 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePHAT: Modeling Period Heterogeneity for Multivariate Time Series Forecasting
Jan 31, 2026While existing multivariate time series forecasting models have advanced significantly in modeling periodicity, they largely neglect the periodic heterogeneity common in real-world data, where variates exhibit distinct and dynamically changing periods. To effectively capture this periodic heterogeneity, we propose PHAT (Period Heterogeneity-Aware Transformer). Specifically, PHAT arranges multivariate inputs into a three-dimensional "periodic bucket" tensor, where the dimensions correspond to variate group characteristics with similar periodicity, time steps aligned by phase, and offsets within the period. By restricting interactions within buckets and masking cross-bucket connections, PHAT effectively avoids interference from inconsistent periods. We also propose a positive-negative attention mechanism, which captures periodic dependencies from two perspectives: periodic alignment and periodic deviation. Additionally, the periodic alignment attention scores are decomposed into positive and negative components, with a modulation term encoding periodic priors. This modulation constrains the attention mechanism to more faithfully reflect the underlying periodic trends. A mathematical explanation is provided to support this property. We evaluate PHAT comprehensively on 14 real-world datasets against 18 baselines, and the results show that it significantly outperforms existing methods, achieving highly competitive forecasting performance. Our sources is available at GitHub.
To See Far, Look Close: Evolutionary Forecasting for Long-term Time Series
Jan 30, 2026The prevailing Direct Forecasting (DF) paradigm dominates Long-term Time Series Forecasting (LTSF) by forcing models to predict the entire future horizon in a single forward pass. While efficient, this rigid coupling of output and evaluation horizons necessitates computationally prohibitive re-training for every target horizon. In this work, we uncover a counter-intuitive optimization anomaly: models trained on short horizons-when coupled with our proposed Evolutionary Forecasting (EF) paradigm-significantly outperform those trained directly on long horizons. We attribute this success to the mitigation of a fundamental optimization pathology inherent in DF, where conflicting gradients from distant futures cripple the learning of local dynamics. We establish EF as a unified generative framework, proving that DF is merely a degenerate special case of EF. Extensive experiments demonstrate that a singular EF model surpasses task-specific DF ensembles across standard benchmarks and exhibits robust asymptotic stability in extreme extrapolation. This work propels a paradigm shift in LTSF: moving from passive Static Mapping to autonomous Evolutionary Reasoning.
A General ReLearner: Empowering Spatiotemporal Prediction by Re-learning Input-label Residual
Jan 30, 2026Prevailing spatiotemporal prediction models typically operate under a forward (unidirectional) learning paradigm, in which models extract spatiotemporal features from historical observation input and map them to target spatiotemporal space for future forecasting (label). However, these models frequently exhibit suboptimal performance when spatiotemporal discrepancies exist between inputs and labels, for instance, when nodes with similar time-series inputs manifest distinct future labels, or vice versa. To address this limitation, we propose explicitly incorporating label features during the training phase. Specifically, we introduce the Spatiotemporal Residual Theorem, which generalizes the conventional unidirectional spatiotemporal prediction paradigm into a bidirectional learning framework. Building upon this theoretical foundation, we design an universal module, termed ReLearner, which seamlessly augments Spatiotemporal Neural Networks (STNNs) with a bidirectional learning capability via an auxiliary inverse learning process. In this process, the model relearns the spatiotemporal feature residuals between input data and future data. The proposed ReLearner comprises two critical components: (1) a Residual Learning Module, designed to effectively disentangle spatiotemporal feature discrepancies between input and label representations; and (2) a Residual Smoothing Module, employed to smooth residual terms and facilitate stable convergence. Extensive experiments conducted on 11 real-world datasets across 14 backbone models demonstrate that ReLearner significantly enhances the predictive performance of existing STNNs.Our code is available on GitHub.
FaLW: A Forgetting-aware Loss Reweighting for Long-tailed Unlearning
Jan 26, 2026Machine unlearning, which aims to efficiently remove the influence of specific data from trained models, is crucial for upholding data privacy regulations like the ``right to be forgotten". However, existing research predominantly evaluates unlearning methods on relatively balanced forget sets. This overlooks a common real-world scenario where data to be forgotten, such as a user's activity records, follows a long-tailed distribution. Our work is the first to investigate this critical research gap. We find that in such long-tailed settings, existing methods suffer from two key issues: \textit{Heterogeneous Unlearning Deviation} and \textit{Skewed Unlearning Deviation}. To address these challenges, we propose FaLW, a plug-and-play, instance-wise dynamic loss reweighting method. FaLW innovatively assesses the unlearning state of each sample by comparing its predictive probability to the distribution of unseen data from the same class. Based on this, it uses a forgetting-aware reweighting scheme, modulated by a balancing factor, to adaptively adjust the unlearning intensity for each sample. Extensive experiments demonstrate that FaLW achieves superior performance. Code is available at \textbf{Supplementary Material}.
Rethinking Crystal Symmetry Prediction: A Decoupled Perspective
Nov 10, 2025Efficiently and accurately determining the symmetry is a crucial step in the structural analysis of crystalline materials. Existing methods usually mindlessly apply deep learning models while ignoring the underlying chemical rules. More importantly, experiments show that they face a serious sub-property confusion SPC problem. To address the above challenges, from a decoupled perspective, we introduce the XRDecoupler framework, a problem-solving arsenal specifically designed to tackle the SPC problem. Imitating the thinking process of chemists, we innovatively incorporate multidimensional crystal symmetry information as superclass guidance to ensure that the model's prediction process aligns with chemical intuition. We further design a hierarchical PXRD pattern learning model and a multi-objective optimization approach to achieve high-quality representation and balanced optimization. Comprehensive evaluations on three mainstream databases (e.g., CCDC, CoREMOF, and InorganicData) demonstrate that XRDecoupler excels in performance, interpretability, and generalization.
Spatiotemporal Causal Decoupling Model for Air Quality Forecasting
May 26, 2025Due to the profound impact of air pollution on human health, livelihoods, and economic development, air quality forecasting is of paramount significance. Initially, we employ the causal graph method to scrutinize the constraints of existing research in comprehensively modeling the causal relationships between the air quality index (AQI) and meteorological features. In order to enhance prediction accuracy, we introduce a novel air quality forecasting model, AirCade, which incorporates a causal decoupling approach. AirCade leverages a spatiotemporal module in conjunction with knowledge embedding techniques to capture the internal dynamics of AQI. Subsequently, a causal decoupling module is proposed to disentangle synchronous causality from past AQI and meteorological features, followed by the dissemination of acquired knowledge to future time steps to enhance performance. Additionally, we introduce a causal intervention mechanism to explicitly represent the uncertainty of future meteorological features, thereby bolstering the model's robustness. Our evaluation of AirCade on an open-source air quality dataset demonstrates over 20\% relative improvement over state-of-the-art models.
Soft causal learning for generalized molecule property prediction: An environment perspective
May 07, 2025Learning on molecule graphs has become an increasingly important topic in AI for science, which takes full advantage of AI to facilitate scientific discovery. Existing solutions on modeling molecules utilize Graph Neural Networks (GNNs) to achieve representations but they mostly fail to adapt models to out-of-distribution (OOD) samples. Although recent advances on OOD-oriented graph learning have discovered the invariant rationale on graphs, they still ignore three important issues, i.e., 1) the expanding atom patterns regarding environments on graphs lead to failures of invariant rationale based models, 2) the associations between discovered molecular subgraphs and corresponding properties are complex where causal substructures cannot fully interpret the labels. 3) the interactions between environments and invariances can influence with each other thus are challenging to be modeled. To this end, we propose a soft causal learning framework, to tackle the unresolved OOD challenge in molecular science, from the perspective of fully modeling the molecule environments and bypassing the invariant subgraphs. Specifically, we first incorporate chemistry theories into our graph growth generator to imitate expaned environments, and then devise an GIB-based objective to disentangle environment from whole graphs and finally introduce a cross-attention based soft causal interaction, which allows dynamic interactions between environments and invariances. We perform experiments on seven datasets by imitating different kinds of OOD generalization scenarios. Extensive comparison, ablation experiments as well as visualized case studies demonstrate well generalization ability of our proposal.
From Understanding to Excelling: Template-Free Algorithm Design through Structural-Functional Co-Evolution
Mar 13, 2025Large language models (LLMs) have greatly accelerated the automation of algorithm generation and optimization. However, current methods such as EoH and FunSearch mainly rely on predefined templates and expert-specified functions that focus solely on the local evolution of key functionalities. Consequently, they fail to fully leverage the synergistic benefits of the overall architecture and the potential of global optimization. In this paper, we introduce an end-to-end algorithm generation and optimization framework based on LLMs. Our approach utilizes the deep semantic understanding of LLMs to convert natural language requirements or human-authored papers into code solutions, and employs a two-dimensional co-evolution strategy to optimize both functional and structural aspects. This closed-loop process spans problem analysis, code generation, and global optimization, automatically identifying key algorithm modules for multi-level joint optimization and continually enhancing performance and design innovation. Extensive experiments demonstrate that our method outperforms traditional local optimization approaches in both performance and innovation, while also exhibiting strong adaptability to unknown environments and breakthrough potential in structural design. By building on human research, our framework generates and optimizes novel algorithms that surpass those designed by human experts, broadening the applicability of LLMs for algorithm design and providing a novel solution pathway for automated algorithm development.
Delayed Bottlenecking: Alleviating Forgetting in Pre-trained Graph Neural Networks
Apr 23, 2024Pre-training GNNs to extract transferable knowledge and apply it to downstream tasks has become the de facto standard of graph representation learning. Recent works focused on designing self-supervised pre-training tasks to extract useful and universal transferable knowledge from large-scale unlabeled data. However, they have to face an inevitable question: traditional pre-training strategies that aim at extracting useful information about pre-training tasks, may not extract all useful information about the downstream task. In this paper, we reexamine the pre-training process within traditional pre-training and fine-tuning frameworks from the perspective of Information Bottleneck (IB) and confirm that the forgetting phenomenon in pre-training phase may cause detrimental effects on downstream tasks. Therefore, we propose a novel \underline{D}elayed \underline{B}ottlenecking \underline{P}re-training (DBP) framework which maintains as much as possible mutual information between latent representations and training data during pre-training phase by suppressing the compression operation and delays the compression operation to fine-tuning phase to make sure the compression can be guided with labeled fine-tuning data and downstream tasks. To achieve this, we design two information control objectives that can be directly optimized and further integrate them into the actual model design. Extensive experiments on both chemistry and biology domains demonstrate the effectiveness of DBP.
Graph-Free Learning in Graph-Structured Data: A More Efficient and Accurate Spatiotemporal Learning Perspective
Jan 30, 2023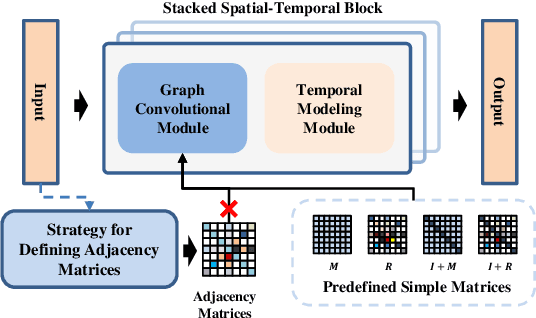
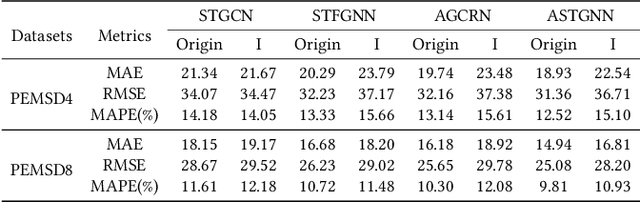
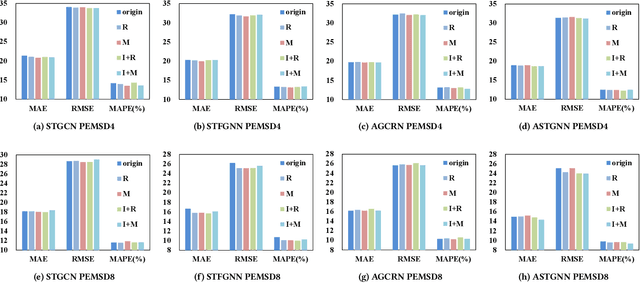
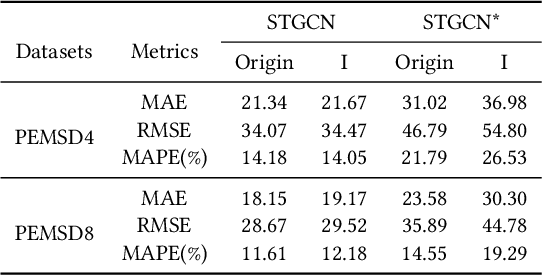
Spatiotemporal learning, which aims at extracting spatiotemporal correlations from the collected spatiotemporal data, is a research hotspot in recent years. And considering the inherent graph structure of spatiotemporal data, recent works focus on capturing spatial dependencies by utilizing Graph Convolutional Networks (GCNs) to aggregate vertex features with the guidance of adjacency matrices. In this paper, with extensive and deep-going experiments, we comprehensively analyze existing spatiotemporal graph learning models and reveal that extracting adjacency matrices with carefully design strategies, which are viewed as the key of enhancing performance on graph learning, are largely ineffective. Meanwhile, based on these experiments, we also discover that the aggregation itself is more important than the way that how vertices are aggregated. With these preliminary, a novel efficient Graph-Free Spatial (GFS) learning module based on layer normalization for capturing spatial correlations in spatiotemporal graph learning. The proposed GFS module can be easily plugged into existing models for replacing all graph convolution components. Rigorous theoretical proof demonstrates that the time complexity of GFS is significantly better than that of graph convolution operation. Extensive experiments verify the superiority of GFS in both the perspectives of efficiency and learning effect in processing graph-structured data especially extreme large scale graph data.