 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualbert
Papers and Code
A Multimodal Approach to Heritage Preservation in the Context of Climate Change
Oct 15, 2025Cultural heritage sites face accelerating degradation due to climate change, yet tradi- tional monitoring relies on unimodal analysis (visual inspection or environmental sen- sors alone) that fails to capture the complex interplay between environmental stres- sors and material deterioration. We propose a lightweight multimodal architecture that fuses sensor data (temperature, humidity) with visual imagery to predict degradation severity at heritage sites. Our approach adapts PerceiverIO with two key innovations: (1) simplified encoders (64D latent space) that prevent overfitting on small datasets (n=37 training samples), and (2) Adaptive Barlow Twins loss that encourages modality complementarity rather than redundancy. On data from Strasbourg Cathedral, our model achieves 76.9% accu- racy, a 43% improvement over standard multimodal architectures (VisualBERT, Trans- former) and 25% over vanilla PerceiverIO. Ablation studies reveal that sensor-only achieves 61.5% while image-only reaches 46.2%, confirming successful multimodal synergy. A systematic hyperparameter study identifies an optimal moderate correlation target ({\tau} =0.3) that balances align- ment and complementarity, achieving 69.2% accuracy compared to other {\tau} values ({\tau} =0.1/0.5/0.7: 53.8%, {\tau} =0.9: 61.5%). This work demonstrates that architectural sim- plicity combined with contrastive regularization enables effective multimodal learning in data-scarce heritage monitoring contexts, providing a foundation for AI-driven con- servation decision support systems.
NLKI: A lightweight Natural Language Knowledge Integration Framework for Improving Small VLMs in Commonsense VQA Tasks
Aug 28, 2025Commonsense visual-question answering often hinges on knowledge that is missing from the image or the question. Small vision-language models (sVLMs) such as ViLT, VisualBERT and FLAVA therefore lag behind their larger generative counterparts. To study the effect of careful commonsense knowledge integration on sVLMs, we present an end-to-end framework (NLKI) that (i) retrieves natural language facts, (ii) prompts an LLM to craft natural language explanations, and (iii) feeds both signals to sVLMs respectively across two commonsense VQA datasets (CRIC, AOKVQA) and a visual-entailment dataset (e-SNLI-VE). Facts retrieved using a fine-tuned ColBERTv2 and an object information-enriched prompt yield explanations that largely cut down hallucinations, while lifting the end-to-end answer accuracy by up to 7% (across 3 datasets), making FLAVA and other models in NLKI match or exceed medium-sized VLMs such as Qwen-2 VL-2B and SmolVLM-2.5B. As these benchmarks contain 10-25% label noise, additional finetuning using noise-robust losses (such as symmetric cross entropy and generalised cross entropy) adds another 2.5% in CRIC, and 5.5% in AOKVQA. Our findings expose when LLM-based commonsense knowledge beats retrieval from commonsense knowledge bases, how noise-aware training stabilises small models in the context of external knowledge augmentation, and why parameter-efficient commonsense reasoning is now within reach for 250M models.
Visual Question Answering on Multiple Remote Sensing Image Modalities
May 21, 2025The extraction of visual features is an essential step in Visual Question Answering (VQA). Building a good visual representation of the analyzed scene is indeed one of the essential keys for the system to be able to correctly understand the latter in order to answer complex questions. In many fields such as remote sensing, the visual feature extraction step could benefit significantly from leveraging different image modalities carrying complementary spectral, spatial and contextual information. In this work, we propose to add multiple image modalities to VQA in the particular context of remote sensing, leading to a novel task for the computer vision community. To this end, we introduce a new VQA dataset, named TAMMI (Text and Multi-Modal Imagery) with diverse questions on scenes described by three different modalities (very high resolution RGB, multi-spectral imaging data and synthetic aperture radar). Thanks to an automated pipeline, this dataset can be easily extended according to experimental needs. We also propose the MM-RSVQA (Multi-modal Multi-resolution Remote Sensing Visual Question Answering) model, based on VisualBERT, a vision-language transformer, to effectively combine the multiple image modalities and text through a trainable fusion process. A preliminary experimental study shows promising results of our methodology on this challenging dataset, with an accuracy of 65.56% on the targeted VQA task. This pioneering work paves the way for the community to a new multi-modal multi-resolution VQA task that can be applied in other imaging domains (such as medical imaging) where multi-modality can enrich the visual representation of a scene. The dataset and code are available at https://tammi.sylvainlobry.com/.
Seeing Through VisualBERT: A Causal Adventure on Memetic Landscapes
Oct 17, 2024



Detecting offensive memes is crucial, yet standard deep neural network systems often remain opaque. Various input attribution-based methods attempt to interpret their behavior, but they face challenges with implicitly offensive memes and non-causal attributions. To address these issues, we propose a framework based on a Structural Causal Model (SCM). In this framework, VisualBERT is trained to predict the class of an input meme based on both meme input and causal concepts, allowing for transparent interpretation. Our qualitative evaluation demonstrates the framework's effectiveness in understanding model behavior, particularly in determining whether the model was right due to the right reason, and in identifying reasons behind misclassification. Additionally, quantitative analysis assesses the significance of proposed modelling choices, such as de-confounding, adversarial learning, and dynamic routing, and compares them with input attribution methods. Surprisingly, we find that input attribution methods do not guarantee causality within our framework, raising questions about their reliability in safety-critical applications. The project page is at: https://newcodevelop.github.io/causality_adventure/
OSPC: Detecting Harmful Memes with Large Language Model as a Catalyst
Jun 14, 2024

Memes, which rapidly disseminate personal opinions and positions across the internet, also pose significant challenges in propagating social bias and prejudice. This study presents a novel approach to detecting harmful memes, particularly within the multicultural and multilingual context of Singapore. Our methodology integrates image captioning, Optical Character Recognition (OCR), and Large Language Model (LLM) analysis to comprehensively understand and classify harmful memes. Utilizing the BLIP model for image captioning, PP-OCR and TrOCR for text recognition across multiple languages, and the Qwen LLM for nuanced language understanding, our system is capable of identifying harmful content in memes created in English, Chinese, Malay, and Tamil. To enhance the system's performance, we fine-tuned our approach by leveraging additional data labeled using GPT-4V, aiming to distill the understanding capability of GPT-4V for harmful memes to our system. Our framework achieves top-1 at the public leaderboard of the Online Safety Prize Challenge hosted by AI Singapore, with the AUROC as 0.7749 and accuracy as 0.7087, significantly ahead of the other teams. Notably, our approach outperforms previous benchmarks, with FLAVA achieving an AUROC of 0.5695 and VisualBERT an AUROC of 0.5561.
Beyond Image-Text Matching: Verb Understanding in Multimodal Transformers Using Guided Masking
Jan 29, 2024The dominant probing approaches rely on the zero-shot performance of image-text matching tasks to gain a finer-grained understanding of the representations learned by recent multimodal image-language transformer models. The evaluation is carried out on carefully curated datasets focusing on counting, relations, attributes, and others. This work introduces an alternative probing strategy called guided masking. The proposed approach ablates different modalities using masking and assesses the model's ability to predict the masked word with high accuracy. We focus on studying multimodal models that consider regions of interest (ROI) features obtained by object detectors as input tokens. We probe the understanding of verbs using guided masking on ViLBERT, LXMERT, UNITER, and VisualBERT and show that these models can predict the correct verb with high accuracy. This contrasts with previous conclusions drawn from image-text matching probing techniques that frequently fail in situations requiring verb understanding. The code for all experiments will be publicly available https://github.com/ivana-13/guided_masking.
A Review of Vision-Language Models and their Performance on the Hateful Memes Challenge
May 09, 2023



Moderation of social media content is currently a highly manual task, yet there is too much content posted daily to do so effectively. With the advent of a number of multimodal models, there is the potential to reduce the amount of manual labor for this task. In this work, we aim to explore different models and determine what is most effective for the Hateful Memes Challenge, a challenge by Meta designed to further machine learning research in content moderation. Specifically, we explore the differences between early fusion and late fusion models in classifying multimodal memes containing text and images. We first implement a baseline using unimodal models for text and images separately using BERT and ResNet-152, respectively. The outputs from these unimodal models were then concatenated together to create a late fusion model. In terms of early fusion models, we implement ConcatBERT, VisualBERT, ViLT, CLIP, and BridgeTower. It was found that late fusion performed significantly worse than early fusion models, with the best performing model being CLIP which achieved an AUROC of 70.06. The code for this work is available at https://github.com/bzhao18/CS-7643-Project.
Controlling for Stereotypes in Multimodal Language Model Evaluation
Feb 03, 2023


We propose a methodology and design two benchmark sets for measuring to what extent language-and-vision language models use the visual signal in the presence or absence of stereotypes. The first benchmark is designed to test for stereotypical colors of common objects, while the second benchmark considers gender stereotypes. The key idea is to compare predictions when the image conforms to the stereotype to predictions when it does not. Our results show that there is significant variation among multimodal models: the recent Transformer-based FLAVA seems to be more sensitive to the choice of image and less affected by stereotypes than older CNN-based models such as VisualBERT and LXMERT. This effect is more discernible in this type of controlled setting than in traditional evaluations where we do not know whether the model relied on the stereotype or the visual signal.
Learning by Hallucinating: Vision-Language Pre-training with Weak Supervision
Oct 27, 2022



Weakly-supervised vision-language (V-L) pre-training (W-VLP) aims at learning cross-modal alignment with little or no paired data, such as aligned images and captions. Recent W-VLP methods, which pair visual features with object tags, help achieve performances comparable with some VLP models trained with aligned pairs in various V-L downstream tasks. This, however, is not the case in cross-modal retrieval (XMR). We argue that the learning of such a W-VLP model is curbed and biased by the object tags of limited semantics. We address the lack of paired V-L data for model supervision with a novel Visual Vocabulary based Feature Hallucinator (WFH), which is trained via weak supervision as a W-VLP model, not requiring images paired with captions. WFH generates visual hallucinations from texts, which are then paired with the originally unpaired texts, allowing more diverse interactions across modalities. Empirically, WFH consistently boosts the prior W-VLP works, e.g. U-VisualBERT (U-VB), over a variety of V-L tasks, i.e. XMR, Visual Question Answering, etc. Notably, benchmarked with recall@{1,5,10}, it consistently improves U-VB on image-to-text and text-to-image retrieval on two popular datasets Flickr30K and MSCOCO. Meanwhile, it gains by at least 14.5% in cross-dataset generalization tests on these XMR tasks. Moreover, in other V-L downstream tasks considered, our WFH models are on par with models trained with paired V-L data, revealing the utility of unpaired data. These results demonstrate greater generalization of the proposed W-VLP model with WFH.
Transfer Learning with Joint Fine-Tuning for Multimodal Sentiment Analysis
Oct 11, 2022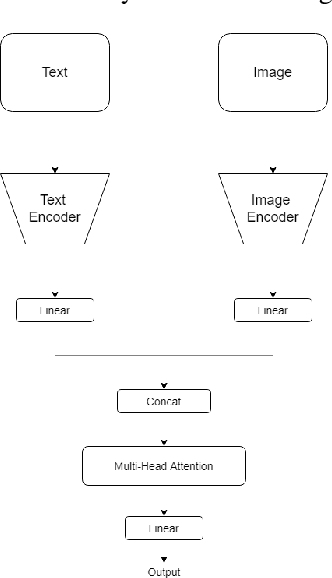
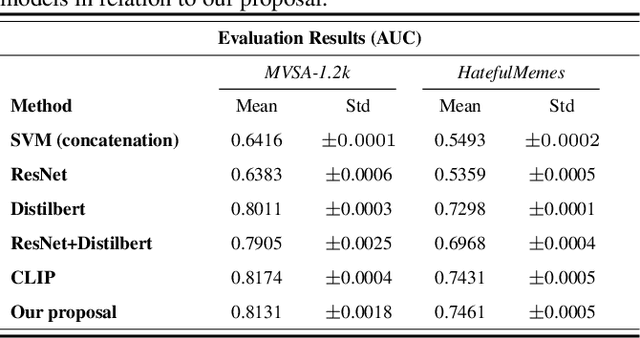
Most existing methods focus on sentiment analysis of textual data. However, recently there has been a massive use of images and videos on social platforms, motivating sentiment analysis from other modalities. Current studies show that exploring other modalities (e.g., images) increases sentiment analysis performance. State-of-the-art multimodal models, such as CLIP and VisualBERT, are pre-trained on datasets with the text paired with images. Although the results obtained by these models are promising, pre-training and sentiment analysis fine-tuning tasks of these models are computationally expensive. This paper introduces a transfer learning approach using joint fine-tuning for sentiment analysis. Our proposal achieved competitive results using a more straightforward alternative fine-tuning strategy that leverages different pre-trained unimodal models and efficiently combines them in a multimodal space. Moreover, our proposal allows flexibility when incorporating any pre-trained model for texts and images during the joint fine-tuning stage, being especially interesting for sentiment classification in low-resource scenarios.