 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgefacial recognition
Facial recognition is an AI-based technique for identifying or confirming an individual's identity using their face. It maps facial features from an image or video and then compares the information with a collection of known faces to find a match.
Papers and Code
Batch Transformer Architecture: Case of Synthetic Image Generation for Emotion Expression Facial Recognition
Nov 13, 2025A novel Transformer variation architecture is proposed in the implicit sparse style. Unlike "traditional" Transformers, instead of attention to sequential or batch entities in their entirety of whole dimensionality, in the proposed Batch Transformers, attention to the "important" dimensions (primary components) is implemented. In such a way, the "important" dimensions or feature selection allows for a significant reduction of the bottleneck size in the encoder-decoder ANN architectures. The proposed architecture is tested on the synthetic image generation for the face recognition task in the case of the makeup and occlusion data set, allowing for increased variability of the limited original data set.
FD-MAD: Frequency-Domain Residual Analysis for Face Morphing Attack Detection
Jan 28, 2026Face morphing attacks present a significant threat to face recognition systems used in electronic identity enrolment and border control, particularly in single-image morphing attack detection (S-MAD) scenarios where no trusted reference is available. In spite of the vast amount of research on this problem, morph detection systems struggle in cross-dataset scenarios. To address this problem, we introduce a region-aware frequency-based morph detection strategy that drastically improves over strong baseline methods in challenging cross-dataset and cross-morph settings using a lightweight approach. Having observed the separability of bona fide and morph samples in the frequency domain of different facial parts, our approach 1) introduces the concept of residual frequency domain, where the frequency of the signal is decoupled from the natural spectral decay to easily discriminate between morph and bona fide data; 2) additionally, we reason in a global and local manner by combining the evidence from different facial regions in a Markov Random Field, which infers a globally consistent decision. The proposed method, trained exclusively on the synthetic morphing attack detection development dataset (SMDD), is evaluated in challenging cross-dataset and cross-morph settings on FRLL-Morph and MAD22 sets. Our approach achieves an average equal error rate (EER) of 1.85\% on FRLL-Morph and ranks second on MAD22 with an average EER of 6.12\%, while also obtaining a good bona fide presentation classification error rate (BPCER) at a low attack presentation classification error rate (APCER) using only spectral features. These findings indicate that Fourier-domain residual modeling with structured regional fusion offers a competitive alternative to deep S-MAD architectures.
Detection of Digital Facial Retouching utilizing Face Beauty Information
Dec 09, 2025



Facial retouching to beautify images is widely spread in social media, advertisements, and it is even applied in professional photo studios to let individuals appear younger, remove wrinkles and skin impurities. Generally speaking, this is done to enhance beauty. This is not a problem itself, but when retouched images are used as biometric samples and enrolled in a biometric system, it is one. Since previous work has proven facial retouching to be a challenge for face recognition systems,the detection of facial retouching becomes increasingly necessary. This work proposes to study and analyze changes in beauty assessment algorithms of retouched images, assesses different feature extraction methods based on artificial intelligence in order to improve retouching detection, and evaluates whether face beauty can be exploited to enhance the detection rate. In a scenario where the attacking retouching algorithm is unknown, this work achieved 1.1% D-EER on single image detection.
Facial-R1: Aligning Reasoning and Recognition for Facial Emotion Analysis
Nov 13, 2025



Facial Emotion Analysis (FEA) extends traditional facial emotion recognition by incorporating explainable, fine-grained reasoning. The task integrates three subtasks: emotion recognition, facial Action Unit (AU) recognition, and AU-based emotion reasoning to model affective states jointly. While recent approaches leverage Vision-Language Models (VLMs) and achieve promising results, they face two critical limitations: (1) hallucinated reasoning, where VLMs generate plausible but inaccurate explanations due to insufficient emotion-specific knowledge; and (2) misalignment between emotion reasoning and recognition, caused by fragmented connections between observed facial features and final labels. We propose Facial-R1, a three-stage alignment framework that effectively addresses both challenges with minimal supervision. First, we employ instruction fine-tuning to establish basic emotional reasoning capability. Second, we introduce reinforcement training guided by emotion and AU labels as reward signals, which explicitly aligns the generated reasoning process with the predicted emotion. Third, we design a data synthesis pipeline that iteratively leverages the prior stages to expand the training dataset, enabling scalable self-improvement of the model. Built upon this framework, we introduce FEA-20K, a benchmark dataset comprising 17,737 training and 1,688 test samples with fine-grained emotion analysis annotations. Extensive experiments across eight standard benchmarks demonstrate that Facial-R1 achieves state-of-the-art performance in FEA, with strong generalization and robust interpretability.
Global Multiple Extraction Network for Low-Resolution Facial Expression Recognition
Nov 08, 2025Facial expression recognition, as a vital computer vision task, is garnering significant attention and undergoing extensive research. Although facial expression recognition algorithms demonstrate impressive performance on high-resolution images, their effectiveness tends to degrade when confronted with low-resolution images. We find it is because: 1) low-resolution images lack detail information; 2) current methods complete weak global modeling, which make it difficult to extract discriminative features. To alleviate the above issues, we proposed a novel global multiple extraction network (GME-Net) for low-resolution facial expression recognition, which incorporates 1) a hybrid attention-based local feature extraction module with attention similarity knowledge distillation to learn image details from high-resolution network; 2) a multi-scale global feature extraction module with quasi-symmetric structure to mitigate the influence of local image noise and facilitate capturing global image features. As a result, our GME-Net is capable of extracting expression-related discriminative features. Extensive experiments conducted on several widely-used datasets demonstrate that the proposed GME-Net can better recognize low-resolution facial expression and obtain superior performance than existing solutions.
Text-guided Weakly Supervised Framework for Dynamic Facial Expression Recognition
Nov 14, 2025Dynamic facial expression recognition (DFER) aims to identify emotional states by modeling the temporal changes in facial movements across video sequences. A key challenge in DFER is the many-to-one labeling problem, where a video composed of numerous frames is assigned a single emotion label. A common strategy to mitigate this issue is to formulate DFER as a Multiple Instance Learning (MIL) problem. However, MIL-based approaches inherently suffer from the visual diversity of emotional expressions and the complexity of temporal dynamics. To address this challenge, we propose TG-DFER, a text-guided weakly supervised framework that enhances MIL-based DFER by incorporating semantic guidance and coherent temporal modeling. We incorporate a vision-language pre-trained (VLP) model is integrated to provide semantic guidance through fine-grained textual descriptions of emotional context. Furthermore, we introduce visual prompts, which align enriched textual emotion labels with visual instance features, enabling fine-grained reasoning and frame-level relevance estimation. In addition, a multi-grained temporal network is designed to jointly capture short-term facial dynamics and long-range emotional flow, ensuring coherent affective understanding across time. Extensive results demonstrate that TG-DFER achieves improved generalization, interpretability, and temporal sensitivity under weak supervision.
Facial Expression Recognition with YOLOv11 and YOLOv12: A Comparative Study
Nov 14, 2025



Facial Expression Recognition remains a challenging task, especially in unconstrained, real-world environments. This study investigates the performance of two lightweight models, YOLOv11n and YOLOv12n, which are the nano variants of the latest official YOLO series, within a unified detection and classification framework for FER. Two benchmark classification datasets, FER2013 and KDEF, are converted into object detection format and model performance is evaluated using mAP 0.5, precision, recall, and confusion matrices. Results show that YOLOv12n achieves the highest overall performance on the clean KDEF dataset with a mAP 0.5 of 95.6, and also outperforms YOLOv11n on the FER2013 dataset in terms of mAP 63.8, reflecting stronger sensitivity to varied expressions. In contrast, YOLOv11n demonstrates higher precision 65.2 on FER2013, indicating fewer false positives and better reliability in noisy, real-world conditions. On FER2013, both models show more confusion between visually similar expressions, while clearer class separation is observed on the cleaner KDEF dataset. These findings underscore the trade-off between sensitivity and precision, illustrating how lightweight YOLO models can effectively balance performance and efficiency. The results demonstrate adaptability across both controlled and real-world conditions, establishing these models as strong candidates for real-time, resource-constrained emotion-aware AI applications.
CLIP-FTI: Fine-Grained Face Template Inversion via CLIP-Driven Attribute Conditioning
Dec 17, 2025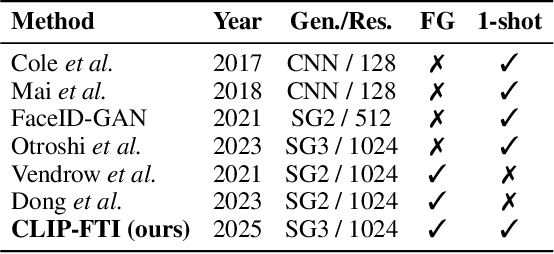
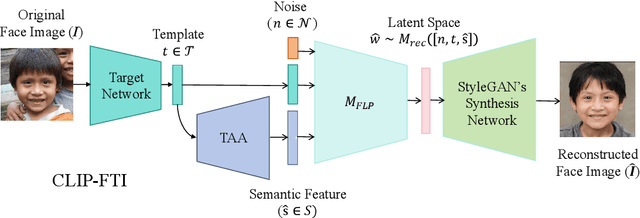
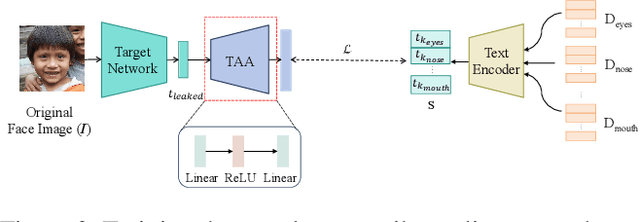
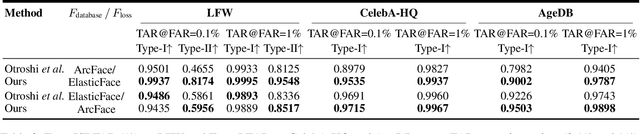
Face recognition systems store face templates for efficient matching. Once leaked, these templates pose a threat: inverting them can yield photorealistic surrogates that compromise privacy and enable impersonation. Although existing research has achieved relatively realistic face template inversion, the reconstructed facial images exhibit over-smoothed facial-part attributes (eyes, nose, mouth) and limited transferability. To address this problem, we present CLIP-FTI, a CLIP-driven fine-grained attribute conditioning framework for face template inversion. Our core idea is to use the CLIP model to obtain the semantic embeddings of facial features, in order to realize the reconstruction of specific facial feature attributes. Specifically, facial feature attribute embeddings extracted from CLIP are fused with the leaked template via a cross-modal feature interaction network and projected into the intermediate latent space of a pretrained StyleGAN. The StyleGAN generator then synthesizes face images with the same identity as the templates but with more fine-grained facial feature attributes. Experiments across multiple face recognition backbones and datasets show that our reconstructions (i) achieve higher identification accuracy and attribute similarity, (ii) recover sharper component-level attribute semantics, and (iii) improve cross-model attack transferability compared to prior reconstruction attacks. To the best of our knowledge, ours is the first method to use additional information besides the face template attack to realize face template inversion and obtains SOTA results.
OmniMER: Indonesian Multimodal Emotion Recognition via Auxiliary-Enhanced LLM Adaptation
Dec 22, 2025Indonesian, spoken by over 200 million people, remains underserved in multimodal emotion recognition research despite its dominant presence on Southeast Asian social media platforms. We introduce IndoMER, the first multimodal emotion recognition benchmark for Indonesian, comprising 1,944 video segments from 203 speakers with temporally aligned text, audio, and visual annotations across seven emotion categories. The dataset exhibits realistic challenges including cross-modal inconsistency and long-tailed class distributions shaped by Indonesian cultural communication norms. To address these challenges, we propose OmniMER, a multimodal adaptation framework built upon Qwen2.5-Omni that enhances emotion recognition through three auxiliary modality-specific perception tasks: emotion keyword extraction for text, facial expression analysis for video, and prosody analysis for audio. These auxiliary tasks help the model identify emotion-relevant cues in each modality before fusion, reducing reliance on spurious correlations in low-resource settings. Experiments on IndoMER show that OmniMER achieves 0.582 Macro-F1 on sentiment classification and 0.454 on emotion recognition, outperforming the base model by 7.6 and 22.1 absolute points respectively. Cross-lingual evaluation on the Chinese CH-SIMS dataset further demonstrates the generalizability of the proposed framework. The dataset and code are publicly available. https://github.com/yanxm01/INDOMER
Emotion Recognition in Signers
Dec 17, 2025Recognition of signers' emotions suffers from one theoretical challenge and one practical challenge, namely, the overlap between grammatical and affective facial expressions and the scarcity of data for model training. This paper addresses these two challenges in a cross-lingual setting using our eJSL dataset, a new benchmark dataset for emotion recognition in Japanese Sign Language signers, and BOBSL, a large British Sign Language dataset with subtitles. In eJSL, two signers expressed 78 distinct utterances with each of seven different emotional states, resulting in 1,092 video clips. We empirically demonstrate that 1) textual emotion recognition in spoken language mitigates data scarcity in sign language, 2) temporal segment selection has a significant impact, and 3) incorporating hand motion enhances emotion recognition in signers. Finally we establish a stronger baseline than spoken language LLMs.