 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTum Visual Inertial Dataset
Papers and Code
SP-VIO: Robust and Efficient Filter-Based Visual Inertial Odometry with State Transformation Model and Pose-Only Visual Description
Nov 12, 2024



Due to the advantages of high computational efficiency and small memory requirements, filter-based visual inertial odometry (VIO) has a good application prospect in miniaturized and payload-constrained embedded systems. However, the filter-based method has the problem of insufficient accuracy. To this end, we propose the State transformation and Pose-only VIO (SP-VIO) by rebuilding the state and measurement models, and considering further visual deprived conditions. In detail, we first proposed a system model based on the double state transformation extended Kalman filter (DST-EKF), which has been proven to have better observability and consistency than the models based on extended Kalman filter (EKF) and state transformation extended Kalman filter (ST-EKF). Secondly, to reduce the influence of linearization error caused by inaccurate 3D reconstruction, we adopt the Pose-only (PO) theory to decouple the measurement model from 3D features. Moreover, to deal with visual deprived conditions, we propose a double state transformation Rauch-Tung-Striebel (DST-RTS) backtracking method to optimize motion trajectories during visual interruption. Experiments on public (EuRoC, Tum-VI, KITTI) and personal datasets show that SP-VIO has better accuracy and efficiency than state-of-the-art (SOTA) VIO algorithms, and has better robustness under visual deprived conditions.
Adaptive VIO: Deep Visual-Inertial Odometry with Online Continual Learning
May 27, 2024



Visual-inertial odometry (VIO) has demonstrated remarkable success due to its low-cost and complementary sensors. However, existing VIO methods lack the generalization ability to adjust to different environments and sensor attributes. In this paper, we propose Adaptive VIO, a new monocular visual-inertial odometry that combines online continual learning with traditional nonlinear optimization. Adaptive VIO comprises two networks to predict visual correspondence and IMU bias. Unlike end-to-end approaches that use networks to fuse the features from two modalities (camera and IMU) and predict poses directly, we combine neural networks with visual-inertial bundle adjustment in our VIO system. The optimized estimates will be fed back to the visual and IMU bias networks, refining the networks in a self-supervised manner. Such a learning-optimization-combined framework and feedback mechanism enable the system to perform online continual learning. Experiments demonstrate that our Adaptive VIO manifests adaptive capability on EuRoC and TUM-VI datasets. The overall performance exceeds the currently known learning-based VIO methods and is comparable to the state-of-the-art optimization-based methods.
SchurVINS: Schur Complement-Based Lightweight Visual Inertial Navigation System
Dec 04, 2023



Accuracy and computational efficiency are the most important metrics to Visual Inertial Navigation System (VINS). The existing VINS algorithms with either high accuracy or low computational complexity, are difficult to provide the high precision localization in resource-constrained devices. To this end, we propose a novel filter-based VINS framework named SchurVINS, which could guarantee both high accuracy by building a complete residual model and low computational complexity with Schur complement. Technically, we first formulate the full residual model where Gradient, Hessian and observation covariance are explicitly modeled. Then Schur complement is employed to decompose the full model into ego-motion residual model and landmark residual model. Finally, Extended Kalman Filter (EKF) update is implemented in these two models with high efficiency. Experiments on EuRoC and TUM-VI datasets show that our method notably outperforms state-of-the-art (SOTA) methods in both accuracy and computational complexity. We will open source our experimental code to benefit the community.
BAMF-SLAM: Bundle Adjusted Multi-Fisheye Visual-Inertial SLAM Using Recurrent Field Transforms
Jun 14, 2023



In this paper, we present BAMF-SLAM, a novel multi-fisheye visual-inertial SLAM system that utilizes Bundle Adjustment (BA) and recurrent field transforms (RFT) to achieve accurate and robust state estimation in challenging scenarios. First, our system directly operates on raw fisheye images, enabling us to fully exploit the wide Field-of-View (FoV) of fisheye cameras. Second, to overcome the low-texture challenge, we explore the tightly-coupled integration of multi-camera inputs and complementary inertial measurements via a unified factor graph and jointly optimize the poses and dense depth maps. Third, for global consistency, the wide FoV of the fisheye camera allows the system to find more potential loop closures, and powered by the broad convergence basin of RFT, our system can perform very wide baseline loop closing with little overlap. Furthermore, we introduce a semi-pose-graph BA method to avoid the expensive full global BA. By combining relative pose factors with loop closure factors, the global states can be adjusted efficiently with modest memory footprint while maintaining high accuracy. Evaluations on TUM-VI, Hilti-Oxford and Newer College datasets show the superior performance of the proposed system over prior works. In the Hilti SLAM Challenge 2022, our VIO version achieves second place. In a subsequent submission, our complete system, including the global BA backend, outperforms the winning approach.
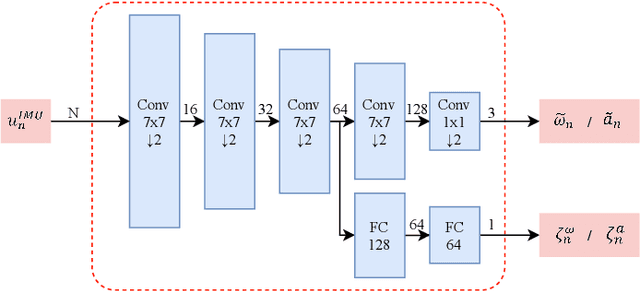
LGC-Net: A Lightweight Gyroscope Calibration Network for Efficient Attitude Estimation
Sep 19, 2022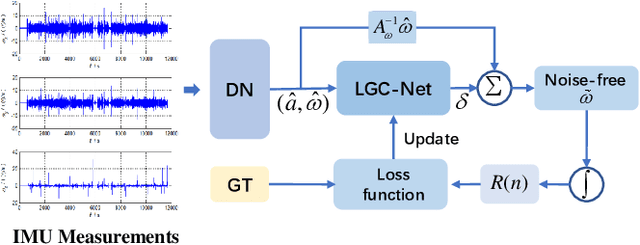
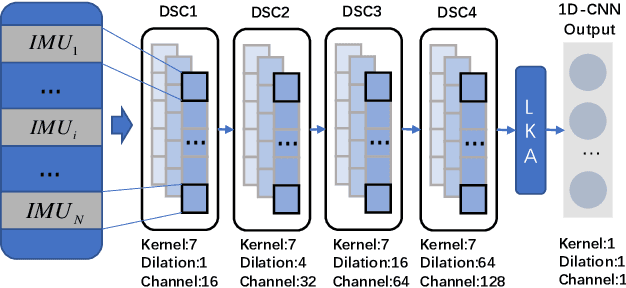
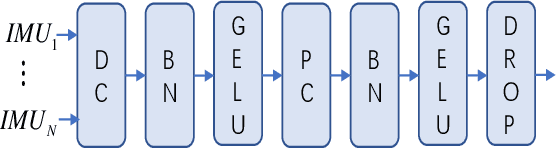
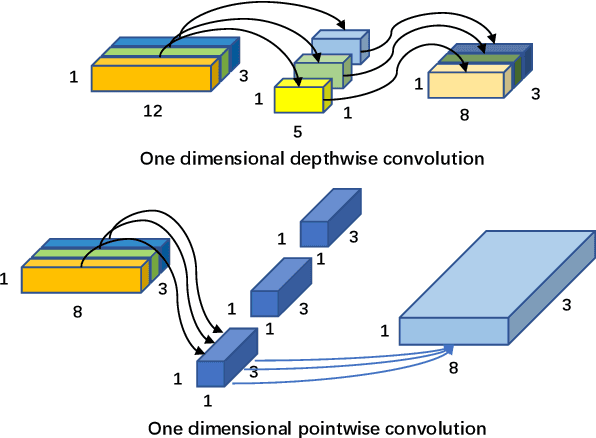
This paper presents a lightweight, efficient calibration neural network model for denoising low-cost microelectromechanical system (MEMS) gyroscope and estimating the attitude of a robot in real-time. The key idea is extracting local and global features from the time window of inertial measurement units (IMU) measurements to regress the output compensation components for the gyroscope dynamically. Following a carefully deduced mathematical calibration model, LGC-Net leverages the depthwise separable convolution to capture the sectional features and reduce the network model parameters. The Large kernel attention is designed to learn the long-range dependencies and feature representation better. The proposed algorithm is evaluated in the EuRoC and TUM-VI datasets and achieves state-of-the-art on the (unseen) test sequences with a more lightweight model structure. The estimated orientation with our LGC-Net is comparable with the top-ranked visual-inertial odometry systems, although it does not adopt vision sensors. We make our method open-source at: https://github.com/huazai665/LGC-Net
TUM-VIE: The TUM Stereo Visual-Inertial Event Dataset
Aug 16, 2021
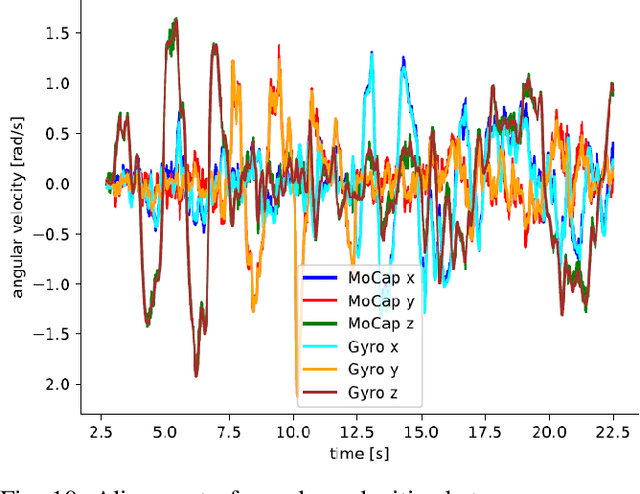
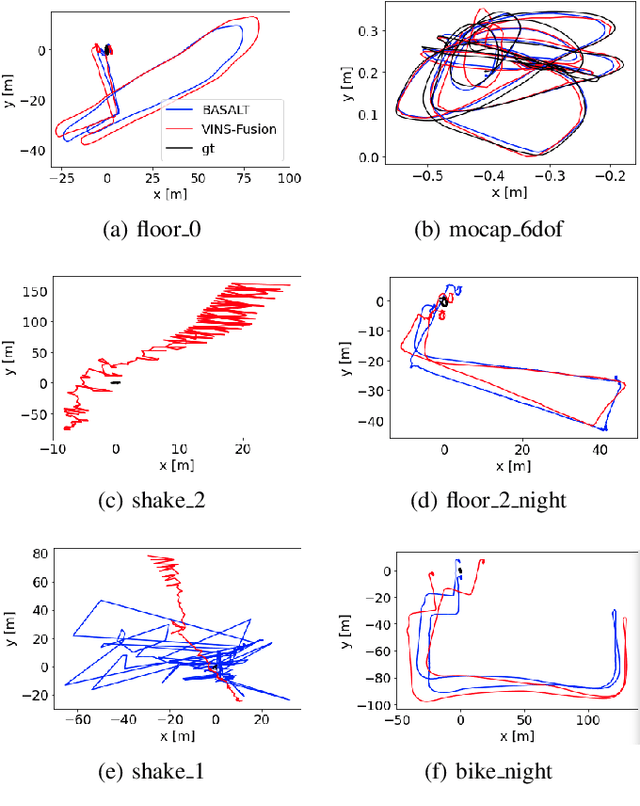

Event cameras are bio-inspired vision sensors which measure per pixel brightness changes. They offer numerous benefits over traditional, frame-based cameras, including low latency, high dynamic range, high temporal resolution and low power consumption. Thus, these sensors are suited for robotics and virtual reality applications. To foster the development of 3D perception and navigation algorithms with event cameras, we present the TUM-VIE dataset. It consists of a large variety of handheld and head-mounted sequences in indoor and outdoor environments, including rapid motion during sports and high dynamic range scenarios. The dataset contains stereo event data, stereo grayscale frames at 20Hz as well as IMU data at 200Hz. Timestamps between all sensors are synchronized in hardware. The event cameras contain a large sensor of 1280x720 pixels, which is significantly larger than the sensors used in existing stereo event datasets (at least by a factor of ten). We provide ground truth poses from a motion capture system at 120Hz during the beginning and end of each sequence, which can be used for trajectory evaluation. TUM-VIE includes challenging sequences where state-of-the art visual SLAM algorithms either fail or result in large drift. Hence, our dataset can help to push the boundary of future research on event-based visual-inertial perception algorithms.
MITI: SLAM Benchmark for Laparoscopic Surgery
Feb 23, 2022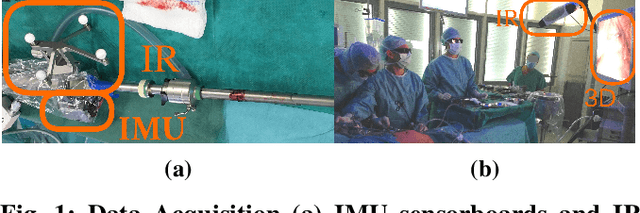
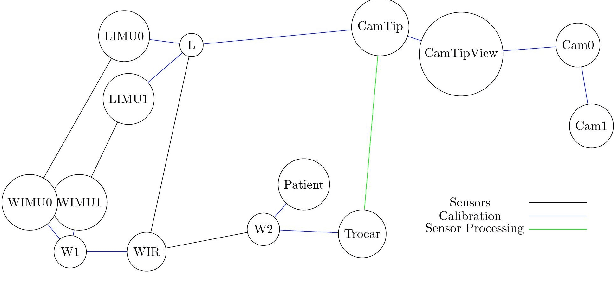

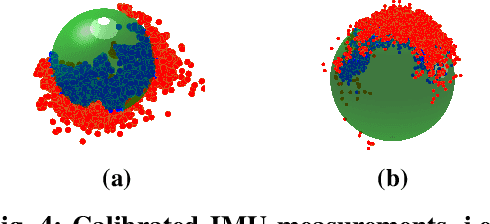
We propose a new benchmark for evaluating stereoscopic visual-inertial computer vision algorithms (SLAM/ SfM/ 3D Reconstruction/ Visual-Inertial Odometry) for minimally invasive surgical (MIS) interventions in the abdomen. Our MITI Dataset available at [https://mediatum.ub.tum.de/1621941] provides all the necessary data by a complete recording of a handheld surgical intervention at Research Hospital Rechts der Isar of TUM. It contains multimodal sensor information from IMU, stereoscopic video, and infrared (IR) tracking as ground truth for evaluation. Furthermore, calibration for the stereoscope, accelerometer, magnetometer, the rigid transformations in the sensor setup, and time-offsets are available. We wisely chose a suitable intervention that contains very few cutting and tissue deformation and shows a full scan of the abdomen with a handheld camera such that it is ideal for testing SLAM algorithms. Intending to promote the progress of visual-inertial algorithms designed for MIS application, we hope that our clinical training dataset helps and enables researchers to enhance algorithms.
Ctrl-VIO: Continuous-Time Visual-Inertial Odometry for Rolling Shutter Cameras
Aug 25, 2022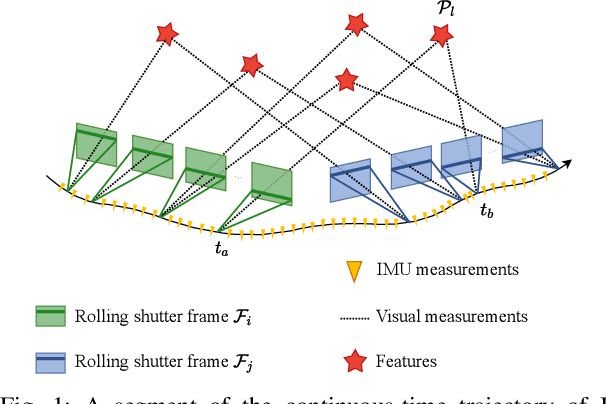
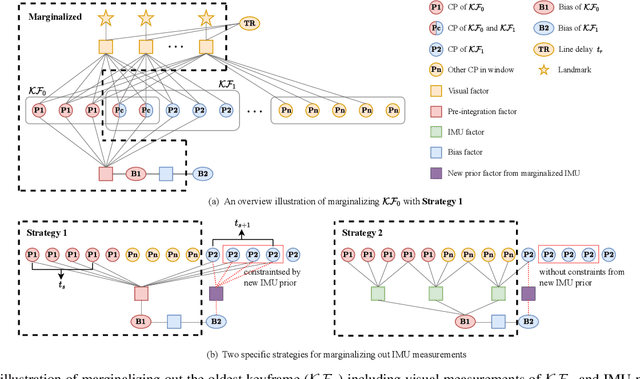
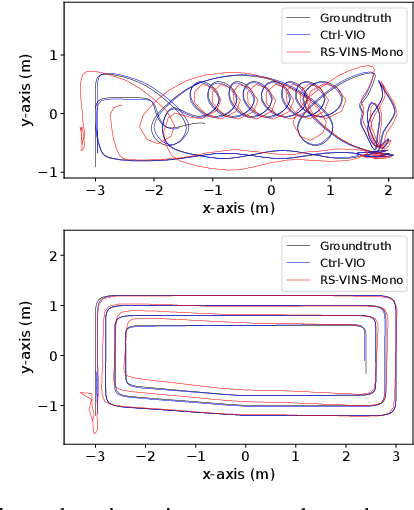
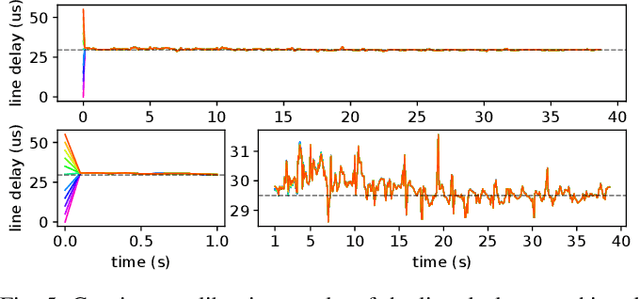
In this paper, we propose a probabilistic continuous-time visual-inertial odometry (VIO) for rolling shutter cameras. The continuous-time trajectory formulation naturally facilitates the fusion of asynchronized high-frequency IMU data and motion-distorted rolling shutter images. To prevent intractable computation load, the proposed VIO is sliding-window and keyframe-based. We propose to probabilistically marginalize the control points to keep the constant number of keyframes in the sliding window. Furthermore, the line exposure time difference (line delay) of the rolling shutter camera can be online calibrated in our continuous-time VIO. To extensively examine the performance of our continuous-time VIO, experiments are conducted on publicly-available WHU-RSVI, TUM-RSVI, and SenseTime-RSVI rolling shutter datasets. The results demonstrate the proposed continuous-time VIO significantly outperforms the existing state-of-the-art VIO methods. The codebase of this paper will also be open-sourced at \url{https://github.com/APRIL-ZJU/Ctrl-VIO}.
DM-VIO: Delayed Marginalization Visual-Inertial Odometry
Jan 11, 2022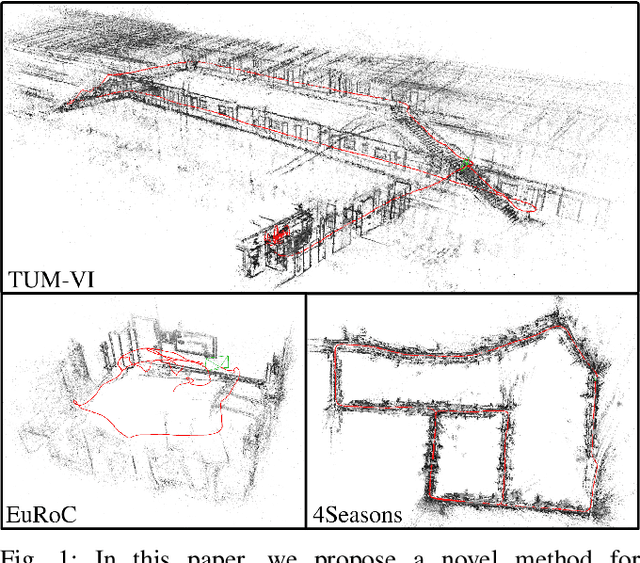
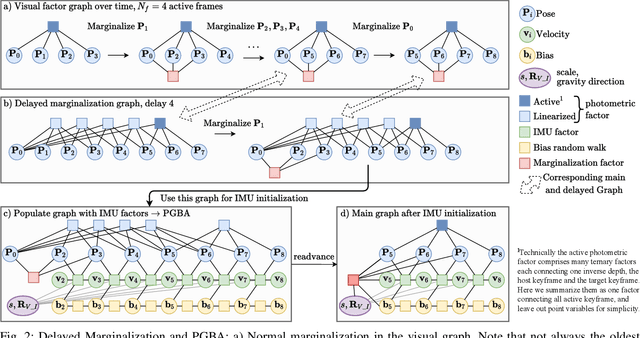
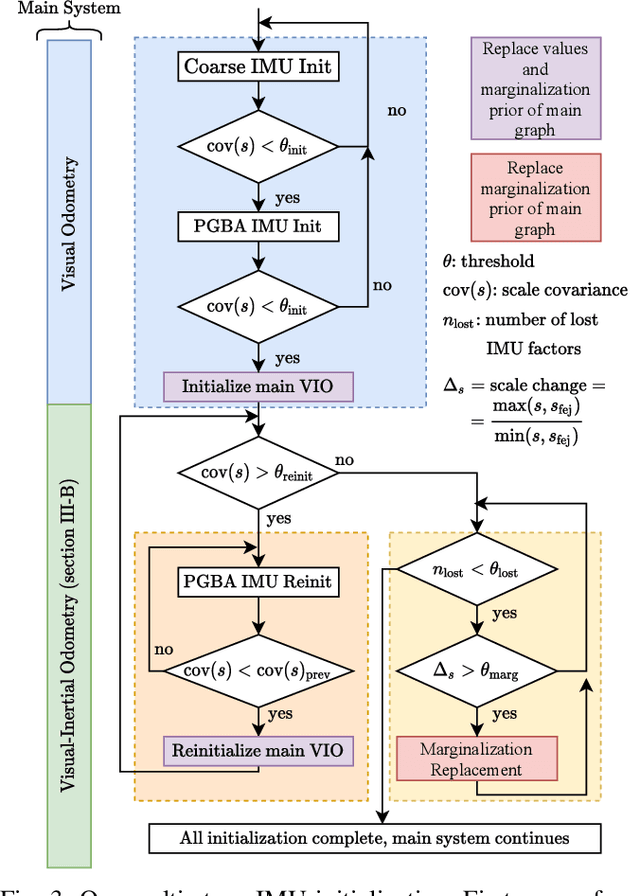
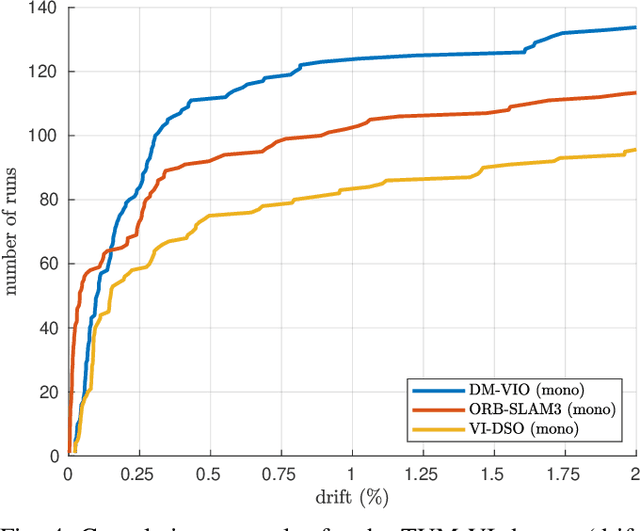
We present DM-VIO, a monocular visual-inertial odometry system based on two novel techniques called delayed marginalization and pose graph bundle adjustment. DM-VIO performs photometric bundle adjustment with a dynamic weight for visual residuals. We adopt marginalization, which is a popular strategy to keep the update time constrained, but it cannot easily be reversed, and linearization points of connected variables have to be fixed. To overcome this we propose delayed marginalization: The idea is to maintain a second factor graph, where marginalization is delayed. This allows us to later readvance this delayed graph, yielding an updated marginalization prior with new and consistent linearization points. In addition, delayed marginalization enables us to inject IMU information into already marginalized states. This is the foundation of the proposed pose graph bundle adjustment, which we use for IMU initialization. In contrast to prior works on IMU initialization, it is able to capture the full photometric uncertainty, improving the scale estimation. In order to cope with initially unobservable scale, we continue to optimize scale and gravity direction in the main system after IMU initialization is complete. We evaluate our system on the EuRoC, TUM-VI, and 4Seasons datasets, which comprise flying drone, large-scale handheld, and automotive scenarios. Thanks to the proposed IMU initialization, our system exceeds the state of the art in visual-inertial odometry, even outperforming stereo-inertial methods while using only a single camera and IMU. The code will be published at http://vision.in.tum.de/dm-vio
SRVIO: Super Robust Visual Inertial Odometry for dynamic environments and challenging Loop-closure conditions
Jan 14, 2022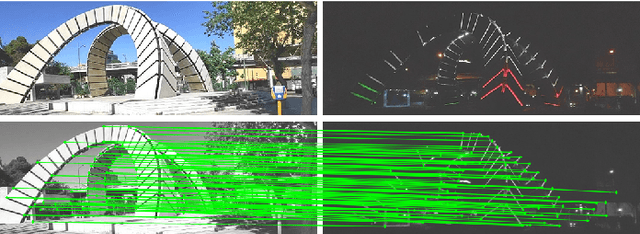
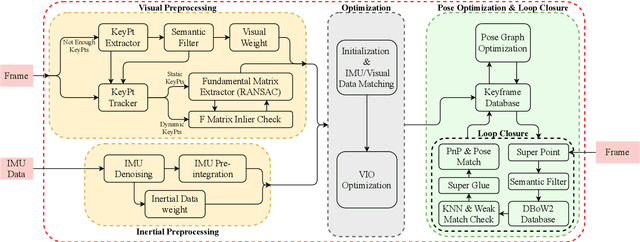

The visual localization or odometry problem is a well-known challenge in the field of autonomous robots and cars. Traditionally, this problem can ba tackled with the help of expensive sensors such as lidars. Nowadays, the leading research is on robust localization using economic sensors, such as cameras and IMUs. The geometric methods based on these sensors are pretty good in normal conditions withstable lighting and no dynamic objects. These methods suffer from significant loss and divergence in such challenging environments. The scientists came to use deep neural networks (DNNs) as the savior to mitigate this problem. The main idea behind using DNNs was to better understand the problem inside the data and overcome complex conditions (such as a dynamic object in front of the camera, extreme lighting conditions, keeping the track at high speeds, etc.) The prior endto-end DNN methods are able to overcome some of the mentioned challenges. However, no general and robust framework for all of these scenarios is available. In this paper, we have combined geometric and DNN based methods to have the pros of geometric SLAM frameworks and overcome the remaining challenges with the DNNs help. To do this, we have modified the Vins-Mono framework (the most robust and accurate framework till now) and we were able to achieve state-of-the-art results on TUM-Dynamic, TUM-VI, ADVIO and EuRoC datasets compared to geometric and end-to-end DNN based SLAMs. Our proposed framework was also able to achieve acceptable results on extreme simulated cases resembling the challenges mentioned earlier easy.