 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnlarging Instance-specific and Class-specific Information for Open-set Action Recognition
Mar 25, 2023Open-set action recognition is to reject unknown human action cases which are out of the distribution of the training set. Existing methods mainly focus on learning better uncertainty scores but dismiss the importance of feature representations. We find that features with richer semantic diversity can significantly improve the open-set performance under the same uncertainty scores. In this paper, we begin with analyzing the feature representation behavior in the open-set action recognition (OSAR) problem based on the information bottleneck (IB) theory, and propose to enlarge the instance-specific (IS) and class-specific (CS) information contained in the feature for better performance. To this end, a novel Prototypical Similarity Learning (PSL) framework is proposed to keep the instance variance within the same class to retain more IS information. Besides, we notice that unknown samples sharing similar appearances to known samples are easily misclassified as known classes. To alleviate this issue, video shuffling is further introduced in our PSL to learn distinct temporal information between original and shuffled samples, which we find enlarges the CS information. Extensive experiments demonstrate that the proposed PSL can significantly boost both the open-set and closed-set performance and achieves state-of-the-art results on multiple benchmarks. Code is available at https://github.com/Jun-CEN/PSL.
HyRSM++: Hybrid Relation Guided Temporal Set Matching for Few-shot Action Recognition
Jan 09, 2023



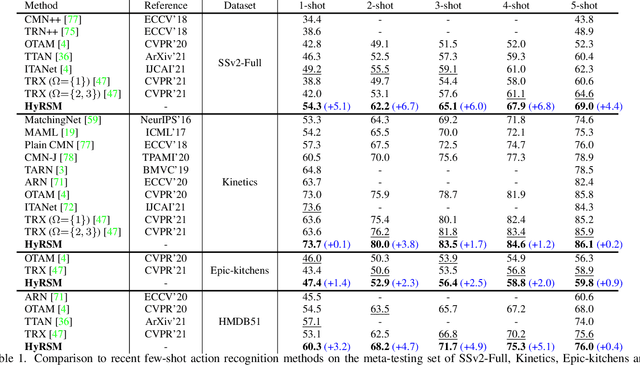
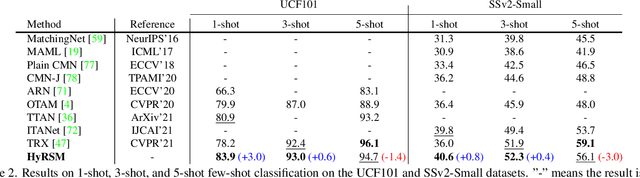
Recent attempts mainly focus on learning deep representations for each video individually under the episodic meta-learning regime and then performing temporal alignment to match query and support videos. However, they still suffer from two drawbacks: (i) learning individual features without considering the entire task may result in limited representation capability, and (ii) existing alignment strategies are sensitive to noises and misaligned instances. To handle the two limitations, we propose a novel Hybrid Relation guided temporal Set Matching (HyRSM++) approach for few-shot action recognition. The core idea of HyRSM++ is to integrate all videos within the task to learn discriminative representations and involve a robust matching technique. To be specific, HyRSM++ consists of two key components, a hybrid relation module and a temporal set matching metric. Given the basic representations from the feature extractor, the hybrid relation module is introduced to fully exploit associated relations within and cross videos in an episodic task and thus can learn task-specific embeddings. Subsequently, in the temporal set matching metric, we carry out the distance measure between query and support videos from a set matching perspective and design a Bi-MHM to improve the resilience to misaligned instances. In addition, we explicitly exploit the temporal coherence in videos to regularize the matching process. Furthermore, we extend the proposed HyRSM++ to deal with the more challenging semi-supervised few-shot action recognition and unsupervised few-shot action recognition tasks. Experimental results on multiple benchmarks demonstrate that our method achieves state-of-the-art performance under various few-shot settings. The source code is available at https://github.com/alibaba-mmai-research/HyRSMPlusPlus.
Learning a Condensed Frame for Memory-Efficient Video Class-Incremental Learning
Nov 02, 2022



Recent incremental learning for action recognition usually stores representative videos to mitigate catastrophic forgetting. However, only a few bulky videos can be stored due to the limited memory. To address this problem, we propose FrameMaker, a memory-efficient video class-incremental learning approach that learns to produce a condensed frame for each selected video. Specifically, FrameMaker is mainly composed of two crucial components: Frame Condensing and Instance-Specific Prompt. The former is to reduce the memory cost by preserving only one condensed frame instead of the whole video, while the latter aims to compensate the lost spatio-temporal details in the Frame Condensing stage. By this means, FrameMaker enables a remarkable reduction in memory but keep enough information that can be applied to following incremental tasks. Experimental results on multiple challenging benchmarks, i.e., HMDB51, UCF101 and Something-Something V2, demonstrate that FrameMaker can achieve better performance to recent advanced methods while consuming only 20% memory. Additionally, under the same memory consumption conditions, FrameMaker significantly outperforms existing state-of-the-arts by a convincing margin.
MAR: Masked Autoencoders for Efficient Action Recognition
Jul 24, 2022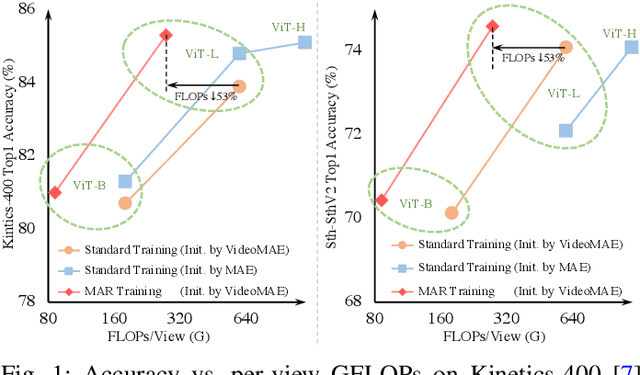
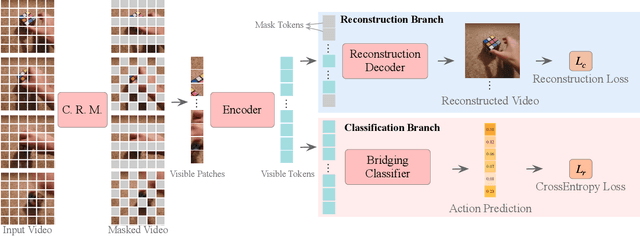
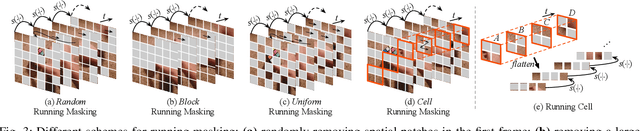
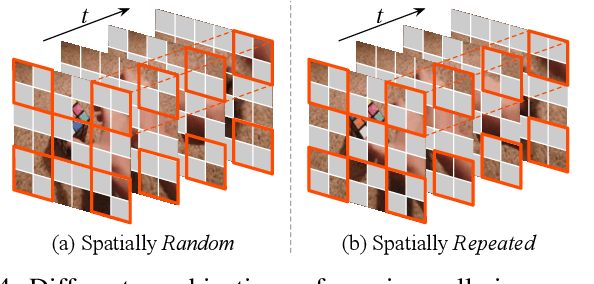
Standard approaches for video recognition usually operate on the full input videos, which is inefficient due to the widely present spatio-temporal redundancy in videos. Recent progress in masked video modelling, i.e., VideoMAE, has shown the ability of vanilla Vision Transformers (ViT) to complement spatio-temporal contexts given only limited visual contents. Inspired by this, we propose propose Masked Action Recognition (MAR), which reduces the redundant computation by discarding a proportion of patches and operating only on a part of the videos. MAR contains the following two indispensable components: cell running masking and bridging classifier. Specifically, to enable the ViT to perceive the details beyond the visible patches easily, cell running masking is presented to preserve the spatio-temporal correlations in videos, which ensures the patches at the same spatial location can be observed in turn for easy reconstructions. Additionally, we notice that, although the partially observed features can reconstruct semantically explicit invisible patches, they fail to achieve accurate classification. To address this, a bridging classifier is proposed to bridge the semantic gap between the ViT encoded features for reconstruction and the features specialized for classification. Our proposed MAR reduces the computational cost of ViT by 53% and extensive experiments show that MAR consistently outperforms existing ViT models with a notable margin. Especially, we found a ViT-Large trained by MAR outperforms the ViT-Huge trained by a standard training scheme by convincing margins on both Kinetics-400 and Something-Something v2 datasets, while our computation overhead of ViT-Large is only 14.5% of ViT-Huge.
Hybrid Relation Guided Set Matching for Few-shot Action Recognition
Apr 28, 2022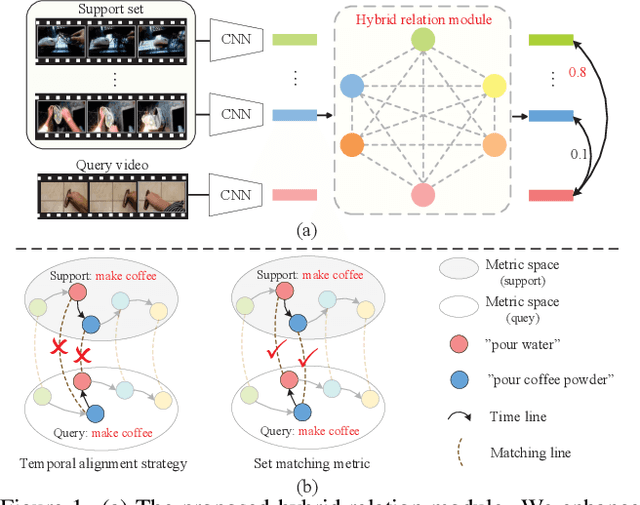
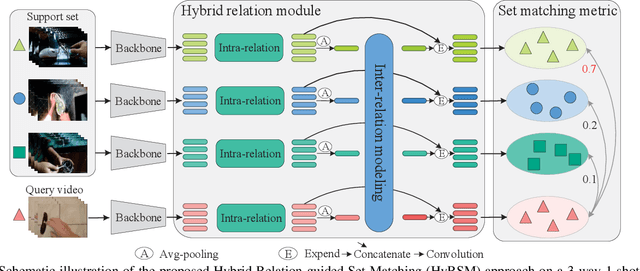
Current few-shot action recognition methods reach impressive performance by learning discriminative features for each video via episodic training and designing various temporal alignment strategies. Nevertheless, they are limited in that (a) learning individual features without considering the entire task may lose the most relevant information in the current episode, and (b) these alignment strategies may fail in misaligned instances. To overcome the two limitations, we propose a novel Hybrid Relation guided Set Matching (HyRSM) approach that incorporates two key components: hybrid relation module and set matching metric. The purpose of the hybrid relation module is to learn task-specific embeddings by fully exploiting associated relations within and cross videos in an episode. Built upon the task-specific features, we reformulate distance measure between query and support videos as a set matching problem and further design a bidirectional Mean Hausdorff Metric to improve the resilience to misaligned instances. By this means, the proposed HyRSM can be highly informative and flexible to predict query categories under the few-shot settings. We evaluate HyRSM on six challenging benchmarks, and the experimental results show its superiority over the state-of-the-art methods by a convincing margin. Project page: https://hyrsm-cvpr2022.github.io/.
Learning from Untrimmed Videos: Self-Supervised Video Representation Learning with Hierarchical Consistency
Apr 06, 2022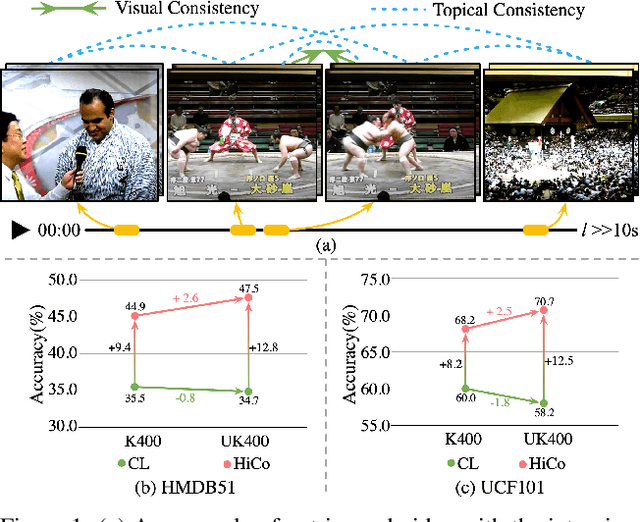
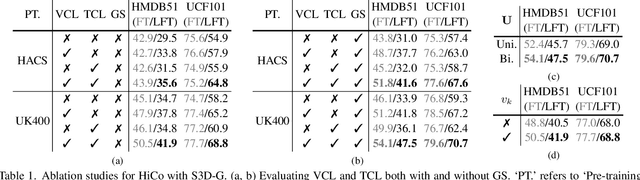
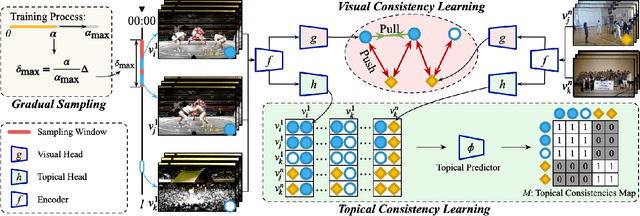
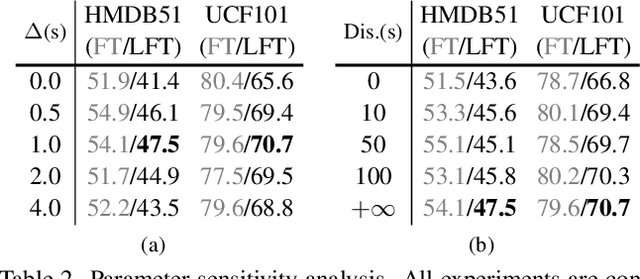
Natural videos provide rich visual contents for self-supervised learning. Yet most existing approaches for learning spatio-temporal representations rely on manually trimmed videos, leading to limited diversity in visual patterns and limited performance gain. In this work, we aim to learn representations by leveraging more abundant information in untrimmed videos. To this end, we propose to learn a hierarchy of consistencies in videos, i.e., visual consistency and topical consistency, corresponding respectively to clip pairs that tend to be visually similar when separated by a short time span and share similar topics when separated by a long time span. Specifically, a hierarchical consistency learning framework HiCo is presented, where the visually consistent pairs are encouraged to have the same representation through contrastive learning, while the topically consistent pairs are coupled through a topical classifier that distinguishes whether they are topic related. Further, we impose a gradual sampling algorithm for proposed hierarchical consistency learning, and demonstrate its theoretical superiority. Empirically, we show that not only HiCo can generate stronger representations on untrimmed videos, it also improves the representation quality when applied to trimmed videos. This is in contrast to standard contrastive learning that fails to learn appropriate representations from untrimmed videos.
TAda! Temporally-Adaptive Convolutions for Video Understanding
Oct 12, 2021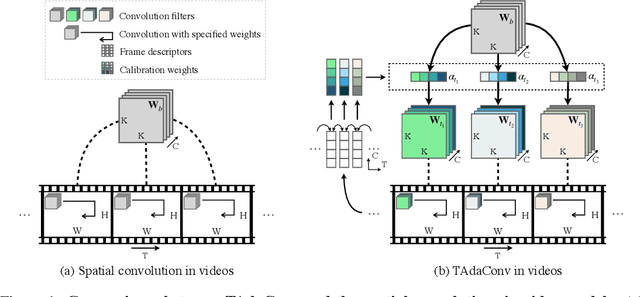

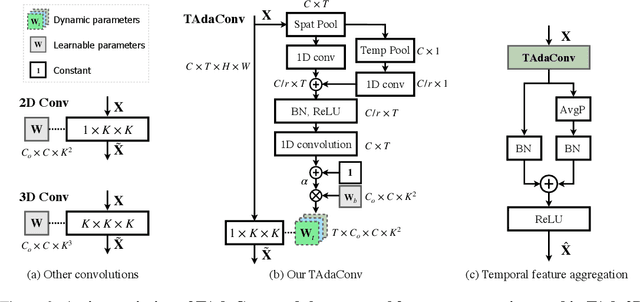
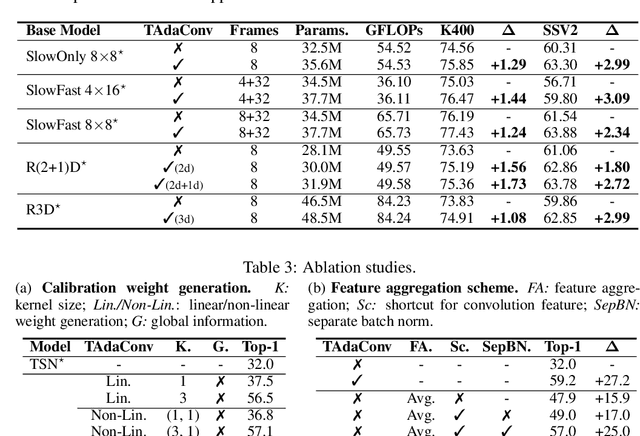
Spatial convolutions are widely used in numerous deep video models. It fundamentally assumes spatio-temporal invariance, i.e., using shared weights for every location in different frames. This work presents Temporally-Adaptive Convolutions (TAdaConv) for video understanding, which shows that adaptive weight calibration along the temporal dimension is an efficient way to facilitate modelling complex temporal dynamics in videos. Specifically, TAdaConv empowers the spatial convolutions with temporal modelling abilities by calibrating the convolution weights for each frame according to its local and global temporal context. Compared to previous temporal modelling operations, TAdaConv is more efficient as it operates over the convolution kernels instead of the features, whose dimension is an order of magnitude smaller than the spatial resolutions. Further, the kernel calibration also brings an increased model capacity. We construct TAda2D networks by replacing the spatial convolutions in ResNet with TAdaConv, which leads to on par or better performance compared to state-of-the-art approaches on multiple video action recognition and localization benchmarks. We also demonstrate that as a readily plug-in operation with negligible computation overhead, TAdaConv can effectively improve many existing video models with a convincing margin. Codes and models will be made available at https://github.com/alibaba-mmai-research/pytorch-video-understanding.
ParamCrop: Parametric Cubic Cropping for Video Contrastive Learning
Sep 05, 2021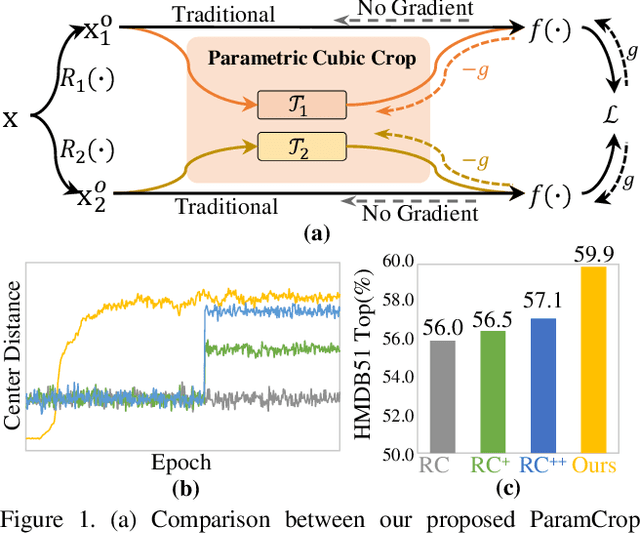

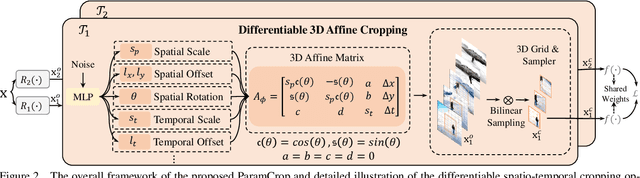
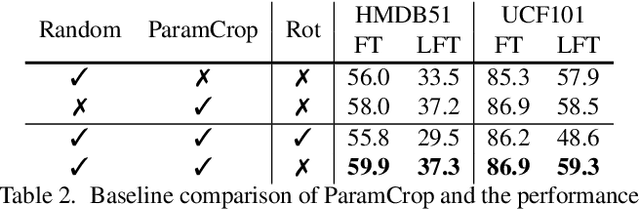
The central idea of contrastive learning is to discriminate between different instances and force different views of the same instance to share the same representation. To avoid trivial solutions, augmentation plays an important role in generating different views, among which random cropping is shown to be effective for the model to learn a strong and generalized representation. Commonly used random crop operation keeps the difference between two views statistically consistent along the training process. In this work, we challenge this convention by showing that adaptively controlling the disparity between two augmented views along the training process enhances the quality of the learnt representation. Specifically, we present a parametric cubic cropping operation, ParamCrop, for video contrastive learning, which automatically crops a 3D cubic from the video by differentiable 3D affine transformations. ParamCrop is trained simultaneously with the video backbone using an adversarial objective and learns an optimal cropping strategy from the data. The visualizations show that the center distance and the IoU between two augmented views are adaptively controlled by ParamCrop and the learned change in the disparity along the training process is beneficial to learning a strong representation. Extensive ablation studies demonstrate the effectiveness of the proposed ParamCrop on multiple contrastive learning frameworks and video backbones. With ParamCrop, we improve the state-of-the-art performance on both HMDB51 and UCF101 datasets.
Exploring Stronger Feature for Temporal Action Localization
Jun 24, 2021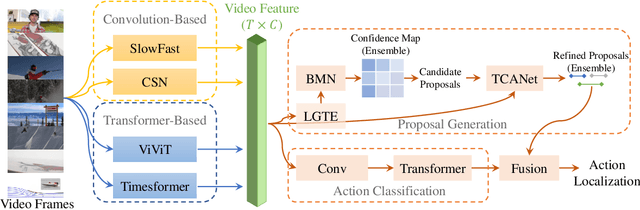
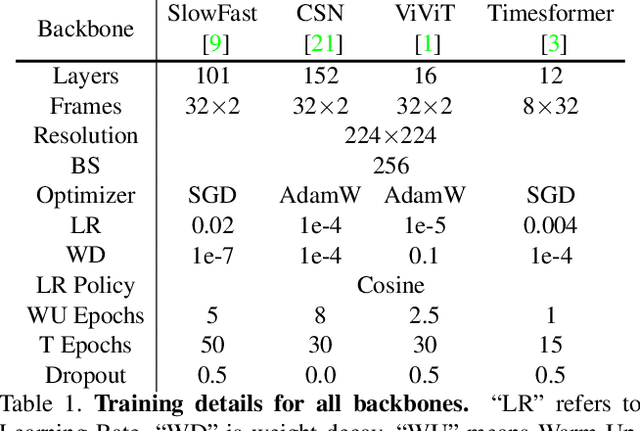
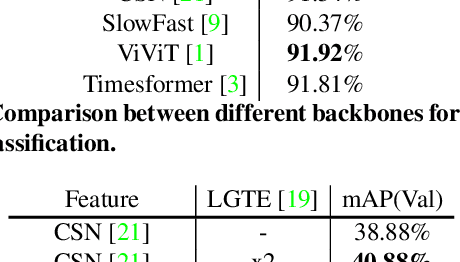

Temporal action localization aims to localize starting and ending time with action category. Limited by GPU memory, mainstream methods pre-extract features for each video. Therefore, feature quality determines the upper bound of detection performance. In this technical report, we explored classic convolution-based backbones and the recent surge of transformer-based backbones. We found that the transformer-based methods can achieve better classification performance than convolution-based, but they cannot generate accuracy action proposals. In addition, extracting features with larger frame resolution to reduce the loss of spatial information can also effectively improve the performance of temporal action localization. Finally, we achieve 42.42% in terms of mAP on validation set with a single SlowFast feature by a simple combination: BMN+TCANet, which is 1.87% higher than the result of 2020's multi-model ensemble. Finally, we achieve Rank 1st on the CVPR2021 HACS supervised Temporal Action Localization Challenge.
OadTR: Online Action Detection with Transformers
Jun 21, 2021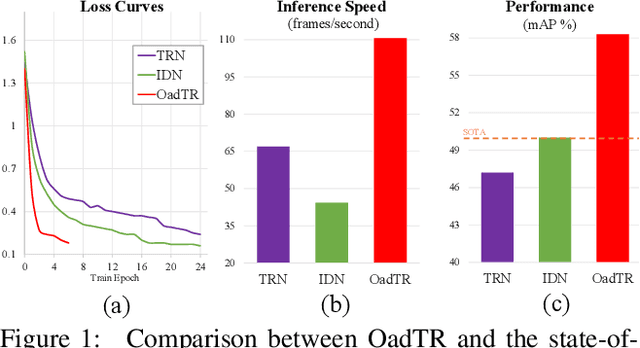

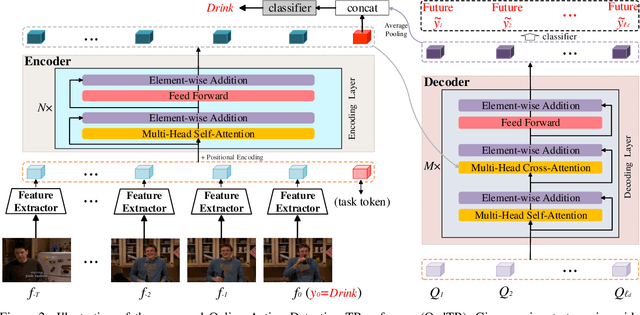
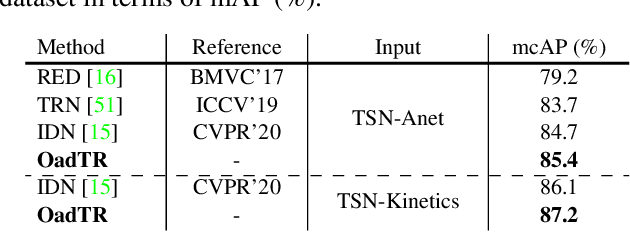
Most recent approaches for online action detection tend to apply Recurrent Neural Network (RNN) to capture long-range temporal structure. However, RNN suffers from non-parallelism and gradient vanishing, hence it is hard to be optimized. In this paper, we propose a new encoder-decoder framework based on Transformers, named OadTR, to tackle these problems. The encoder attached with a task token aims to capture the relationships and global interactions between historical observations. The decoder extracts auxiliary information by aggregating anticipated future clip representations. Therefore, OadTR can recognize current actions by encoding historical information and predicting future context simultaneously. We extensively evaluate the proposed OadTR on three challenging datasets: HDD, TVSeries, and THUMOS14. The experimental results show that OadTR achieves higher training and inference speeds than current RNN based approaches, and significantly outperforms the state-of-the-art methods in terms of both mAP and mcAP. Code is available at https://github.com/wangxiang1230/OadTR.