 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStandardized Evaluation of Automatic Methods for Perivascular Spaces Segmentation in MRI -- MICCAI 2024 Challenge Results
Dec 20, 2025



Perivascular spaces (PVS), when abnormally enlarged and visible in magnetic resonance imaging (MRI) structural sequences, are important imaging markers of cerebral small vessel disease and potential indicators of neurodegenerative conditions. Despite their clinical significance, automatic enlarged PVS (EPVS) segmentation remains challenging due to their small size, variable morphology, similarity with other pathological features, and limited annotated datasets. This paper presents the EPVS Challenge organized at MICCAI 2024, which aims to advance the development of automated algorithms for EPVS segmentation across multi-site data. We provided a diverse dataset comprising 100 training, 50 validation, and 50 testing scans collected from multiple international sites (UK, Singapore, and China) with varying MRI protocols and demographics. All annotations followed the STRIVE protocol to ensure standardized ground truth and covered the full brain parenchyma. Seven teams completed the full challenge, implementing various deep learning approaches primarily based on U-Net architectures with innovations in multi-modal processing, ensemble strategies, and transformer-based components. Performance was evaluated using dice similarity coefficient, absolute volume difference, recall, and precision metrics. The winning method employed MedNeXt architecture with a dual 2D/3D strategy for handling varying slice thicknesses. The top solutions showed relatively good performance on test data from seen datasets, but significant degradation of performance was observed on the previously unseen Shanghai cohort, highlighting cross-site generalization challenges due to domain shift. This challenge establishes an important benchmark for EPVS segmentation methods and underscores the need for the continued development of robust algorithms that can generalize in diverse clinical settings.
An LLM-based Framework for Human-Swarm Teaming Cognition in Disaster Search and Rescue
Nov 06, 2025



Large-scale disaster Search And Rescue (SAR) operations are persistently challenged by complex terrain and disrupted communications. While Unmanned Aerial Vehicle (UAV) swarms offer a promising solution for tasks like wide-area search and supply delivery, yet their effective coordination places a significant cognitive burden on human operators. The core human-machine collaboration bottleneck lies in the ``intention-to-action gap'', which is an error-prone process of translating a high-level rescue objective into a low-level swarm command under high intensity and pressure. To bridge this gap, this study proposes a novel LLM-CRF system that leverages Large Language Models (LLMs) to model and augment human-swarm teaming cognition. The proposed framework initially captures the operator's intention through natural and multi-modal interactions with the device via voice or graphical annotations. It then employs the LLM as a cognitive engine to perform intention comprehension, hierarchical task decomposition, and mission planning for the UAV swarm. This closed-loop framework enables the swarm to act as a proactive partner, providing active feedback in real-time while reducing the need for manual monitoring and control, which considerably advances the efficacy of the SAR task. We evaluate the proposed framework in a simulated SAR scenario. Experimental results demonstrate that, compared to traditional order and command-based interfaces, the proposed LLM-driven approach reduced task completion time by approximately $64.2\%$ and improved task success rate by $7\%$. It also leads to a considerable reduction in subjective cognitive workload, with NASA-TLX scores dropping by $42.9\%$. This work establishes the potential of LLMs to create more intuitive and effective human-swarm collaborations in high-stakes scenarios.
Self-Supervised Cross-Modal Learning for Image-to-Point Cloud Registration
Sep 19, 2025Bridging 2D and 3D sensor modalities is critical for robust perception in autonomous systems. However, image-to-point cloud (I2P) registration remains challenging due to the semantic-geometric gap between texture-rich but depth-ambiguous images and sparse yet metrically precise point clouds, as well as the tendency of existing methods to converge to local optima. To overcome these limitations, we introduce CrossI2P, a self-supervised framework that unifies cross-modal learning and two-stage registration in a single end-to-end pipeline. First, we learn a geometric-semantic fused embedding space via dual-path contrastive learning, enabling annotation-free, bidirectional alignment of 2D textures and 3D structures. Second, we adopt a coarse-to-fine registration paradigm: a global stage establishes superpoint-superpixel correspondences through joint intra-modal context and cross-modal interaction modeling, followed by a geometry-constrained point-level refinement for precise registration. Third, we employ a dynamic training mechanism with gradient normalization to balance losses for feature alignment, correspondence refinement, and pose estimation. Extensive experiments demonstrate that CrossI2P outperforms state-of-the-art methods by 23.7% on the KITTI Odometry benchmark and by 37.9% on nuScenes, significantly improving both accuracy and robustness.
Fairness-aware Bayes optimal functional classification
May 14, 2025Algorithmic fairness has become a central topic in machine learning, and mitigating disparities across different subpopulations has emerged as a rapidly growing research area. In this paper, we systematically study the classification of functional data under fairness constraints, ensuring the disparity level of the classifier is controlled below a pre-specified threshold. We propose a unified framework for fairness-aware functional classification, tackling an infinite-dimensional functional space, addressing key challenges from the absence of density ratios and intractability of posterior probabilities, and discussing unique phenomena in functional classification. We further design a post-processing algorithm, Fair Functional Linear Discriminant Analysis classifier (Fair-FLDA), which targets at homoscedastic Gaussian processes and achieves fairness via group-wise thresholding. Under weak structural assumptions on eigenspace, theoretical guarantees on fairness and excess risk controls are established. As a byproduct, our results cover the excess risk control of the standard FLDA as a special case, which, to the best of our knowledge, is first time seen. Our theoretical findings are complemented by extensive numerical experiments on synthetic and real datasets, highlighting the practicality of our designed algorithm.
1$^{st}$ Place Solution of WWW 2025 EReL@MIR Workshop Multimodal CTR Prediction Challenge
May 06, 2025



The WWW 2025 EReL@MIR Workshop Multimodal CTR Prediction Challenge focuses on effectively applying multimodal embedding features to improve click-through rate (CTR) prediction in recommender systems. This technical report presents our 1$^{st}$ place winning solution for Task 2, combining sequential modeling and feature interaction learning to effectively capture user-item interactions. For multimodal information integration, we simply append the frozen multimodal embeddings to each item embedding. Experiments on the challenge dataset demonstrate the effectiveness of our method, achieving superior performance with a 0.9839 AUC on the leaderboard, much higher than the baseline model. Code and configuration are available in our GitHub repository and the checkpoint of our model can be found in HuggingFace.
A new method to derive the calculation formula of antenna total isotropic sensitivity
Sep 09, 2024In the OTA test of the antenna spatial performance of communication equipment,the total radiated power TRP and the total isotropic sensitivity TIS are two important characterization parameters,representing the overall transmission and reception performance of the antenna in space.In order to gain a deeper understanding of the physical meaning of these two parameters and the calculation method of TIS,this paper proposes a new method for deriving the TIS calculation formula.This method uses the reciprocity principle of the transmitting antenna and the receiving antenna.By comparing the transmitting process,two corresponding receiving antenna parameters are newly defined in the receiving process analysis.Combining the relationship between the antenna pattern and the receiving intensity,the relationship formula between TIS and equivalent isotropic sensitivity EIS is obtained after a simple deduction.This formula is consistent with the calculation formula given in the reference,but the derivation method in the reference is to use the ideal omnidirectional antenna as a reference,calculate the received power at the receiver input,and combine factors such as the actual antenna gain to derive the TIS calculation formula;the method proposed in this paper is to first derive the expression of the receiving directivity coefficient by definition,introduce the receiving strength parameter,calculate the full-space receiving power at the antenna,and derive the TIS calculation formula.In comparison,the derivation process in this paper calculates the received power from the input end of the receiving antenna,so there is no need to consider the efficiency of the antenna itself.The received power calculation starts directly from the receiving intensity.The entire derivation process is intuitive and easy to understand,avoiding complex concepts and formulas.
Accurate, fully-automated NMR spectral profiling for metabolomics
Sep 08, 2014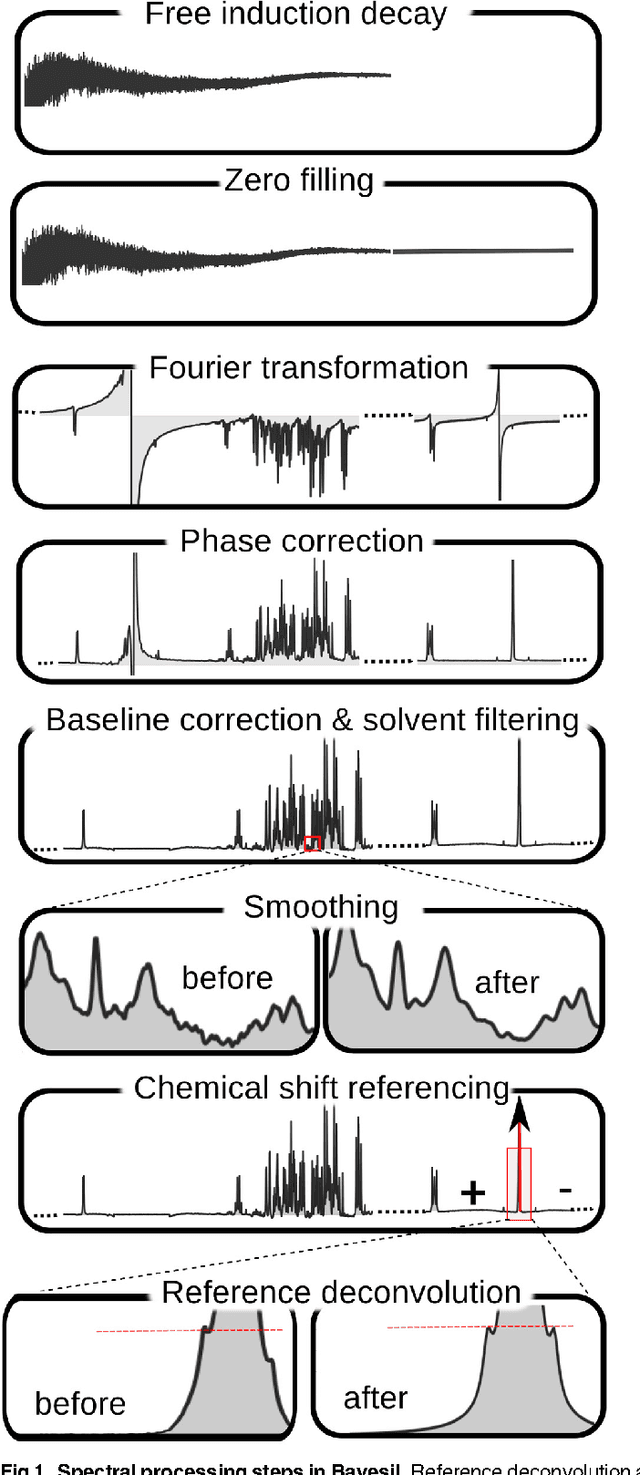
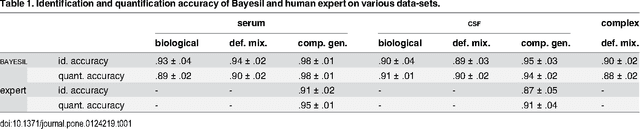
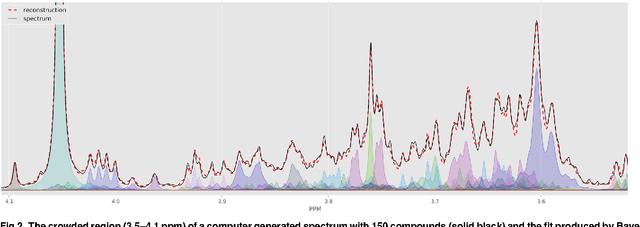
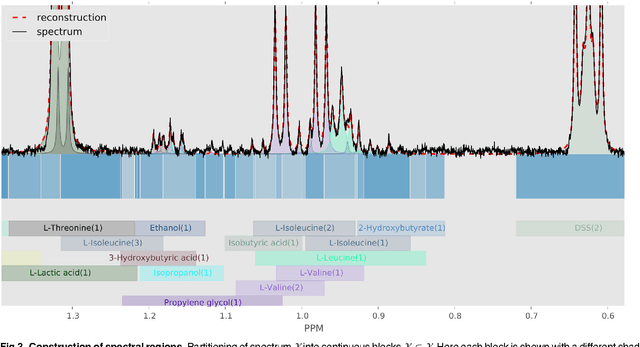
Many diseases cause significant changes to the concentrations of small molecules (aka metabolites) that appear in a person's biofluids, which means such diseases can often be readily detected from a person's "metabolic profile". This information can be extracted from a biofluid's NMR spectrum. Today, this is often done manually by trained human experts, which means this process is relatively slow, expensive and error-prone. This paper presents a tool, Bayesil, that can quickly, accurately and autonomously produce a complex biofluid's (e.g., serum or CSF) metabolic profile from a 1D1H NMR spectrum. This requires first performing several spectral processing steps then matching the resulting spectrum against a reference compound library, which contains the "signatures" of each relevant metabolite. Many of these steps are novel algorithms and our matching step views spectral matching as an inference problem within a probabilistic graphical model that rapidly approximates the most probable metabolic profile. Our extensive studies on a diverse set of complex mixtures, show that Bayesil can autonomously find the concentration of all NMR-detectable metabolites accurately (~90% correct identification and ~10% quantification error), in <5minutes on a single CPU. These results demonstrate that Bayesil is the first fully-automatic publicly-accessible system that provides quantitative NMR spectral profiling effectively -- with an accuracy that meets or exceeds the performance of trained experts. We anticipate this tool will usher in high-throughput metabolomics and enable a wealth of new applications of NMR in clinical settings. Available at http://www.bayesil.ca.