 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLIONs: An Empirically Optimized Approach to Align Language Models
Jul 09, 2024



Alignment is a crucial step to enhance the instruction-following and conversational abilities of language models. Despite many recent work proposing new algorithms, datasets, and training pipelines, there is a lack of comprehensive studies measuring the impact of various design choices throughout the whole training process. We first conduct a rigorous analysis over a three-stage training pipeline consisting of supervised fine-tuning, offline preference learning, and online preference learning. We have found that using techniques like sequence packing, loss masking in SFT, increasing the preference dataset size in DPO, and online DPO training can significantly improve the performance of language models. We then train from Gemma-2b-base and LLama-3-8b-base, and find that our best models exceed the performance of the official instruct models tuned with closed-source data and algorithms. Our code and models can be found at https://github.com/Columbia-NLP-Lab/LionAlignment.
DECOR: Improving Coherence in L2 English Writing with a Novel Benchmark for Incoherence Detection, Reasoning, and Rewriting
Jun 28, 2024



Coherence in writing, an aspect that second-language (L2) English learners often struggle with, is crucial in assessing L2 English writing. Existing automated writing evaluation systems primarily use basic surface linguistic features to detect coherence in writing. However, little effort has been made to correct the detected incoherence, which could significantly benefit L2 language learners seeking to improve their writing. To bridge this gap, we introduce DECOR, a novel benchmark that includes expert annotations for detecting incoherence in L2 English writing, identifying the underlying reasons, and rewriting the incoherent sentences. To our knowledge, DECOR is the first coherence assessment dataset specifically designed for improving L2 English writing, featuring pairs of original incoherent sentences alongside their expert-rewritten counterparts. Additionally, we fine-tuned models to automatically detect and rewrite incoherence in student essays. We find that incorporating specific reasons for incoherence during fine-tuning consistently improves the quality of the rewrites, achieving a result that is favored in both automatic and human evaluations.
VarBench: Robust Language Model Benchmarking Through Dynamic Variable Perturbation
Jun 26, 2024



As large language models achieve impressive scores on traditional benchmarks, an increasing number of researchers are becoming concerned about benchmark data leakage during pre-training, commonly known as the data contamination problem. To ensure fair evaluation, recent benchmarks release only the training and validation sets, keeping the test set labels closed-source. They require anyone wishing to evaluate his language model to submit the model's predictions for centralized processing and then publish the model's result on their leaderboard. However, this submission process is inefficient and prevents effective error analysis. To address this issue, we propose to variabilize benchmarks and evaluate language models dynamically. Specifically, we extract variables from each test case and define a value range for each variable. For each evaluation, we sample new values from these value ranges to create unique test cases, thus ensuring a fresh evaluation each time. We applied this variable perturbation method to four datasets: GSM8K, ARC, CommonsenseQA, and TruthfulQA, which cover mathematical generation and multiple-choice tasks. Our experimental results demonstrate that this approach provides a more accurate assessment of the true capabilities of language models, effectively mitigating the contamination problem.
EDEN: Empathetic Dialogues for English learning
Jun 25, 2024

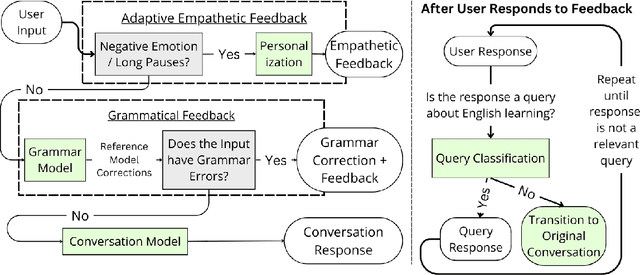
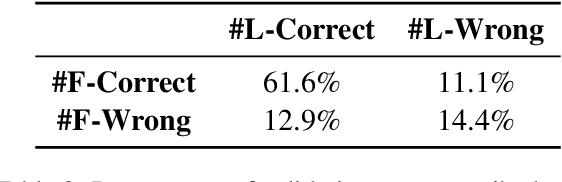
Dialogue systems have been used as conversation partners in English learning, but few have studied whether these systems improve learning outcomes. Student passion and perseverance, or grit, has been associated with language learning success. Recent work establishes that as students perceive their English teachers to be more supportive, their grit improves. Hypothesizing that the same pattern applies to English-teaching chatbots, we create EDEN, a robust open-domain chatbot for spoken conversation practice that provides empathetic feedback. To construct EDEN, we first train a specialized spoken utterance grammar correction model and a high-quality social chit-chat conversation model. We then conduct a preliminary user study with a variety of strategies for empathetic feedback. Our experiment suggests that using adaptive empathetic feedback leads to higher perceived affective support, which, in turn, predicts increased student grit.
TinyStyler: Efficient Few-Shot Text Style Transfer with Authorship Embeddings
Jun 21, 2024



The goal of text style transfer is to transform the style of texts while preserving their original meaning, often with only a few examples of the target style. Existing style transfer methods generally rely on the few-shot capabilities of large language models or on complex controllable text generation approaches that are inefficient and underperform on fluency metrics. We introduce TinyStyler, a lightweight but effective approach, which leverages a small language model (800M params) and pre-trained authorship embeddings to perform efficient, few-shot text style transfer. We evaluate on the challenging task of authorship style transfer and find TinyStyler outperforms strong approaches such as GPT-4. We also evaluate TinyStyler's ability to perform text attribute style transfer (formal $\leftrightarrow$ informal) with automatic and human evaluations and find that the approach outperforms recent controllable text generation methods. Our model has been made publicly available at https://huggingface.co/tinystyler/tinystyler .
Investigation of Customized Medical Decision Algorithms Utilizing Graph Neural Networks
May 23, 2024



Aiming at the limitations of traditional medical decision system in processing large-scale heterogeneous medical data and realizing highly personalized recommendation, this paper introduces a personalized medical decision algorithm utilizing graph neural network (GNN). This research innovatively integrates graph neural network technology into the medical and health field, aiming to build a high-precision representation model of patient health status by mining the complex association between patients' clinical characteristics, genetic information, living habits. In this study, medical data is preprocessed to transform it into a graph structure, where nodes represent different data entities (such as patients, diseases, genes, etc.) and edges represent interactions or relationships between entities. The core of the algorithm is to design a novel multi-scale fusion mechanism, combining the historical medical records, physiological indicators and genetic characteristics of patients, to dynamically adjust the attention allocation strategy of the graph neural network, so as to achieve highly customized analysis of individual cases. In the experimental part, this study selected several publicly available medical data sets for validation, and the results showed that compared with traditional machine learning methods and a single graph neural network model, the proposed personalized medical decision algorithm showed significantly superior performance in terms of disease prediction accuracy, treatment effect evaluation and patient risk stratification.
Imp: Highly Capable Large Multimodal Models for Mobile Devices
May 20, 2024By harnessing the capabilities of large language models (LLMs), recent large multimodal models (LMMs) have shown remarkable versatility in open-world multimodal understanding. Nevertheless, they are usually parameter-heavy and computation-intensive, thus hindering their applicability in resource-constrained scenarios. To this end, several lightweight LMMs have been proposed successively to maximize the capabilities under constrained scale (e.g., 3B). Despite the encouraging results achieved by these methods, most of them only focus on one or two aspects of the design space, and the key design choices that influence model capability have not yet been thoroughly investigated. In this paper, we conduct a systematic study for lightweight LMMs from the aspects of model architecture, training strategy, and training data. Based on our findings, we obtain Imp -- a family of highly capable LMMs at the 2B-4B scales. Notably, our Imp-3B model steadily outperforms all the existing lightweight LMMs of similar size, and even surpasses the state-of-the-art LMMs at the 13B scale. With low-bit quantization and resolution reduction techniques, our Imp model can be deployed on a Qualcomm Snapdragon 8Gen3 mobile chip with a high inference speed of about 13 tokens/s.
Research on Intelligent Aided Diagnosis System of Medical Image Based on Computer Deep Learning
Apr 29, 2024This paper combines Struts and Hibernate two architectures together, using DAO (Data Access Object) to store and access data. Then a set of dual-mode humidity medical image library suitable for deep network is established, and a dual-mode medical image assisted diagnosis method based on the image is proposed. Through the test of various feature extraction methods, the optimal operating characteristic under curve product (AUROC) is 0.9985, the recall rate is 0.9814, and the accuracy is 0.9833. This method can be applied to clinical diagnosis, and it is a practical method. Any outpatient doctor can register quickly through the system, or log in to the platform to upload the image to obtain more accurate images. Through the system, each outpatient physician can quickly register or log in to the platform for image uploading, thus obtaining more accurate images. The segmentation of images can guide doctors in clinical departments. Then the image is analyzed to determine the location and nature of the tumor, so as to make targeted treatment.
Effective Unsupervised Constrained Text Generation based on Perturbed Masking
Apr 24, 2024Unsupervised constrained text generation aims to generate text under a given set of constraints without any supervised data. Current state-of-the-art methods stochastically sample edit positions and actions, which may cause unnecessary search steps. In this paper, we propose PMCTG to improve effectiveness by searching for the best edit position and action in each step. Specifically, PMCTG extends perturbed masking technique to effectively search for the most incongruent token to edit. Then it introduces four multi-aspect scoring functions to select edit action to further reduce search difficulty. Since PMCTG does not require supervised data, it could be applied to different generation tasks. We show that under the unsupervised setting, PMCTG achieves new state-of-the-art results in two representative tasks, namely keywords-to-sentence generation and paraphrasing.
Using Adaptive Empathetic Responses for Teaching English
Apr 21, 2024Existing English-teaching chatbots rarely incorporate empathy explicitly in their feedback, but empathetic feedback could help keep students engaged and reduce learner anxiety. Toward this end, we propose the task of negative emotion detection via audio, for recognizing empathetic feedback opportunities in language learning. We then build the first spoken English-teaching chatbot with adaptive, empathetic feedback. This feedback is synthesized through automatic prompt optimization of ChatGPT and is evaluated with English learners. We demonstrate the effectiveness of our system through a preliminary user study.