 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperpixels
Papers and Code
Bidirectional Cross-Perception for Open-Vocabulary Semantic Segmentation in Remote Sensing Imagery
Jan 29, 2026High-resolution remote sensing imagery is characterized by densely distributed land-cover objects and complex boundaries, which places higher demands on both geometric localization and semantic prediction. Existing training-free open-vocabulary semantic segmentation (OVSS) methods typically fuse CLIP and vision foundation models (VFMs) using "one-way injection" and "shallow post-processing" strategies, making it difficult to satisfy these requirements. To address this issue, we propose a spatial-regularization-aware dual-branch collaborative inference framework for training-free OVSS, termed SDCI. First, during feature encoding, SDCI introduces a cross-model attention fusion (CAF) module, which guides collaborative inference by injecting self-attention maps into each other. Second, we propose a bidirectional cross-graph diffusion refinement (BCDR) module that enhances the reliability of dual-branch segmentation scores through iterative random-walk diffusion. Finally, we incorporate low-level superpixel structures and develop a convex-optimization-based superpixel collaborative prediction (CSCP) mechanism to further refine object boundaries. Experiments on multiple remote sensing semantic segmentation benchmarks demonstrate that our method achieves better performance than existing approaches. Moreover, ablation studies further confirm that traditional object-based remote sensing image analysis methods leveraging superpixel structures remain effective within deep learning frameworks. Code: https://github.com/yu-ni1989/SDCI.
UCAD: Uncertainty-guided Contour-aware Displacement for semi-supervised medical image segmentation
Jan 24, 2026Existing displacement strategies in semi-supervised segmentation only operate on rectangular regions, ignoring anatomical structures and resulting in boundary distortions and semantic inconsistency. To address these issues, we propose UCAD, an Uncertainty-Guided Contour-Aware Displacement framework for semi-supervised medical image segmentation that preserves contour-aware semantics while enhancing consistency learning. Our UCAD leverages superpixels to generate anatomically coherent regions aligned with anatomy boundaries, and an uncertainty-guided selection mechanism to selectively displace challenging regions for better consistency learning. We further propose a dynamic uncertainty-weighted consistency loss, which adaptively stabilizes training and effectively regularizes the model on unlabeled regions. Extensive experiments demonstrate that UCAD consistently outperforms state-of-the-art semi-supervised segmentation methods, achieving superior segmentation accuracy under limited annotation. The code is available at:https://github.com/dcb937/UCAD.
Superpixel-Based Image Segmentation Using Squared 2-Wasserstein Distances
Jan 22, 2026We present an efficient method for image segmentation in the presence of strong inhomogeneities. The approach can be interpreted as a two-level clustering procedure: pixels are first grouped into superpixels via a linear least-squares assignment problem, which can be viewed as a special case of a discrete optimal transport (OT) problem, and these superpixels are subsequently greedily merged into object-level segments using the squared 2-Wasserstein distance between their empirical distributions. In contrast to conventional superpixel merging strategies based on mean-color distances, our framework employs a distributional OT distance, yielding a mathematically unified formulation across both clustering levels. Numerical experiments demonstrate that this perspective leads to improved segmentation accuracy on challenging images while retaining high computational efficiency.
SPOT-Face: Forensic Face Identification using Attention Guided Optimal Transport
Jan 14, 2026Person identification in forensic investigations becomes very challenging when common identification means for DNA (i.e., hair strands, soft tissue) are not available. Current methods utilize deep learning methods for face recognition. However, these methods lack effective mechanisms to model cross-domain structural correspondence between two different forensic modalities. In this paper, we introduce a SPOT-Face, a superpixel graph-based framework designed for cross-domain forensic face identification of victims using their skeleton and sketch images. Our unified framework involves constructing a superpixel-based graph from an image and then using different graph neural networks(GNNs) backbones to extract the embeddings of these graphs, while cross-domain correspondence is established through attention-guided optimal transport mechanism. We have evaluated our proposed framework on two publicly available dataset: IIT\_Mandi\_S2F (S2F) and CUFS. Extensive experiments were conducted to evaluate our proposed framework. The experimental results show significant improvement in identification metrics ( i.e., Recall, mAP) over existing graph-based baselines. Furthermore, our framework demonstrates to be highly effective for matching skulls and sketches to faces in forensic investigations.
Diffusion Posterior Sampler for Hyperspectral Unmixing with Spectral Variability Modeling
Dec 10, 2025Linear spectral mixture models (LMM) provide a concise form to disentangle the constituent materials (endmembers) and their corresponding proportions (abundance) in a single pixel. The critical challenges are how to model the spectral prior distribution and spectral variability. Prior knowledge and spectral variability can be rigorously modeled under the Bayesian framework, where posterior estimation of Abundance is derived by combining observed data with endmember prior distribution. Considering the key challenges and the advantages of the Bayesian framework, a novel method using a diffusion posterior sampler for semiblind unmixing, denoted as DPS4Un, is proposed to deal with these challenges with the following features: (1) we view the pretrained conditional spectrum diffusion model as a posterior sampler, which can combine the learned endmember prior with observation to get the refined abundance distribution. (2) Instead of using the existing spectral library as prior, which may raise bias, we establish the image-based endmember bundles within superpixels, which are used to train the endmember prior learner with diffusion model. Superpixels make sure the sub-scene is more homogeneous. (3) Instead of using the image-level data consistency constraint, the superpixel-based data fidelity term is proposed. (4) The endmember is initialized as Gaussian noise for each superpixel region, DPS4Un iteratively updates the abundance and endmember, contributing to spectral variability modeling. The experimental results on three real-world benchmark datasets demonstrate that DPS4Un outperforms the state-of-the-art hyperspectral unmixing methods.
C2F-Space: Coarse-to-Fine Space Grounding for Spatial Instructions using Vision-Language Models
Nov 19, 2025Space grounding refers to localizing a set of spatial references described in natural language instructions. Traditional methods often fail to account for complex reasoning -- such as distance, geometry, and inter-object relationships -- while vision-language models (VLMs), despite strong reasoning abilities, struggle to produce a fine-grained region of outputs. To overcome these limitations, we propose C2F-Space, a novel coarse-to-fine space-grounding framework that (i) estimates an approximated yet spatially consistent region using a VLM, then (ii) refines the region to align with the local environment through superpixelization. For the coarse estimation, we design a grid-based visual-grounding prompt with a propose-validate strategy, maximizing VLM's spatial understanding and yielding physically and semantically valid canonical region (i.e., ellipses). For the refinement, we locally adapt the region to surrounding environment without over-relaxed to free space. We construct a new space-grounding benchmark and compare C2F-Space with five state-of-the-art baselines using success rate and intersection-over-union. Our C2F-Space significantly outperforms all baselines. Our ablation study confirms the effectiveness of each module in the two-step process and their synergistic effect of the combined framework. We finally demonstrate the applicability of C2F-Space to simulated robotic pick-and-place tasks.
Bridging Granularity Gaps: Hierarchical Semantic Learning for Cross-domain Few-shot Segmentation
Nov 15, 2025Cross-domain Few-shot Segmentation (CD-FSS) aims to segment novel classes from target domains that are not involved in training and have significantly different data distributions from the source domain, using only a few annotated samples, and recent years have witnessed significant progress on this task. However, existing CD-FSS methods primarily focus on style gaps between source and target domains while ignoring segmentation granularity gaps, resulting in insufficient semantic discriminability for novel classes in target domains. Therefore, we propose a Hierarchical Semantic Learning (HSL) framework to tackle this problem. Specifically, we introduce a Dual Style Randomization (DSR) module and a Hierarchical Semantic Mining (HSM) module to learn hierarchical semantic features, thereby enhancing the model's ability to recognize semantics at varying granularities. DSR simulates target domain data with diverse foreground-background style differences and overall style variations through foreground and global style randomization respectively, while HSM leverages multi-scale superpixels to guide the model to mine intra-class consistency and inter-class distinction at different granularities. Additionally, we also propose a Prototype Confidence-modulated Thresholding (PCMT) module to mitigate segmentation ambiguity when foreground and background are excessively similar. Extensive experiments are conducted on four popular target domain datasets, and the results demonstrate that our method achieves state-of-the-art performance.
Multitask GLocal OBIA-Mamba for Sentinel-2 Landcover Mapping
Nov 13, 2025Although Sentinel-2 based land use and land cover (LULC) classification is critical for various environmental monitoring applications, it is a very difficult task due to some key data challenges (e.g., spatial heterogeneity, context information, signature ambiguity). This paper presents a novel Multitask Glocal OBIA-Mamba (MSOM) for enhanced Sentinel-2 classification with the following contributions. First, an object-based image analysis (OBIA) Mamba model (OBIA-Mamba) is designed to reduce redundant computation without compromising fine-grained details by using superpixels as Mamba tokens. Second, a global-local (GLocal) dual-branch convolutional neural network (CNN)-mamba architecture is designed to jointly model local spatial detail and global contextual information. Third, a multitask optimization framework is designed to employ dual loss functions to balance local precision with global consistency. The proposed approach is tested on Sentinel-2 imagery in Alberta, Canada, in comparison with several advanced classification approaches, and the results demonstrate that the proposed approach achieves higher classification accuracy and finer details that the other state-of-the-art methods.
Do Superpixel Segmentation Methods Influence Deforestation Image Classification?
Oct 06, 2025
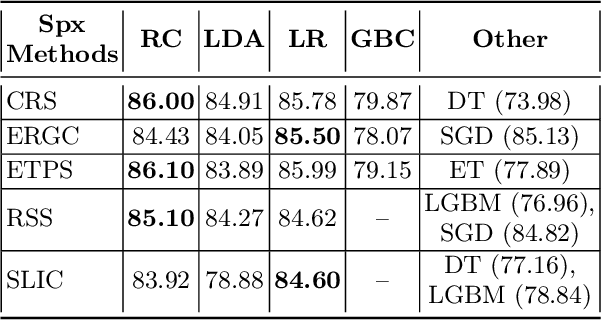

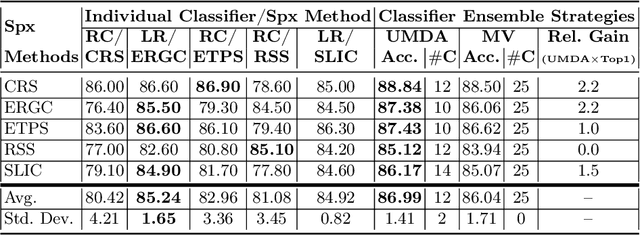
Image segmentation is a crucial step in various visual applications, including environmental monitoring through remote sensing. In the context of the ForestEyes project, which combines citizen science and machine learning to detect deforestation in tropical forests, image segments are used for labeling by volunteers and subsequent model training. Traditionally, the Simple Linear Iterative Clustering (SLIC) algorithm is adopted as the segmentation method. However, recent studies have indicated that other superpixel-based methods outperform SLIC in remote sensing image segmentation, and might suggest that they are more suitable for the task of detecting deforested areas. In this sense, this study investigated the impact of the four best segmentation methods, together with SLIC, on the training of classifiers for the target application. Initially, the results showed little variation in performance among segmentation methods, even when selecting the top five classifiers using the PyCaret AutoML library. However, by applying a classifier fusion approach (ensemble of classifiers), noticeable improvements in balanced accuracy were observed, highlighting the importance of both the choice of segmentation method and the combination of machine learning-based models for deforestation detection tasks.
Self-Supervised Cross-Modal Learning for Image-to-Point Cloud Registration
Sep 19, 2025Bridging 2D and 3D sensor modalities is critical for robust perception in autonomous systems. However, image-to-point cloud (I2P) registration remains challenging due to the semantic-geometric gap between texture-rich but depth-ambiguous images and sparse yet metrically precise point clouds, as well as the tendency of existing methods to converge to local optima. To overcome these limitations, we introduce CrossI2P, a self-supervised framework that unifies cross-modal learning and two-stage registration in a single end-to-end pipeline. First, we learn a geometric-semantic fused embedding space via dual-path contrastive learning, enabling annotation-free, bidirectional alignment of 2D textures and 3D structures. Second, we adopt a coarse-to-fine registration paradigm: a global stage establishes superpoint-superpixel correspondences through joint intra-modal context and cross-modal interaction modeling, followed by a geometry-constrained point-level refinement for precise registration. Third, we employ a dynamic training mechanism with gradient normalization to balance losses for feature alignment, correspondence refinement, and pose estimation. Extensive experiments demonstrate that CrossI2P outperforms state-of-the-art methods by 23.7% on the KITTI Odometry benchmark and by 37.9% on nuScenes, significantly improving both accuracy and robustness.