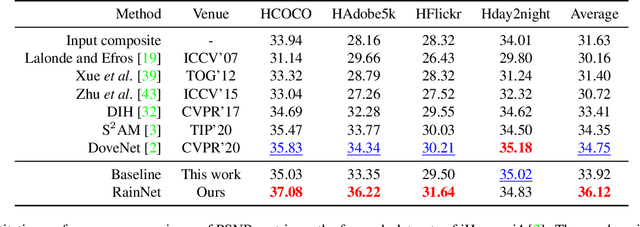
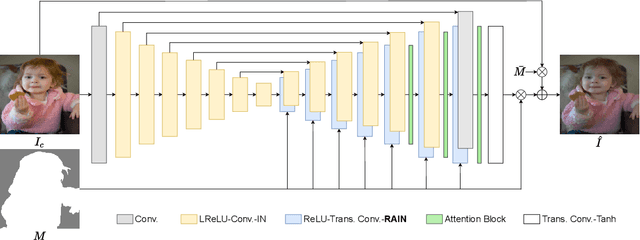
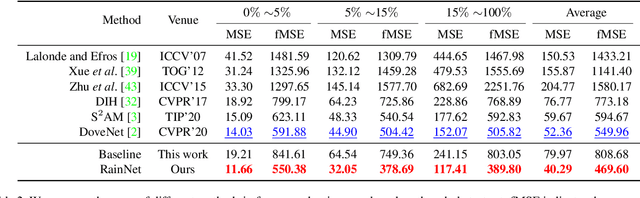
Image composition plays a common but important role in photo editing. To acquire photo-realistic composite images, one must adjust the appearance and visual style of the foreground to be compatible with the background. Existing deep learning methods for harmonizing composite images directly learn an image mapping network from the composite to the real one, without explicit exploration on visual style consistency between the background and the foreground images. To ensure the visual style consistency between the foreground and the background, in this paper, we treat image harmonization as a style transfer problem. In particular, we propose a simple yet effective Region-aware Adaptive Instance Normalization (RAIN) module, which explicitly formulates the visual style from the background and adaptively applies them to the foreground. With our settings, our RAIN module can be used as a drop-in module for existing image harmonization networks and is able to bring significant improvements. Extensive experiments on the existing image harmonization benchmark datasets show the superior capability of the proposed method. Code is available at {https://github.com/junleen/RainNet}.
SLGAN: Style- and Latent-guided Generative Adversarial Network for Desirable Makeup Transfer and Removal
Sep 24, 2020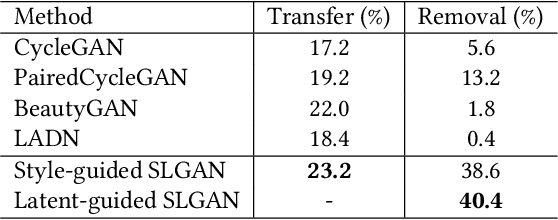
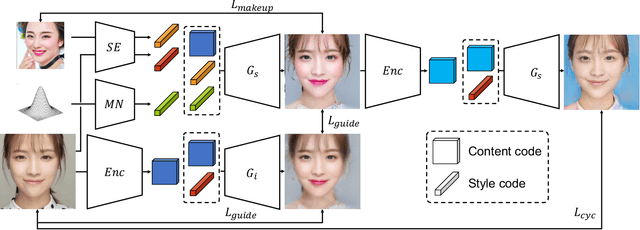


There are five features to consider when using generative adversarial networks to apply makeup to photos of the human face. These features include (1) facial components, (2) interactive color adjustments, (3) makeup variations, (4) robustness to poses and expressions, and the (5) use of multiple reference images. Several related works have been proposed, mainly using generative adversarial networks (GAN). Unfortunately, none of them have addressed all five features simultaneously. This paper closes the gap with an innovative style- and latent-guided GAN (SLGAN). We provide a novel, perceptual makeup loss and a style-invariant decoder that can transfer makeup styles based on histogram matching to avoid the identity-shift problem. In our experiments, we show that our SLGAN is better than or comparable to state-of-the-art methods. Furthermore, we show that our proposal can interpolate facial makeup images to determine the unique features, compare existing methods, and help users find desirable makeup configurations.