 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Multi Person Pose Estimation Absolute
3D multi-person pose estimation (absolute) is the process of estimating the 3D poses of multiple people in a global coordinate system.
Papers and Code
Group Inertial Poser: Multi-Person Pose and Global Translation from Sparse Inertial Sensors and Ultra-Wideband Ranging
Oct 24, 2025Tracking human full-body motion using sparse wearable inertial measurement units (IMUs) overcomes the limitations of occlusion and instrumentation of the environment inherent in vision-based approaches. However, purely IMU-based tracking compromises translation estimates and accurate relative positioning between individuals, as inertial cues are inherently self-referential and provide no direct spatial reference for others. In this paper, we present a novel approach for robustly estimating body poses and global translation for multiple individuals by leveraging the distances between sparse wearable sensors - both on each individual and across multiple individuals. Our method Group Inertial Poser estimates these absolute distances between pairs of sensors from ultra-wideband ranging (UWB) and fuses them with inertial observations as input into structured state-space models to integrate temporal motion patterns for precise 3D pose estimation. Our novel two-step optimization further leverages the estimated distances for accurately tracking people's global trajectories through the world. We also introduce GIP-DB, the first IMU+UWB dataset for two-person tracking, which comprises 200 minutes of motion recordings from 14 participants. In our evaluation, Group Inertial Poser outperforms previous state-of-the-art methods in accuracy and robustness across synthetic and real-world data, showing the promise of IMU+UWB-based multi-human motion capture in the wild. Code, models, dataset: https://github.com/eth-siplab/GroupInertialPoser
Mocap-2-to-3: Lifting 2D Diffusion-Based Pretrained Models for 3D Motion Capture
Mar 05, 2025



Recovering absolute poses in the world coordinate system from monocular views presents significant challenges. Two primary issues arise in this context. Firstly, existing methods rely on 3D motion data for training, which requires collection in limited environments. Acquiring such 3D labels for new actions in a timely manner is impractical, severely restricting the model's generalization capabilities. In contrast, 2D poses are far more accessible and easier to obtain. Secondly, estimating a person's absolute position in metric space from a single viewpoint is inherently more complex. To address these challenges, we introduce Mocap-2-to-3, a novel framework that decomposes intricate 3D motions into 2D poses, leveraging 2D data to enhance 3D motion reconstruction in diverse scenarios and accurately predict absolute positions in the world coordinate system. We initially pretrain a single-view diffusion model with extensive 2D data, followed by fine-tuning a multi-view diffusion model for view consistency using publicly available 3D data. This strategy facilitates the effective use of large-scale 2D data. Additionally, we propose an innovative human motion representation that decouples local actions from global movements and encodes geometric priors of the ground, ensuring the generative model learns accurate motion priors from 2D data. During inference, this allows for the gradual recovery of global movements, resulting in more plausible positioning. We evaluate our model's performance on real-world datasets, demonstrating superior accuracy in motion and absolute human positioning compared to state-of-the-art methods, along with enhanced generalization and scalability. Our code will be made publicly available.
CasCalib: Cascaded Calibration for Motion Capture from Sparse Unsynchronized Cameras
May 10, 2024



It is now possible to estimate 3D human pose from monocular images with off-the-shelf 3D pose estimators. However, many practical applications require fine-grained absolute pose information for which multi-view cues and camera calibration are necessary. Such multi-view recordings are laborious because they require manual calibration, and are expensive when using dedicated hardware. Our goal is full automation, which includes temporal synchronization, as well as intrinsic and extrinsic camera calibration. This is done by using persons in the scene as the calibration objects. Existing methods either address only synchronization or calibration, assume one of the former as input, or have significant limitations. A common limitation is that they only consider single persons, which eases correspondence finding. We attain this generality by partitioning the high-dimensional time and calibration space into a cascade of subspaces and introduce tailored algorithms to optimize each efficiently and robustly. The outcome is an easy-to-use, flexible, and robust motion capture toolbox that we release to enable scientific applications, which we demonstrate on diverse multi-view benchmarks. Project website: https://github.com/jamestang1998/CasCalib.
Advancing Smart Malnutrition Monitoring: A Multi-Modal Learning Approach for Vital Health Parameter Estimation
Jul 31, 2023



Malnutrition poses a significant threat to global health, resulting from an inadequate intake of essential nutrients that adversely impacts vital organs and overall bodily functioning. Periodic examinations and mass screenings, incorporating both conventional and non-invasive techniques, have been employed to combat this challenge. However, these approaches suffer from critical limitations, such as the need for additional equipment, lack of comprehensive feature representation, absence of suitable health indicators, and the unavailability of smartphone implementations for precise estimations of Body Fat Percentage (BFP), Basal Metabolic Rate (BMR), and Body Mass Index (BMI) to enable efficient smart-malnutrition monitoring. To address these constraints, this study presents a groundbreaking, scalable, and robust smart malnutrition-monitoring system that leverages a single full-body image of an individual to estimate height, weight, and other crucial health parameters within a multi-modal learning framework. Our proposed methodology involves the reconstruction of a highly precise 3D point cloud, from which 512-dimensional feature embeddings are extracted using a headless-3D classification network. Concurrently, facial and body embeddings are also extracted, and through the application of learnable parameters, these features are then utilized to estimate weight accurately. Furthermore, essential health metrics, including BMR, BFP, and BMI, are computed to conduct a comprehensive analysis of the subject's health, subsequently facilitating the provision of personalized nutrition plans. While being robust to a wide range of lighting conditions across multiple devices, our model achieves a low Mean Absolute Error (MAE) of $\pm$ 4.7 cm and $\pm$ 5.3 kg in estimating height and weight.
Dual networks based 3D Multi-Person Pose Estimation from Monocular Video
May 06, 2022


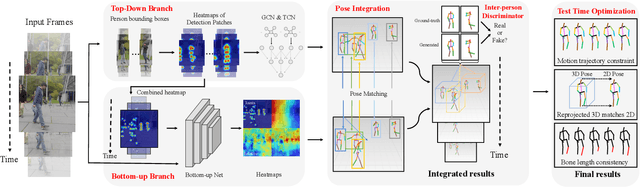
Monocular 3D human pose estimation has made progress in recent years. Most of the methods focus on single persons, which estimate the poses in the person-centric coordinates, i.e., the coordinates based on the center of the target person. Hence, these methods are inapplicable for multi-person 3D pose estimation, where the absolute coordinates (e.g., the camera coordinates) are required. Moreover, multi-person pose estimation is more challenging than single pose estimation, due to inter-person occlusion and close human interactions. Existing top-down multi-person methods rely on human detection (i.e., top-down approach), and thus suffer from the detection errors and cannot produce reliable pose estimation in multi-person scenes. Meanwhile, existing bottom-up methods that do not use human detection are not affected by detection errors, but since they process all persons in a scene at once, they are prone to errors, particularly for persons in small scales. To address all these challenges, we propose the integration of top-down and bottom-up approaches to exploit their strengths. Our top-down network estimates human joints from all persons instead of one in an image patch, making it robust to possible erroneous bounding boxes. Our bottom-up network incorporates human-detection based normalized heatmaps, allowing the network to be more robust in handling scale variations. Finally, the estimated 3D poses from the top-down and bottom-up networks are fed into our integration network for final 3D poses. To address the common gaps between training and testing data, we do optimization during the test time, by refining the estimated 3D human poses using high-order temporal constraint, re-projection loss, and bone length regularizations. Our evaluations demonstrate the effectiveness of the proposed method. Code and models are available: https://github.com/3dpose/3D-Multi-Person-Pose.
Scene-Aware 3D Multi-Human Motion Capture from a Single Camera
Jan 12, 2023In this work, we consider the problem of estimating the 3D position of multiple humans in a scene as well as their body shape and articulation from a single RGB video recorded with a static camera. In contrast to expensive marker-based or multi-view systems, our lightweight setup is ideal for private users as it enables an affordable 3D motion capture that is easy to install and does not require expert knowledge. To deal with this challenging setting, we leverage recent advances in computer vision using large-scale pre-trained models for a variety of modalities, including 2D body joints, joint angles, normalized disparity maps, and human segmentation masks. Thus, we introduce the first non-linear optimization-based approach that jointly solves for the absolute 3D position of each human, their articulated pose, their individual shapes as well as the scale of the scene. In particular, we estimate the scene depth and person unique scale from normalized disparity predictions using the 2D body joints and joint angles. Given the per-frame scene depth, we reconstruct a point-cloud of the static scene in 3D space. Finally, given the per-frame 3D estimates of the humans and scene point-cloud, we perform a space-time coherent optimization over the video to ensure temporal, spatial and physical plausibility. We evaluate our method on established multi-person 3D human pose benchmarks where we consistently outperform previous methods and we qualitatively demonstrate that our method is robust to in-the-wild conditions including challenging scenes with people of different sizes.
Transformer-based Global 3D Hand Pose Estimation in Two Hands Manipulating Objects Scenarios
Oct 20, 2022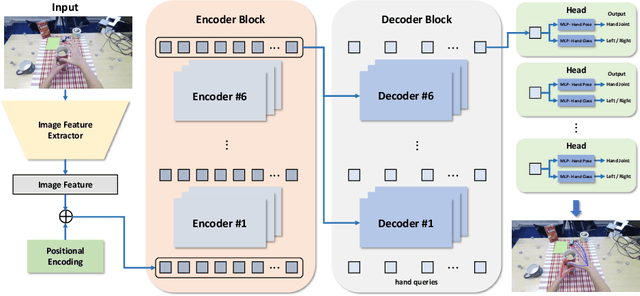
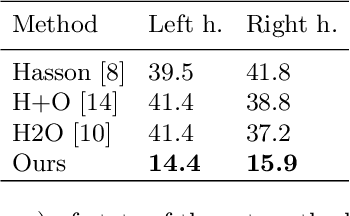
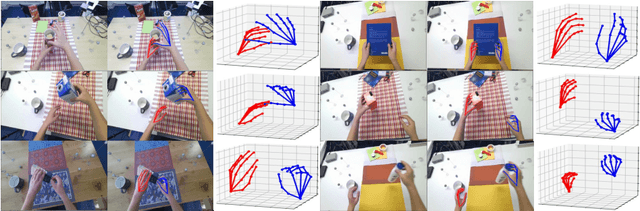

This report describes our 1st place solution to ECCV 2022 challenge on Human Body, Hands, and Activities (HBHA) from Egocentric and Multi-view Cameras (hand pose estimation). In this challenge, we aim to estimate global 3D hand poses from the input image where two hands and an object are interacting on the egocentric viewpoint. Our proposed method performs end-to-end multi-hand pose estimation via transformer architecture. In particular, our method robustly estimates hand poses in a scenario where two hands interact. Additionally, we propose an algorithm that considers hand scales to robustly estimate the absolute depth. The proposed algorithm works well even when the hand sizes are various for each person. Our method attains 14.4 mm (left) and 15.9 mm (right) errors for each hand in the test set.
SMAP: Single-Shot Multi-Person Absolute 3D Pose Estimation
Aug 26, 2020
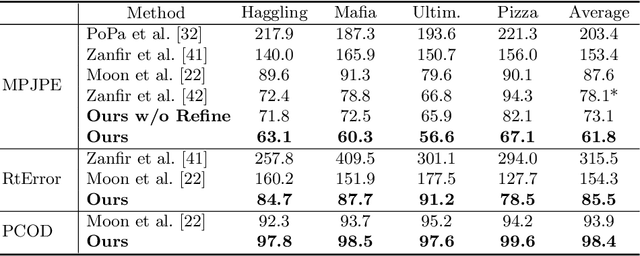
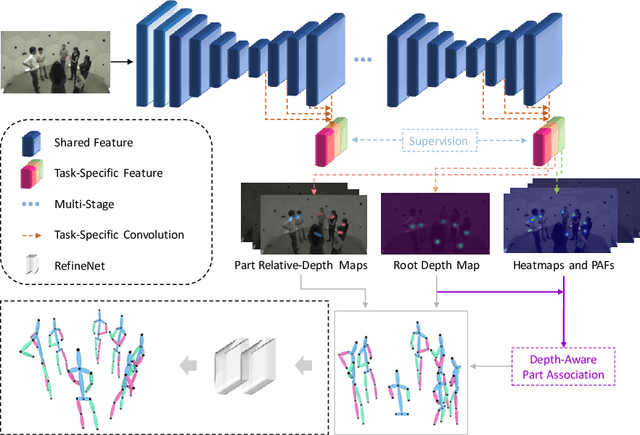
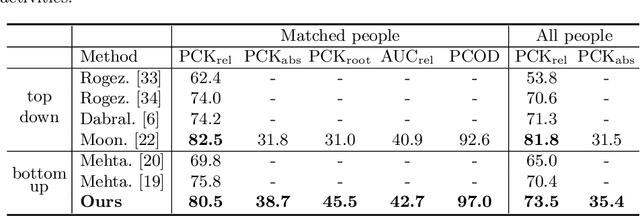
Recovering multi-person 3D poses with absolute scales from a single RGB image is a challenging problem due to the inherent depth and scale ambiguity from a single view. Addressing this ambiguity requires to aggregate various cues over the entire image, such as body sizes, scene layouts, and inter-person relationships. However, most previous methods adopt a top-down scheme that first performs 2D pose detection and then regresses the 3D pose and scale for each detected person individually, ignoring global contextual cues. In this paper, we propose a novel system that first regresses a set of 2.5D representations of body parts and then reconstructs the 3D absolute poses based on these 2.5D representations with a depth-aware part association algorithm. Such a single-shot bottom-up scheme allows the system to better learn and reason about the inter-person depth relationship, improving both 3D and 2D pose estimation. The experiments demonstrate that the proposed approach achieves the state-of-the-art performance on the CMU Panoptic and MuPoTS-3D datasets and is applicable to in-the-wild videos.
Multi-Person Absolute 3D Human Pose Estimation with Weak Depth Supervision
Apr 08, 2020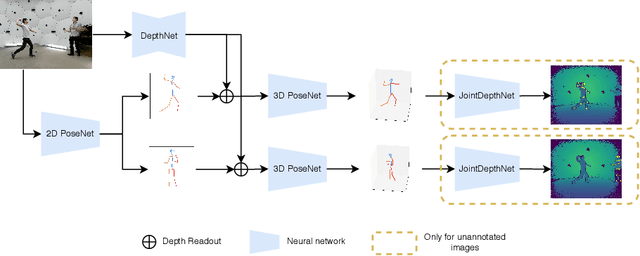
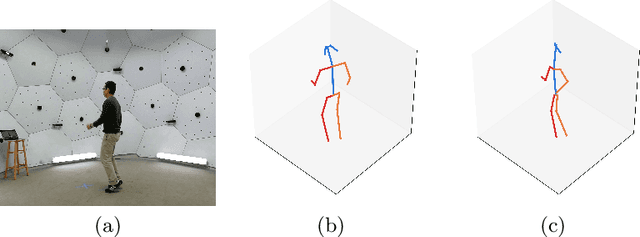


In 3D human pose estimation one of the biggest problems is the lack of large, diverse datasets. This is especially true for multi-person 3D pose estimation, where, to our knowledge, there are only machine generated annotations available for training. To mitigate this issue, we introduce a network that can be trained with additional RGB-D images in a weakly supervised fashion. Due to the existence of cheap sensors, videos with depth maps are widely available, and our method can exploit a large, unannotated dataset. Our algorithm is a monocular, multi-person, absolute pose estimator. We evaluate the algorithm on several benchmarks, showing a consistent improvement in error rates. Also, our model achieves state-of-the-art results on the MuPoTS-3D dataset by a considerable margin.
Improving Robustness and Accuracy via Relative Information Encoding in 3D Human Pose Estimation
Jul 29, 2021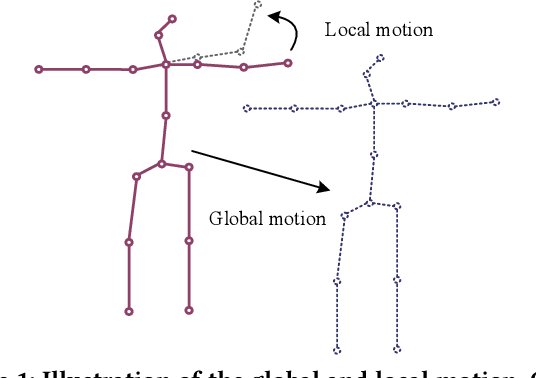
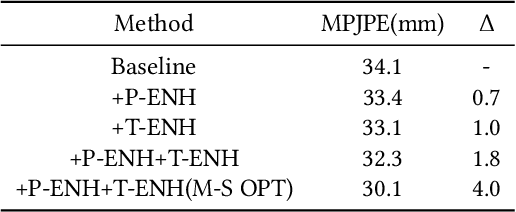
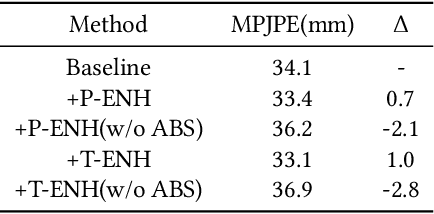
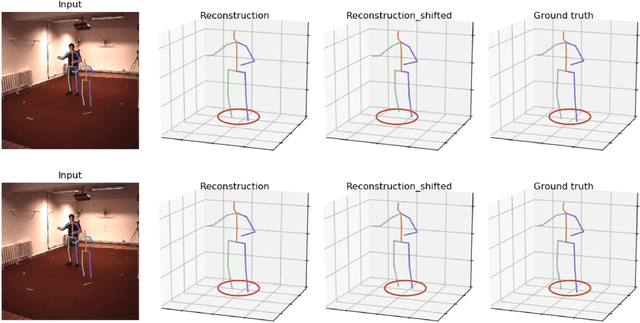
Most of the existing 3D human pose estimation approaches mainly focus on predicting 3D positional relationships between the root joint and other human joints (local motion) instead of the overall trajectory of the human body (global motion). Despite the great progress achieved by these approaches, they are not robust to global motion, and lack the ability to accurately predict local motion with a small movement range. To alleviate these two problems, we propose a relative information encoding method that yields positional and temporal enhanced representations. Firstly, we encode positional information by utilizing relative coordinates of 2D poses to enhance the consistency between the input and output distribution. The same posture with different absolute 2D positions can be mapped to a common representation. It is beneficial to resist the interference of global motion on the prediction results. Second, we encode temporal information by establishing the connection between the current pose and other poses of the same person within a period of time. More attention will be paid to the movement changes before and after the current pose, resulting in better prediction performance on local motion with a small movement range. The ablation studies validate the effectiveness of the proposed relative information encoding method. Besides, we introduce a multi-stage optimization method to the whole framework to further exploit the positional and temporal enhanced representations. Our method outperforms state-of-the-art methods on two public datasets. Code is available at https://github.com/paTRICK-swk/Pose3D-RIE.