 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlt
Papers and Code
An Inversion Theorem for Buffered Linear Toeplitz (BLT) Matrices and Applications to Streaming Differential Privacy
Apr 30, 2025Buffered Linear Toeplitz (BLT) matrices are a family of parameterized lower-triangular matrices that play an important role in streaming differential privacy with correlated noise. Our main result is a BLT inversion theorem: the inverse of a BLT matrix is itself a BLT matrix with different parameters. We also present an efficient and differentiable $O(d^3)$ algorithm to compute the parameters of the inverse BLT matrix, where $d$ is the degree of the original BLT (typically $d < 10$). Our characterization enables direct optimization of BLT parameters for privacy mechanisms through automatic differentiation.
Byte Latent Transformer: Patches Scale Better Than Tokens
Dec 13, 2024We introduce the Byte Latent Transformer (BLT), a new byte-level LLM architecture that, for the first time, matches tokenization-based LLM performance at scale with significant improvements in inference efficiency and robustness. BLT encodes bytes into dynamically sized patches, which serve as the primary units of computation. Patches are segmented based on the entropy of the next byte, allocating more compute and model capacity where increased data complexity demands it. We present the first FLOP controlled scaling study of byte-level models up to 8B parameters and 4T training bytes. Our results demonstrate the feasibility of scaling models trained on raw bytes without a fixed vocabulary. Both training and inference efficiency improve due to dynamically selecting long patches when data is predictable, along with qualitative improvements on reasoning and long tail generalization. Overall, for fixed inference costs, BLT shows significantly better scaling than tokenization-based models, by simultaneously growing both patch and model size.
A Hassle-free Algorithm for Private Learning in Practice: Don't Use Tree Aggregation, Use BLTs
Aug 16, 2024



The state-of-the-art for training on-device language models for mobile keyboard applications combines federated learning (FL) with differential privacy (DP) via the DP-Follow-the-Regularized-Leader (DP-FTRL) algorithm. Two variants of DP-FTRL are used in practice, tree aggregation and matrix factorization. However, tree aggregation suffers from significantly suboptimal privacy/utility tradeoffs, while matrix mechanisms require expensive optimization parameterized by hard-to-estimate-in-advance constants, and high runtime memory costs.This paper extends the recently introduced Buffered Linear Toeplitz (BLT) mechanism to multi-participation scenarios. Our BLT-DP-FTRL maintains the ease-of-use advantages of tree aggregation, while essentially matching matrix factorization in terms of utility and privacy. We evaluate BLT-DP-FTRL on the StackOverflow dataset, serving as a re-producible simulation benchmark, and across four on-device language model tasks in a production FL system. Our empirical results highlight the advantages of the BLT mechanism and elevate the practicality and effectiveness of DP in real-world scenarios.
BLT: Can Large Language Models Handle Basic Legal Text?
Nov 16, 2023


We find that the best publicly available LLMs like GPT-4 and PaLM 2 currently perform poorly at basic text handling required of lawyers or paralegals, such as looking up the text at a line of a witness deposition or at a subsection of a contract. We introduce a benchmark to quantify this poor performance, which casts into doubt LLMs' current reliability as-is for legal practice. Finetuning for these tasks brings an older LLM to near-perfect performance on our test set and also raises performance on a related legal task. This stark result highlights the need for more domain expertise in LLM training.
Uncertainty Quantification of MLE for Entity Ranking with Covariates
Dec 20, 2022This paper concerns with statistical estimation and inference for the ranking problems based on pairwise comparisons with additional covariate information such as the attributes of the compared items. Despite extensive studies, few prior literatures investigate this problem under the more realistic setting where covariate information exists. To tackle this issue, we propose a novel model, Covariate-Assisted Ranking Estimation (CARE) model, that extends the well-known Bradley-Terry-Luce (BTL) model, by incorporating the covariate information. Specifically, instead of assuming every compared item has a fixed latent score $\{\theta_i^*\}_{i=1}^n$, we assume the underlying scores are given by $\{\alpha_i^*+{x}_i^\top\beta^*\}_{i=1}^n$, where $\alpha_i^*$ and ${x}_i^\top\beta^*$ represent latent baseline and covariate score of the $i$-th item, respectively. We impose natural identifiability conditions and derive the $\ell_{\infty}$- and $\ell_2$-optimal rates for the maximum likelihood estimator of $\{\alpha_i^*\}_{i=1}^{n}$ and $\beta^*$ under a sparse comparison graph, using a novel `leave-one-out' technique (Chen et al., 2019) . To conduct statistical inferences, we further derive asymptotic distributions for the MLE of $\{\alpha_i^*\}_{i=1}^n$ and $\beta^*$ with minimal sample complexity. This allows us to answer the question whether some covariates have any explanation power for latent scores and to threshold some sparse parameters to improve the ranking performance. We improve the approximation method used in (Gao et al., 2021) for the BLT model and generalize it to the CARE model. Moreover, we validate our theoretical results through large-scale numerical studies and an application to the mutual fund stock holding dataset.
C2FTrans: Coarse-to-Fine Transformers for Medical Image Segmentation
Jun 29, 2022
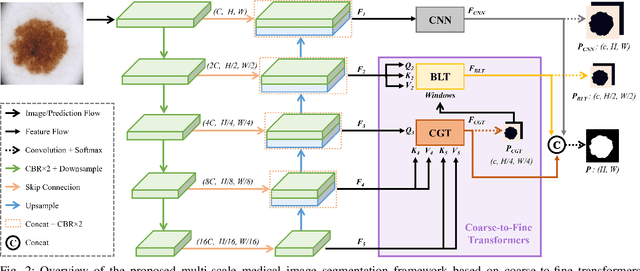
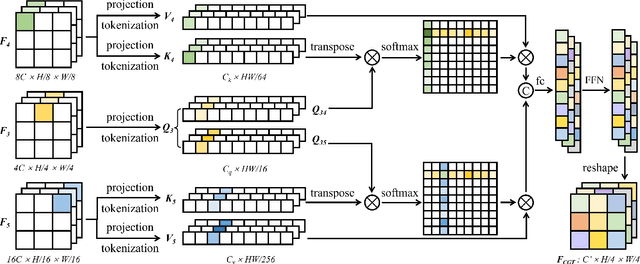
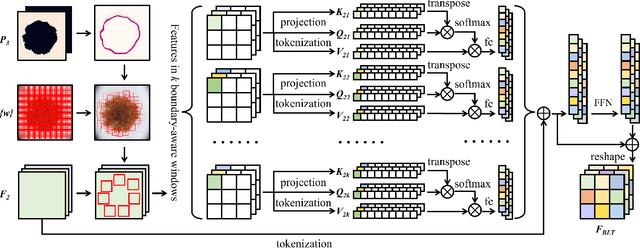
Convolutional neural networks (CNN), the most prevailing architecture for deep-learning based medical image analysis, are still functionally limited by their intrinsic inductive biases and inadequate receptive fields. Transformer, born to address this issue, has drawn explosive attention in natural language processing and computer vision due to its remarkable ability in capturing long-range dependency. However, most recent transformer-based methods for medical image segmentation directly apply vanilla transformers as an auxiliary module in CNN-based methods, resulting in severe detail loss due to the rigid patch partitioning scheme in transformers. To address this problem, we propose C2FTrans, a novel multi-scale architecture that formulates medical image segmentation as a coarse-to-fine procedure. C2FTrans mainly consists of a cross-scale global transformer (CGT) which addresses local contextual similarity in CNN and a boundary-aware local transformer (BLT) which overcomes boundary uncertainty brought by rigid patch partitioning in transformers. Specifically, CGT builds global dependency across three different small-scale feature maps to obtain rich global semantic features with an acceptable computational cost, while BLT captures mid-range dependency by adaptively generating windows around boundaries under the guidance of entropy to reduce computational complexity and minimize detail loss based on large-scale feature maps. Extensive experimental results on three public datasets demonstrate the superior performance of C2FTrans against state-of-the-art CNN-based and transformer-based methods with fewer parameters and lower FLOPs. We believe the design of C2FTrans would further inspire future work on developing efficient and lightweight transformers for medical image segmentation. The source code of this paper is publicly available at https://github.com/xianlin7/C2FTrans.
BLT: Bidirectional Layout Transformer for Controllable Layout Generation
Dec 09, 2021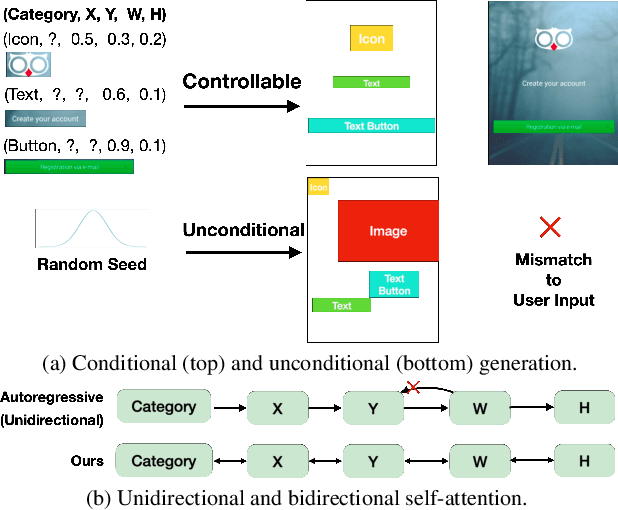
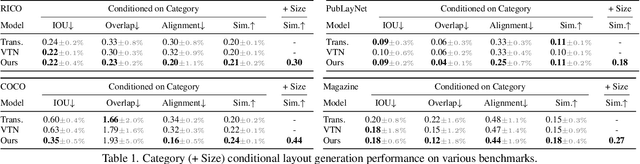
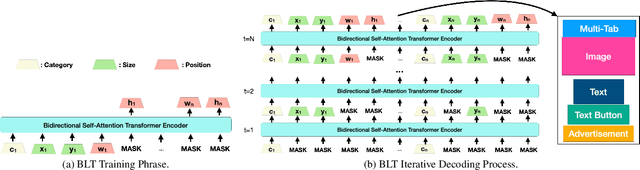
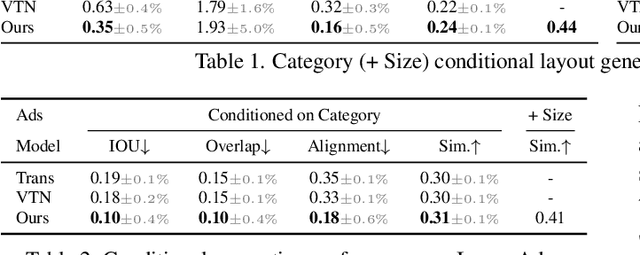
Creating visual layouts is an important step in graphic design. Automatic generation of such layouts is important as we seek scale-able and diverse visual designs. Prior works on automatic layout generation focus on unconditional generation, in which the models generate layouts while neglecting user needs for specific problems. To advance conditional layout generation, we introduce BLT, a bidirectional layout transformer. BLT differs from autoregressive decoding as it first generates a draft layout that satisfies the user inputs and then refines the layout iteratively. We verify the proposed model on multiple benchmarks with various fidelity metrics. Our results demonstrate two key advances to the state-of-the-art layout transformer models. First, our model empowers layout transformers to fulfill controllable layout generation. Second, our model slashes the linear inference time in autoregressive decoding into a constant complexity, thereby achieving 4x-10x speedups in generating a layout at inference time.
You Better Look Twice: a new perspective for designing accurate detectors with reduced computations
Aug 03, 2021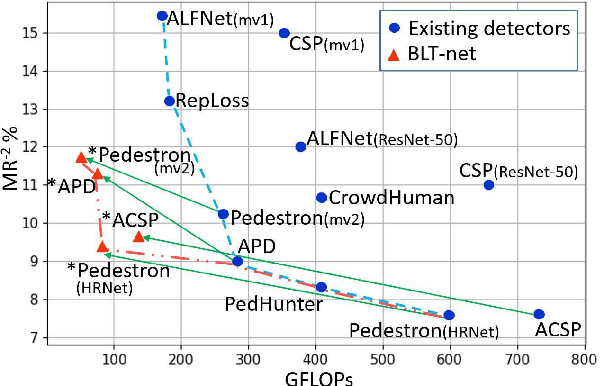
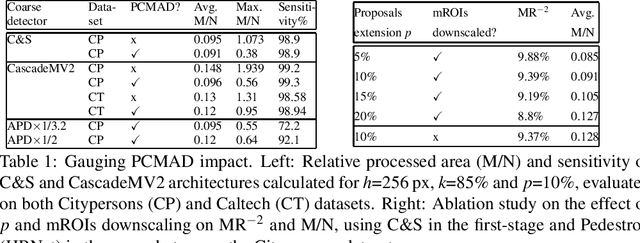
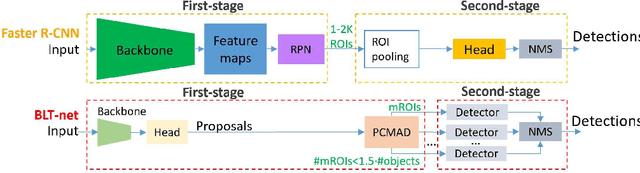
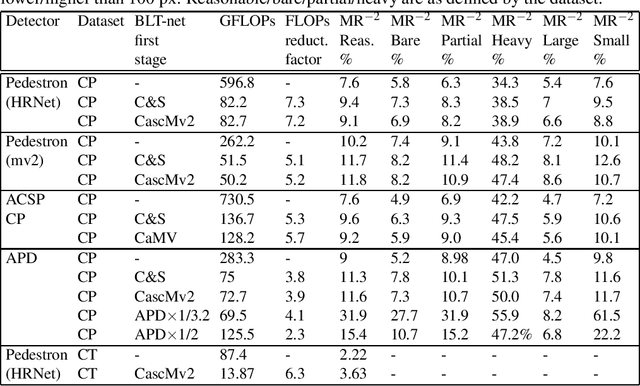
General object detectors use powerful backbones that uniformly extract features from images for enabling detection of a vast amount of object types. However, utilization of such backbones in object detection applications developed for specific object types can unnecessarily over-process an extensive amount of background. In addition, they are agnostic to object scales, thus redundantly process all image regions at the same resolution. In this work we introduce BLT-net, a new low-computation two-stage object detection architecture designed to process images with a significant amount of background and objects of variate scales. BLT-net reduces computations by separating objects from background using a very lite first-stage. BLT-net then efficiently merges obtained proposals to further decrease processed background and then dynamically reduces their resolution to minimize computations. Resulting image proposals are then processed in the second-stage by a highly accurate model. We demonstrate our architecture on the pedestrian detection problem, where objects are of different sizes, images are of high resolution and object detection is required to run in real-time. We show that our design reduces computations by a factor of x4-x7 on the Citypersons and Caltech datasets with respect to leading pedestrian detectors, on account of a small accuracy degradation. This method can be applied on other object detection applications in scenes with a considerable amount of background and variate object sizes to reduce computations.
How to Make a BLT Sandwich? Learning to Reason towards Understanding Web Instructional Videos
Dec 06, 2018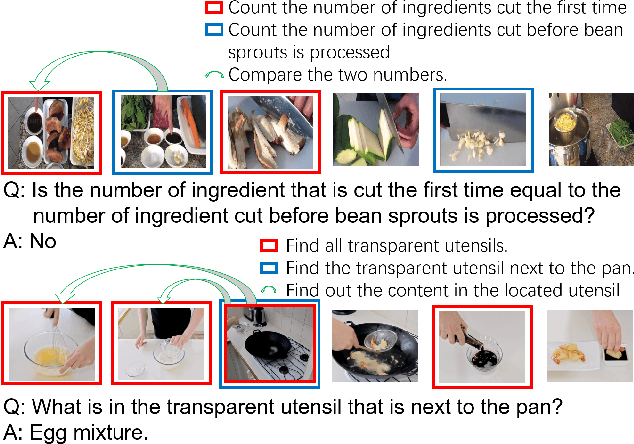
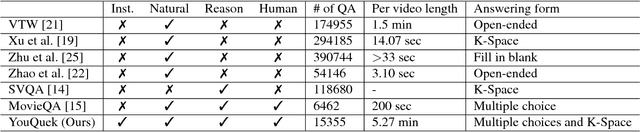
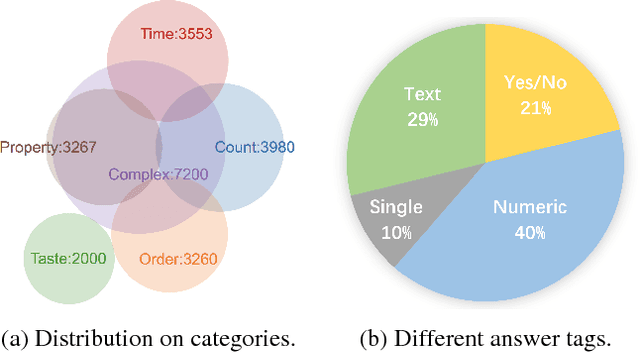
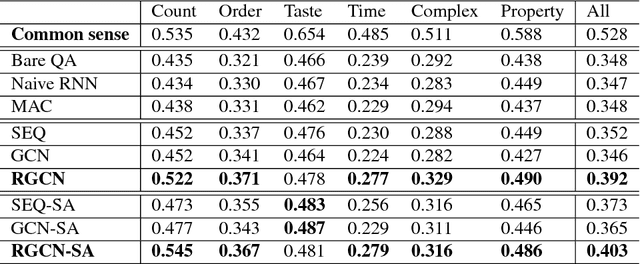
Understanding web instructional videos is an essential branch of video understanding in two aspects. First, most existing video methods focus on short-term actions for a-few-second-long video clips; these methods are not directly applicable to long videos. Second, unlike unconstrained long videos, e.g., movies, instructional videos are more structured in that they have step-by-step procedure constraining the understanding task. In this paper, we study reasoning on instructional videos via question-answering (QA). Surprisingly, it has not been an emphasis in the video community despite its rich applications. We thereby introduce YouQuek, an annotated QA dataset for instructional videos based on the recent YouCook2. The questions in YouQuek are not limited to cues on one frame but related to logical reasoning in the temporal dimension. Observing the lack of effective representations for modeling long videos, we propose a set of carefully designed models including a novel Recurrent Graph Convolutional Network (RGCN) that captures both temporal order and relation information. Furthermore, we study multiple modalities including description and transcripts for the purpose of boosting video understanding. Extensive experiments on YouQuek suggest that RGCN performs the best in terms of QA accuracy and a better performance is gained by introducing human annotated description.