 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniTalking: A Unified Audio-Video Framework for Talking Portrait Generation
Mar 02, 2026While state-of-the-art audio-video generation models like Veo3 and Sora2 demonstrate remarkable capabilities, their closed-source nature makes their architectures and training paradigms inaccessible. To bridge this gap in accessibility and performance, we introduce UniTalking, a unified, end-to-end diffusion framework for generating high-fidelity speech and lip-synchronized video. At its core, our framework employs Multi-Modal Transformer Blocks to explicitly model the fine-grained temporal correspondence between audio and video latent tokens via a shared self-attention mechanism. By leveraging powerful priors from a pre-trained video generation model, our framework ensures state-of-the-art visual fidelity while enabling efficient training. Furthermore, UniTalking incorporates a personalized voice cloning capability, allowing the generation of speech in a target style from a brief audio reference. Qualitative and quantitative results demonstrate that our method produces highly realistic talking portraits, achieving superior performance over existing open-source approaches in lip-sync accuracy, audio naturalness, and overall perceptual quality.
Attentive Knowledge Graph Embedding for Personalized Recommendation
Oct 30, 2019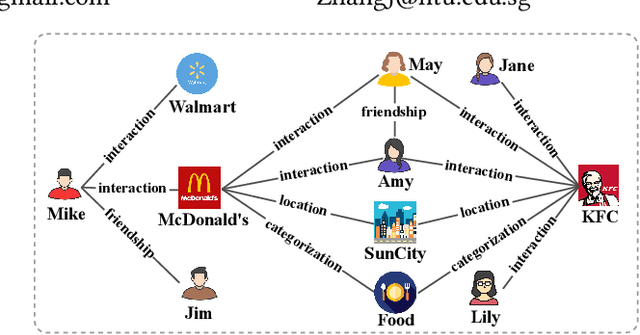
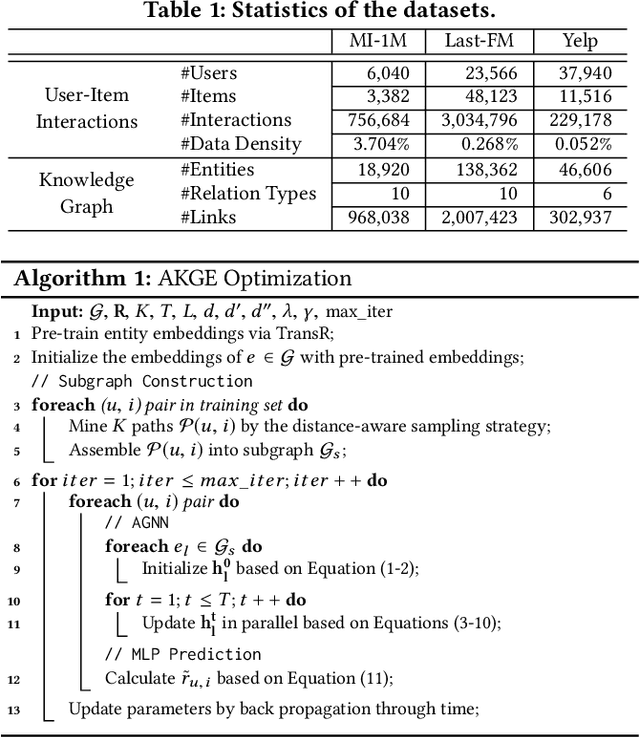
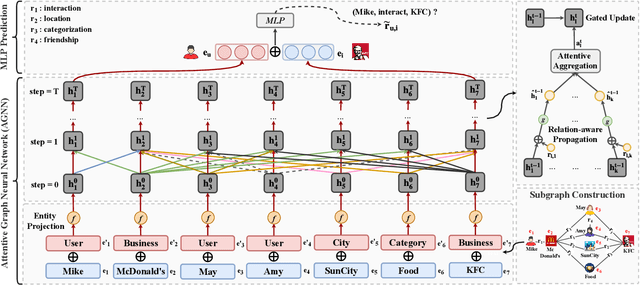

Knowledge graphs (KGs) have proven to be effective for high-quality recommendation. Most efforts, however, explore KGs by either extracting separate paths connecting user-item pairs, or iteratively propagating user preference over the entire KGs, thus failing to efficiently exploit KGs for enhanced recommendation. In this paper, we design a novel attentive knowledge graph embedding (AKGE) framework for recommendation, which sufficiently exploits both semantics and topology of KGs in an interaction-specific manner. Specifically, AKGE first automatically extracts high-order subgraphs that link user-item pairs with rich semantics, and then encodes the subgraphs by the proposed attentive graph neural network to learn accurate user preference. Extensive experiments on three real-world datasets demonstrate that AKGE consistently outperforms state-of-the-art methods. It additionally provides potential explanations for the recommendation results.