 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCcg Supertagging
Papers and Code
Integrating Supertag Features into Neural Discontinuous Constituent Parsing
Oct 11, 2024



Syntactic parsing is essential in natural-language processing, with constituent structure being one widely used description of syntax. Traditional views of constituency demand that constituents consist of adjacent words, but this poses challenges in analysing syntax with non-local dependencies, common in languages like German. Therefore, in a number of treebanks like NeGra and TIGER for German and DPTB for English, long-range dependencies are represented by crossing edges. Various grammar formalisms have been used to describe discontinuous trees - often with high time complexities for parsing. Transition-based parsing aims at reducing this factor by eliminating the need for an explicit grammar. Instead, neural networks are trained to produce trees given raw text input using supervised learning on large annotated corpora. An elegant proposal for a stack-free transition-based parser developed by Coavoux and Cohen (2019) successfully allows for the derivation of any discontinuous constituent tree over a sentence in worst-case quadratic time. The purpose of this work is to explore the introduction of supertag information into transition-based discontinuous constituent parsing. In lexicalised grammar formalisms like CCG (Steedman, 1989) informative categories are assigned to the words in a sentence and act as the building blocks for composing the sentence's syntax. These supertags indicate a word's structural role and syntactic relationship with surrounding items. The study examines incorporating supertag information by using a dedicated supertagger as additional input for a neural parser (pipeline) and by jointly training a neural model for both parsing and supertagging (multi-task). In addition to CCG, several other frameworks (LTAG-spinal, LCFRS) and sequence labelling tasks (chunking, dependency parsing) will be compared in terms of their suitability as auxiliary tasks for parsing.
Something Old, Something New: Grammar-based CCG Parsing with Transformer Models
Sep 28, 2021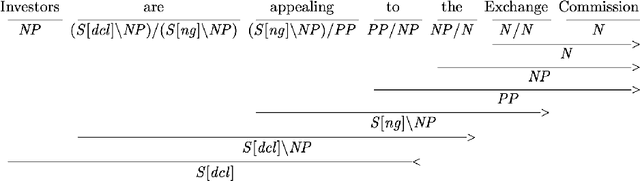
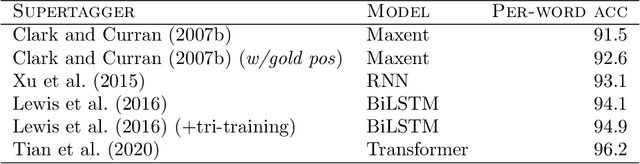


This report describes the parsing problem for Combinatory Categorial Grammar (CCG), showing how a combination of Transformer-based neural models and a symbolic CCG grammar can lead to substantial gains over existing approaches. The report also documents a 20-year research program, showing how NLP methods have evolved over this time. The staggering accuracy improvements provided by neural models for CCG parsing can be seen as a reflection of the improvements seen in NLP more generally. The report provides a minimal introduction to CCG and CCG parsing, with many pointers to the relevant literature. It then describes the CCG supertagging problem, and some recent work from Tian et al. (2020) which applies Transformer-based models to supertagging with great effect. I use this existing model to develop a CCG multitagger, which can serve as a front-end to an existing CCG parser. Simply using this new multitagger provides substantial gains in parsing accuracy. I then show how a Transformer-based model from the parsing literature can be combined with the grammar-based CCG parser, setting a new state-of-the-art for the CCGbank parsing task of almost 93% F-score for labelled dependencies, with complete sentence accuracies of over 50%.
Supertagging Combinatory Categorial Grammar with Attentive Graph Convolutional Networks
Oct 13, 2020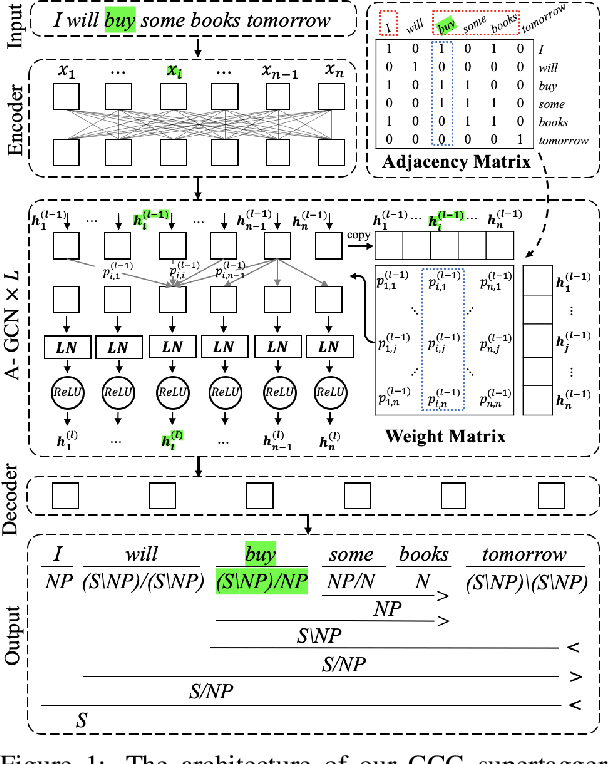
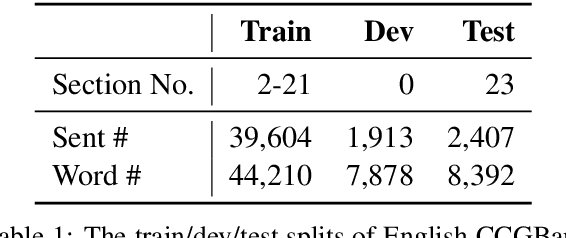

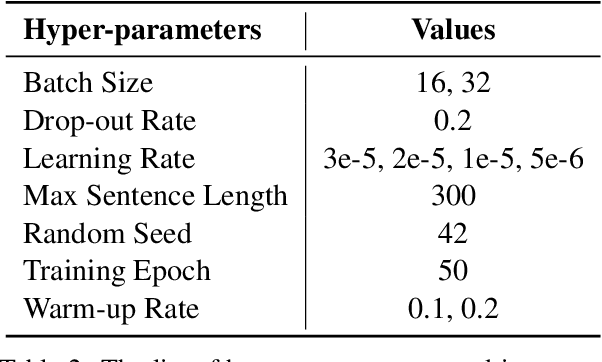
Supertagging is conventionally regarded as an important task for combinatory categorial grammar (CCG) parsing, where effective modeling of contextual information is highly important to this task. However, existing studies have made limited efforts to leverage contextual features except for applying powerful encoders (e.g., bi-LSTM). In this paper, we propose attentive graph convolutional networks to enhance neural CCG supertagging through a novel solution of leveraging contextual information. Specifically, we build the graph from chunks (n-grams) extracted from a lexicon and apply attention over the graph, so that different word pairs from the contexts within and across chunks are weighted in the model and facilitate the supertagging accordingly. The experiments performed on the CCGbank demonstrate that our approach outperforms all previous studies in terms of both supertagging and parsing. Further analyses illustrate the effectiveness of each component in our approach to discriminatively learn from word pairs to enhance CCG supertagging.
Supertagging the Long Tail with Tree-Structured Decoding of Complex Categories
Dec 11, 2020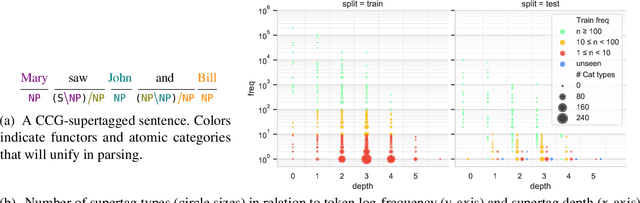


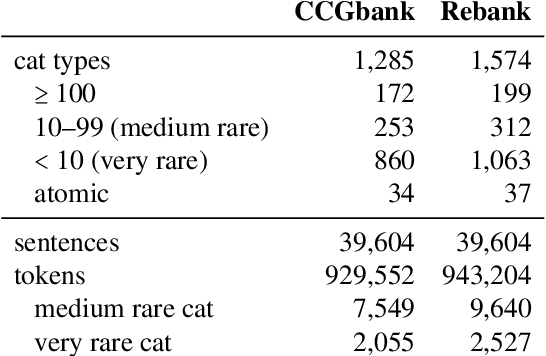
Although current CCG supertaggers achieve high accuracy on the standard WSJ test set, few systems make use of the categories' internal structure that will drive the syntactic derivation during parsing. The tagset is traditionally truncated, discarding the many rare and complex category types in the long tail. However, supertags are themselves trees. Rather than give up on rare tags, we investigate constructive models that account for their internal structure, including novel methods for tree-structured prediction. Our best tagger is capable of recovering a sizeable fraction of the long-tail supertags and even generates CCG categories that have never been seen in training, while approximating the prior state of the art in overall tag accuracy with fewer parameters. We further investigate how well different approaches generalize to out-of-domain evaluation sets.
Hierarchically-Refined Label Attention Network for Sequence Labeling
Aug 26, 2019



CRF has been used as a powerful model for statistical sequence labeling. For neural sequence labeling, however, BiLSTM-CRF does not always lead to better results compared with BiLSTM-softmax local classification. This can be because the simple Markov label transition model of CRF does not give much information gain over strong neural encoding. For better representing label sequences, we investigate a hierarchically-refined label attention network, which explicitly leverages label embeddings and captures potential long-term label dependency by giving each word incrementally refined label distributions with hierarchical attention. Results on POS tagging, NER and CCG supertagging show that the proposed model not only improves the overall tagging accuracy with similar number of parameters, but also significantly speeds up the training and testing compared to BiLSTM-CRF.
Probing What Different NLP Tasks Teach Machines about Function Word Comprehension
Apr 25, 2019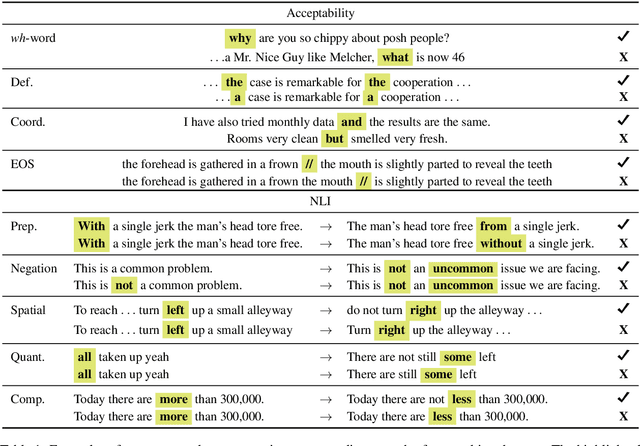
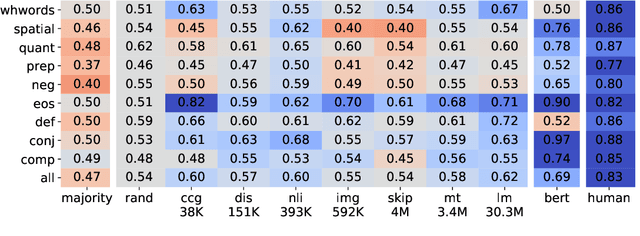

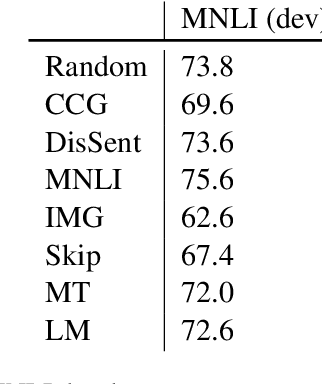
We introduce a set of nine challenge tasks that test for the understanding of function words. These tasks are created by structurally mutating sentences from existing datasets to target the comprehension of specific types of function words (e.g., prepositions, wh-words). Using these probing tasks, we explore the effects of various pretraining objectives for sentence encoders (e.g., language modeling, CCG supertagging and natural language inference (NLI)) on the learned representations. Our results show that pretraining on CCG---our most syntactic objective---performs the best on average across our probing tasks, suggesting that syntactic knowledge helps function word comprehension. Language modeling also shows strong performance, supporting its widespread use for pretraining state-of-the-art NLP models. Overall, no pretraining objective dominates across the board, and our function word probing tasks highlight several intuitive differences between pretraining objectives, e.g., that NLI helps the comprehension of negation.
An Empirical Investigation of Global and Local Normalization for Recurrent Neural Sequence Models Using a Continuous Relaxation to Beam Search
Apr 15, 2019
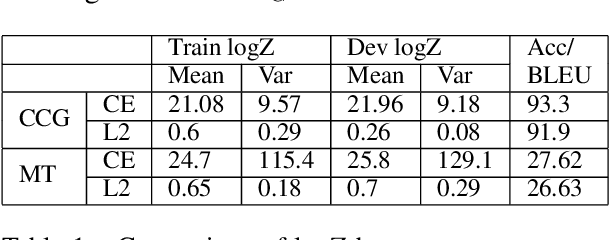
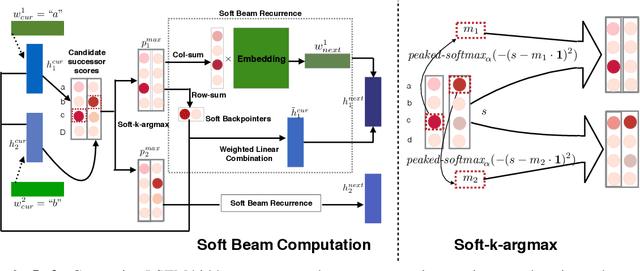
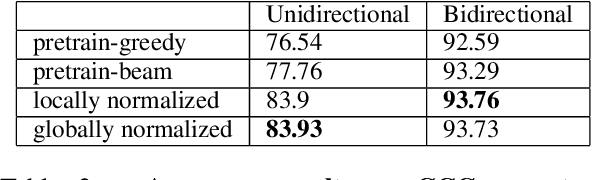
Globally normalized neural sequence models are considered superior to their locally normalized equivalents because they may ameliorate the effects of label bias. However, when considering high-capacity neural parametrizations that condition on the whole input sequence, both model classes are theoretically equivalent in terms of the distributions they are capable of representing. Thus, the practical advantage of global normalization in the context of modern neural methods remains unclear. In this paper, we attempt to shed light on this problem through an empirical study. We extend an approach for search-aware training via a continuous relaxation of beam search (Goyal et al., 2017b) in order to enable training of globally normalized recurrent sequence models through simple backpropagation. We then use this technique to conduct an empirical study of the interaction between global normalization, high-capacity encoders, and search-aware optimization. We observe that in the context of inexact search, globally normalized neural models are still more effective than their locally normalized counterparts. Further, since our training approach is sensitive to warm-starting with pre-trained models, we also propose a novel initialization strategy based on self-normalization for pre-training globally normalized models. We perform analysis of our approach on two tasks: CCG supertagging and Machine Translation, and demonstrate the importance of global normalization under different conditions while using search-aware training.
Targeted Syntactic Evaluation of Language Models
Aug 27, 2018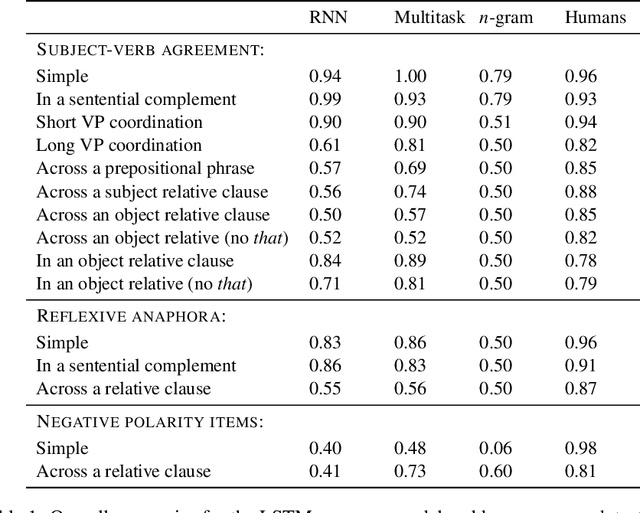
We present a dataset for evaluating the grammaticality of the predictions of a language model. We automatically construct a large number of minimally different pairs of English sentences, each consisting of a grammatical and an ungrammatical sentence. The sentence pairs represent different variations of structure-sensitive phenomena: subject-verb agreement, reflexive anaphora and negative polarity items. We expect a language model to assign a higher probability to the grammatical sentence than the ungrammatical one. In an experiment using this data set, an LSTM language model performed poorly on many of the constructions. Multi-task training with a syntactic objective (CCG supertagging) improved the LSTM's accuracy, but a large gap remained between its performance and the accuracy of human participants recruited online. This suggests that there is considerable room for improvement over LSTMs in capturing syntax in a language model.
Predicting Target Language CCG Supertags Improves Neural Machine Translation
Jul 18, 2017
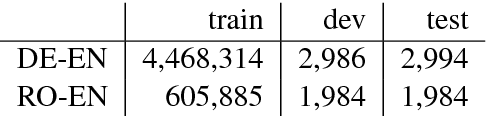
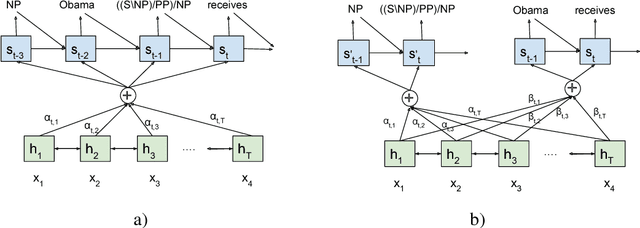
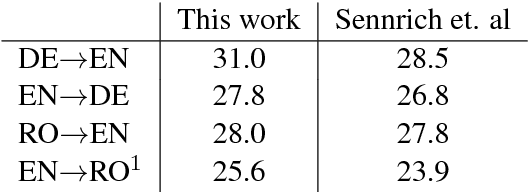
Neural machine translation (NMT) models are able to partially learn syntactic information from sequential lexical information. Still, some complex syntactic phenomena such as prepositional phrase attachment are poorly modeled. This work aims to answer two questions: 1) Does explicitly modeling target language syntax help NMT? 2) Is tight integration of words and syntax better than multitask training? We introduce syntactic information in the form of CCG supertags in the decoder, by interleaving the target supertags with the word sequence. Our results on WMT data show that explicitly modeling target-syntax improves machine translation quality for German->English, a high-resource pair, and for Romanian->English, a low-resource pair and also several syntactic phenomena including prepositional phrase attachment. Furthermore, a tight coupling of words and syntax improves translation quality more than multitask training. By combining target-syntax with adding source-side dependency labels in the embedding layer, we obtain a total improvement of 0.9 BLEU for German->English and 1.2 BLEU for Romanian->English.
A Dynamic Window Neural Network for CCG Supertagging
Oct 10, 2016



Combinatory Category Grammar (CCG) supertagging is a task to assign lexical categories to each word in a sentence. Almost all previous methods use fixed context window sizes as input features. However, it is obvious that different tags usually rely on different context window sizes. These motivate us to build a supertagger with a dynamic window approach, which can be treated as an attention mechanism on the local contexts. Applying dropout on the dynamic filters can be seen as drop on words directly, which is superior to the regular dropout on word embeddings. We use this approach to demonstrate the state-of-the-art CCG supertagging performance on the standard test set.