 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Semantic Dominance: Cognitive Affective Reasoning and Empathetic Response Alignment in Audio Language Models
Jun 05, 2026While Audio Language Models (ALMs) demonstrate strong semantic understanding, they struggle with complex affective interactions. Specifically, textual semantic dominance often overshadows acoustic nuances, and a lack of cognitive depth leads to generic, emotion-agnostic responses. We propose CogAudio-LLM\footnote{ \urlstyle{same} https://github.com/zxzhao0/CogAudio-LLM, a novel cognitive affective reasoning framework. To mitigate semantic dominance, we build LIME-440K, a ``lexically-identical, multi-emotion'' dataset designed to facilitate acoustic-semantic decoupling. We introduce EIPS, a 4-step Chain-of-Thought (CoT) mechanism incorporating psychological reasoning. For inference efficiency, multi-stage training explicitly establishes EIPS via supervised fine-tuning, then distills this logic into an implicit generation process. Finally, we design DR-SAPO (Dual-Route Soft Adaptive Policy Optimization) to dynamically balance the logical rigor of the CoT with the empathetic quality of the direct response.
Towards Fine-Grained Multi-Dimensional Speech Understanding: Data Pipeline, Benchmark, and Model
May 12, 2026While speech Large Language Models (LLMs) excel at conventional tasks like basic speech recognition, they lack fine-grained, multi-dimensional perception. This deficiency is evident in their struggle to disentangle complex features like micro-acoustic cues, acoustic scenes, and paralinguistic signals. This resulting incomplete comprehension of real-world speech fundamentally bottlenecks the development of perceptive and empathetic next-generation speech systems. At its core, this persistent perceptual limitation primarily stems from three interacting factors: scarce high-quality expressive data, absent fine-grained modeling for multi-dimensional attributes, and reliance on restricted coverage, coarse-grained benchmarks. We address these challenges through three pillars: First, our robust data curation pipeline resolves complex acoustic environments and long-audio timestamp alignment challenges to extract a high-quality spontaneous speech corpus from audiovisual sources. Second, we construct FMSU-Bench, a pioneering benchmark covering 14 speech attribute dimensions to rigorously assess the fine-grained, multi-dimensional speech understanding capabilities of current models. Third, empowered by our curated corpus, we introduce FM-Speech. Driven by a decoupled attribute modeling and progressive curriculum fine-tuning framework, it substantially elevates fine-grained, multi-dimensional acoustic perception. Extensive evaluations on FMSU-Bench reveal that current speech LLMs still require significant improvement in multi-dimensional, fine-grained understanding. In contrast, FM-Speech substantially outperforms current open-source models, establishing a robust paradigm for real-world speech understanding.
Full-Duplex Interaction in Spoken Dialogue Systems: A Comprehensive Study from the ICASSP 2026 HumDial Challenge
Apr 23, 2026Full-duplex interaction, where speakers and listeners converse simultaneously, is a key element of human communication often missing from traditional spoken dialogue systems. These systems, based on rigid turn-taking paradigms, struggle to respond naturally in dynamic conversations. The Full-Duplex Interaction Track of ICASSP 2026 Human-like Spoken Dialogue Systems Challenge (HumDial Challenge) aims to advance the evaluation of full-duplex systems by offering a framework for handling real-time interruptions, speech overlap, and dynamic turn negotiation. We introduce a comprehensive benchmark for full-duplex spoken dialogue systems, built from the HumDial Challenge. We release a high-quality dual-channel dataset of real human-recorded conversations, capturing interruptions, overlapping speech, and feedback mechanisms. This dataset forms the basis for the HumDial-FDBench benchmark, which assesses a system's ability to handle interruptions while maintaining conversational flow. Additionally, we create a public leaderboard to compare the performance of open-source and proprietary models, promoting transparent, reproducible evaluation. These resources support the development of more responsive, adaptive, and human-like dialogue systems.
HumDial-EIBench: A Human-Recorded Multi-Turn Emotional Intelligence Benchmark for Audio Language Models
Apr 13, 2026Evaluating the emotional intelligence (EI) of audio language models (ALMs) is critical. However, existing benchmarks mostly rely on synthesized speech, are limited to single-turn interactions, and depend heavily on open-ended scoring. This paper proposes HumDial-EIBench, a comprehensive benchmark for evaluating ALMs' EI. Using real-recorded human dialogues from the ICASSP 2026 HumDial Challenge, it reformulates emotional tracking and causal reasoning into multiple-choice questions with adversarial distractors, mitigating subjective scoring bias for cognitive tasks. It retains the generation of empathetic responses and introduces an acoustic-semantic conflict task to assess robustness against contradictory multimodal signals. Evaluations of eight ALMs reveal that most models struggle with multi-turn emotional tracking and implicit causal reasoning. Furthermore, all models exhibit decoupled textual and acoustic empathy, alongside a severe text-dominance bias during cross-modal conflicts.
EmoOmni: Bridging Emotional Understanding and Expression in Omni-Modal LLMs
Feb 25, 2026The evolution of Omni-Modal Large Language Models~(Omni-LLMs) has revolutionized human--computer interaction, enabling unified audio-visual perception and speech response. However, existing Omni-LLMs struggle with complex real-world scenarios, often leading to superficial understanding and contextually mismatched emotional responses. This issue is further intensified by Omni-LLM's Thinker-Talker architectures, which are implicitly connected through hidden states, leading to the loss of emotional details. In this work, we present EmoOmni, a unified framework for accurate understanding and expression in multimodal emotional dialogue. At its core, we introduce the emotional Chain-of-Thought~(E-CoT), which enforces a reasoning from fine-grained multimodal perception to textual response. Moreover, we explicitly treat E-CoT as high-level emotional instructions that guide the talker, enabling accurate emotional expression. Complementing the model, we construct EmoOmniPipe to obtain the real-world annotated dialogue data and establish a benchmark, EmoOmniEval, to facilitate systematic assessment of multimodal emotional dialogue task. Experiments show that EmoOmni-7B achieves comparable performance with Qwen3Omni-30B-A3B-Thinking under the same talker.
Integrating Fine-Grained Audio-Visual Evidence for Robust Multimodal Emotion Reasoning
Jan 26, 2026Multimodal emotion analysis is shifting from static classification to generative reasoning. Beyond simple label prediction, robust affective reasoning must synthesize fine-grained signals such as facial micro-expressions and prosodic which shifts to decode the latent causality within complex social contexts. However, current Multimodal Large Language Models (MLLMs) face significant limitations in fine-grained perception, primarily due to data scarcity and insufficient cross-modal fusion. As a result, these models often exhibit unimodal dominance which leads to hallucinations in complex multimodal interactions, particularly when visual and acoustic cues are subtle, ambiguous, or even contradictory (e.g., in sarcastic scenery). To address this, we introduce SABER-LLM, a framework designed for robust multimodal reasoning. First, we construct SABER, a large-scale emotion reasoning dataset comprising 600K video clips, annotated with a novel six-dimensional schema that jointly captures audiovisual cues and causal logic. Second, we propose the structured evidence decomposition paradigm, which enforces a "perceive-then-reason" separation between evidence extraction and reasoning to alleviate unimodal dominance. The ability to perceive complex scenes is further reinforced by consistency-aware direct preference optimization, which explicitly encourages alignment among modalities under ambiguous or conflicting perceptual conditions. Experiments on EMER, EmoBench-M, and SABER-Test demonstrate that SABER-LLM significantly outperforms open-source baselines and achieves robustness competitive with closed-source models in decoding complex emotional dynamics. The dataset and model are available at https://github.com/zxzhao0/SABER-LLM.
dLLM-ASR: A Faster Diffusion LLM-based Framework for Speech Recognition
Jan 25, 2026Automatic speech recognition (ASR) systems based on large language models (LLMs) achieve superior performance by leveraging pretrained LLMs as decoders, but their token-by-token generation mechanism leads to inference latency that grows linearly with sequence length. Meanwhile, discrete diffusion large language models (dLLMs) offer a promising alternative, enabling high-quality parallel sequence generation with pretrained decoders. However, directly applying native text-oriented dLLMs to ASR leads to a fundamental mismatch between open-ended text generation and the acoustically conditioned transcription paradigm required by ASR. As a result, it introduces unnecessary difficulty and computational redundancy, such as denoising from pure noise, inflexible generation lengths, and fixed denoising steps. We propose dLLM-ASR, an efficient dLLM-based ASR framework that formulates dLLM's decoding as a prior-guided and adaptive denoising process. It leverages an ASR prior to initialize the denoising process and provide an anchor for sequence length. Building upon this prior, length-adaptive pruning dynamically removes redundant tokens, while confidence-based denoising allows converged tokens to exit the denoising loop early, enabling token-level adaptive computation. Experiments demonstrate that dLLM-ASR achieves recognition accuracy comparable to autoregressive LLM-based ASR systems and delivers a 4.44$\times$ inference speedup, establishing a practical and efficient paradigm for ASR.
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Mar 03, 2025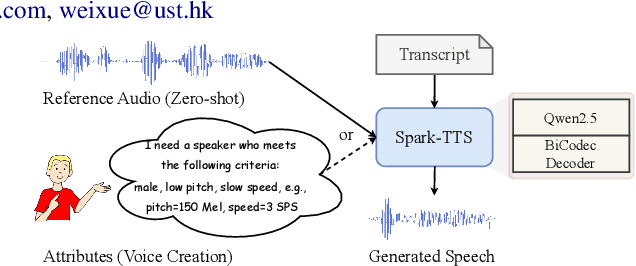



Recent advancements in large language models (LLMs) have driven significant progress in zero-shot text-to-speech (TTS) synthesis. However, existing foundation models rely on multi-stage processing or complex architectures for predicting multiple codebooks, limiting efficiency and integration flexibility. To overcome these challenges, we introduce Spark-TTS, a novel system powered by BiCodec, a single-stream speech codec that decomposes speech into two complementary token types: low-bitrate semantic tokens for linguistic content and fixed-length global tokens for speaker attributes. This disentangled representation, combined with the Qwen2.5 LLM and a chain-of-thought (CoT) generation approach, enables both coarse-grained control (e.g., gender, speaking style) and fine-grained adjustments (e.g., precise pitch values, speaking rate). To facilitate research in controllable TTS, we introduce VoxBox, a meticulously curated 100,000-hour dataset with comprehensive attribute annotations. Extensive experiments demonstrate that Spark-TTS not only achieves state-of-the-art zero-shot voice cloning but also generates highly customizable voices that surpass the limitations of reference-based synthesis. Source code, pre-trained models, and audio samples are available at https://github.com/SparkAudio/Spark-TTS.
Steering Language Model to Stable Speech Emotion Recognition via Contextual Perception and Chain of Thought
Feb 25, 2025



Large-scale audio language models (ALMs), such as Qwen2-Audio, are capable of comprehending diverse audio signal, performing audio analysis and generating textual responses. However, in speech emotion recognition (SER), ALMs often suffer from hallucinations, resulting in misclassifications or irrelevant outputs. To address these challenges, we propose C$^2$SER, a novel ALM designed to enhance the stability and accuracy of SER through Contextual perception and Chain of Thought (CoT). C$^2$SER integrates the Whisper encoder for semantic perception and Emotion2Vec-S for acoustic perception, where Emotion2Vec-S extends Emotion2Vec with semi-supervised learning to enhance emotional discrimination. Additionally, C$^2$SER employs a CoT approach, processing SER in a step-by-step manner while leveraging speech content and speaking styles to improve recognition. To further enhance stability, C$^2$SER introduces self-distillation from explicit CoT to implicit CoT, mitigating error accumulation and boosting recognition accuracy. Extensive experiments show that C$^2$SER outperforms existing popular ALMs, such as Qwen2-Audio and SECap, delivering more stable and precise emotion recognition. We release the training code, checkpoints, and test sets to facilitate further research.
Improving Multimodal Emotion Recognition by Leveraging Acoustic Adaptation and Visual Alignment
Sep 10, 2024



Multimodal Emotion Recognition (MER) aims to automatically identify and understand human emotional states by integrating information from various modalities. However, the scarcity of annotated multimodal data significantly hinders the advancement of this research field. This paper presents our solution for the MER-SEMI sub-challenge of MER 2024. First, to better adapt acoustic modality features for the MER task, we experimentally evaluate the contributions of different layers of the pre-trained speech model HuBERT in emotion recognition. Based on these observations, we perform Parameter-Efficient Fine-Tuning (PEFT) on the layers identified as most effective for emotion recognition tasks, thereby achieving optimal adaptation for emotion recognition with a minimal number of learnable parameters. Second, leveraging the strengths of the acoustic modality, we propose a feature alignment pre-training method. This approach uses large-scale unlabeled data to train a visual encoder, thereby promoting the semantic alignment of visual features within the acoustic feature space. Finally, using the adapted acoustic features, aligned visual features, and lexical features, we employ an attention mechanism for feature fusion. On the MER2024-SEMI test set, the proposed method achieves a weighted F1 score of 88.90%, ranking fourth among all participating teams, validating the effectiveness of our approach.