 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemusic generation
Music generation is the task of generating music or music-like sounds from a model or algorithm.
Papers and Code
Pairwise and Attribute-Aware Decision Tree-Based Preference Elicitation for Cold-Start Recommendation
Oct 31, 2025


Recommender systems (RSs) are intelligent filtering methods that suggest items to users based on their inferred preferences, derived from their interaction history on the platform. Collaborative filtering-based RSs rely on users past interactions to generate recommendations. However, when a user is new to the platform, referred to as a cold-start user, there is no historical data available, making it difficult to provide personalized recommendations. To address this, rating elicitation techniques can be used to gather initial ratings or preferences on selected items, helping to build an early understanding of the user's tastes. Rating elicitation approaches are generally categorized into two types: non-personalized and personalized. Decision tree-based rating elicitation is a personalized method that queries users about their preferences at each node of the tree until sufficient information is gathered. In this paper, we propose an extension to the decision tree approach for rating elicitation in the context of music recommendation. Our method: (i) elicits not only item ratings but also preferences on attributes such as genres to better cluster users, and (ii) uses item pairs instead of single items at each node to more effectively learn user preferences. Experimental results demonstrate that both proposed enhancements lead to improved performance, particularly with a reduced number of queries.
AnyAccomp: Generalizable Accompaniment Generation via Quantized Melodic Bottleneck
Sep 17, 2025
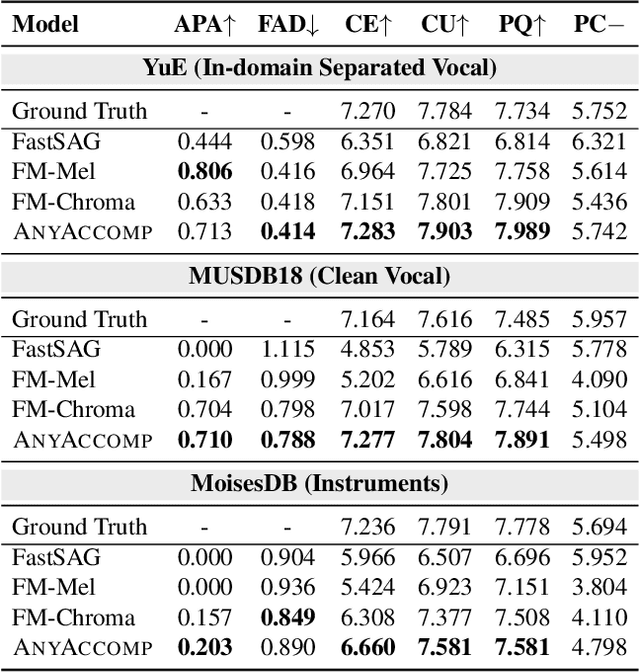
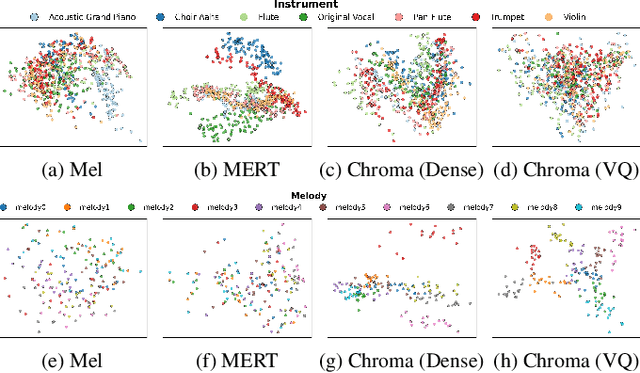
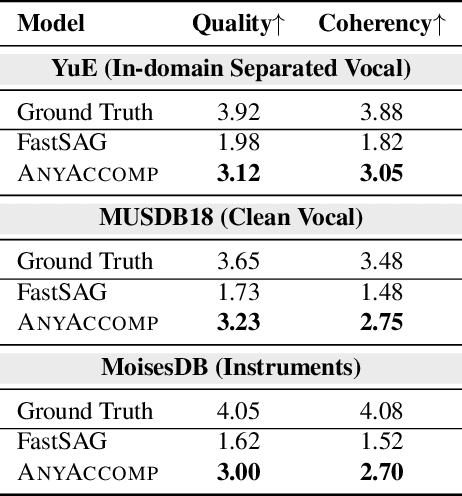
Singing Accompaniment Generation (SAG) is the process of generating instrumental music for a given clean vocal input. However, existing SAG techniques use source-separated vocals as input and overfit to separation artifacts. This creates a critical train-test mismatch, leading to failure on clean, real-world vocal inputs. We introduce AnyAccomp, a framework that resolves this by decoupling accompaniment generation from source-dependent artifacts. AnyAccomp first employs a quantized melodic bottleneck, using a chromagram and a VQ-VAE to extract a discrete and timbre-invariant representation of the core melody. A subsequent flow-matching model then generates the accompaniment conditioned on these robust codes. Experiments show AnyAccomp achieves competitive performance on separated-vocal benchmarks while significantly outperforming baselines on generalization test sets of clean studio vocals and, notably, solo instrumental tracks. This demonstrates a qualitative leap in generalization, enabling robust accompaniment for instruments - a task where existing models completely fail - and paving the way for more versatile music co-creation tools. Demo audio and code: https://anyaccomp.github.io
Real-world Music Plagiarism Detection With Music Segment Transcription System
Sep 10, 2025As a result of continuous advances in Music Information Retrieval (MIR) technology, generating and distributing music has become more diverse and accessible. In this context, interest in music intellectual property protection is increasing to safeguard individual music copyrights. In this work, we propose a system for detecting music plagiarism by combining various MIR technologies. We developed a music segment transcription system that extracts musically meaningful segments from audio recordings to detect plagiarism across different musical formats. With this system, we compute similarity scores based on multiple musical features that can be evaluated through comprehensive musical analysis. Our approach demonstrated promising results in music plagiarism detection experiments, and the proposed method can be applied to real-world music scenarios. We also collected a Similar Music Pair (SMP) dataset for musical similarity research using real-world cases. The dataset are publicly available.
Jamendo-QA: A Large-Scale Music Question Answering Dataset
Sep 19, 2025We introduce Jamendo-QA, a large-scale dataset for Music Question Answering (Music-QA). The dataset is built on freely licensed tracks from the Jamendo platform and is automatically annotated using the Qwen-Omni model. Jamendo-QA provides question-answer pairs and captions aligned with music audio, enabling both supervised training and zero-shot evaluation. Our resource aims to fill the gap of music-specific QA datasets and foster further research in music understanding, retrieval, and generative applications. In addition to its scale, Jamendo-QA covers a diverse range of genres, instruments, and metadata attributes, allowing robust model benchmarking across varied musical contexts. We also provide detailed dataset statistics and highlight potential biases such as genre and gender imbalance to guide fair evaluation. We position Jamendo-QA as a scalable and publicly available benchmark that can facilitate future research in music understanding, multimodal modeling, and fair evaluation of music-oriented QA systems.
Amadeus: Autoregressive Model with Bidirectional Attribute Modelling for Symbolic Music
Aug 28, 2025Existing state-of-the-art symbolic music generation models predominantly adopt autoregressive or hierarchical autoregressive architectures, modelling symbolic music as a sequence of attribute tokens with unidirectional temporal dependencies, under the assumption of a fixed, strict dependency structure among these attributes. However, we observe that using different attributes as the initial token in these models leads to comparable performance. This suggests that the attributes of a musical note are, in essence, a concurrent and unordered set, rather than a temporally dependent sequence. Based on this insight, we introduce Amadeus, a novel symbolic music generation framework. Amadeus adopts a two-level architecture: an autoregressive model for note sequences and a bidirectional discrete diffusion model for attributes. To enhance performance, we propose Music Latent Space Discriminability Enhancement Strategy(MLSDES), incorporating contrastive learning constraints that amplify discriminability of intermediate music representations. The Conditional Information Enhancement Module (CIEM) simultaneously strengthens note latent vector representation via attention mechanisms, enabling more precise note decoding. We conduct extensive experiments on unconditional and text-conditioned generation tasks. Amadeus significantly outperforms SOTA models across multiple metrics while achieving at least 4$\times$ speed-up. Furthermore, we demonstrate training-free, fine-grained note attribute control feasibility using our model. To explore the upper performance bound of the Amadeus architecture, we compile the largest open-source symbolic music dataset to date, AMD (Amadeus MIDI Dataset), supporting both pre-training and fine-tuning.
Opening Musical Creativity? Embedded Ideologies in Generative-AI Music Systems
Aug 12, 2025

AI systems for music generation are increasingly common and easy to use, granting people without any musical background the ability to create music. Because of this, generative-AI has been marketed and celebrated as a means of democratizing music making. However, inclusivity often functions as marketable rhetoric rather than a genuine guiding principle in these industry settings. In this paper, we look at four generative-AI music making systems available to the public as of mid-2025 (AIVA, Stable Audio, Suno, and Udio) and track how they are rhetoricized by their developers, and received by users. Our aim is to investigate ideologies that are driving the early-stage development and adoption of generative-AI in music making, with a particular focus on democratization. A combination of autoethnography and digital ethnography is used to examine patterns and incongruities in rhetoric when positioned against product functionality. The results are then collated to develop a nuanced, contextual discussion. The shared ideology we map between producers and consumers is individualist, globalist, techno-liberal, and ethically evasive. It is a 'total ideology' which obfuscates individual responsibility, and through which the nature of music and musical practice is transfigured to suit generative outcomes.
MDD: A Dataset for Text-and-Music Conditioned Duet Dance Generation
Aug 23, 2025We introduce Multimodal DuetDance (MDD), a diverse multimodal benchmark dataset designed for text-controlled and music-conditioned 3D duet dance motion generation. Our dataset comprises 620 minutes of high-quality motion capture data performed by professional dancers, synchronized with music, and detailed with over 10K fine-grained natural language descriptions. The annotations capture a rich movement vocabulary, detailing spatial relationships, body movements, and rhythm, making MDD the first dataset to seamlessly integrate human motions, music, and text for duet dance generation. We introduce two novel tasks supported by our dataset: (1) Text-to-Duet, where given music and a textual prompt, both the leader and follower dance motion are generated (2) Text-to-Dance Accompaniment, where given music, textual prompt, and the leader's motion, the follower's motion is generated in a cohesive, text-aligned manner. We include baseline evaluations on both tasks to support future research.
From Language to Locomotion: Retargeting-free Humanoid Control via Motion Latent Guidance
Oct 16, 2025Natural language offers a natural interface for humanoid robots, but existing language-guided humanoid locomotion pipelines remain cumbersome and unreliable. They typically decode human motion, retarget it to robot morphology, and then track it with a physics-based controller. However, this multi-stage process is prone to cumulative errors, introduces high latency, and yields weak coupling between semantics and control. These limitations call for a more direct pathway from language to action, one that eliminates fragile intermediate stages. Therefore, we present RoboGhost, a retargeting-free framework that directly conditions humanoid policies on language-grounded motion latents. By bypassing explicit motion decoding and retargeting, RoboGhost enables a diffusion-based policy to denoise executable actions directly from noise, preserving semantic intent and supporting fast, reactive control. A hybrid causal transformer-diffusion motion generator further ensures long-horizon consistency while maintaining stability and diversity, yielding rich latent representations for precise humanoid behavior. Extensive experiments demonstrate that RoboGhost substantially reduces deployment latency, improves success rates and tracking accuracy, and produces smooth, semantically aligned locomotion on real humanoids. Beyond text, the framework naturally extends to other modalities such as images, audio, and music, providing a general foundation for vision-language-action humanoid systems.
Video Object Segmentation-Aware Audio Generation
Sep 30, 2025



Existing multimodal audio generation models often lack precise user control, which limits their applicability in professional Foley workflows. In particular, these models focus on the entire video and do not provide precise methods for prioritizing a specific object within a scene, generating unnecessary background sounds, or focusing on the wrong objects. To address this gap, we introduce the novel task of video object segmentation-aware audio generation, which explicitly conditions sound synthesis on object-level segmentation maps. We present SAGANet, a new multimodal generative model that enables controllable audio generation by leveraging visual segmentation masks along with video and textual cues. Our model provides users with fine-grained and visually localized control over audio generation. To support this task and further research on segmentation-aware Foley, we propose Segmented Music Solos, a benchmark dataset of musical instrument performance videos with segmentation information. Our method demonstrates substantial improvements over current state-of-the-art methods and sets a new standard for controllable, high-fidelity Foley synthesis. Code, samples, and Segmented Music Solos are available at https://saganet.notion.site
Contrastive timbre representations for musical instrument and synthesizer retrieval
Sep 16, 2025



Efficiently retrieving specific instrument timbres from audio mixtures remains a challenge in digital music production. This paper introduces a contrastive learning framework for musical instrument retrieval, enabling direct querying of instrument databases using a single model for both single- and multi-instrument sounds. We propose techniques to generate realistic positive/negative pairs of sounds for virtual musical instruments, such as samplers and synthesizers, addressing limitations in common audio data augmentation methods. The first experiment focuses on instrument retrieval from a dataset of 3,884 instruments, using single-instrument audio as input. Contrastive approaches are competitive with previous works based on classification pre-training. The second experiment considers multi-instrument retrieval with a mixture of instruments as audio input. In this case, the proposed contrastive framework outperforms related works, achieving 81.7\% top-1 and 95.7\% top-5 accuracies for three-instrument mixtures.