 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Acoustic Echo Cancellation for Full-duplex Communications
May 30, 2022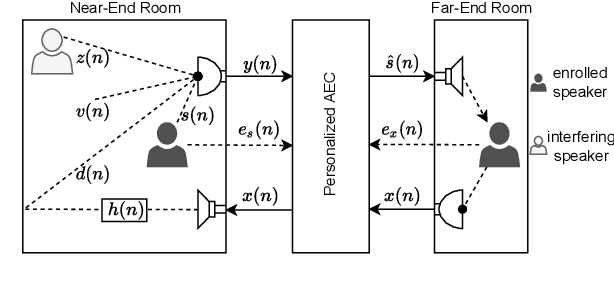

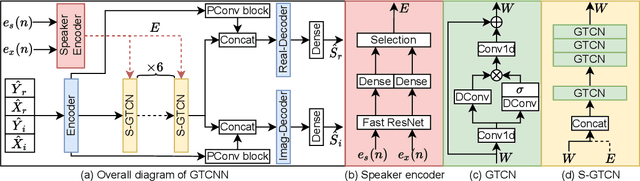
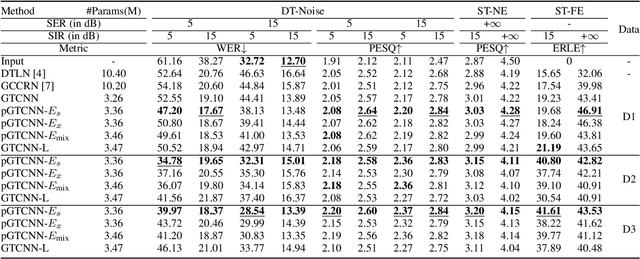
Deep neural networks (DNNs) have shown promising results for acoustic echo cancellation (AEC). But the DNN-based AEC models let through all near-end speakers including the interfering speech. In light of recent studies on personalized speech enhancement, we investigate the feasibility of personalized acoustic echo cancellation (PAEC) in this paper for full-duplex communications, where background noise and interfering speakers may coexist with acoustic echoes. Specifically, we first propose a novel backbone neural network termed as gated temporal convolutional neural network (GTCNN) that outperforms state-of-the-art AEC models in performance. Speaker embeddings like d-vectors are further adopted as auxiliary information to guide the GTCNN to focus on the target speaker. A special case in PAEC is that speech snippets of both parties on the call are enrolled. Experimental results show that auxiliary information from either the near-end speaker or the far-end speaker can improve the DNN-based AEC performance. Nevertheless, there is still much room for improvement in the utilization of the finite-dimensional speaker embeddings.
Causality Inspired Representation Learning for Domain Generalization
Mar 27, 2022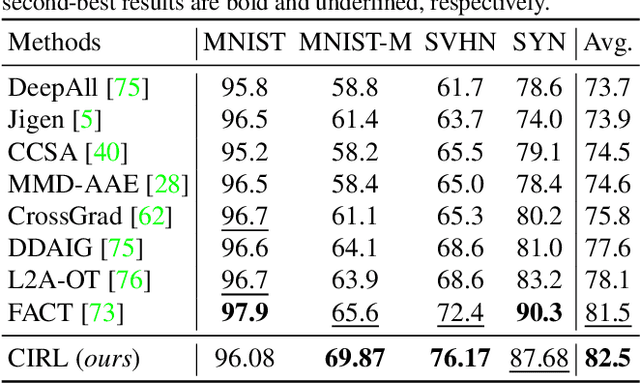

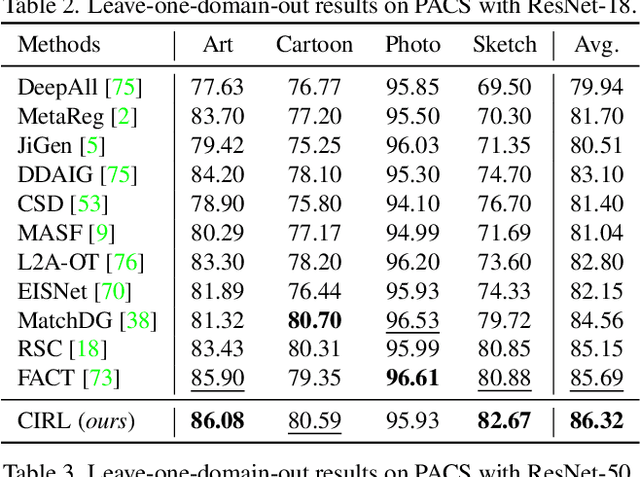
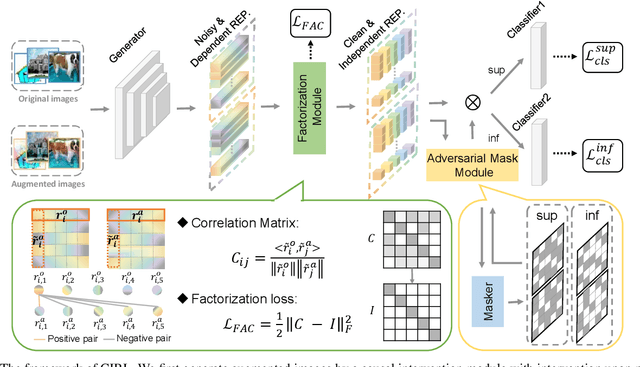
Domain generalization (DG) is essentially an out-of-distribution problem, aiming to generalize the knowledge learned from multiple source domains to an unseen target domain. The mainstream is to leverage statistical models to model the dependence between data and labels, intending to learn representations independent of domain. Nevertheless, the statistical models are superficial descriptions of reality since they are only required to model dependence instead of the intrinsic causal mechanism. When the dependence changes with the target distribution, the statistic models may fail to generalize. In this regard, we introduce a general structural causal model to formalize the DG problem. Specifically, we assume that each input is constructed from a mix of causal factors (whose relationship with the label is invariant across domains) and non-causal factors (category-independent), and only the former cause the classification judgments. Our goal is to extract the causal factors from inputs and then reconstruct the invariant causal mechanisms. However, the theoretical idea is far from practical of DG since the required causal/non-causal factors are unobserved. We highlight that ideal causal factors should meet three basic properties: separated from the non-causal ones, jointly independent, and causally sufficient for the classification. Based on that, we propose a Causality Inspired Representation Learning (CIRL) algorithm that enforces the representations to satisfy the above properties and then uses them to simulate the causal factors, which yields improved generalization ability. Extensive experimental results on several widely used datasets verify the effectiveness of our approach.
Multi-Task Deep Residual Echo Suppression with Echo-aware Loss
Feb 21, 2022

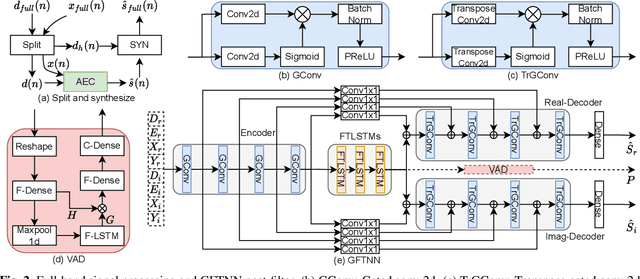
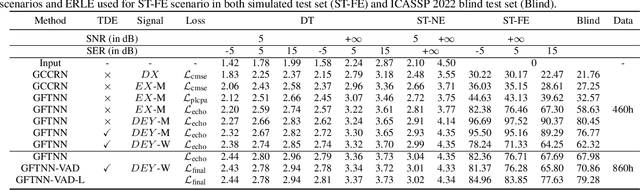
This paper introduces the NWPU Team's entry to the ICASSP 2022 AEC Challenge. We take a hybrid approach that cascades a linear AEC with a neural post-filter. The former is used to deal with the linear echo components while the latter suppresses the residual non-linear echo components. We use gated convolutional F-T-LSTM neural network (GFTNN) as the backbone and shape the post-filter by a multi-task learning (MTL) framework, where a voice activity detection (VAD) module is adopted as an auxiliary task along with echo suppression, with the aim to avoid over suppression that may cause speech distortion. Moreover, we adopt an echo-aware loss function, where the mean square error (MSE) loss can be optimized particularly for every time-frequency bin (TF-bin) according to the signal-to-echo ratio (SER), leading to further suppression on the echo. Extensive ablation study shows that the time delay estimation (TDE) module in neural post-filter leads to better perceptual quality, and an adaptive filter with better convergence will bring consistent performance gain for the post-filter. Besides, we find that using the linear echo as the input of our neural post-filter is a better choice than using the reference signal directly. In the ICASSP 2022 AEC-Challenge, our approach has ranked the 1st place on word accuracy (WAcc) (0.817) and the 3rd place on both mean opinion score (MOS) (4.502) and the final score (0.864).
Controllable Multichannel Speech Dereverberation based on Deep Neural Networks
Oct 16, 2021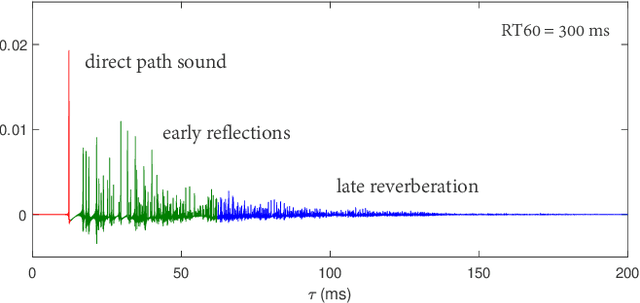
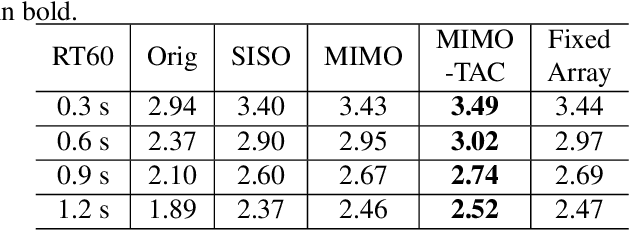
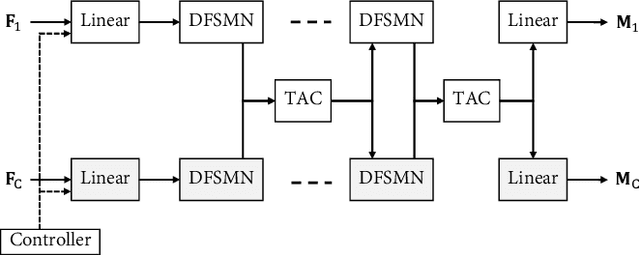
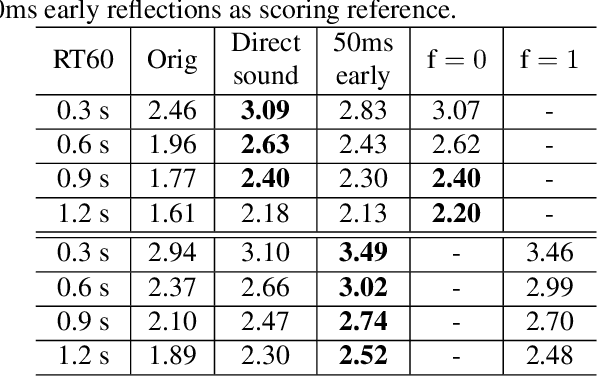
Neural network based speech dereverberation has achieved promising results in recent studies. Nevertheless, many are focused on recovery of only the direct path sound and early reflections, which could be beneficial to speech perception, are discarded. The performance of a model trained to recover clean speech degrades when evaluated on early reverberation targets, and vice versa. This paper proposes a novel deep neural network based multichannel speech dereverberation algorithm, in which the dereverberation level is controllable. This is realized by adding a simple floating-point number as target controller of the model. Experiments are conducted using spatially distributed microphones, and the efficacy of the proposed algorithm is confirmed in various simulated conditions.
NN3A: Neural Network supported Acoustic Echo Cancellation, Noise Suppression and Automatic Gain Control for Real-Time Communications
Oct 16, 2021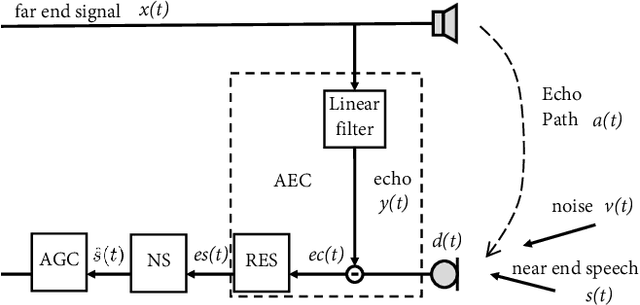
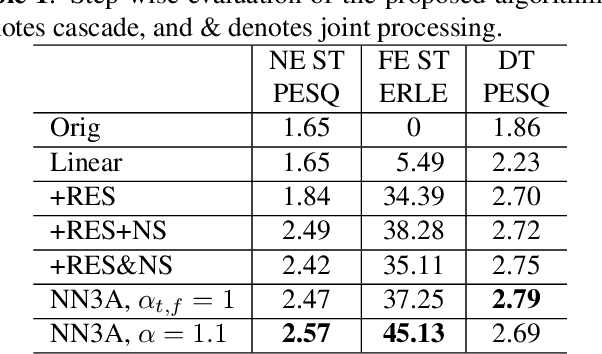
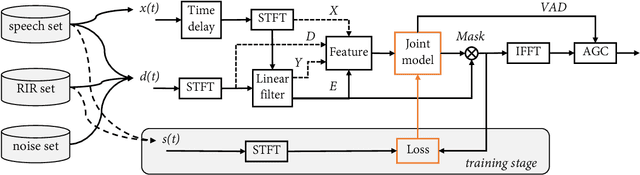
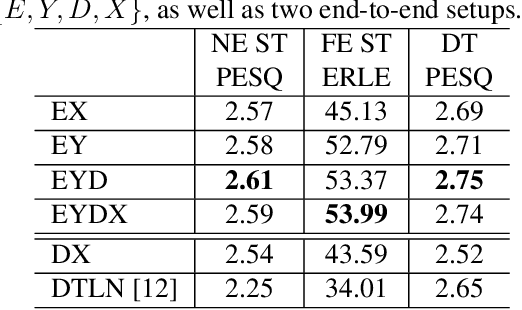
Acoustic echo cancellation (AEC), noise suppression (NS) and automatic gain control (AGC) are three often required modules for real-time communications (RTC). This paper proposes a neural network supported algorithm for RTC, namely NN3A, which incorporates an adaptive filter and a multi-task model for residual echo suppression, noise reduction and near-end speech activity detection. The proposed algorithm is shown to outperform both a method using separate models and an end-to-end alternative. It is further shown that there exists a trade-off in the model between residual suppression and near-end speech distortion, which could be balanced by a novel loss weighting function. Several practical aspects of training the joint model are also investigated to push its performance to limit.
Projector-Guided Non-Holonomic Mobile 3D Printing
May 19, 2021
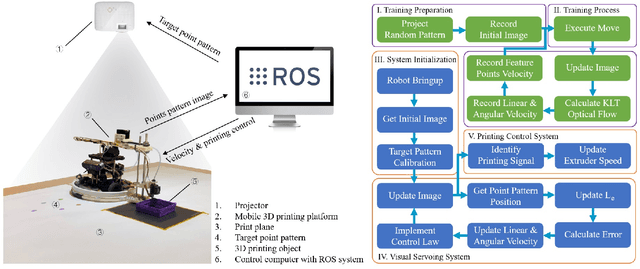

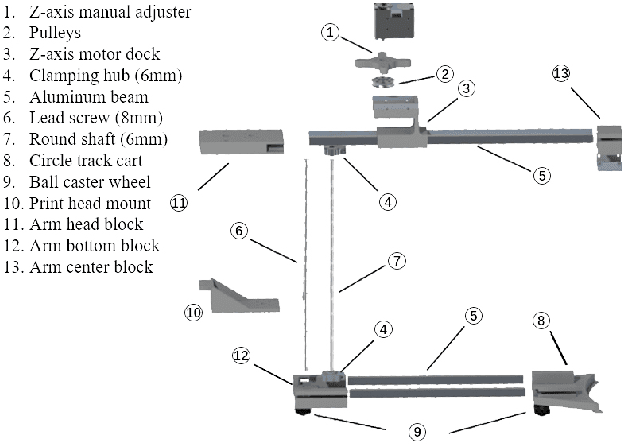
Fused deposition modeling (FDM) using mobile robots instead of the gantry-based 3D printer enables additive manufacturing at a larger scale with higher speed. This introduces challenges including accurate localization, control of the printhead, and design of a stable mobile manipulator with low vibrations and proper degrees of freedom. We proposed and developed a low-cost non-holonomic mobile 3D printing system guided by a projector via learning-based visual servo-ing. It requires almost no manual calibration of the system parameters. Using a regular top-down projector without any expensive external localization device for pose feedback, this system enabled mobile robots to accurately follow pre-designed millimeter-level printing trajectories with speed control. We evaluate the system in terms of its trajectory accuracy and printing quality compared with original 3D designs. We further demonstrated the potential of this system using two such mobile robots to collaboratively print a 3D object with dimensions of 80cm x 30cm size, which exceeds the limitation of common desktop FDM 3D printers.
Joint Online Multichannel Acoustic Echo Cancellation, Speech Dereverberation and Source Separation
Apr 09, 2021
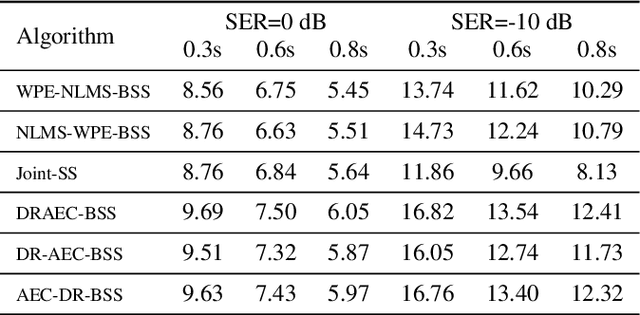
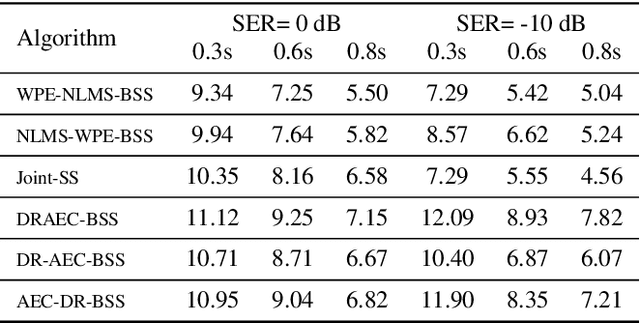
This paper presents a joint source separation algorithm that simultaneously reduces acoustic echo, reverberation and interfering sources. Target speeches are separated from the mixture by maximizing independence with respect to the other sources. It is shown that the separation process can be decomposed into cascading sub-processes that separately relate to acoustic echo cancellation, speech dereverberation and source separation, all of which are solved using the auxiliary function based independent component/vector analysis techniques, and their solving orders are exchangeable. The cascaded solution not only leads to lower computational complexity but also better separation performance than the vanilla joint algorithm.
Weighted Recursive Least Square Filter and Neural Network based Residual Echo Suppression for the AEC-Challenge
Feb 18, 2021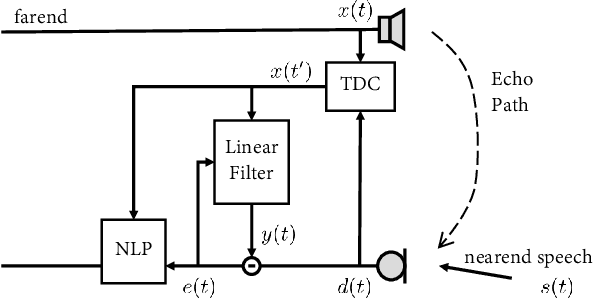
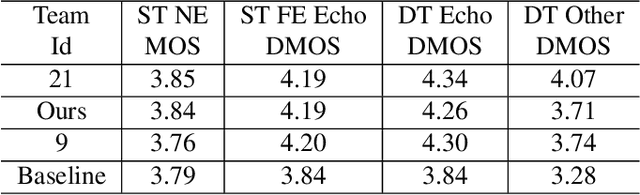
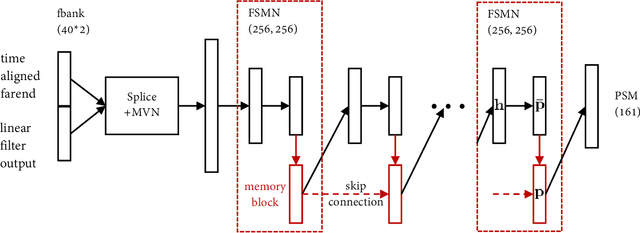
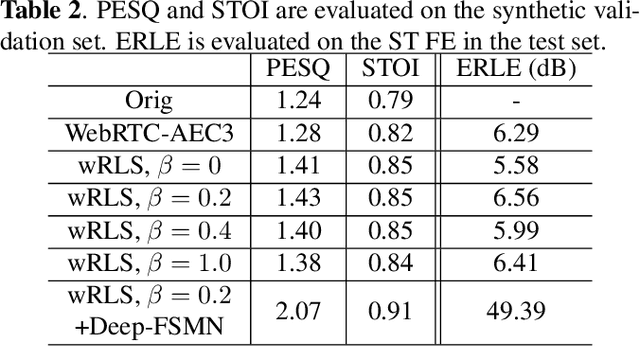
This paper presents a real-time Acoustic Echo Cancellation (AEC) algorithm submitted to the AEC-Challenge. The algorithm consists of three modules: Generalized Cross-Correlation with PHAse Transform (GCC-PHAT) based time delay compensation, weighted Recursive Least Square (wRLS) based linear adaptive filtering and neural network based residual echo suppression. The wRLS filter is derived from a novel semi-blind source separation perspective. The neural network model predicts a Phase-Sensitive Mask (PSM) based on the aligned reference and the linear filter output. The algorithm achieved a mean subjective score of 4.00 and ranked 2nd in the AEC-Challenge.
DARWIN: A Highly Flexible Platform for Imaging Research in Radiology
Sep 02, 2020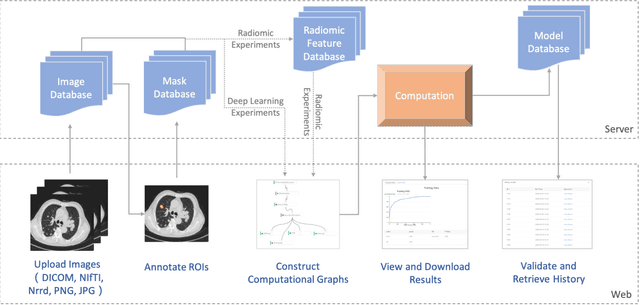
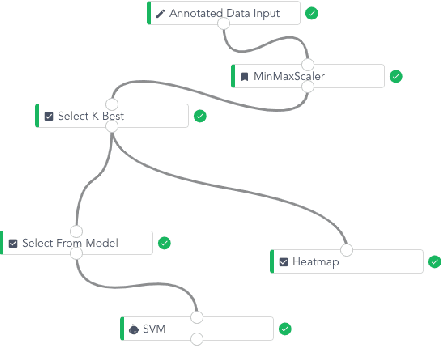
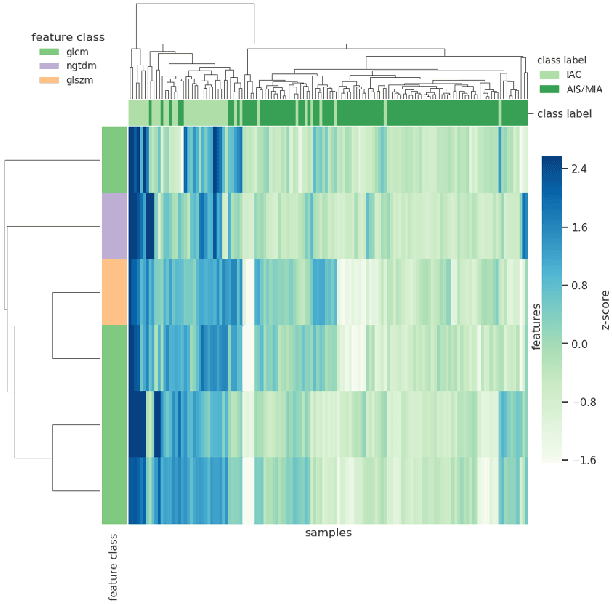
To conduct a radiomics or deep learning research experiment, the radiologists or physicians need to grasp the needed programming skills, which, however, could be frustrating and costly when they have limited coding experience. In this paper, we present DARWIN, a flexible research platform with a graphical user interface for medical imaging research. Our platform is consists of a radiomics module and a deep learning module. The radiomics module can extract more than 1000 dimension features(first-, second-, and higher-order) and provided many draggable supervised and unsupervised machine learning models. Our deep learning module integrates state of the art architectures of classification, detection, and segmentation tasks. It allows users to manually select hyperparameters, or choose an algorithm to automatically search for the best ones. DARWIN also offers the possibility for users to define a custom pipeline for their experiment. These flexibilities enable radiologists to carry out various experiments easily.
Rank-1 Constrained Multichannel Wiener Filter for Speech Recognition in Noisy Environments
Nov 15, 2017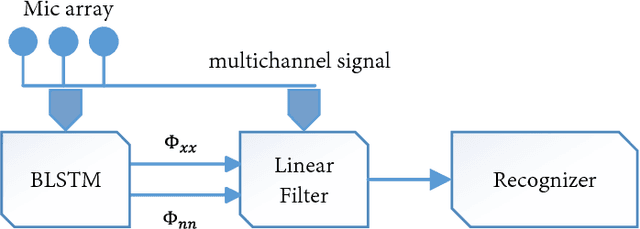

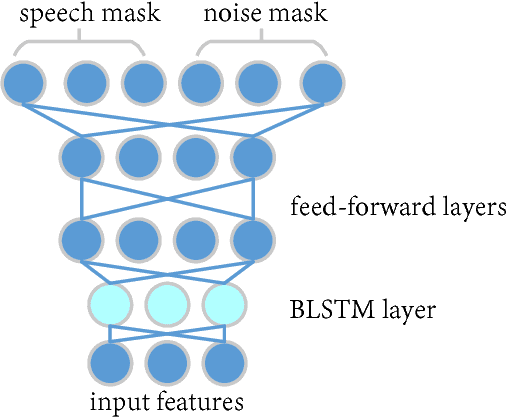
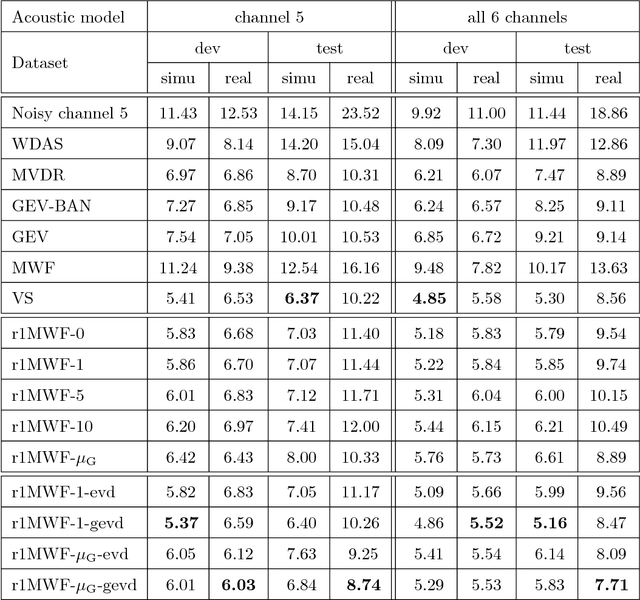
Multichannel linear filters, such as the Multichannel Wiener Filter (MWF) and the Generalized Eigenvalue (GEV) beamformer are popular signal processing techniques which can improve speech recognition performance. In this paper, we present an experimental study on these linear filters in a specific speech recognition task, namely the CHiME-4 challenge, which features real recordings in multiple noisy environments. Specifically, the rank-1 MWF is employed for noise reduction and a new constant residual noise power constraint is derived which enhances the recognition performance. To fulfill the underlying rank-1 assumption, the speech covariance matrix is reconstructed based on eigenvectors or generalized eigenvectors. Then the rank-1 constrained MWF is evaluated with alternative multichannel linear filters under the same framework, which involves a Bidirectional Long Short-Term Memory (BLSTM) network for mask estimation. The proposed filter outperforms alternative ones, leading to a 40% relative Word Error Rate (WER) reduction compared with the baseline Weighted Delay and Sum (WDAS) beamformer on the real test set, and a 15% relative WER reduction compared with the GEV-BAN method. The results also suggest that the speech recognition accuracy correlates more with the Mel-frequency cepstral coefficients (MFCC) feature variance than with the noise reduction or the speech distortion level.