 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGazecapture
Papers and Code
WEBEYETRACK: Scalable Eye-Tracking for the Browser via On-Device Few-Shot Personalization
Aug 27, 2025With advancements in AI, new gaze estimation methods are exceeding state-of-the-art (SOTA) benchmarks, but their real-world application reveals a gap with commercial eye-tracking solutions. Factors like model size, inference time, and privacy often go unaddressed. Meanwhile, webcam-based eye-tracking methods lack sufficient accuracy, in particular due to head movement. To tackle these issues, we introduce We bEyeTrack, a framework that integrates lightweight SOTA gaze estimation models directly in the browser. It incorporates model-based head pose estimation and on-device few-shot learning with as few as nine calibration samples (k < 9). WebEyeTrack adapts to new users, achieving SOTA performance with an error margin of 2.32 cm on GazeCapture and real-time inference speeds of 2.4 milliseconds on an iPhone 14. Our open-source code is available at https://github.com/RedForestAi/WebEyeTrack.
QualitEye: Public and Privacy-preserving Gaze Data Quality Verification
Jun 06, 2025Gaze-based applications are increasingly advancing with the availability of large datasets but ensuring data quality presents a substantial challenge when collecting data at scale. It further requires different parties to collaborate, therefore, privacy concerns arise. We propose QualitEye--the first method for verifying image-based gaze data quality. QualitEye employs a new semantic representation of eye images that contains the information required for verification while excluding irrelevant information for better domain adaptation. QualitEye covers a public setting where parties can freely exchange data and a privacy-preserving setting where parties cannot reveal their raw data nor derive gaze features/labels of others with adapted private set intersection protocols. We evaluate QualitEye on the MPIIFaceGaze and GazeCapture datasets and achieve a high verification performance (with a small overhead in runtime for privacy-preserving versions). Hence, QualitEye paves the way for new gaze analysis methods at the intersection of machine learning, human-computer interaction, and cryptography.
3D Prior is All You Need: Cross-Task Few-shot 2D Gaze Estimation
Feb 06, 20253D and 2D gaze estimation share the fundamental objective of capturing eye movements but are traditionally treated as two distinct research domains. In this paper, we introduce a novel cross-task few-shot 2D gaze estimation approach, aiming to adapt a pre-trained 3D gaze estimation network for 2D gaze prediction on unseen devices using only a few training images. This task is highly challenging due to the domain gap between 3D and 2D gaze, unknown screen poses, and limited training data. To address these challenges, we propose a novel framework that bridges the gap between 3D and 2D gaze. Our framework contains a physics-based differentiable projection module with learnable parameters to model screen poses and project 3D gaze into 2D gaze. The framework is fully differentiable and can integrate into existing 3D gaze networks without modifying their original architecture. Additionally, we introduce a dynamic pseudo-labelling strategy for flipped images, which is particularly challenging for 2D labels due to unknown screen poses. To overcome this, we reverse the projection process by converting 2D labels to 3D space, where flipping is performed. Notably, this 3D space is not aligned with the camera coordinate system, so we learn a dynamic transformation matrix to compensate for this misalignment. We evaluate our method on MPIIGaze, EVE, and GazeCapture datasets, collected respectively on laptops, desktop computers, and mobile devices. The superior performance highlights the effectiveness of our approach, and demonstrates its strong potential for real-world applications.
PrivatEyes: Appearance-based Gaze Estimation Using Federated Secure Multi-Party Computation
Feb 29, 2024Latest gaze estimation methods require large-scale training data but their collection and exchange pose significant privacy risks. We propose PrivatEyes - the first privacy-enhancing training approach for appearance-based gaze estimation based on federated learning (FL) and secure multi-party computation (MPC). PrivatEyes enables training gaze estimators on multiple local datasets across different users and server-based secure aggregation of the individual estimators' updates. PrivatEyes guarantees that individual gaze data remains private even if a majority of the aggregating servers is malicious. We also introduce a new data leakage attack DualView that shows that PrivatEyes limits the leakage of private training data more effectively than previous approaches. Evaluations on the MPIIGaze, MPIIFaceGaze, GazeCapture, and NVGaze datasets further show that the improved privacy does not lead to a lower gaze estimation accuracy or substantially higher computational costs - both of which are on par with its non-secure counterparts.
Open Gaze: Open Source eye tracker for smartphone devices using Deep Learning
Aug 29, 2023Eye tracking has been a pivotal tool in diverse fields such as vision research, language analysis, and usability assessment. The majority of prior investigations, however, have concentrated on expansive desktop displays employing specialized, costly eye tracking hardware that lacks scalability. Remarkably little insight exists into ocular movement patterns on smartphones, despite their widespread adoption and significant usage. In this manuscript, we present an open-source implementation of a smartphone-based gaze tracker that emulates the methodology proposed by a GooglePaper (whose source code remains proprietary). Our focus is on attaining accuracy comparable to that attained through the GooglePaper's methodology, without the necessity for supplementary hardware. Through the integration of machine learning techniques, we unveil an accurate eye tracking solution that is native to smartphones. Our approach demonstrates precision akin to the state-of-the-art mobile eye trackers, which are characterized by a cost that is two orders of magnitude higher. Leveraging the vast MIT GazeCapture dataset, which is available through registration on the dataset's website, we successfully replicate crucial findings from previous studies concerning ocular motion behavior in oculomotor tasks and saliency analyses during natural image observation. Furthermore, we emphasize the applicability of smartphone-based gaze tracking in discerning reading comprehension challenges. Our findings exhibit the inherent potential to amplify eye movement research by significant proportions, accommodating participation from thousands of subjects with explicit consent. This scalability not only fosters advancements in vision research, but also extends its benefits to domains such as accessibility enhancement and healthcare applications.
EFE: End-to-end Frame-to-Gaze Estimation
May 09, 2023



Despite the recent development of learning-based gaze estimation methods, most methods require one or more eye or face region crops as inputs and produce a gaze direction vector as output. Cropping results in a higher resolution in the eye regions and having fewer confounding factors (such as clothing and hair) is believed to benefit the final model performance. However, this eye/face patch cropping process is expensive, erroneous, and implementation-specific for different methods. In this paper, we propose a frame-to-gaze network that directly predicts both 3D gaze origin and 3D gaze direction from the raw frame out of the camera without any face or eye cropping. Our method demonstrates that direct gaze regression from the raw downscaled frame, from FHD/HD to VGA/HVGA resolution, is possible despite the challenges of having very few pixels in the eye region. The proposed method achieves comparable results to state-of-the-art methods in Point-of-Gaze (PoG) estimation on three public gaze datasets: GazeCapture, MPIIFaceGaze, and EVE, and generalizes well to extreme camera view changes.
One Eye is All You Need: Lightweight Ensembles for Gaze Estimation with Single Encoders
Nov 22, 2022Gaze estimation has grown rapidly in accuracy in recent years. However, these models often fail to take advantage of different computer vision (CV) algorithms and techniques (such as small ResNet and Inception networks and ensemble models) that have been shown to improve results for other CV problems. Additionally, most current gaze estimation models require the use of either both eyes or an entire face, whereas real-world data may not always have both eyes in high resolution. Thus, we propose a gaze estimation model that implements the ResNet and Inception model architectures and makes predictions using only one eye image. Furthermore, we propose an ensemble calibration network that uses the predictions from several individual architectures for subject-specific predictions. With the use of lightweight architectures, we achieve high performance on the GazeCapture dataset with very low model parameter counts. When using two eyes as input, we achieve a prediction error of 1.591 cm on the test set without calibration and 1.439 cm with an ensemble calibration model. With just one eye as input, we still achieve an average prediction error of 2.312 cm on the test set without calibration and 1.951 cm with an ensemble calibration model. We also notice significantly lower errors on the right eye images in the test set, which could be important in the design of future gaze estimation-based tools.
Adaptive Feature Fusion Network for Gaze Tracking in Mobile Tablets
Mar 20, 2021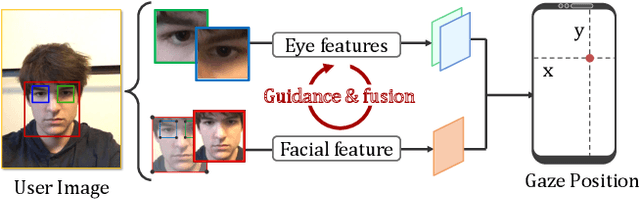
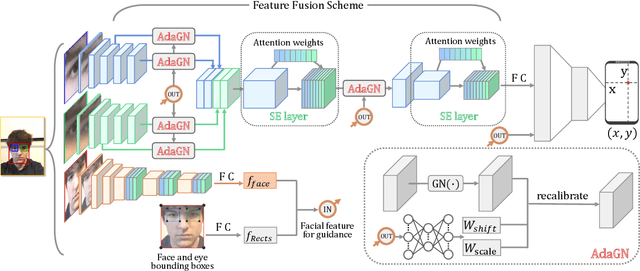
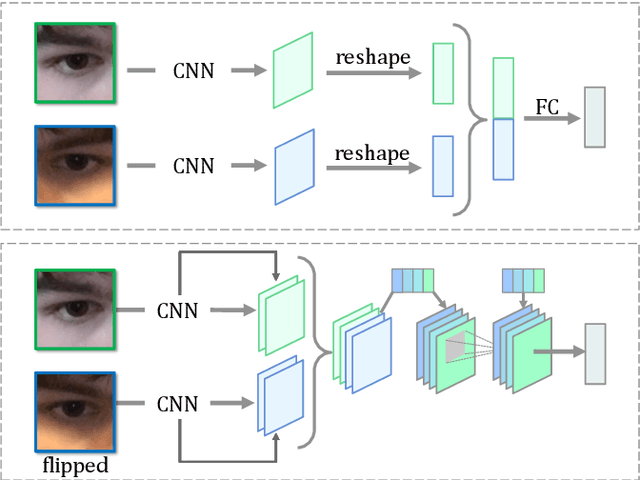
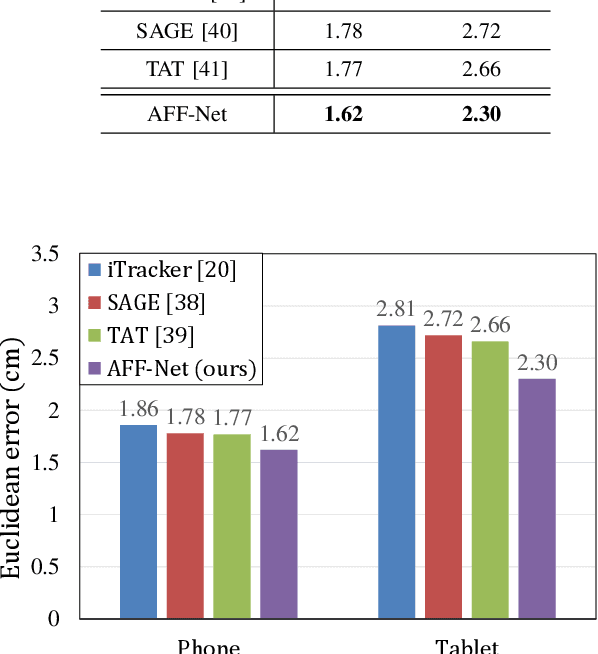
Recently, many multi-stream gaze estimation methods have been proposed. They estimate gaze from eye and face appearances and achieve reasonable accuracy. However, most of the methods simply concatenate the features extracted from eye and face appearance. The feature fusion process has been ignored. In this paper, we propose a novel Adaptive Feature Fusion Network (AFF-Net), which performs gaze tracking task in mobile tablets. We stack two-eye feature maps and utilize Squeeze-and-Excitation layers to adaptively fuse two-eye features according to their similarity on appearance. Meanwhile, we also propose Adaptive Group Normalization to recalibrate eye features with the guidance of facial feature. Extensive experiments on both GazeCapture and MPIIFaceGaze datasets demonstrate consistently superior performance of the proposed method.
Towards Hardware-Agnostic Gaze-Trackers
Oct 11, 2020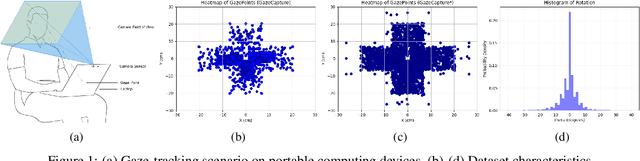
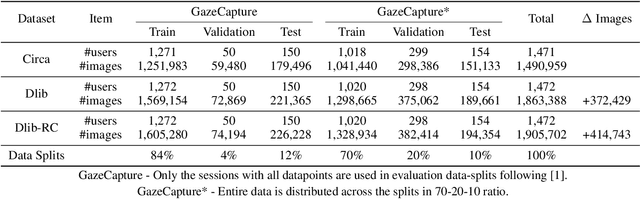
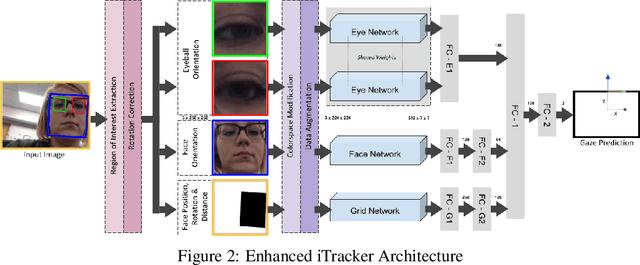
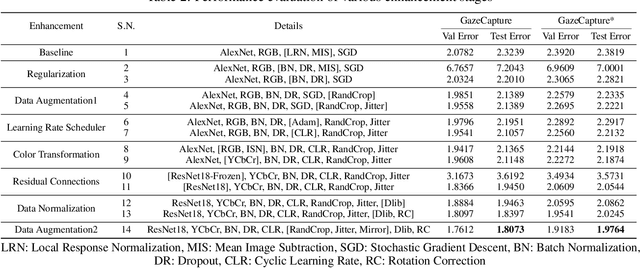
Gaze-tracking is a novel way of interacting with computers which allows new scenarios, such as enabling people with motor-neuron disabilities to control their computers or doctors to interact with patient information without touching screen or keyboard. Further, there are emerging applications of gaze-tracking in interactive gaming, user experience research, human attention analysis and behavioral studies. Accurate estimation of the gaze may involve accounting for head-pose, head-position, eye rotation, distance from the object as well as operating conditions such as illumination, occlusion, background noise and various biological aspects of the user. Commercially available gaze-trackers utilize specialized sensor assemblies that usually consist of an infrared light source and camera. There are several challenges in the universal proliferation of gaze-tracking as accessibility technologies, specifically its affordability, reliability, and ease-of-use. In this paper, we try to address these challenges through the development of a hardware-agnostic gaze-tracker. We present a deep neural network architecture as an appearance-based method for constrained gaze-tracking that utilizes facial imagery captured on an ordinary RGB camera ubiquitous in all modern computing devices. Our system achieved an error of 1.8073cm on GazeCapture dataset without any calibration or device specific fine-tuning. This research shows promise that one day soon any computer, tablet, or phone will be controllable using just your eyes due to the prediction capabilities of deep neutral networks.
A Generalized and Robust Method Towards Practical Gaze Estimation on Smart Phone
Oct 16, 2019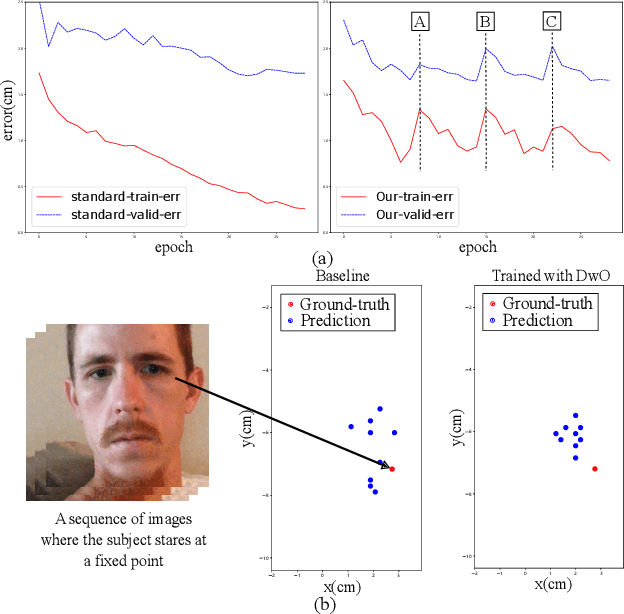
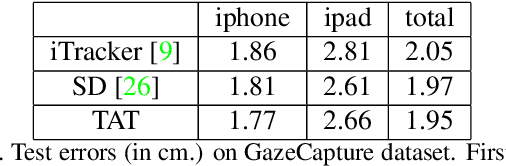
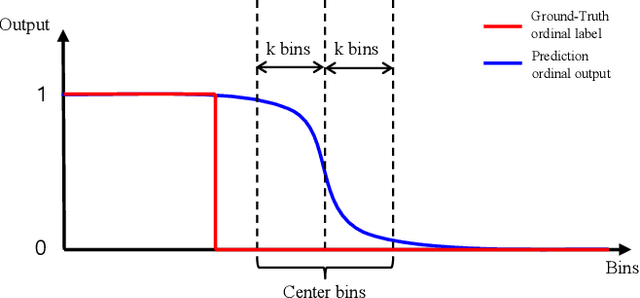
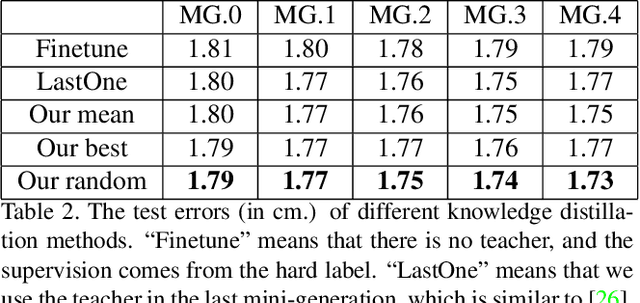
Gaze estimation for ordinary smart phone, e.g. estimating where the user is looking at on the phone screen, can be applied in various applications. However, the widely used appearance-based CNN methods still have two issues for practical adoption. First, due to the limited dataset, gaze estimation is very likely to suffer from over-fitting, leading to poor accuracy at run time. Second, the current methods are usually not robust, i.e. their prediction results having notable jitters even when the user is performing gaze fixation, which degrades user experience greatly. For the first issue, we propose a new tolerant and talented (TAT) training scheme, which is an iterative random knowledge distillation framework enhanced with cosine similarity pruning and aligned orthogonal initialization. The knowledge distillation is a tolerant teaching process providing diverse and informative supervision. The enhanced pruning and initialization is a talented learning process prompting the network to escape from the local minima and re-born from a better start. For the second issue, we define a new metric to measure the robustness of gaze estimator, and propose an adversarial training based Disturbance with Ordinal loss (DwO) method to improve it. The experimental results show that our TAT method achieves state-of-the-art performance on GazeCapture dataset, and that our DwO method improves the robustness while keeping comparable accuracy.