 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText2Graph: Combining Lightweight LLMs and GNNs for Efficient Text Classification in Label-Scarce Scenarios
Dec 12, 2025



Large Language Models (LLMs) have become effective zero-shot classifiers, but their high computational requirements and environmental costs limit their practicality for large-scale annotation in high-performance computing (HPC) environments. To support more sustainable workflows, we present Text2Graph, an open-source Python package that provides a modular implementation of existing text-to-graph classification approaches. The framework enables users to combine LLM-based partial annotation with Graph Neural Network (GNN) label propagation in a flexible manner, making it straightforward to swap components such as feature extractors, edge construction methods, and sampling strategies. We benchmark Text2Graph on a zero-shot setting using five datasets spanning topic classification and sentiment analysis tasks, comparing multiple variants against other zero-shot approaches for text classification. In addition to reporting performance, we provide detailed estimates of energy consumption and carbon emissions, showing that graph-based propagation achieves competitive results at a fraction of the energy and environmental cost.
Transfer Learning with Joint Fine-Tuning for Multimodal Sentiment Analysis
Oct 11, 2022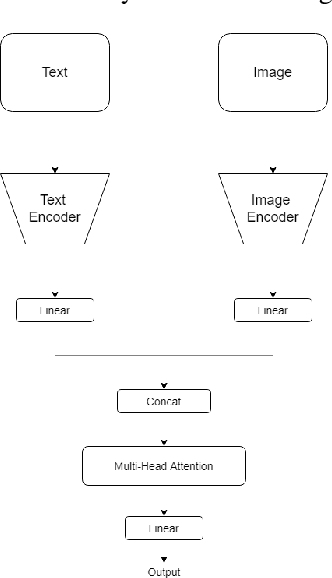
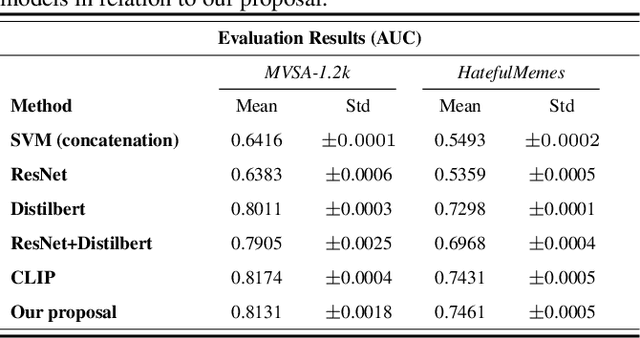
Most existing methods focus on sentiment analysis of textual data. However, recently there has been a massive use of images and videos on social platforms, motivating sentiment analysis from other modalities. Current studies show that exploring other modalities (e.g., images) increases sentiment analysis performance. State-of-the-art multimodal models, such as CLIP and VisualBERT, are pre-trained on datasets with the text paired with images. Although the results obtained by these models are promising, pre-training and sentiment analysis fine-tuning tasks of these models are computationally expensive. This paper introduces a transfer learning approach using joint fine-tuning for sentiment analysis. Our proposal achieved competitive results using a more straightforward alternative fine-tuning strategy that leverages different pre-trained unimodal models and efficiently combines them in a multimodal space. Moreover, our proposal allows flexibility when incorporating any pre-trained model for texts and images during the joint fine-tuning stage, being especially interesting for sentiment classification in low-resource scenarios.
BULNER: BUg Localization with word embeddings and NEtwork Regularization
Aug 26, 2019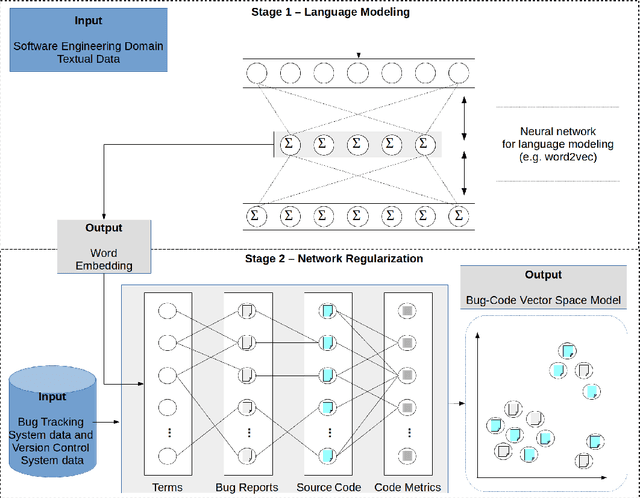

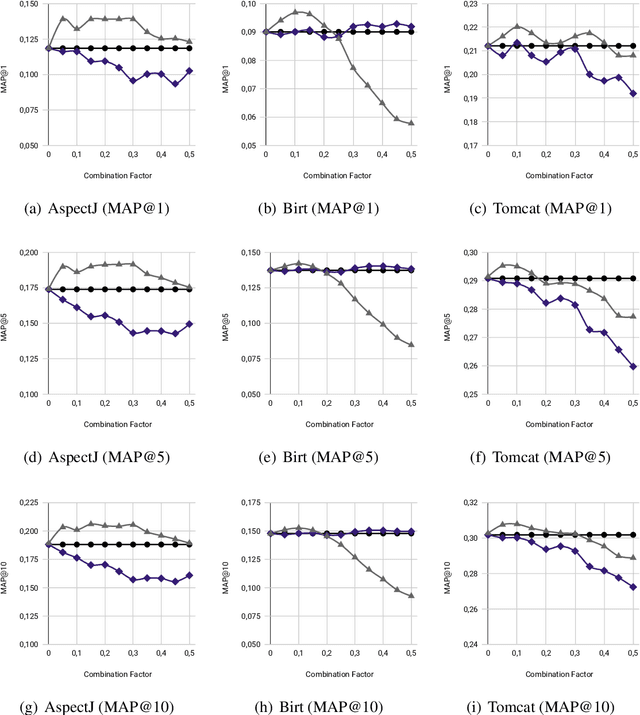
Bug localization (BL) from the bug report is the strategic activity of the software maintaining process. Because BL is a costly and tedious activity, BL techniques information retrieval-based and machine learning-based could aid software engineers. We propose a method for BUg Localization with word embeddings and Network Regularization (BULNER). The preliminary results suggest that BULNER has better performance than two state-of-the-art methods.