 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToronto 3D
Papers and Code
Subspace Prototype Guidance for Mitigating Class Imbalance in Point Cloud Semantic Segmentation
Aug 20, 2024



Point cloud semantic segmentation can significantly enhance the perception of an intelligent agent. Nevertheless, the discriminative capability of the segmentation network is influenced by the quantity of samples available for different categories. To mitigate the cognitive bias induced by class imbalance, this paper introduces a novel method, namely subspace prototype guidance (\textbf{SPG}), to guide the training of segmentation network. Specifically, the point cloud is initially separated into independent point sets by category to provide initial conditions for the generation of feature subspaces. The auxiliary branch which consists of an encoder and a projection head maps these point sets into separate feature subspaces. Subsequently, the feature prototypes which are extracted from the current separate subspaces and then combined with prototypes of historical subspaces guide the feature space of main branch to enhance the discriminability of features of minority categories. The prototypes derived from the feature space of main branch are also employed to guide the training of the auxiliary branch, forming a supervisory loop to maintain consistent convergence of the entire network. The experiments conducted on the large public benchmarks (i.e. S3DIS, ScanNet v2, ScanNet200, Toronto-3D) and collected real-world data illustrate that the proposed method significantly improves the segmentation performance and surpasses the state-of-the-art method. The code is available at \url{https://github.com/Javion11/PointLiBR.git}.
3D Learnable Supertoken Transformer for LiDAR Point Cloud Scene Segmentation
May 23, 2024



3D Transformers have achieved great success in point cloud understanding and representation. However, there is still considerable scope for further development in effective and efficient Transformers for large-scale LiDAR point cloud scene segmentation. This paper proposes a novel 3D Transformer framework, named 3D Learnable Supertoken Transformer (3DLST). The key contributions are summarized as follows. Firstly, we introduce the first Dynamic Supertoken Optimization (DSO) block for efficient token clustering and aggregating, where the learnable supertoken definition avoids the time-consuming pre-processing of traditional superpoint generation. Since the learnable supertokens can be dynamically optimized by multi-level deep features during network learning, they are tailored to the semantic homogeneity-aware token clustering. Secondly, an efficient Cross-Attention-guided Upsampling (CAU) block is proposed for token reconstruction from optimized supertokens. Thirdly, the 3DLST is equipped with a novel W-net architecture instead of the common U-net design, which is more suitable for Transformer-based feature learning. The SOTA performance on three challenging LiDAR datasets (airborne MultiSpectral LiDAR (MS-LiDAR) (89.3% of the average F1 score), DALES (80.2% of mIoU), and Toronto-3D dataset (80.4% of mIoU)) demonstrate the superiority of 3DLST and its strong adaptability to various LiDAR point cloud data (airborne MS-LiDAR, aerial LiDAR, and vehicle-mounted LiDAR data). Furthermore, 3DLST also achieves satisfactory results in terms of algorithm efficiency, which is up to 5x faster than previous best-performing methods.
Point Cloud Segmentation Using Transfer Learning with RandLA-Net: A Case Study on Urban Areas
Dec 19, 2023Urban environments are characterized by complex structures and diverse features, making accurate segmentation of point cloud data a challenging task. This paper presents a comprehensive study on the application of RandLA-Net, a state-of-the-art neural network architecture, for the 3D segmentation of large-scale point cloud data in urban areas. The study focuses on three major Chinese cities, namely Chengdu, Jiaoda, and Shenzhen, leveraging their unique characteristics to enhance segmentation performance. To address the limited availability of labeled data for these specific urban areas, we employed transfer learning techniques. We transferred the learned weights from the Sensat Urban and Toronto 3D datasets to initialize our RandLA-Net model. Additionally, we performed class remapping to adapt the model to the target urban areas, ensuring accurate segmentation results. The experimental results demonstrate the effectiveness of the proposed approach achieving over 80\% F1 score for each areas in 3D point cloud segmentation. The transfer learning strategy proves to be crucial in overcoming data scarcity issues, providing a robust solution for urban point cloud analysis. The findings contribute to the advancement of point cloud segmentation methods, especially in the context of rapidly evolving Chinese urban areas.
Dynamic Clustering Transformer Network for Point Cloud Segmentation
May 30, 2023



Point cloud segmentation is one of the most important tasks in computer vision with widespread scientific, industrial, and commercial applications. The research thereof has resulted in many breakthroughs in 3D object and scene understanding. Previous methods typically utilized hierarchical architectures for feature representation. However, the commonly used sampling and grouping methods in hierarchical networks are only based on point-wise three-dimensional coordinates, ignoring local semantic homogeneity of point clusters. Additionally, the prevalent Farthest Point Sampling (FPS) method is often a computational bottleneck. To address these issues, we propose a novel 3D point cloud representation network, called Dynamic Clustering Transformer Network (DCTNet). It has an encoder-decoder architecture, allowing for both local and global feature learning. Specifically, we propose novel semantic feature-based dynamic sampling and clustering methods in the encoder, which enables the model to be aware of local semantic homogeneity for local feature aggregation. Furthermore, in the decoder, we propose an efficient semantic feature-guided upsampling method. Our method was evaluated on an object-based dataset (ShapeNet), an urban navigation dataset (Toronto-3D), and a multispectral LiDAR dataset, verifying the performance of DCTNet across a wide variety of practical engineering applications. The inference speed of DCTNet is 3.8-16.8$\times$ faster than existing State-of-the-Art (SOTA) models on the ShapeNet dataset, while achieving an instance-wise mIoU of $86.6\%$, the current top score. Our method similarly outperforms previous methods on the other datasets, verifying it as the new State-of-the-Art in point cloud segmentation.
Enabling High-Precision 5G mmWave-Based Positioning for Autonomous Vehicles in Dense Urban Environments
May 04, 2023



5G-based mmWave wireless positioning has emerged as a promising solution for autonomous vehicle (AV) positioning in recent years. Previous studies have highlighted the benefits of fusing a line-of-sight (LoS) 5G positioning solution with an Inertial Navigation System (INS) for an improved positioning solution. However, the highly dynamic environment of urban areas, where AVs are expected to operate, poses a challenge, as non-line-of-sight (NLoS) communication can deteriorate the 5G mmWave positioning solution and lead to erroneous corrections to the INS. To address this challenge, we exploit 5G multipath and LoS signals to improve positioning performance in dense urban environments. In addition, we integrate the proposed 5G-based positioning with low-cost onboard motion sensors (OBMS). Moreover, the integration is realized using an unscented Kalman filter (UKF) as an alternative to the widely utilized EKF as a fusion engine to avoid ignoring the higher-order and non-linear terms of the dynamic system model. We also introduce techniques to evaluate the quality of each LoS and multipath measurement prior to incorporation into the filter's correction stage. To validate the proposed methodologies, we performed two test trajectories in the dense urban environment of downtown Toronto, Canada. For each trajectory, quasi-real 5G measurements were collected using a ray-tracing tool incorporating 3D map scans of real-world buildings, allowing for realistic multipath scenarios. For the same trajectories, real OBMS data were collected from two-different low-cost IMUs. Our integrated positioning solution was capable of maintaining a level of accuracy below 30 cm for approximately 97% of the time, which is superior to the accuracy level achieved when multipath signals are not considered, which is only around 91% of the time.
Semantic Segmentation for Point Cloud Scenes via Dilated Graph Feature Aggregation and Pyramid Decoders
Apr 11, 2022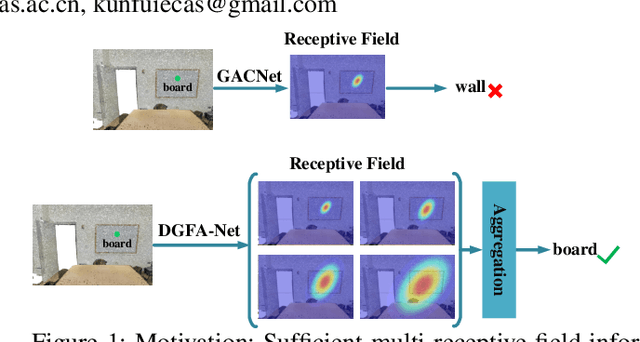
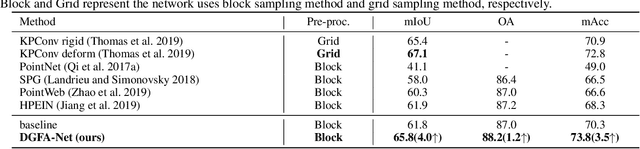
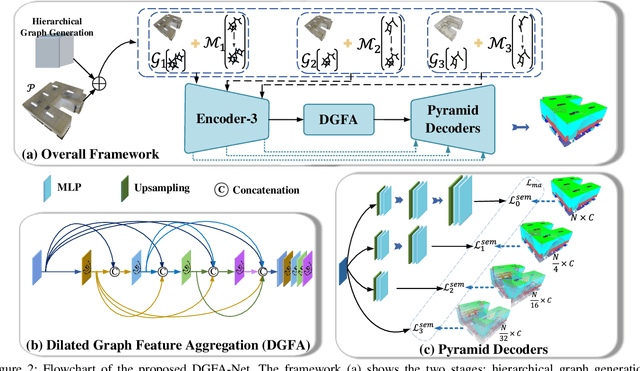

Semantic segmentation of point clouds generates comprehensive understanding of scenes through densely predicting the category for each point. Due to the unicity of receptive field, semantic segmentation of point clouds remains challenging for the expression of multi-receptive field features, which brings about the misclassification of instances with similar spatial structures. In this paper, we propose a graph convolutional network DGFA-Net rooted in dilated graph feature aggregation (DGFA), guided by multi-basis aggregation loss (MALoss) calculated through Pyramid Decoders. To configure multi-receptive field features, DGFA which takes the proposed dilated graph convolution (DGConv) as its basic building block, is designed to aggregate multi-scale feature representation by capturing dilated graphs with various receptive regions. By simultaneously considering penalizing the receptive field information with point sets of different resolutions as calculation bases, we introduce Pyramid Decoders driven by MALoss for the diversity of receptive field bases. Combining these two aspects, DGFA-Net significantly improves the segmentation performance of instances with similar spatial structures. Experiments on S3DIS, ShapeNetPart and Toronto-3D show that DGFA-Net outperforms the baseline approach, achieving a new state-of-the-art segmentation performance.
Toronto-3D: A Large-scale Mobile LiDAR Dataset for Semantic Segmentation of Urban Roadways
Apr 16, 2020
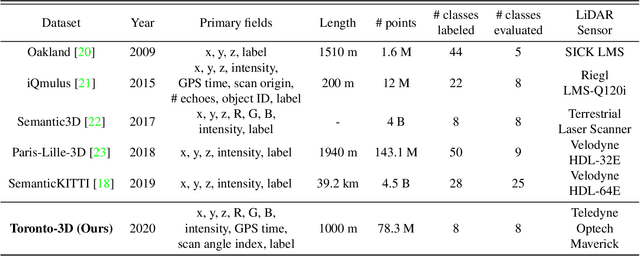
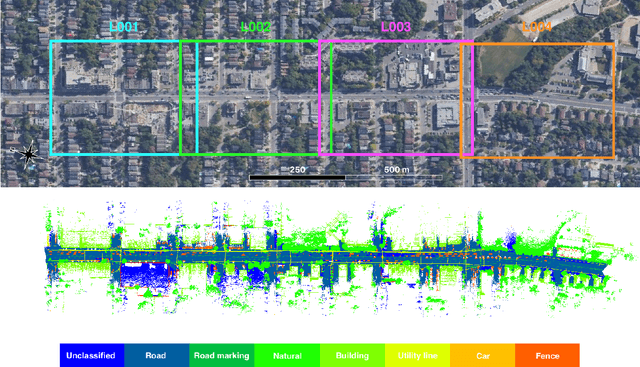

Semantic segmentation of large-scale outdoor point clouds is essential for urban scene understanding in various applications, especially autonomous driving and urban high-definition (HD) mapping. With rapid developments of mobile laser scanning (MLS) systems, massive point clouds are available for scene understanding, but publicly accessible large-scale labeled datasets, which are essential for developing learning-based methods, are still limited. This paper introduces Toronto-3D, a large-scale urban outdoor point cloud dataset acquired by a MLS system in Toronto, Canada for semantic segmentation. This dataset covers approximately 1 km of point clouds and consists of about 78.3 million points with 8 labeled object classes. Baseline experiments for semantic segmentation were conducted and the results confirmed the capability of this dataset to train deep learning models effectively. Toronto-3D is released to encourage new research, and the labels will be improved and updated with feedback from the research community.