 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Large Language Models to Detect Socially Shared Regulation of Collaborative Learning
Jan 08, 2026The field of learning analytics has made notable strides in automating the detection of complex learning processes in multimodal data. However, most advancements have focused on individualized problem-solving instead of collaborative, open-ended problem-solving, which may offer both affordances (richer data) and challenges (low cohesion) to behavioral prediction. Here, we extend predictive models to automatically detect socially shared regulation of learning (SSRL) behaviors in collaborative computational modeling environments using embedding-based approaches. We leverage large language models (LLMs) as summarization tools to generate task-aware representations of student dialogue aligned with system logs. These summaries, combined with text-only embeddings, context-enriched embeddings, and log-derived features, were used to train predictive models. Results show that text-only embeddings often achieve stronger performance in detecting SSRL behaviors related to enactment or group dynamics (e.g., off-task behavior or requesting assistance). In contrast, contextual and multimodal features provide complementary benefits for constructs such as planning and reflection. Overall, our findings highlight the promise of embedding-based models for extending learning analytics by enabling scalable detection of SSRL behaviors, ultimately supporting real-time feedback and adaptive scaffolding in collaborative learning environments that teachers value.
Designing Gaze Analytics for ELA Instruction: A User-Centered Dashboard with Conversational AI Support
Sep 03, 2025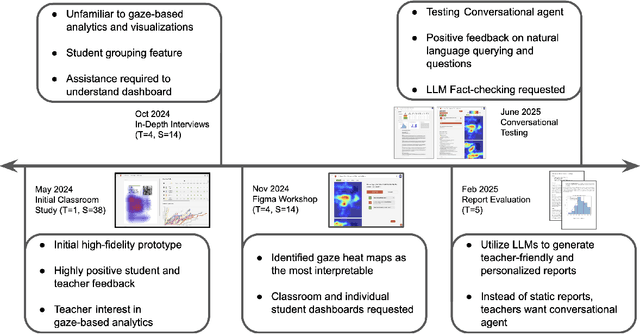
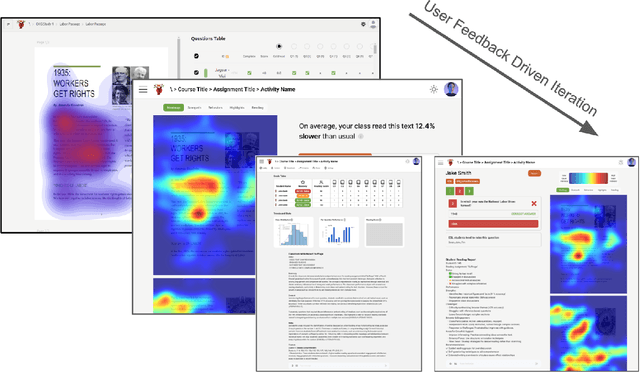
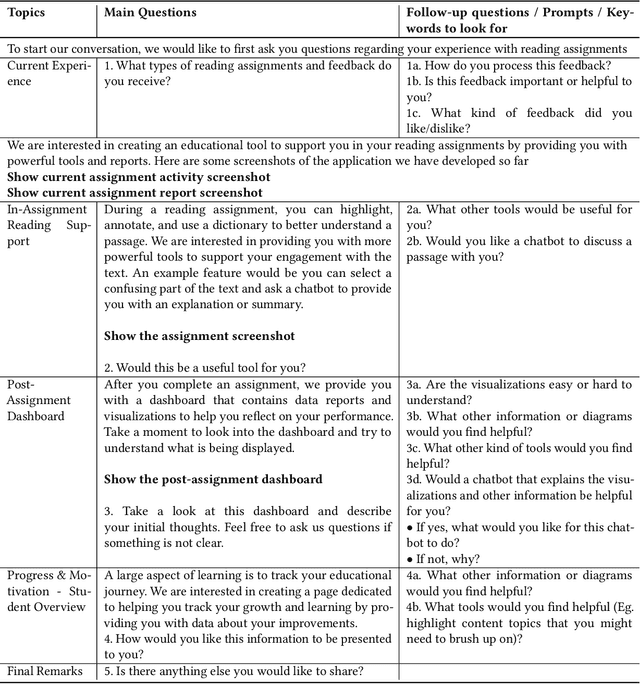
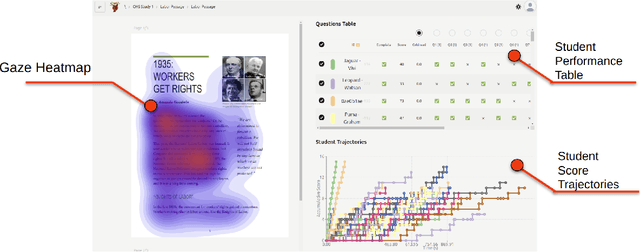
Eye-tracking offers rich insights into student cognition and engagement, but remains underutilized in classroom-facing educational technology due to challenges in data interpretation and accessibility. In this paper, we present the iterative design and evaluation of a gaze-based learning analytics dashboard for English Language Arts (ELA), developed through five studies involving teachers and students. Guided by user-centered design and data storytelling principles, we explored how gaze data can support reflection, formative assessment, and instructional decision-making. Our findings demonstrate that gaze analytics can be approachable and pedagogically valuable when supported by familiar visualizations, layered explanations, and narrative scaffolds. We further show how a conversational agent, powered by a large language model (LLM), can lower cognitive barriers to interpreting gaze data by enabling natural language interactions with multimodal learning analytics. We conclude with design implications for future EdTech systems that aim to integrate novel data modalities in classroom contexts.
WEBEYETRACK: Scalable Eye-Tracking for the Browser via On-Device Few-Shot Personalization
Aug 27, 2025With advancements in AI, new gaze estimation methods are exceeding state-of-the-art (SOTA) benchmarks, but their real-world application reveals a gap with commercial eye-tracking solutions. Factors like model size, inference time, and privacy often go unaddressed. Meanwhile, webcam-based eye-tracking methods lack sufficient accuracy, in particular due to head movement. To tackle these issues, we introduce We bEyeTrack, a framework that integrates lightweight SOTA gaze estimation models directly in the browser. It incorporates model-based head pose estimation and on-device few-shot learning with as few as nine calibration samples (k < 9). WebEyeTrack adapts to new users, achieving SOTA performance with an error margin of 2.32 cm on GazeCapture and real-time inference speeds of 2.4 milliseconds on an iPhone 14. Our open-source code is available at https://github.com/RedForestAi/WebEyeTrack.
Personalizing Student-Agent Interactions Using Log-Contextualized Retrieval Augmented Generation (RAG)
May 22, 2025Collaborative dialogue offers rich insights into students' learning and critical thinking. This is essential for adapting pedagogical agents to students' learning and problem-solving skills in STEM+C settings. While large language models (LLMs) facilitate dynamic pedagogical interactions, potential hallucinations can undermine confidence, trust, and instructional value. Retrieval-augmented generation (RAG) grounds LLM outputs in curated knowledge, but its effectiveness depends on clear semantic links between user input and a knowledge base, which are often weak in student dialogue. We propose log-contextualized RAG (LC-RAG), which enhances RAG retrieval by incorporating environment logs to contextualize collaborative discourse. Our findings show that LC-RAG improves retrieval over a discourse-only baseline and allows our collaborative peer agent, Copa, to deliver relevant, personalized guidance that supports students' critical thinking and epistemic decision-making in a collaborative computational modeling environment, XYZ.
LLMs as Educational Analysts: Transforming Multimodal Data Traces into Actionable Reading Assessment Reports
Mar 03, 2025



Reading assessments are essential for enhancing students' comprehension, yet many EdTech applications focus mainly on outcome-based metrics, providing limited insights into student behavior and cognition. This study investigates the use of multimodal data sources -- including eye-tracking data, learning outcomes, assessment content, and teaching standards -- to derive meaningful reading insights. We employ unsupervised learning techniques to identify distinct reading behavior patterns, and then a large language model (LLM) synthesizes the derived information into actionable reports for educators, streamlining the interpretation process. LLM experts and human educators evaluate these reports for clarity, accuracy, relevance, and pedagogical usefulness. Our findings indicate that LLMs can effectively function as educational analysts, turning diverse data into teacher-friendly insights that are well-received by educators. While promising for automating insight generation, human oversight remains crucial to ensure reliability and fairness. This research advances human-centered AI in education, connecting data-driven analytics with practical classroom applications.
Beyond Instructed Tasks: Recognizing In-the-Wild Reading Behaviors in the Classroom Using Eye Tracking
Jan 30, 2025



Understanding reader behaviors such as skimming, deep reading, and scanning is essential for improving educational instruction. While prior eye-tracking studies have trained models to recognize reading behaviors, they often rely on instructed reading tasks, which can alter natural behaviors and limit the applicability of these findings to in-the-wild settings. Additionally, there is a lack of clear definitions for reading behavior archetypes in the literature. We conducted a classroom study to address these issues by collecting instructed and in-the-wild reading data. We developed a mixed-method framework, including a human-driven theoretical model, statistical analyses, and an AI classifier, to differentiate reading behaviors based on their velocity, density, and sequentiality. Our lightweight 2D CNN achieved an F1 score of 0.8 for behavior recognition, providing a robust approach for understanding in-the-wild reading. This work advances our ability to provide detailed behavioral insights to educators, supporting more targeted and effective assessment and instruction.