 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen does word order matter and when doesn't it?
Mar 01, 2024Language models (LMs) may appear insensitive to word order changes in natural language understanding (NLU) tasks. In this paper, we propose that linguistic redundancy can explain this phenomenon, whereby word order and other linguistic cues such as case markers provide overlapping and thus redundant information. Our hypothesis is that models exhibit insensitivity to word order when the order provides redundant information, and the degree of insensitivity varies across tasks. We quantify how informative word order is using mutual information (MI) between unscrambled and scrambled sentences. Our results show the effect that the less informative word order is, the more consistent the model's predictions are between unscrambled and scrambled sentences. We also find that the effect varies across tasks: for some tasks, like SST-2, LMs' prediction is almost always consistent with the original one even if the Pointwise-MI (PMI) changes, while for others, like RTE, the consistency is near random when the PMI gets lower, i.e., word order is really important.
The Trajectory of Voice Onset Time with Vocal Aging
Oct 15, 2018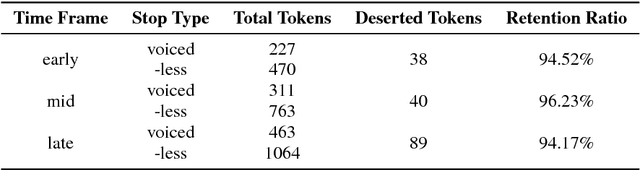
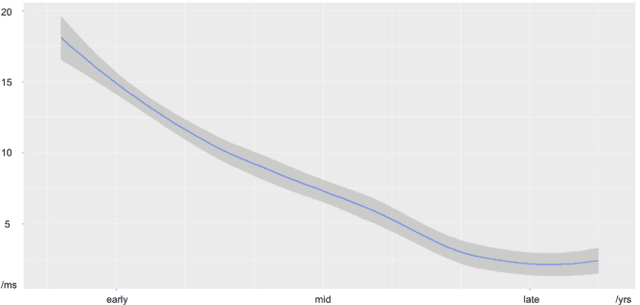
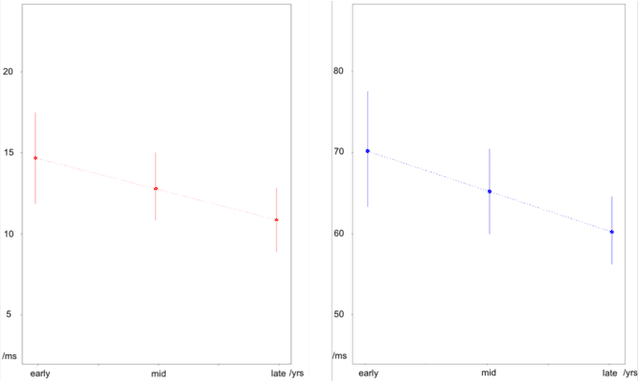
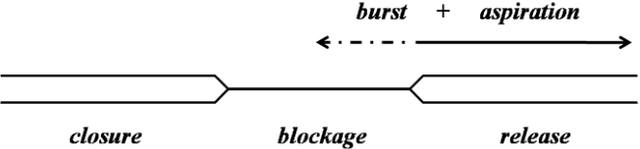
Vocal aging, a universal process of human aging, can largely affect one's language use, possibly including some subtle acoustic features of one's utterances like Voice Onset Time. To figure out the time effects, Queen Elizabeth's Christmas speeches are documented and analyzed in the long-term trend. We build statistical models of time dependence in Voice Onset Time, controlling a wide range of other fixed factors, to present annual variations and the simulated trajectory. It is revealed that the variation range of Voice Onset Time has been narrowing over fifty years with a slight reduction in the mean value, which, possibly, is an effect of diminishing exertion, resulting from subdued muscle contraction, transcending other non-linguistic factors in forming Voice Onset Time patterns over a long time.
* conference