 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLibra-VLA: Achieving Learning Equilibrium via Asynchronous Coarse-to-Fine Dual-System
Apr 27, 2026Vision-Language-Action (VLA) models are a promising paradigm for generalist robotic manipulation by grounding high-level semantic instructions into executable physical actions. However, prevailing approaches typically adopt a monolithic generation paradigm, directly mapping visual-linguistic features to high-frequency motor commands in a flat, non-hierarchical fashion. This strategy overlooks the inherent hierarchy of robotic manipulation, where complex actions can be naturally modeled in a Hybrid Action Space, decomposing into discrete macro-directional reaching and continuous micro-pose alignment, severely widening the semantic-actuation gap and imposing a heavy representational burden on grounding high-level semantics to continuous actions. To address this, we introduce Libra-VLA, a novel Coarse-to-Fine Dual-System VLA architecture. We explicitly decouple the learning complexity into a coarse-to-fine hierarchy to strike a training equilibrium, while simultaneously leveraging this structural modularity to implement an asynchronous execution strategy. The Semantic Planner predicts discrete action tokens capturing macro-directional intent, while the Action Refiner conditions on coarse intent to generate high-frequency continuous actions for precise alignment. Crucially, our empirical analysis reveals that performance follows an inverted-U curve relative to action decomposition granularity, peaking exactly when the learning difficulty is balanced between the two sub-systems. With the asynchronous design, our approach offers a scalable, robust, and responsive solution for open-world manipulation.
ACoT-VLA: Action Chain-of-Thought for Vision-Language-Action Models
Jan 16, 2026Vision-Language-Action (VLA) models have emerged as essential generalist robot policies for diverse manipulation tasks, conventionally relying on directly translating multimodal inputs into actions via Vision-Language Model (VLM) embeddings. Recent advancements have introduced explicit intermediary reasoning, such as sub-task prediction (language) or goal image synthesis (vision), to guide action generation. However, these intermediate reasoning are often indirect and inherently limited in their capacity to convey the full, granular information required for precise action execution. Instead, we posit that the most effective form of reasoning is one that deliberates directly in the action space. We introduce Action Chain-of-Thought (ACoT), a paradigm where the reasoning process itself is formulated as a structured sequence of coarse action intents that guide the final policy. In this paper, we propose ACoT-VLA, a novel architecture that materializes the ACoT paradigm. Specifically, we introduce two complementary components: an Explicit Action Reasoner (EAR) and Implicit Action Reasoner (IAR). The former proposes coarse reference trajectories as explicit action-level reasoning steps, while the latter extracts latent action priors from internal representations of multimodal input, co-forming an ACoT that conditions the downstream action head to enable grounded policy learning. Extensive experiments in real-world and simulation environments demonstrate the superiority of our proposed method, which achieves 98.5%, 84.1%, and 47.4% on LIBERO, LIBERO-Plus and VLABench, respectively.
DeCOM: Decomposed Policy for Constrained Cooperative Multi-Agent Reinforcement Learning
Nov 10, 2021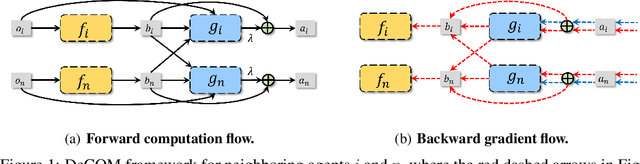

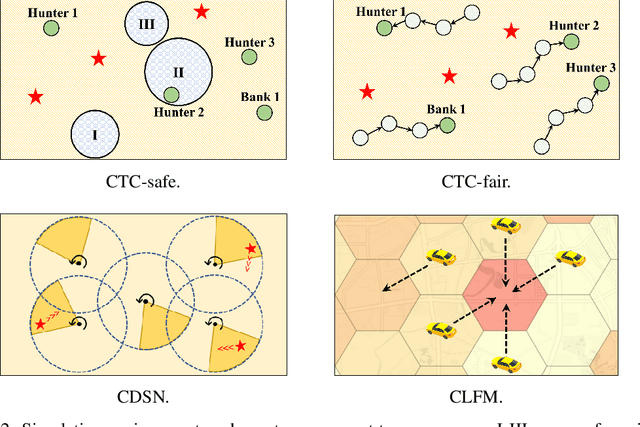
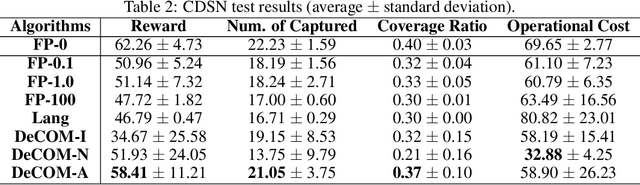
In recent years, multi-agent reinforcement learning (MARL) has presented impressive performance in various applications. However, physical limitations, budget restrictions, and many other factors usually impose \textit{constraints} on a multi-agent system (MAS), which cannot be handled by traditional MARL frameworks. Specifically, this paper focuses on constrained MASes where agents work \textit{cooperatively} to maximize the expected team-average return under various constraints on expected team-average costs, and develops a \textit{constrained cooperative MARL} framework, named DeCOM, for such MASes. In particular, DeCOM decomposes the policy of each agent into two modules, which empowers information sharing among agents to achieve better cooperation. In addition, with such modularization, the training algorithm of DeCOM separates the original constrained optimization into an unconstrained optimization on reward and a constraints satisfaction problem on costs. DeCOM then iteratively solves these problems in a computationally efficient manner, which makes DeCOM highly scalable. We also provide theoretical guarantees on the convergence of DeCOM's policy update algorithm. Finally, we validate the effectiveness of DeCOM with various types of costs in both toy and large-scale (with 500 agents) environments.