 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvocation: Who benefits from "inclusion" in Generative AI?
Nov 14, 2024
The demands for accurate and representative generative AI systems means there is an increased demand on participatory evaluation structures. While these participatory structures are paramount to to ensure non-dominant values, knowledge and material culture are also reflected in AI models and the media they generate, we argue that dominant structures of community participation in AI development and evaluation are not explicit enough about the benefits and harms that members of socially marginalized groups may experience as a result of their participation. Without explicit interrogation of these benefits by AI developers, as a community we may remain blind to the immensity of systemic change that is needed as well. To support this provocation, we present a speculative case study, developed from our own collective experiences as AI researchers. We use this speculative context to itemize the barriers that need to be overcome in order for the proposed benefits to marginalized communities to be realized, and harms mitigated.
You are what you eat? Feeding foundation models a regionally diverse food dataset of World Wide Dishes
Jun 13, 2024Foundation models are increasingly ubiquitous in our daily lives, used in everyday tasks such as text-image searches, interactions with chatbots, and content generation. As use increases, so does concern over the disparities in performance and fairness of these models for different people in different parts of the world. To assess these growing regional disparities, we present World Wide Dishes, a mixed text and image dataset consisting of 765 dishes, with dish names collected in 131 local languages. World Wide Dishes has been collected purely through human contribution and decentralised means, by creating a website widely distributed through social networks. Using the dataset, we demonstrate a novel means of operationalising capability and representational biases in foundation models such as language models and text-to-image generative models. We enrich these studies with a pilot community review to understand, from a first-person perspective, how these models generate images for people in five African countries and the United States. We find that these models generally do not produce quality text and image outputs of dishes specific to different regions. This is true even for the US, which is typically considered to be more well-resourced in training data - though the generation of US dishes does outperform that of the investigated African countries. The models demonstrate a propensity to produce outputs that are inaccurate as well as culturally misrepresentative, flattening, and insensitive. These failures in capability and representational bias have the potential to further reinforce stereotypes and disproportionately contribute to erasure based on region. The dataset and code are available at https://github.com/oxai/world-wide-dishes/.
VisoGender: A dataset for benchmarking gender bias in image-text pronoun resolution
Jun 21, 2023



We introduce VisoGender, a novel dataset for benchmarking gender bias in vision-language models. We focus on occupation-related gender biases, inspired by Winograd and Winogender schemas, where each image is associated with a caption containing a pronoun relationship of subjects and objects in the scene. VisoGender is balanced by gender representation in professional roles, supporting bias evaluation in two ways: i) resolution bias, where we evaluate the difference between gender resolution accuracies for men and women and ii) retrieval bias, where we compare ratios of male and female professionals retrieved for a gender-neutral search query. We benchmark several state-of-the-art vision-language models and find that they lack the reasoning abilities to correctly resolve gender in complex scenes. While the direction and magnitude of gender bias depends on the task and the model being evaluated, captioning models generally are more accurate and less biased than CLIP-like models. Dataset and code are available at https://github.com/oxai/visogender
Balancing the Picture: Debiasing Vision-Language Datasets with Synthetic Contrast Sets
May 24, 2023Vision-language models are growing in popularity and public visibility to generate, edit, and caption images at scale; but their outputs can perpetuate and amplify societal biases learned during pre-training on uncurated image-text pairs from the internet. Although debiasing methods have been proposed, we argue that these measurements of model bias lack validity due to dataset bias. We demonstrate there are spurious correlations in COCO Captions, the most commonly used dataset for evaluating bias, between background context and the gender of people in-situ. This is problematic because commonly-used bias metrics (such as Bias@K) rely on per-gender base rates. To address this issue, we propose a novel dataset debiasing pipeline to augment the COCO dataset with synthetic, gender-balanced contrast sets, where only the gender of the subject is edited and the background is fixed. However, existing image editing methods have limitations and sometimes produce low-quality images; so, we introduce a method to automatically filter the generated images based on their similarity to real images. Using our balanced synthetic contrast sets, we benchmark bias in multiple CLIP-based models, demonstrating how metrics are skewed by imbalance in the original COCO images. Our results indicate that the proposed approach improves the validity of the evaluation, ultimately contributing to more realistic understanding of bias in vision-language models.
A Prompt Array Keeps the Bias Away: Debiasing Vision-Language Models with Adversarial Learning
Apr 01, 2022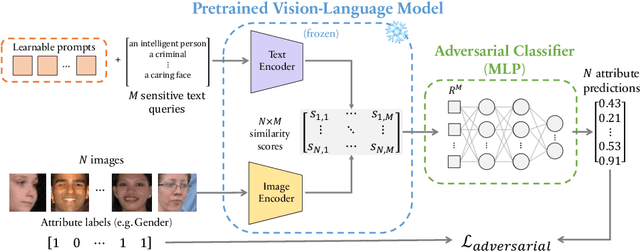

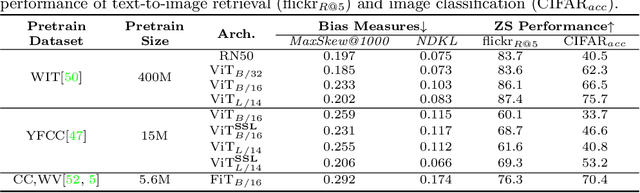

Vision-language models can encode societal biases and stereotypes, but there are challenges to measuring and mitigating these harms. Prior proposed bias measurements lack robustness and feature degradation occurs when mitigating bias without access to pretraining data. We address both of these challenges in this paper: First, we evaluate different bias measures and propose the use of retrieval metrics to image-text representations via a bias measuring framework. Second, we investigate debiasing methods and show that optimizing for adversarial loss via learnable token embeddings minimizes various bias measures without substantially degrading feature representations.