 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Evaluation of Federated Learning on Biomedical Natural Language Processing
Jul 20, 2023Language models (LMs) like BERT and GPT have revolutionized natural language processing (NLP). However, privacy-sensitive domains, particularly the medical field, face challenges to train LMs due to limited data access and privacy constraints imposed by regulations like the Health Insurance Portability and Accountability Act (HIPPA) and the General Data Protection Regulation (GDPR). Federated learning (FL) offers a decentralized solution that enables collaborative learning while ensuring the preservation of data privacy. In this study, we systematically evaluate FL in medicine across $2$ biomedical NLP tasks using $6$ LMs encompassing $8$ corpora. Our results showed that: 1) FL models consistently outperform LMs trained on individual client's data and sometimes match the model trained with polled data; 2) With the fixed number of total data, LMs trained using FL with more clients exhibit inferior performance, but pre-trained transformer-based models exhibited greater resilience. 3) LMs trained using FL perform nearly on par with the model trained with pooled data when clients' data are IID distributed while exhibiting visible gaps with non-IID data. Our code is available at: https://github.com/PL97/FedNLP
Communication-Efficient Vertical Federated Learning with Limited Overlapping Samples
Mar 30, 2023



Federated learning is a popular collaborative learning approach that enables clients to train a global model without sharing their local data. Vertical federated learning (VFL) deals with scenarios in which the data on clients have different feature spaces but share some overlapping samples. Existing VFL approaches suffer from high communication costs and cannot deal efficiently with limited overlapping samples commonly seen in the real world. We propose a practical vertical federated learning (VFL) framework called \textbf{one-shot VFL} that can solve the communication bottleneck and the problem of limited overlapping samples simultaneously based on semi-supervised learning. We also propose \textbf{few-shot VFL} to improve the accuracy further with just one more communication round between the server and the clients. In our proposed framework, the clients only need to communicate with the server once or only a few times. We evaluate the proposed VFL framework on both image and tabular datasets. Our methods can improve the accuracy by more than 46.5\% and reduce the communication cost by more than 330$\times$ compared with state-of-the-art VFL methods when evaluated on CIFAR-10. Our code will be made publicly available at \url{https://nvidia.github.io/NVFlare/research/one-shot-vfl}.
Fair Federated Medical Image Segmentation via Client Contribution Estimation
Mar 29, 2023How to ensure fairness is an important topic in federated learning (FL). Recent studies have investigated how to reward clients based on their contribution (collaboration fairness), and how to achieve uniformity of performance across clients (performance fairness). Despite achieving progress on either one, we argue that it is critical to consider them together, in order to engage and motivate more diverse clients joining FL to derive a high-quality global model. In this work, we propose a novel method to optimize both types of fairness simultaneously. Specifically, we propose to estimate client contribution in gradient and data space. In gradient space, we monitor the gradient direction differences of each client with respect to others. And in data space, we measure the prediction error on client data using an auxiliary model. Based on this contribution estimation, we propose a FL method, federated training via contribution estimation (FedCE), i.e., using estimation as global model aggregation weights. We have theoretically analyzed our method and empirically evaluated it on two real-world medical datasets. The effectiveness of our approach has been validated with significant performance improvements, better collaboration fairness, better performance fairness, and comprehensive analytical studies.
MONAI: An open-source framework for deep learning in healthcare
Nov 04, 2022



Artificial Intelligence (AI) is having a tremendous impact across most areas of science. Applications of AI in healthcare have the potential to improve our ability to detect, diagnose, prognose, and intervene on human disease. For AI models to be used clinically, they need to be made safe, reproducible and robust, and the underlying software framework must be aware of the particularities (e.g. geometry, physiology, physics) of medical data being processed. This work introduces MONAI, a freely available, community-supported, and consortium-led PyTorch-based framework for deep learning in healthcare. MONAI extends PyTorch to support medical data, with a particular focus on imaging, and provide purpose-specific AI model architectures, transformations and utilities that streamline the development and deployment of medical AI models. MONAI follows best practices for software-development, providing an easy-to-use, robust, well-documented, and well-tested software framework. MONAI preserves the simple, additive, and compositional approach of its underlying PyTorch libraries. MONAI is being used by and receiving contributions from research, clinical and industrial teams from around the world, who are pursuing applications spanning nearly every aspect of healthcare.
NVIDIA FLARE: Federated Learning from Simulation to Real-World
Oct 24, 2022



Federated learning (FL) enables building robust and generalizable AI models by leveraging diverse datasets from multiple collaborators without centralizing the data. We created NVIDIA FLARE as an open-source software development kit (SDK) to make it easier for data scientists to use FL in their research and real-world applications. The SDK includes solutions for state-of-the-art FL algorithms and federated machine learning approaches, which facilitate building workflows for distributed learning across enterprises and enable platform developers to create a secure, privacy-preserving offering for multiparty collaboration utilizing homomorphic encryption or differential privacy. The SDK is a lightweight, flexible, and scalable Python package, and allows researchers to bring their data science workflows implemented in any training libraries (PyTorch, TensorFlow, XGBoost, or even NumPy) and apply them in real-world FL settings. This paper introduces the key design principles of FLARE and illustrates some use cases (e.g., COVID analysis) with customizable FL workflows that implement different privacy-preserving algorithms. Code is available at https://github.com/NVIDIA/NVFlare.
Split-U-Net: Preventing Data Leakage in Split Learning for Collaborative Multi-Modal Brain Tumor Segmentation
Aug 22, 2022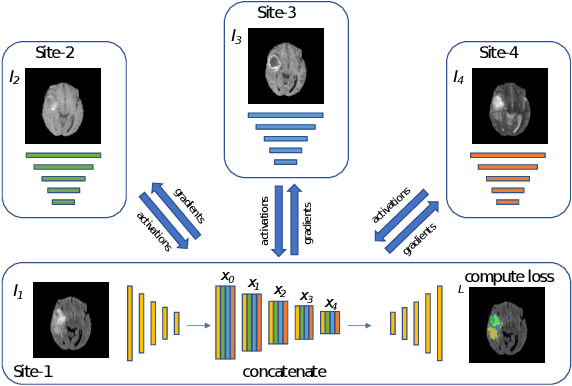

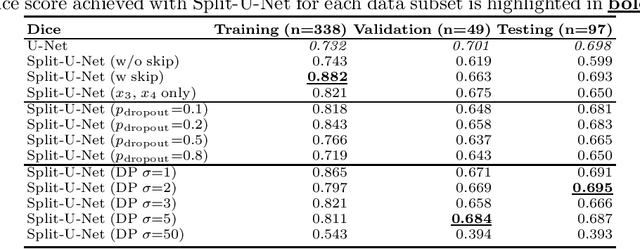
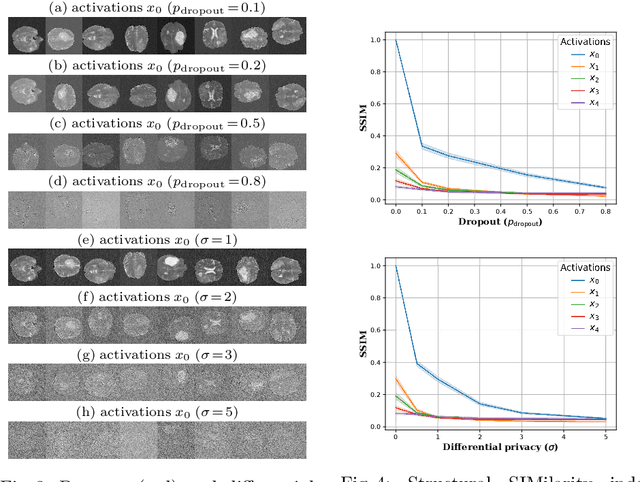
Split learning (SL) has been proposed to train deep learning models in a decentralized manner. For decentralized healthcare applications with vertical data partitioning, SL can be beneficial as it allows institutes with complementary features or images for a shared set of patients to jointly develop more robust and generalizable models. In this work, we propose "Split-U-Net" and successfully apply SL for collaborative biomedical image segmentation. Nonetheless, SL requires the exchanging of intermediate activation maps and gradients to allow training models across different feature spaces, which might leak data and raise privacy concerns. Therefore, we also quantify the amount of data leakage in common SL scenarios for biomedical image segmentation and provide ways to counteract such leakage by applying appropriate defense strategies.
UNetFormer: A Unified Vision Transformer Model and Pre-Training Framework for 3D Medical Image Segmentation
Apr 05, 2022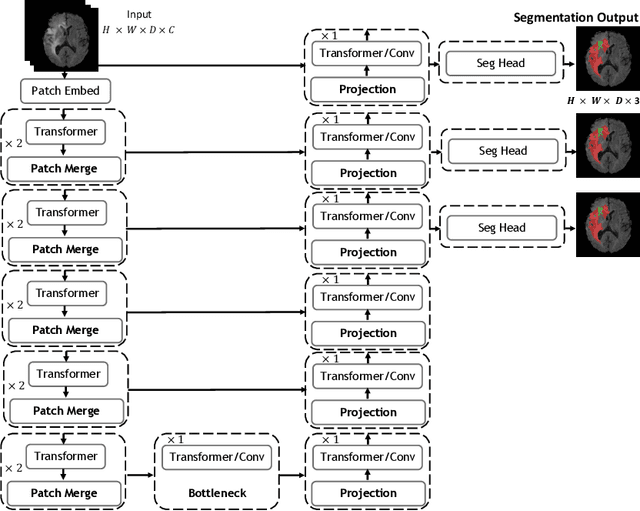
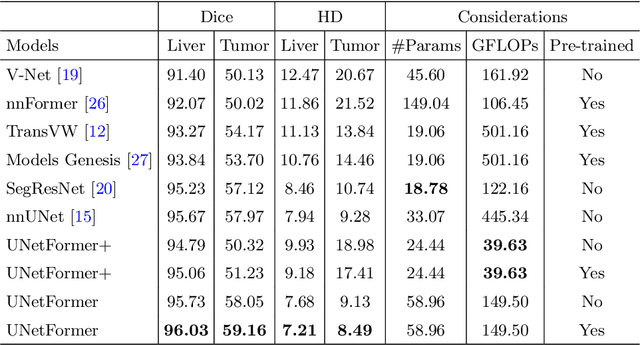
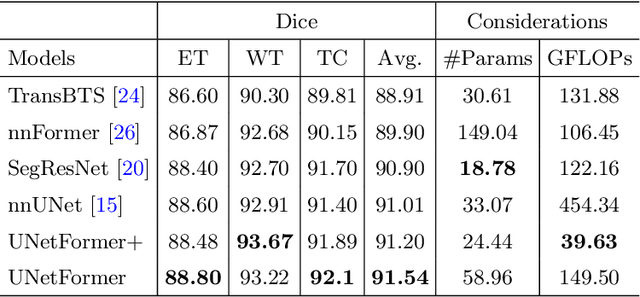
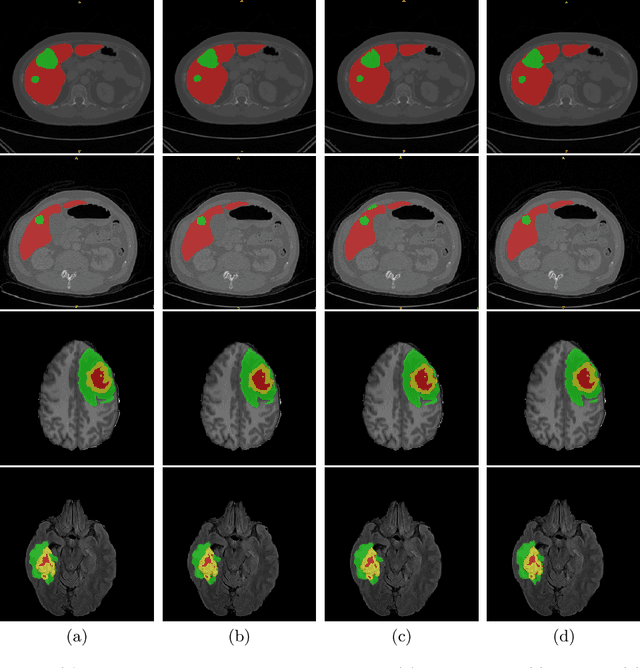
Vision Transformers (ViT)s have recently become popular due to their outstanding modeling capabilities, in particular for capturing long-range information, and scalability to dataset and model sizes which has led to state-of-the-art performance in various computer vision and medical image analysis tasks. In this work, we introduce a unified framework consisting of two architectures, dubbed UNetFormer, with a 3D Swin Transformer-based encoder and Convolutional Neural Network (CNN) and transformer-based decoders. In the proposed model, the encoder is linked to the decoder via skip connections at five different resolutions with deep supervision. The design of proposed architecture allows for meeting a wide range of trade-off requirements between accuracy and computational cost. In addition, we present a methodology for self-supervised pre-training of the encoder backbone via learning to predict randomly masked volumetric tokens using contextual information of visible tokens. We pre-train our framework on a cohort of $5050$ CT images, gathered from publicly available CT datasets, and present a systematic investigation of various components such as masking ratio and patch size that affect the representation learning capability and performance of downstream tasks. We validate the effectiveness of our pre-training approach by fine-tuning and testing our model on liver and liver tumor segmentation task using the Medical Segmentation Decathlon (MSD) dataset and achieve state-of-the-art performance in terms of various segmentation metrics. To demonstrate its generalizability, we train and test the model on BraTS 21 dataset for brain tumor segmentation using MRI images and outperform other methods in terms of Dice score. Code: https://github.com/Project-MONAI/research-contributions
Closing the Generalization Gap of Cross-silo Federated Medical Image Segmentation
Mar 18, 2022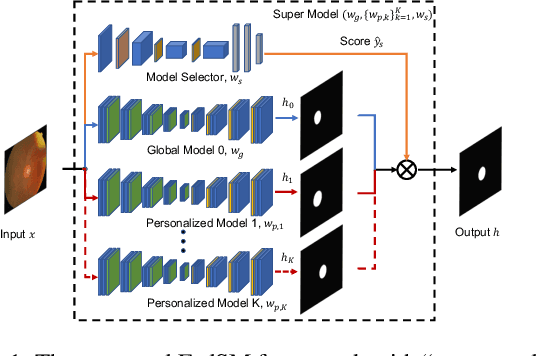
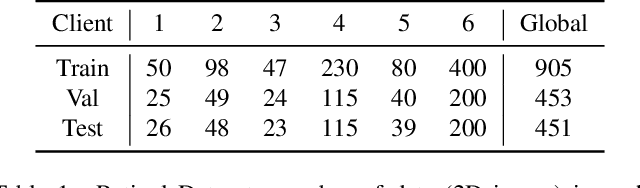
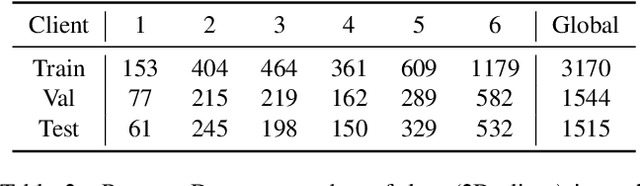
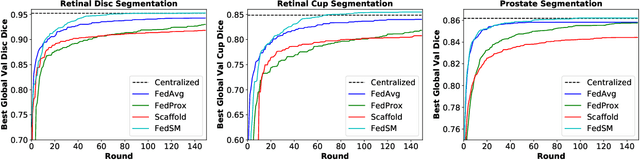
Cross-silo federated learning (FL) has attracted much attention in medical imaging analysis with deep learning in recent years as it can resolve the critical issues of insufficient data, data privacy, and training efficiency. However, there can be a generalization gap between the model trained from FL and the one from centralized training. This important issue comes from the non-iid data distribution of the local data in the participating clients and is well-known as client drift. In this work, we propose a novel training framework FedSM to avoid the client drift issue and successfully close the generalization gap compared with the centralized training for medical image segmentation tasks for the first time. We also propose a novel personalized FL objective formulation and a new method SoftPull to solve it in our proposed framework FedSM. We conduct rigorous theoretical analysis to guarantee its convergence for optimizing the non-convex smooth objective function. Real-world medical image segmentation experiments using deep FL validate the motivations and effectiveness of our proposed method.
Auto-FedRL: Federated Hyperparameter Optimization for Multi-institutional Medical Image Segmentation
Mar 12, 2022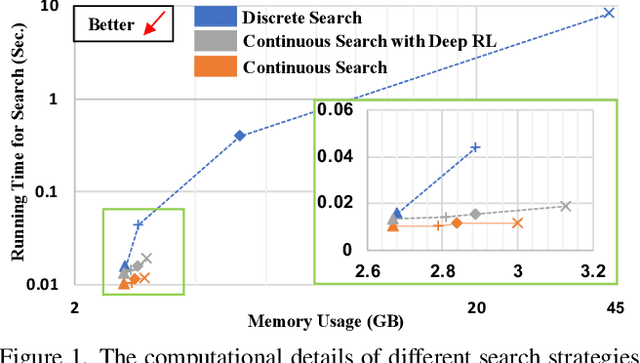

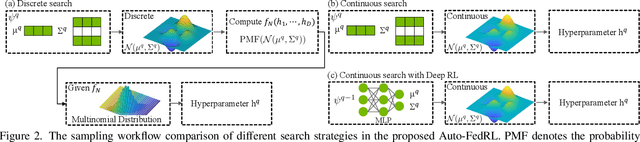

Federated learning (FL) is a distributed machine learning technique that enables collaborative model training while avoiding explicit data sharing. The inherent privacy-preserving property of FL algorithms makes them especially attractive to the medical field. However, in case of heterogeneous client data distributions, standard FL methods are unstable and require intensive hyperparameter tuning to achieve optimal performance. Conventional hyperparameter optimization algorithms are impractical in real-world FL applications as they involve numerous training trials, which are often not affordable with limited compute budgets. In this work, we propose an efficient reinforcement learning~(RL)-based federated hyperparameter optimization algorithm, termed Auto-FedRL, in which an online RL agent can dynamically adjust hyperparameters of each client based on the current training progress. Extensive experiments are conducted to investigate different search strategies and RL agents. The effectiveness of the proposed method is validated on a heterogeneous data split of the CIFAR-10 dataset as well as two real-world medical image segmentation datasets for COVID-19 lesion segmentation in chest CT and pancreas segmentation in abdominal CT.
T-AutoML: Automated Machine Learning for Lesion Segmentation using Transformers in 3D Medical Imaging
Nov 15, 2021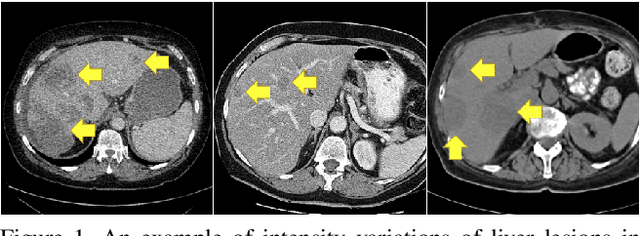
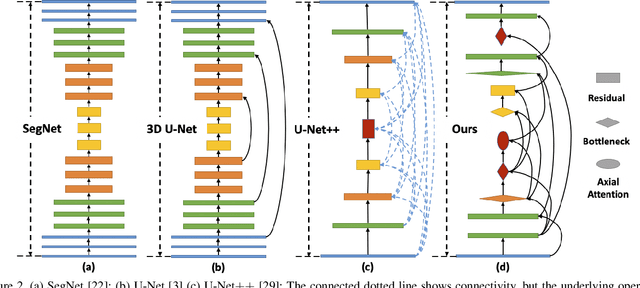
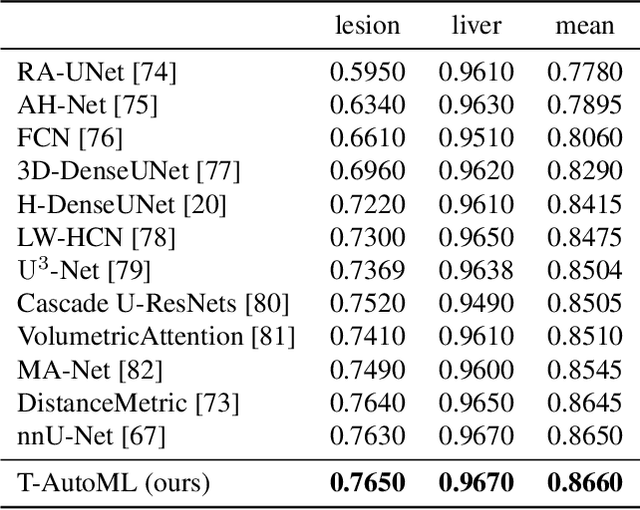
Lesion segmentation in medical imaging has been an important topic in clinical research. Researchers have proposed various detection and segmentation algorithms to address this task. Recently, deep learning-based approaches have significantly improved the performance over conventional methods. However, most state-of-the-art deep learning methods require the manual design of multiple network components and training strategies. In this paper, we propose a new automated machine learning algorithm, T-AutoML, which not only searches for the best neural architecture, but also finds the best combination of hyper-parameters and data augmentation strategies simultaneously. The proposed method utilizes the modern transformer model, which is introduced to adapt to the dynamic length of the search space embedding and can significantly improve the ability of the search. We validate T-AutoML on several large-scale public lesion segmentation data-sets and achieve state-of-the-art performance.