 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWinogender Schemas
Papers and Code
Revisiting English Winogender Schemas for Consistency, Coverage, and Grammatical Case
Sep 09, 2024



While measuring bias and robustness in coreference resolution are important goals, such measurements are only as good as the tools we use to measure them with. Winogender schemas (Rudinger et al., 2018) are an influential dataset proposed to evaluate gender bias in coreference resolution, but a closer look at the data reveals issues with the instances that compromise their use for reliable evaluation, including treating different grammatical cases of pronouns in the same way, violations of template constraints, and typographical errors. We identify these issues and fix them, contributing a new dataset: Winogender 2.0. Our changes affect performance with state-of-the-art supervised coreference resolution systems as well as all model sizes of the language model FLAN-T5, with F1 dropping on average 0.1 points. We also propose a new method to evaluate pronominal bias in coreference resolution that goes beyond the binary. With this method and our new dataset which is balanced for grammatical case, we empirically demonstrate that bias characteristics vary not just across pronoun sets, but also across surface forms of those sets.
VisoGender: A dataset for benchmarking gender bias in image-text pronoun resolution
Jun 21, 2023



We introduce VisoGender, a novel dataset for benchmarking gender bias in vision-language models. We focus on occupation-related gender biases, inspired by Winograd and Winogender schemas, where each image is associated with a caption containing a pronoun relationship of subjects and objects in the scene. VisoGender is balanced by gender representation in professional roles, supporting bias evaluation in two ways: i) resolution bias, where we evaluate the difference between gender resolution accuracies for men and women and ii) retrieval bias, where we compare ratios of male and female professionals retrieved for a gender-neutral search query. We benchmark several state-of-the-art vision-language models and find that they lack the reasoning abilities to correctly resolve gender in complex scenes. While the direction and magnitude of gender bias depends on the task and the model being evaluated, captioning models generally are more accurate and less biased than CLIP-like models. Dataset and code are available at https://github.com/oxai/visogender
Discovering Language Model Behaviors with Model-Written Evaluations
Dec 19, 2022



As language models (LMs) scale, they develop many novel behaviors, good and bad, exacerbating the need to evaluate how they behave. Prior work creates evaluations with crowdwork (which is time-consuming and expensive) or existing data sources (which are not always available). Here, we automatically generate evaluations with LMs. We explore approaches with varying amounts of human effort, from instructing LMs to write yes/no questions to making complex Winogender schemas with multiple stages of LM-based generation and filtering. Crowdworkers rate the examples as highly relevant and agree with 90-100% of labels, sometimes more so than corresponding human-written datasets. We generate 154 datasets and discover new cases of inverse scaling where LMs get worse with size. Larger LMs repeat back a dialog user's preferred answer ("sycophancy") and express greater desire to pursue concerning goals like resource acquisition and goal preservation. We also find some of the first examples of inverse scaling in RL from Human Feedback (RLHF), where more RLHF makes LMs worse. For example, RLHF makes LMs express stronger political views (on gun rights and immigration) and a greater desire to avoid shut down. Overall, LM-written evaluations are high-quality and let us quickly discover many novel LM behaviors.
Bipol: Multi-axes Evaluation of Bias with Explainability in Benchmark Datasets
Jan 28, 2023



We evaluate five English NLP benchmark datasets (available on the superGLUE leaderboard) for bias, along multiple axes. The datasets are the following: Boolean Question (Boolq), CommitmentBank (CB), Winograd Schema Challenge (WSC), Winogender diagnostic (AXg), and Recognising Textual Entailment (RTE). Bias can be harmful and it is known to be common in data, which ML models learn from. In order to mitigate bias in data, it is crucial to be able to estimate it objectively. We use bipol, a novel multi-axes bias metric with explainability, to quantify and explain how much bias exists in these datasets. Multilingual, multi-axes bias evaluation is not very common. Hence, we also contribute a new, large labelled Swedish bias-detection dataset, with about 2 million samples; translated from the English version. In addition, we contribute new multi-axes lexica for bias detection in Swedish. We train a SotA model on the new dataset for bias detection. We make the codes, model, and new dataset publicly available.
Exploiting Selection Bias on Underspecified Tasks in Large Language Models
Sep 30, 2022



In this paper we motivate the causal mechanisms behind sample selection induced collider bias (selection collider bias) that can cause Large Language Models (LLMs) to learn unconditional dependence between entities that are unconditionally independent in the real world. We show that selection collider bias can become amplified in underspecified learning tasks, and although difficult to overcome, we describe a method to exploit the resulting spurious correlations for determination of when a model may be uncertain about its prediction. We demonstrate an uncertainty metric that matches human uncertainty in tasks with gender pronoun underspecification on an extended version of the Winogender Schemas evaluation set, and we provide online demos where users can evaluate spurious correlations and apply our uncertainty metric to their own texts and models. Finally, we generalize our approach to address a wider range of prediction tasks.
Selection Collider Bias in Large Language Models
Aug 22, 2022



In this paper we motivate the causal mechanisms behind sample selection induced collider bias (selection collider bias) that can cause Large Language Models (LLMs) to learn unconditional dependence between entities that are unconditionally independent in the real world. We show that selection collider bias can be amplified in underspecified learning tasks, and that the magnitude of the resulting spurious correlations appear scale agnostic. While selection collider bias can be difficult to overcome, we describe a method to exploit the resulting spurious correlations for determination of when a model may be uncertain about its prediction, and demonstrate that it matches human uncertainty in tasks with gender pronoun underspecification on an extended version of the Winogender Schemas evaluation set.
Gender Bias in Coreference Resolution
Apr 25, 2018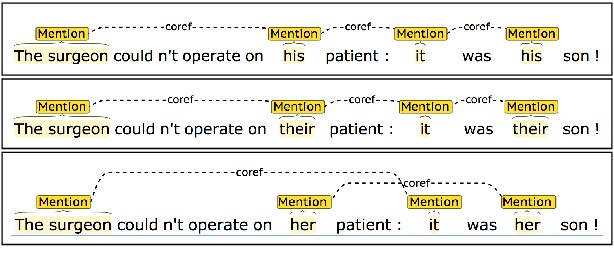
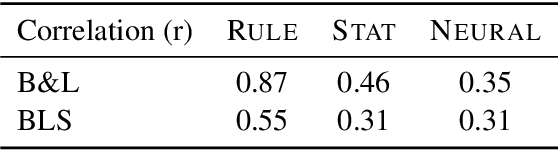


We present an empirical study of gender bias in coreference resolution systems. We first introduce a novel, Winograd schema-style set of minimal pair sentences that differ only by pronoun gender. With these "Winogender schemas," we evaluate and confirm systematic gender bias in three publicly-available coreference resolution systems, and correlate this bias with real-world and textual gender statistics.