 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice Conversion Challenge 2018
Papers and Code
SVSNet+: Enhancing Speaker Voice Similarity Assessment Models with Representations from Speech Foundation Models
Jun 12, 2024



Representations from pre-trained speech foundation models (SFMs) have shown impressive performance in many downstream tasks. However, the potential benefits of incorporating pre-trained SFM representations into speaker voice similarity assessment have not been thoroughly investigated. In this paper, we propose SVSNet+, a model that integrates pre-trained SFM representations to improve performance in assessing speaker voice similarity. Experimental results on the Voice Conversion Challenge 2018 and 2020 datasets show that SVSNet+ incorporating WavLM representations shows significant improvements compared to baseline models. In addition, while fine-tuning WavLM with a small dataset of the downstream task does not improve performance, using the same dataset to learn a weighted-sum representation of WavLM can substantially improve performance. Furthermore, when WavLM is replaced by other SFMs, SVSNet+ still outperforms the baseline models and exhibits strong generalization ability.
Boosting Star-GANs for Voice Conversion with Contrastive Discriminator
Sep 27, 2022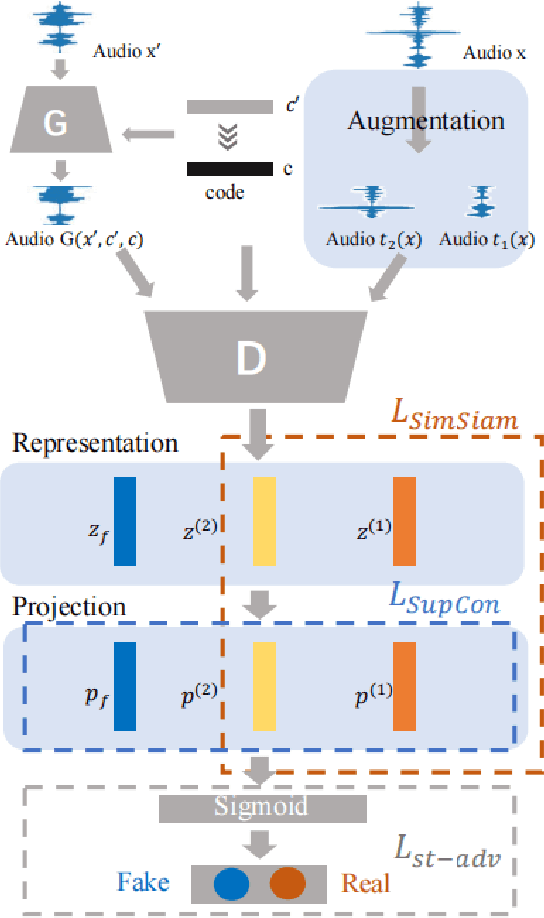


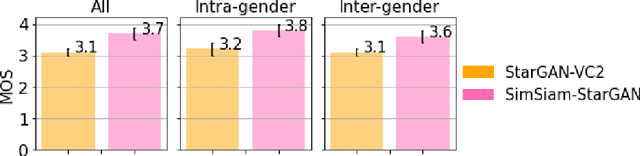
Nonparallel multi-domain voice conversion methods such as the StarGAN-VCs have been widely applied in many scenarios. However, the training of these models usually poses a challenge due to their complicated adversarial network architectures. To address this, in this work we leverage the state-of-the-art contrastive learning techniques and incorporate an efficient Siamese network structure into the StarGAN discriminator. Our method is called SimSiam-StarGAN-VC and it boosts the training stability and effectively prevents the discriminator overfitting issue in the training process. We conduct experiments on the Voice Conversion Challenge (VCC 2018) dataset, plus a user study to validate the performance of our framework. Our experimental results show that SimSiam-StarGAN-VC significantly outperforms existing StarGAN-VC methods in terms of both the objective and subjective metrics.
SVSNet: An End-to-end Speaker Voice Similarity Assessment Model
Jul 20, 2021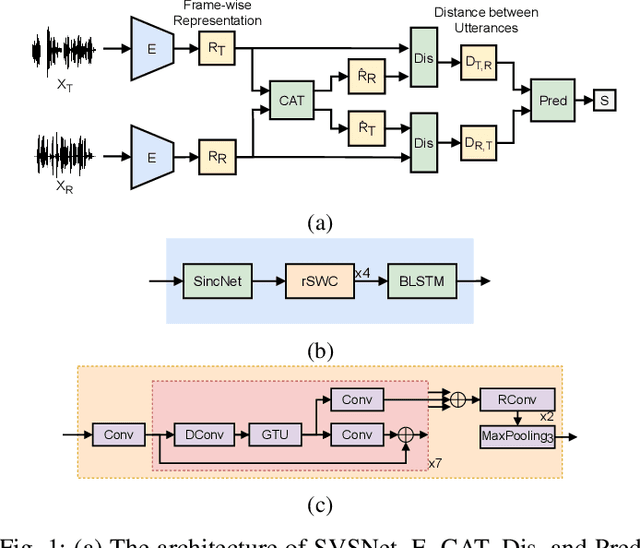
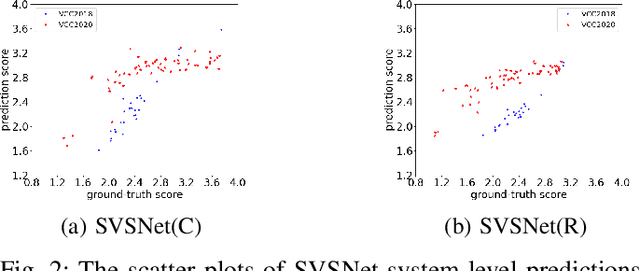
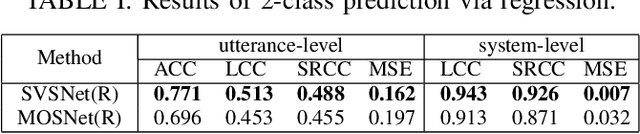
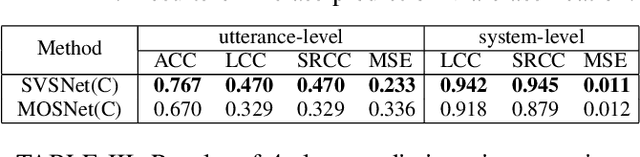
Neural evaluation metrics derived for numerous speech generation tasks have recently attracted great attention. In this paper, we propose SVSNet, the first end-to-end neural network model to assess the speaker voice similarity between natural speech and synthesized speech. Unlike most neural evaluation metrics that use hand-crafted features, SVSNet directly takes the raw waveform as input to more completely utilize speech information for prediction. SVSNet consists of encoder, co-attention, distance calculation, and prediction modules and is trained in an end-to-end manner. The experimental results on the Voice Conversion Challenge 2018 and 2020 (VCC2018 and VCC2020) datasets show that SVSNet notably outperforms well-known baseline systems in the assessment of speaker similarity at the utterance and system levels.
LDNet: Unified Listener Dependent Modeling in MOS Prediction for Synthetic Speech
Oct 18, 2021
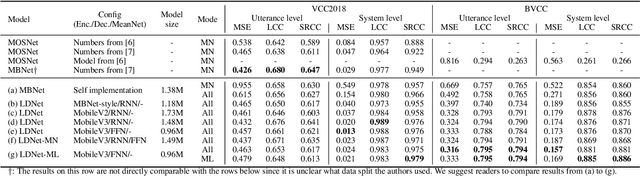
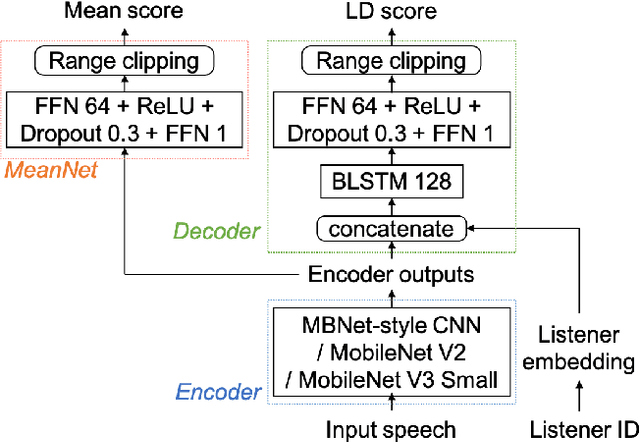
An effective approach to automatically predict the subjective rating for synthetic speech is to train on a listening test dataset with human-annotated scores. Although each speech sample in the dataset is rated by several listeners, most previous works only used the mean score as the training target. In this work, we present LDNet, a unified framework for mean opinion score (MOS) prediction that predicts the listener-wise perceived quality given the input speech and the listener identity. We reflect recent advances in LD modeling, including design choices of the model architecture, and propose two inference methods that provide more stable results and efficient computation. We conduct systematic experiments on the voice conversion challenge (VCC) 2018 benchmark and a newly collected large-scale MOS dataset, providing an in-depth analysis of the proposed framework. Results show that the mean listener inference method is a better way to utilize the mean scores, whose effectiveness is more obvious when having more ratings per sample.
Utilizing Self-supervised Representations for MOS Prediction
Apr 21, 2021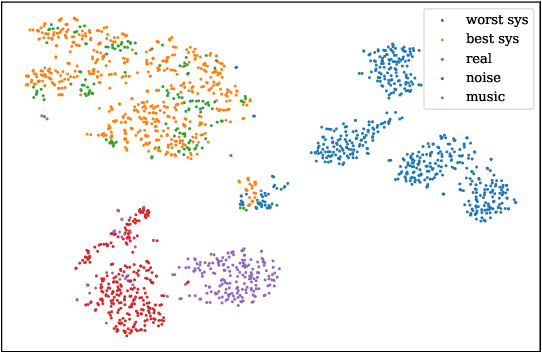
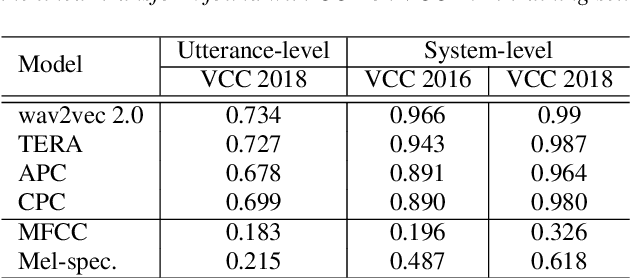
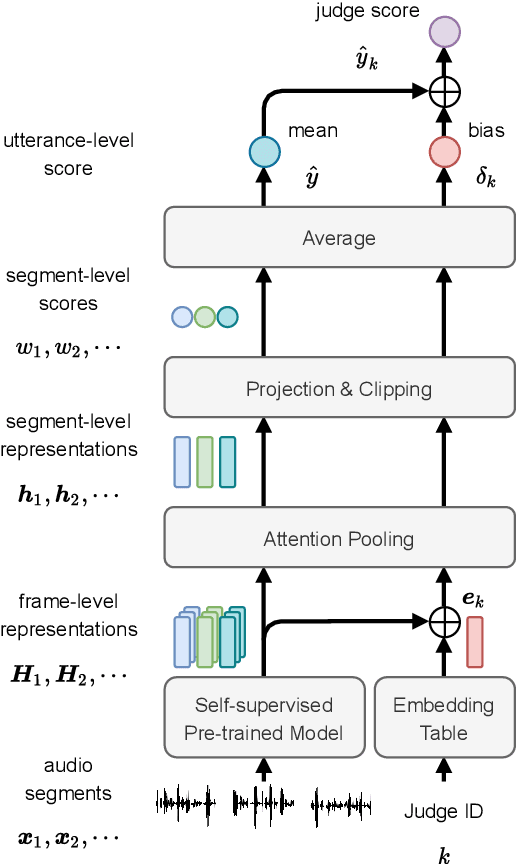
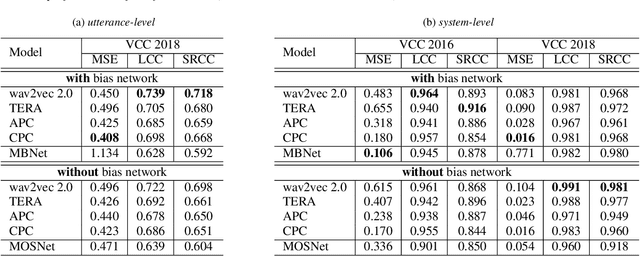
Speech quality assessment has been a critical issue in speech processing for decades. Existing automatic evaluations usually require clean references or parallel ground truth data, which is infeasible when the amount of data soars. Subjective tests, on the other hand, do not need any additional clean or parallel data and correlates better to human perception. However, such a test is expensive and time-consuming because crowd work is necessary. It thus becomes highly desired to develop an automatic evaluation approach that correlates well with human perception while not requiring ground truth data. In this paper, we use self-supervised pre-trained models for MOS prediction. We show their representations can distinguish between clean and noisy audios. Then, we fine-tune these pre-trained models followed by simple linear layers in an end-to-end manner. The experiment results showed that our framework outperforms the two previous state-of-the-art models by a significant improvement on Voice Conversion Challenge 2018 and achieves comparable or superior performance on Voice Conversion Challenge 2016. We also conducted an ablation study to further investigate how each module benefits the task. The experiment results are implemented and reproducible with publicly available toolkits.
Perceptually Guided End-to-End Text-to-Speech
Nov 02, 2020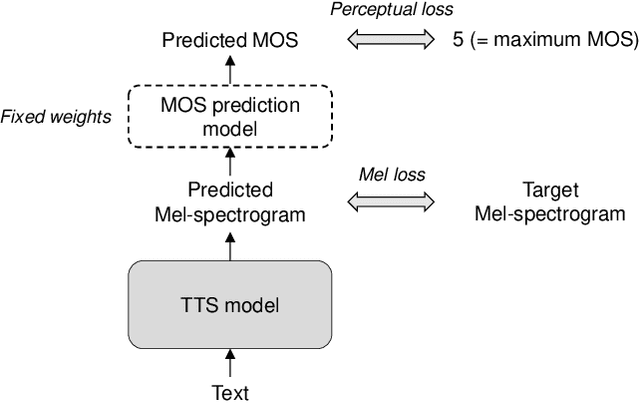
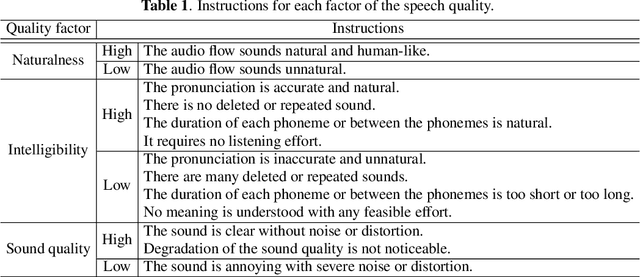
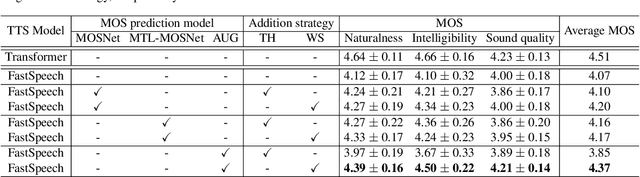
Several fast text-to-speech (TTS) models have been proposed for real-time processing, but there is room for improvement in speech quality. Meanwhile, there is a mismatch between the loss function for training and the mean opinion score (MOS) for evaluation, which may limit the speech quality of TTS models. In this work, we propose a method that can improve the speech quality of a fast TTS model while maintaining the inference speed. To do so, we train a TTS model using a perceptual loss based on the predicted MOS. Under the supervision of a MOS prediction model, a TTS model can learn to increase the perceptual quality of speech directly. In experiments, we train FastSpeech on our internal Korean dataset using the MOS prediction model pre-trained on the Voice Conversion Challenge 2018 evaluation results. The MOS test results show that our proposed approach outperforms FastSpeech in speech quality.
An Adaptive Learning based Generative Adversarial Network for One-To-One Voice Conversion
Apr 25, 2021



Voice Conversion (VC) emerged as a significant domain of research in the field of speech synthesis in recent years due to its emerging application in voice-assisting technology, automated movie dubbing, and speech-to-singing conversion to name a few. VC basically deals with the conversion of vocal style of one speaker to another speaker while keeping the linguistic contents unchanged. VC task is performed through a three-stage pipeline consisting of speech analysis, speech feature mapping, and speech reconstruction. Nowadays the Generative Adversarial Network (GAN) models are widely in use for speech feature mapping from source to target speaker. In this paper, we propose an adaptive learning-based GAN model called ALGAN-VC for an efficient one-to-one VC of speakers. Our ALGAN-VC framework consists of some approaches to improve the speech quality and voice similarity between source and target speakers. The model incorporates a Dense Residual Network (DRN) like architecture to the generator network for efficient speech feature learning, for source to target speech feature conversion. We also integrate an adaptive learning mechanism to compute the loss function for the proposed model. Moreover, we use a boosted learning rate approach to enhance the learning capability of the proposed model. The model is trained by using both forward and inverse mapping simultaneously for a one-to-one VC. The proposed model is tested on Voice Conversion Challenge (VCC) 2016, 2018, and 2020 datasets as well as on our self-prepared speech dataset, which has been recorded in Indian regional languages and in English. A subjective and objective evaluation of the generated speech samples indicated that the proposed model elegantly performed the voice conversion task by achieving high speaker similarity and adequate speech quality.
Deep MOS Predictor for Synthetic Speech Using Cluster-Based Modeling
Aug 09, 2020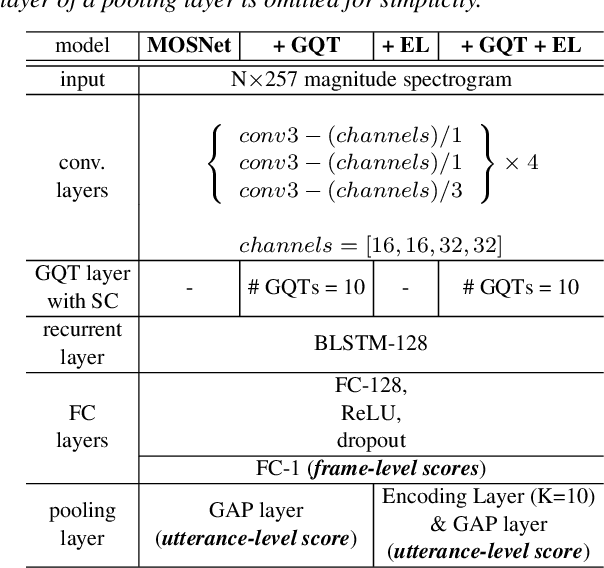

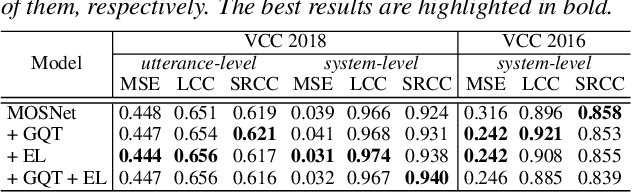
While deep learning has made impressive progress in speech synthesis and voice conversion, the assessment of the synthesized speech is still carried out by human participants. Several recent papers have proposed deep-learning-based assessment models and shown the potential to automate the speech quality assessment. To improve the previously proposed assessment model, MOSNet, we propose three models using cluster-based modeling methods: using a global quality token (GQT) layer, using an Encoding Layer, and using both of them. We perform experiments using the evaluation results of the Voice Conversion Challenge 2018 to predict the mean opinion score of synthesized speech and similarity score between synthesized speech and reference speech. The results show that the GQT layer helps to predict human assessment better by automatically learning the useful quality tokens for the task and that the Encoding Layer helps to utilize frame-level scores more precisely.
Neural MOS Prediction for Synthesized Speech Using Multi-Task Learning With Spoofing Detection and Spoofing Type Classification
Jul 16, 2020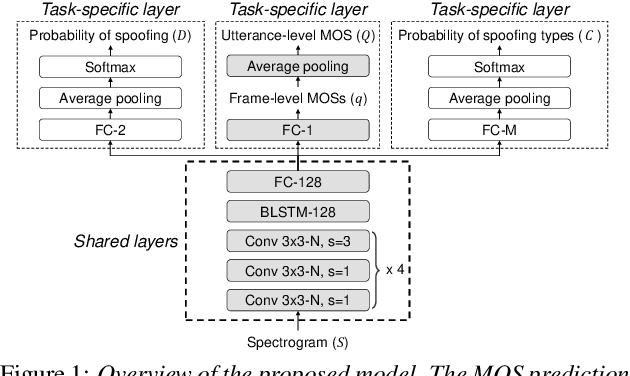
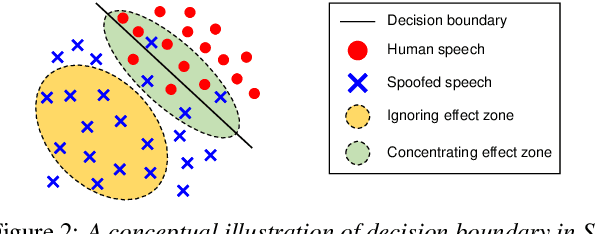
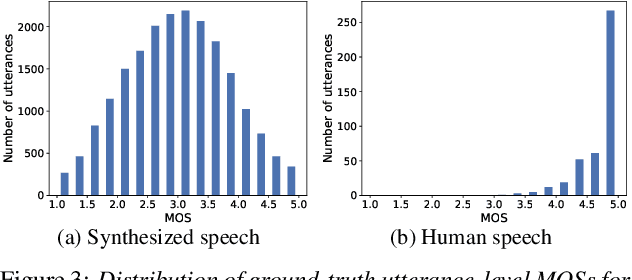
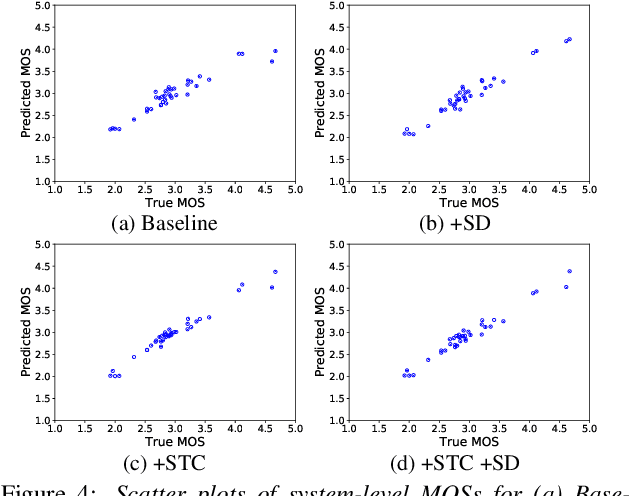
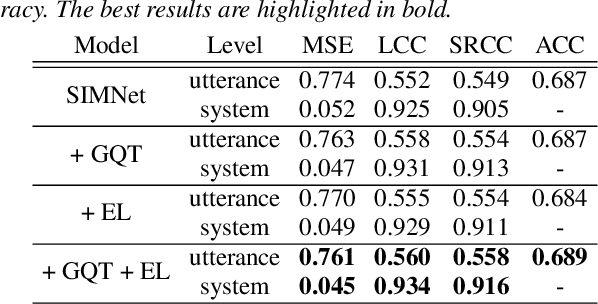
Several papers have proposed deep-learning-based models to predict the mean opinion score (MOS) of synthesized speech, showing the possibility of replacing human raters. However, inter- and intra-rater variability in MOSs makes it hard to ensure the generalization ability of the models. In this paper, we propose a method using multi-task learning (MTL) with spoofing detection (SD) and spoofing type classification (STC) to improve the generalization ability of a MOS prediction model. Besides, we use the focal loss to maximize the synergy between SD and STC for MOS prediction. Experiments using the results of the Voice Conversion Challenge 2018 show that proposed MTL with two auxiliary tasks improves MOS prediction.
SoftGAN: Learning generative models efficiently with application to CycleGAN Voice Conversion
Oct 22, 2019

Voice conversion with deep neural networks has become extremely popular over the last few years with improvements over the past VC architectures. In particular, GAN architectures such as the cycleGAN and the VAEGAN have offered the possibility to learn voice conversion from non-parallel databases. However, GAN-based methods are highly unstable, requiring often a careful tuning of hyper-parameters, and can lead to poor voice identity conversion and substantially degraded converted speech signal. This paper discusses and tackles the stability issues of the GAN in the context of voice conversion. The proposed SoftGAN method aims at reducing the impact of the generator on the discriminator and vice versa during training, so both can learn more gradually and efficiently during training, in particular avoiding a training not in tandem. A subjective experiment conducted on a voice conversion task on the voice conversion challenge 2018 dataset shows that the proposed SoftGAN significantly improves the quality of the voice conversion while preserving the naturalness of the converted speech.