 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVL-Cogito: Progressive Curriculum Reinforcement Learning for Advanced Multimodal Reasoning
Jul 30, 2025



Reinforcement learning has proven its effectiveness in enhancing the reasoning capabilities of large language models. Recent research efforts have progressively extended this paradigm to multimodal reasoning tasks. Due to the inherent complexity and diversity of multimodal tasks, especially in semantic content and problem formulations, existing models often exhibit unstable performance across various domains and difficulty levels. To address these limitations, we propose VL-Cogito, an advanced multimodal reasoning model trained via a novel multi-stage Progressive Curriculum Reinforcement Learning (PCuRL) framework. PCuRL systematically guides the model through tasks of gradually increasing difficulty, substantially improving its reasoning abilities across diverse multimodal contexts. The framework introduces two key innovations: (1) an online difficulty soft weighting mechanism, dynamically adjusting training difficulty across successive RL training stages; and (2) a dynamic length reward mechanism, which encourages the model to adaptively regulate its reasoning path length according to task complexity, thus balancing reasoning efficiency with correctness. Experimental evaluations demonstrate that VL-Cogito consistently matches or surpasses existing reasoning-oriented models across mainstream multimodal benchmarks spanning mathematics, science, logic, and general understanding, validating the effectiveness of our approach.
Autoregressive Semantic Visual Reconstruction Helps VLMs Understand Better
Jun 10, 2025



Typical large vision-language models (LVLMs) apply autoregressive supervision solely to textual sequences, without fully incorporating the visual modality into the learning process. This results in three key limitations: (1) an inability to utilize images without accompanying captions, (2) the risk that captions omit critical visual details, and (3) the challenge that certain vision-centric content cannot be adequately conveyed through text. As a result, current LVLMs often prioritize vision-to-language alignment while potentially overlooking fine-grained visual information. While some prior works have explored autoregressive image generation, effectively leveraging autoregressive visual supervision to enhance image understanding remains an open challenge. In this paper, we introduce Autoregressive Semantic Visual Reconstruction (ASVR), which enables joint learning of visual and textual modalities within a unified autoregressive framework. We show that autoregressively reconstructing the raw visual appearance of images does not enhance and may even impair multimodal understanding. In contrast, autoregressively reconstructing the semantic representation of images consistently improves comprehension. Notably, we find that even when models are given continuous image features as input, they can effectively reconstruct discrete semantic tokens, resulting in stable and consistent improvements across a wide range of multimodal understanding benchmarks. Our approach delivers significant performance gains across varying data scales (556k-2M) and types of LLM bacbones. Specifically, ASVR improves LLaVA-1.5 by 5% in average scores across 14 multimodal benchmarks. The code is available at https://github.com/AlenjandroWang/ASVR.
AutoJudger: An Agent-Driven Framework for Efficient Benchmarking of MLLMs
May 27, 2025Evaluating multimodal large language models (MLLMs) is increasingly expensive, as the growing size and cross-modality complexity of benchmarks demand significant scoring efforts. To tackle with this difficulty, we introduce AutoJudger, an agent-driven framework for efficient and adaptive benchmarking of MLLMs that tackles this escalating cost. AutoJudger employs the Item Response Theory (IRT) to estimate the question difficulty and an autonomous evaluation agent to dynamically select the most informative test questions based on the model's real-time performance. Specifically, AutoJudger incorporates two pivotal components: a semantic-aware retrieval mechanism to ensure that selected questions cover diverse and challenging scenarios across both vision and language modalities, and a dynamic memory that maintains contextual statistics of previously evaluated questions to guide coherent and globally informed question selection throughout the evaluation process. Extensive experiments on four representative multimodal benchmarks demonstrate that our adaptive framework dramatically reduces evaluation expenses, i.e. AutoJudger uses only 4% of the data to achieve over 90% ranking accuracy with the full benchmark evaluation on MMT-Bench.
OViP: Online Vision-Language Preference Learning
May 21, 2025



Large vision-language models (LVLMs) remain vulnerable to hallucination, often generating content misaligned with visual inputs. While recent approaches advance multi-modal Direct Preference Optimization (DPO) to mitigate hallucination, they typically rely on predefined or randomly edited negative samples that fail to reflect actual model errors, limiting training efficacy. In this work, we propose an Online Vision-language Preference Learning (OViP) framework that dynamically constructs contrastive training data based on the model's own hallucinated outputs. By identifying semantic differences between sampled response pairs and synthesizing negative images using a diffusion model, OViP generates more relevant supervision signals in real time. This failure-driven training enables adaptive alignment of both textual and visual preferences. Moreover, we refine existing evaluation protocols to better capture the trade-off between hallucination suppression and expressiveness. Experiments on hallucination and general benchmarks demonstrate that OViP effectively reduces hallucinations while preserving core multi-modal capabilities.
Not All Models Suit Expert Offloading: On Local Routing Consistency of Mixture-of-Expert Models
May 21, 2025Mixture-of-Experts (MoE) enables efficient scaling of large language models (LLMs) with sparsely activated experts during inference. To effectively deploy large MoE models on memory-constrained devices, many systems introduce *expert offloading* that caches a subset of experts in fast memory, leaving others on slow memory to run on CPU or load on demand. While some research has exploited the locality of expert activations, where consecutive tokens activate similar experts, the degree of this **local routing consistency** varies across models and remains understudied. In this paper, we propose two metrics to measure local routing consistency of MoE models: (1) **Segment Routing Best Performance (SRP)**, which evaluates how well a fixed group of experts can cover the needs of a segment of tokens, and (2) **Segment Cache Best Hit Rate (SCH)**, which measures the optimal segment-level cache hit rate under a given cache size limit. We analyzed 20 MoE LLMs with diverse sizes and architectures and found that models that apply MoE on every layer and do not use shared experts exhibit the highest local routing consistency. We further showed that domain-specialized experts contribute more to routing consistency than vocabulary-specialized ones, and that most models can balance between cache effectiveness and efficiency with cache sizes approximately 2x the active experts. These findings pave the way for memory-efficient MoE design and deployment without compromising inference speed. We publish the code for replicating experiments at https://github.com/ljcleo/moe-lrc .
EcoLANG: Efficient and Effective Agent Communication Language Induction for Social Simulation
May 11, 2025



Large language models (LLMs) have demonstrated an impressive ability to role-play humans and replicate complex social dynamics. While large-scale social simulations are gaining increasing attention, they still face significant challenges, particularly regarding high time and computation costs. Existing solutions, such as distributed mechanisms or hybrid agent-based model (ABM) integrations, either fail to address inference costs or compromise accuracy and generalizability. To this end, we propose EcoLANG: Efficient and Effective Agent Communication Language Induction for Social Simulation. EcoLANG operates in two stages: (1) language evolution, where we filter synonymous words and optimize sentence-level rules through natural selection, and (2) language utilization, where agents in social simulations communicate using the evolved language. Experimental results demonstrate that EcoLANG reduces token consumption by over 20%, enhancing efficiency without sacrificing simulation accuracy.
SocioVerse: A World Model for Social Simulation Powered by LLM Agents and A Pool of 10 Million Real-World Users
Apr 14, 2025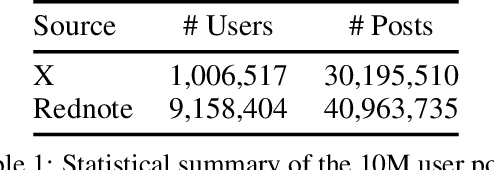
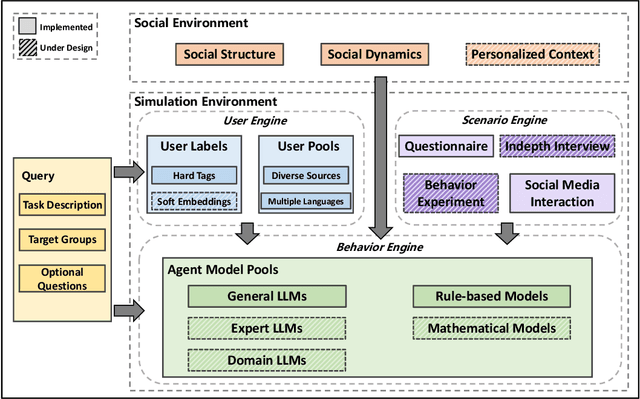

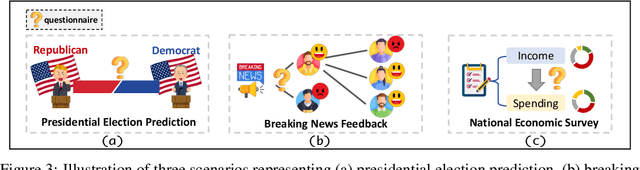
Social simulation is transforming traditional social science research by modeling human behavior through interactions between virtual individuals and their environments. With recent advances in large language models (LLMs), this approach has shown growing potential in capturing individual differences and predicting group behaviors. However, existing methods face alignment challenges related to the environment, target users, interaction mechanisms, and behavioral patterns. To this end, we introduce SocioVerse, an LLM-agent-driven world model for social simulation. Our framework features four powerful alignment components and a user pool of 10 million real individuals. To validate its effectiveness, we conducted large-scale simulation experiments across three distinct domains: politics, news, and economics. Results demonstrate that SocioVerse can reflect large-scale population dynamics while ensuring diversity, credibility, and representativeness through standardized procedures and minimal manual adjustments.
Word Form Matters: LLMs' Semantic Reconstruction under Typoglycemia
Mar 03, 2025Human readers can efficiently comprehend scrambled words, a phenomenon known as Typoglycemia, primarily by relying on word form; if word form alone is insufficient, they further utilize contextual cues for interpretation. While advanced large language models (LLMs) exhibit similar abilities, the underlying mechanisms remain unclear. To investigate this, we conduct controlled experiments to analyze the roles of word form and contextual information in semantic reconstruction and examine LLM attention patterns. Specifically, we first propose SemRecScore, a reliable metric to quantify the degree of semantic reconstruction, and validate its effectiveness. Using this metric, we study how word form and contextual information influence LLMs' semantic reconstruction ability, identifying word form as the core factor in this process. Furthermore, we analyze how LLMs utilize word form and find that they rely on specialized attention heads to extract and process word form information, with this mechanism remaining stable across varying levels of word scrambling. This distinction between LLMs' fixed attention patterns primarily focused on word form and human readers' adaptive strategy in balancing word form and contextual information provides insights into enhancing LLM performance by incorporating human-like, context-aware mechanisms.
Stepwise Informativeness Search for Improving LLM Reasoning
Feb 21, 2025Advances in Large Language Models (LLMs) have significantly improved multi-step reasoning through generating free-text rationales. However, recent studies show that LLMs tend to lose focus over the middle of long contexts. This raises concerns that as reasoning progresses, LLMs may overlook information in earlier steps when decoding subsequent steps, leading to generate unreliable and redundant rationales. To address this, we propose guiding LLMs to generate more accurate and concise step-by-step rationales by (1) proactively referencing information from underutilized prior steps, and (2) minimizing redundant information between new and existing steps. We introduce stepwise informativeness search, an inference-time tree search framework incorporating two selection heuristics: grounding-guided selection which prioritizes steps paying higher attention over underutilized steps; and novelty-guided selection which encourages steps with novel conclusions. During rationale generation, we use a self-grounding strategy that prompts LLMs to explicitly reference relevant prior steps to provide premises before deduction at each step. Experimental results on four reasoning datasets demonstrate that our approach improves reasoning accuracy by generating higher-quality rationales with reduced errors and redundancy.
How Jailbreak Defenses Work and Ensemble? A Mechanistic Investigation
Feb 20, 2025Jailbreak attacks, where harmful prompts bypass generative models' built-in safety, raise serious concerns about model vulnerability. While many defense methods have been proposed, the trade-offs between safety and helpfulness, and their application to Large Vision-Language Models (LVLMs), are not well understood. This paper systematically examines jailbreak defenses by reframing the standard generation task as a binary classification problem to assess model refusal tendencies for both harmful and benign queries. We identify two key defense mechanisms: safety shift, which increases refusal rates across all queries, and harmfulness discrimination, which improves the model's ability to distinguish between harmful and benign inputs. Using these mechanisms, we develop two ensemble defense strategies-inter-mechanism ensembles and intra-mechanism ensembles-to balance safety and helpfulness. Experiments on the MM-SafetyBench and MOSSBench datasets with LLaVA-1.5 models show that these strategies effectively improve model safety or optimize the trade-off between safety and helpfulness.