 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Context Generation for Question Generation
Jun 19, 2024Despite rapid advancements in large language models (LLMs), QG remains a challenging problem due to its complicated process, open-ended nature, and the diverse settings in which question generation occurs. A common approach to address these challenges involves fine-tuning smaller, custom models using datasets containing background context, question, and answer. However, obtaining suitable domain-specific datasets with appropriate context is often more difficult than acquiring question-answer pairs. In this paper, we investigate training QG models using synthetic contexts generated by LLMs from readily available question-answer pairs. We conduct a comprehensive study to answer critical research questions related to the performance of models trained on synthetic contexts and their potential impact on QG research and applications. Our empirical results reveal: 1) contexts are essential for QG tasks, even if they are synthetic; 2) fine-tuning smaller language models has the capability of achieving better performances as compared to prompting larger language models; and 3) synthetic context and real context could achieve comparable performances. These findings highlight the effectiveness of synthetic contexts in QG and paves the way for future advancements in the field.
Toffee: Efficient Million-Scale Dataset Construction for Subject-Driven Text-to-Image Generation
Jun 13, 2024



In subject-driven text-to-image generation, recent works have achieved superior performance by training the model on synthetic datasets containing numerous image pairs. Trained on these datasets, generative models can produce text-aligned images for specific subject from arbitrary testing image in a zero-shot manner. They even outperform methods which require additional fine-tuning on testing images. However, the cost of creating such datasets is prohibitive for most researchers. To generate a single training pair, current methods fine-tune a pre-trained text-to-image model on the subject image to capture fine-grained details, then use the fine-tuned model to create images for the same subject based on creative text prompts. Consequently, constructing a large-scale dataset with millions of subjects can require hundreds of thousands of GPU hours. To tackle this problem, we propose Toffee, an efficient method to construct datasets for subject-driven editing and generation. Specifically, our dataset construction does not need any subject-level fine-tuning. After pre-training two generative models, we are able to generate infinite number of high-quality samples. We construct the first large-scale dataset for subject-driven image editing and generation, which contains 5 million image pairs, text prompts, and masks. Our dataset is 5 times the size of previous largest dataset, yet our cost is tens of thousands of GPU hours lower. To test the proposed dataset, we also propose a model which is capable of both subject-driven image editing and generation. By simply training the model on our proposed dataset, it obtains competitive results, illustrating the effectiveness of the proposed dataset construction framework.
Improve Temporal Awareness of LLMs for Sequential Recommendation
May 05, 2024



Large language models (LLMs) have demonstrated impressive zero-shot abilities in solving a wide range of general-purpose tasks. However, it is empirically found that LLMs fall short in recognizing and utilizing temporal information, rendering poor performance in tasks that require an understanding of sequential data, such as sequential recommendation. In this paper, we aim to improve temporal awareness of LLMs by designing a principled prompting framework inspired by human cognitive processes. Specifically, we propose three prompting strategies to exploit temporal information within historical interactions for LLM-based sequential recommendation. Besides, we emulate divergent thinking by aggregating LLM ranking results derived from these strategies. Evaluations on MovieLens-1M and Amazon Review datasets indicate that our proposed method significantly enhances the zero-shot capabilities of LLMs in sequential recommendation tasks.
AutoDAN: Automatic and Interpretable Adversarial Attacks on Large Language Models
Oct 23, 2023

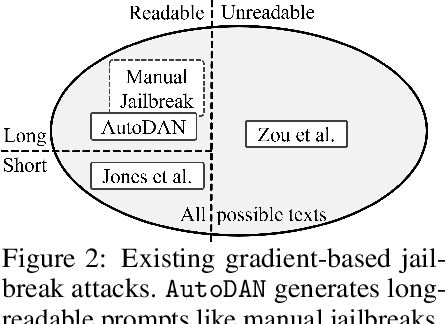

Safety alignment of Large Language Models (LLMs) can be compromised with manual jailbreak attacks and (automatic) adversarial attacks. Recent work suggests that patching LLMs against these attacks is possible: manual jailbreak attacks are human-readable but often limited and public, making them easy to block; adversarial attacks generate gibberish prompts that can be detected using perplexity-based filters. In this paper, we show that these solutions may be too optimistic. We propose an interpretable adversarial attack, \texttt{AutoDAN}, that combines the strengths of both types of attacks. It automatically generates attack prompts that bypass perplexity-based filters while maintaining a high attack success rate like manual jailbreak attacks. These prompts are interpretable and diverse, exhibiting strategies commonly used in manual jailbreak attacks, and transfer better than their non-readable counterparts when using limited training data or a single proxy model. We also customize \texttt{AutoDAN}'s objective to leak system prompts, another jailbreak application not addressed in the adversarial attack literature. %, demonstrating the versatility of the approach. We can also customize the objective of \texttt{AutoDAN} to leak system prompts, beyond the ability to elicit harmful content from the model, demonstrating the versatility of the approach. Our work provides a new way to red-team LLMs and to understand the mechanism of jailbreak attacks.
Novice Learner and Expert Tutor: Evaluating Math Reasoning Abilities of Large Language Models with Misconceptions
Oct 03, 2023



We propose novel evaluations for mathematical reasoning capabilities of Large Language Models (LLMs) based on mathematical misconceptions. Our primary approach is to simulate LLMs as a novice learner and an expert tutor, aiming to identify the incorrect answer to math question resulted from a specific misconception and to recognize the misconception(s) behind an incorrect answer, respectively. Contrary to traditional LLMs-based mathematical evaluations that focus on answering math questions correctly, our approach takes inspirations from principles in educational learning sciences. We explicitly ask LLMs to mimic a novice learner by answering questions in a specific incorrect manner based on incomplete knowledge; and to mimic an expert tutor by identifying misconception(s) corresponding to an incorrect answer to a question. Using simple grade-school math problems, our experiments reveal that, while LLMs can easily answer these questions correctly, they struggle to identify 1) the incorrect answer corresponding to specific incomplete knowledge (misconceptions); 2) the misconceptions that explain particular incorrect answers. Our study indicates new opportunities for enhancing LLMs' math reasoning capabilities, especially on developing robust student simulation and expert tutoring models in the educational applications such as intelligent tutoring systems.
MultiQG-TI: Towards Question Generation from Multi-modal Sources
Jul 07, 2023We study the new problem of automatic question generation (QG) from multi-modal sources containing images and texts, significantly expanding the scope of most of the existing work that focuses exclusively on QG from only textual sources. We propose a simple solution for our new problem, called MultiQG-TI, which enables a text-only question generator to process visual input in addition to textual input. Specifically, we leverage an image-to-text model and an optical character recognition model to obtain the textual description of the image and extract any texts in the image, respectively, and then feed them together with the input texts to the question generator. We only fine-tune the question generator while keeping the other components fixed. On the challenging ScienceQA dataset, we demonstrate that MultiQG-TI significantly outperforms ChatGPT with few-shot prompting, despite having hundred-times less trainable parameters. Additional analyses empirically confirm the necessity of both visual and textual signals for QG and show the impact of various modeling choices.
Improving Reading Comprehension Question Generation with Data Augmentation and Overgenerate-and-rank
Jun 15, 2023



Reading comprehension is a crucial skill in many aspects of education, including language learning, cognitive development, and fostering early literacy skills in children. Automated answer-aware reading comprehension question generation has significant potential to scale up learner support in educational activities. One key technical challenge in this setting is that there can be multiple questions, sometimes very different from each other, with the same answer; a trained question generation method may not necessarily know which question human educators would prefer. To address this challenge, we propose 1) a data augmentation method that enriches the training dataset with diverse questions given the same context and answer and 2) an overgenerate-and-rank method to select the best question from a pool of candidates. We evaluate our method on the FairytaleQA dataset, showing a 5% absolute improvement in ROUGE-L over the best existing method. We also demonstrate the effectiveness of our method in generating harder, "implicit" questions, where the answers are not contained in the context as text spans.
Interpretable Math Word Problem Solution Generation Via Step-by-step Planning
Jun 01, 2023



Solutions to math word problems (MWPs) with step-by-step explanations are valuable, especially in education, to help students better comprehend problem-solving strategies. Most existing approaches only focus on obtaining the final correct answer. A few recent approaches leverage intermediate solution steps to improve final answer correctness but often cannot generate coherent steps with a clear solution strategy. Contrary to existing work, we focus on improving the correctness and coherence of the intermediate solutions steps. We propose a step-by-step planning approach for intermediate solution generation, which strategically plans the generation of the next solution step based on the MWP and the previous solution steps. Our approach first plans the next step by predicting the necessary math operation needed to proceed, given history steps, then generates the next step, token-by-token, by prompting a language model with the predicted math operation. Experiments on the GSM8K dataset demonstrate that our approach improves the accuracy and interpretability of the solution on both automatic metrics and human evaluation.
MANER: Mask Augmented Named Entity Recognition for Extreme Low-Resource Languages
Dec 19, 2022This paper investigates the problem of Named Entity Recognition (NER) for extreme low-resource languages with only a few hundred tagged data samples. NER is a fundamental task in Natural Language Processing (NLP). A critical driver accelerating NER systems' progress is the existence of large-scale language corpora that enable NER systems to achieve outstanding performance in languages such as English and French with abundant training data. However, NER for low-resource languages remains relatively unexplored. In this paper, we introduce Mask Augmented Named Entity Recognition (MANER), a new methodology that leverages the distributional hypothesis of pre-trained masked language models (MLMs) for NER. The <mask> token in pre-trained MLMs encodes valuable semantic contextual information. MANER re-purposes the <mask> token for NER prediction. Specifically, we prepend the <mask> token to every word in a sentence for which we would like to predict the named entity tag. During training, we jointly fine-tune the MLM and a new NER prediction head attached to each <mask> token. We demonstrate that MANER is well-suited for NER in low-resource languages; our experiments show that for 100 languages with as few as 100 training examples, it improves on state-of-the-art methods by up to 48% and by 12% on average on F1 score. We also perform detailed analyses and ablation studies to understand the scenarios that are best-suited to MANER.
TITAN: Bringing The Deep Image Prior to Implicit Representations
Nov 01, 2022We study the interpolation capabilities of implicit neural representations (INRs) of images. In principle, INRs promise a number of advantages, such as continuous derivatives and arbitrary sampling, being freed from the restrictions of a raster grid. However, empirically, INRs have been observed to poorly interpolate between the pixels of the fit image; in other words, they do not inherently possess a suitable prior for natural images. In this paper, we propose to address and improve INRs' interpolation capabilities by explicitly integrating image prior information into the INR architecture via deep decoder, a specific implementation of the deep image prior (DIP). Our method, which we call TITAN, leverages a residual connection from the input which enables integrating the principles of the grid-based DIP into the grid-free INR. Through super-resolution and computed tomography experiments, we demonstrate that our method significantly improves upon classic INRs, thanks to the induced natural image bias. We also find that by constraining the weights to be sparse, image quality and sharpness are enhanced, increasing the Lipschitz constant.